

Fast builds, secure builds. Choose two.
source link: https://stripe.com/blog/fast-secure-builds-choose-two
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Fast builds, secure builds. Choose two.
From data pipelines written in Scala and Python to infrastructure defined in Terraform, Stripe engineers interact with many different programming languages daily. We rely on complex build pipelines to convert Go source code into native binaries, Java into bytecode, and TypeScript into transpiled bundles for the Stripe Dashboard. Even in interpreted languages like Ruby, our code-generation process creates hundreds of thousands of Ruby files containing everything from gRPC service definitions to GraphQL bindings.
Our continuous integration (CI) system is responsible for orchestrating these build pipelines and executing the tens of thousands of test suites that our engineers depend on to validate their changes. Keeping CI performant is crucial for providing our engineers with a delightful development experience. Since our CI system also produces artifacts that ultimately process billions of dollars each day, it's vital that it meets an exceptionally high security bar. At Stripe, we lean on a combination of open-source technologies and novel engineering to deliver a CI system that meets both of these requirements.
A common framework for defining builds
As our codebase grows in volume and variety, Stripe leverages Bazel to manage our build and test pipelines. Bazel provides a multi-language and multi-platform framework to define rules—recipes for how to build and test code in a specific stack. Many of the rules we use are maintained by the open-source community: rules_docker, rules_go and Java rules built directly into Bazel to name a few. Our infrastructure teams build on Bazel’s headline support for custom rulesets to define internal rulesets for Ruby, JavaScript, and Terraform. Our engineers build and test their libraries and services by using these rulesets to declare “targets” specific to their code. Each target instantiates a rule with a set of input files and other attributes. For example, a java_library rule could define a greeter target. The greeter target builds a libgreeter.jar file by invoking various “actions” defined by the rule. In this case, the java_library rule creates an action which invokes the Java compiler (javac).

After engineers define their targets, Bazel is responsible for executing all the necessary actions to build and test a change. However, this execution phase is far from trivial. At Stripe’s scale, building our rapidly growing Java codebase requires executing upwards of two hundred thousand actions.1 Running all these actions from scratch on a single machine would take several hours, even on the largest commodity EC2 instances. Bazel offers two features to address this challenge: remote caching and remote execution. Remote caching allows Bazel to reuse outputs from an action’s earlier execution. Remote execution allows Bazel to distribute actions across multiple machines.

Scaling Bazel with remote caching and execution
Bazel’s remote caching and execution subsystems provide compelling opportunities to improve the performance and efficiency of our CI system. Our engineers consistently identify blazing fast builds as a force multiplier in their workflows. Keeping builds performant (e.g. sub-5 minutes) is core to keeping our engineers productive. Over the years, we’ve dedicated significant engineering resources to building a platform for remote caching and execution that delivers performance and efficiency wins without trading off security or reliability.
To illustrate the risks associated with a naive implementation, consider the implications of allowing any CI build to write to a remote cache. A malicious actor could then replace a business-critical binary trusted to securely handle invoice billing for Stripe customers with a corrupted version that reroutes funds to a personal bank account! Protecting ourselves from action cache poisoning requires that we only allow writes to the cache from trusted sources. A trusted source must faithfully execute actions and upload their true outputs. Fortunately, remote execution comes to the rescue by allowing Bazel to delegate action execution to a trusted source. The trusted sources are exclusively authorized to upload action results to the remote cache.

Creating trusted build workers is easier said than done. Having our trusted worker run Bazel actions implies that we’re evaluating arbitrary untrusted code on our trusted machine. It’s critical that untrusted actions are prevented from writing directly to the action cache or otherwise influencing other co-tenant actions. Our initial implementation of the remote execution service used gVisor, an open-source implementation of the Linux kernel in user space. We coupled it with containerd to manage the container images in which actions execute. Our gVisor-driven sandbox ensured that we were resilient to not only privilege escalations, but also bugs in the Linux kernel. We were able to rest easy knowing that shipping malicious code to our production services would require breaching multiple strong layers of protection.
While gVisor performed admirably for our initial workload, building our Go codebase, it faltered when faced with new workloads. JavaScript bundling, Ruby code generation and Java compilation all showed significant performance penalties in gVisor. In particular, we identified that the filesystem emulation in gVisor adds prohibitive overhead. Unlike Go compilation, which is primarily bound by user space CPU computation, common workloads in the new stacks issue thousands of filesystem syscalls. This behavior is largely attributable to how Ruby and Java import code by searching through a list of tens or hundreds of directories ($LOAD_PATH and CLASSPATH respectively). For instance, running an empty Ruby unit test suite2 issues over 600,000 filesystem syscalls over the course of 5.5 seconds while searching a $LOAD_PATH with over 500 directories!
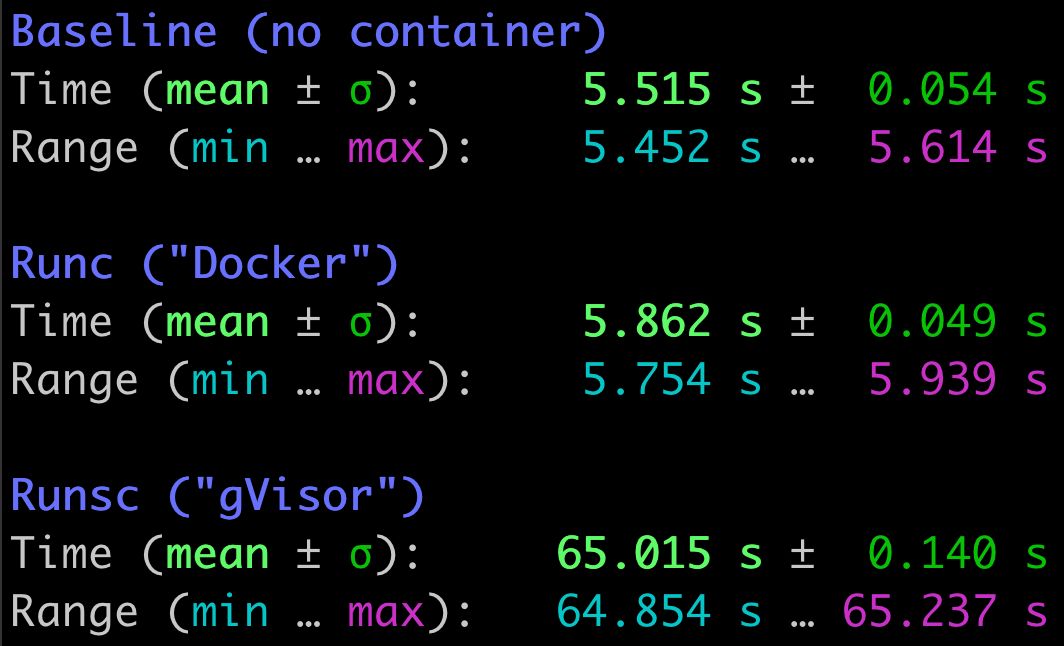
Readout of execution time of a Ruby unit test file with a single no-op test, which immediately succeeds.
The search for a blazing fast sandbox
With application kernels like gVisor imposing a high overhead, and OS-level virtualization primitives like Linux containers lacking a robust enough security barrier, we started exploring hardware virtualization. Our performance goals led us towards Firecracker, a KVM-based microVM solution that features startup times in the 100s of milliseconds and substantially reduces I/O overhead. KVM allows the Linux kernel to act as a hypervisor and run virtual machines (VMs) using hardware virtualization. Our initial experimentation showed promising results, but Firecracker was far from a drop-in solution.
Our most interesting challenge was providing actions with their input files. Before, with our gVisor sandbox, we’d execute actions in an OverlayFS filesystem containing a fixed container image at its base and another directory above it (the “execroot”) with the actions’ inputs, e.g. the test files to execute. Unbeknownst to the action, the execroot consisted entirely of hard links to a local “blobcache” (a directory that held all our input files). This design minimized filesystem setup overhead. For instance, consider running many JavaScript actions where each action requires the same 150K JavaScript files, comprising 2.5GiB, in its node_modules directory. Rather than repeatedly copying 2.5GiB of data for each action, we downloaded each file once into the blobcache. Then, each action received an independent node_modules directory composed of 150K hard links.
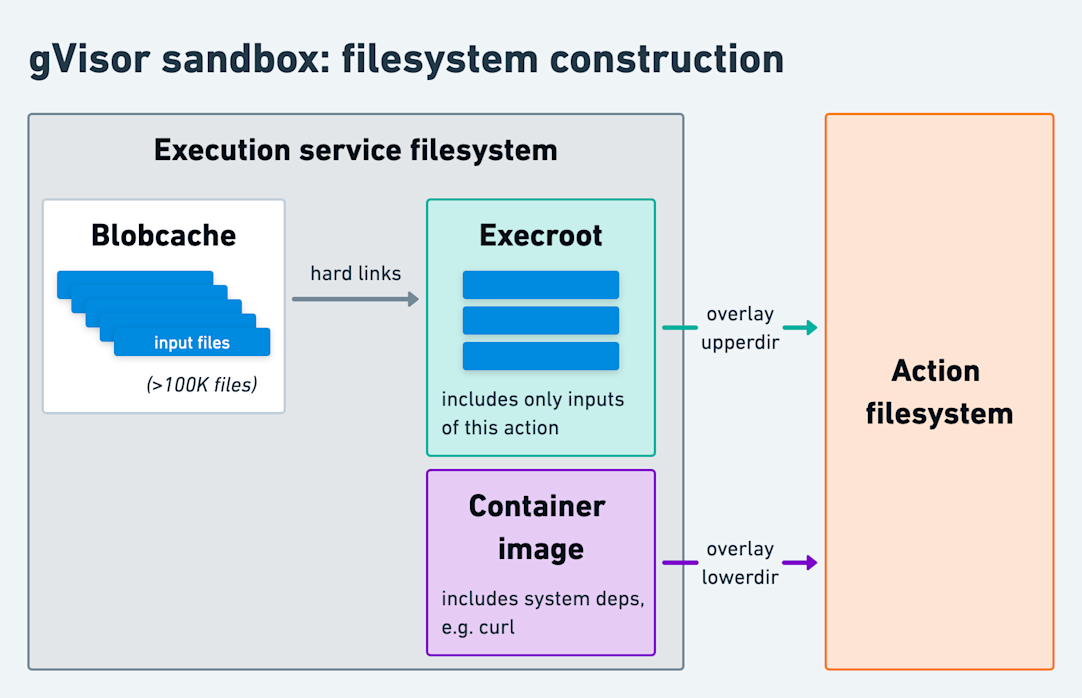
However, Firecracker (or KVM in general) doesn't support an analogous design that depends on OverlayFS to share directories. Instead, KVM exposes a virtio-based API that only allows attaching entire block devices to the guest VM. Since hard links are only valid across the same filesystem, we’d have to directly attach the block device with the blobcache to each microVM. While that might work with a single concurrent microVM, physical block devices, especially ones receiving concurrent writes, can’t be safely mounted more than once. A naive approach of copying from the blobcache for each action would incur a steep performance penalty. We needed an alternative that would allow our remote execution service to binpack dozens of concurrent actions on a single machine.
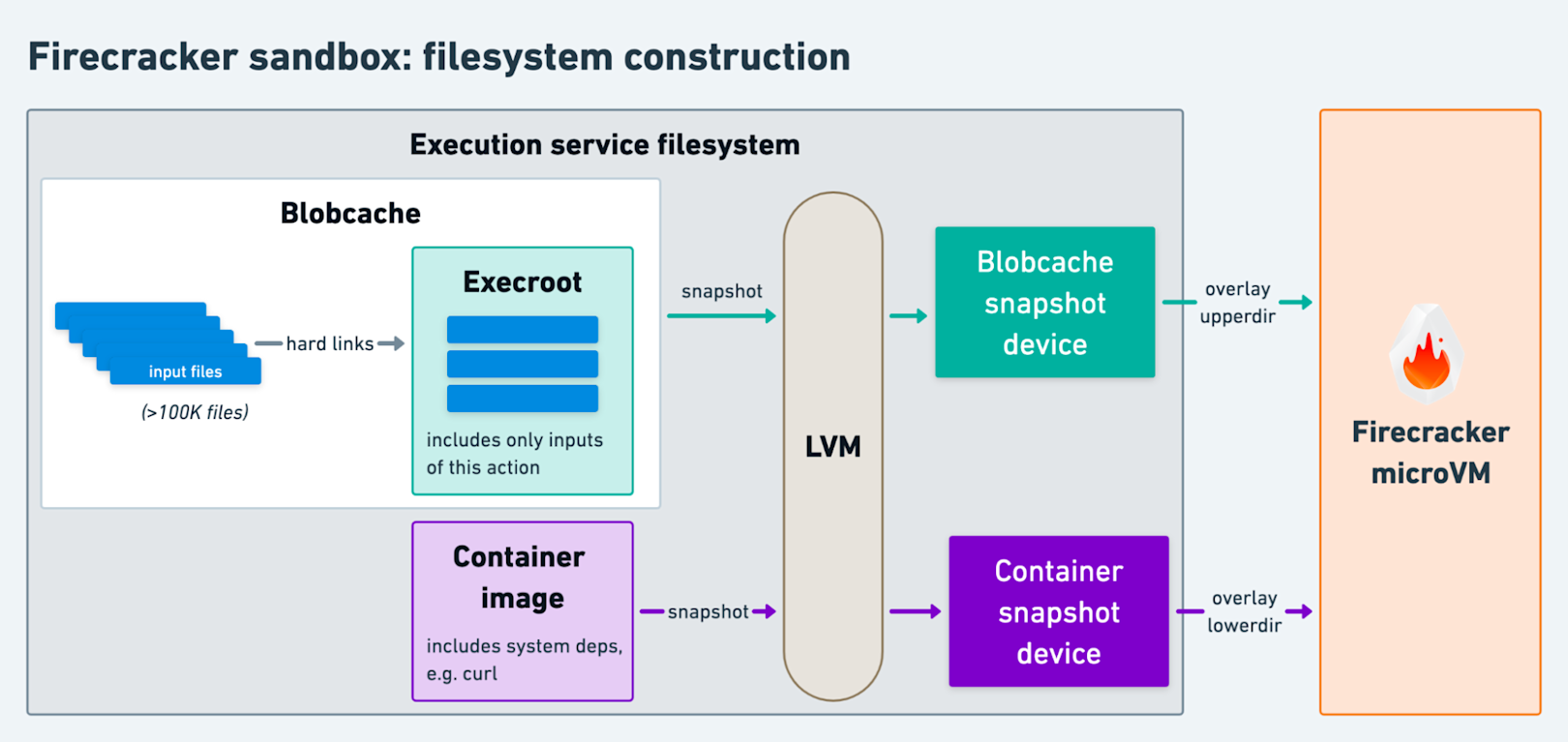
Fortunately, Linux’s Logical Volume Manager (LVM) provides a compelling solution. Our remote execution service now relies on LVM to orchestrate the execution process:
- First, we continue to download action inputs into the blobcache. We concurrently boot our Firecracker microVM3 with empty placeholder disks and an optimized build of the Linux kernel.
- Then, using LVM’s snapshotting capability we create a copy-on-write snapshot of the blobcache’s logical volume. This snapshot occupies almost no physical disk space.
- The blobcache snapshot provides us with a logical block device that we attach to the booted Firecracker microVM using its RESTful API.
- With the containerd devmapper snapshotter (built on the same underlying technology that LVM snapshots abstract over), we create and attach a block device for the action’s container image.
- Then, we send our custom
initprocess a gRPC request over a VM socket, instructing it to mount both block devices and execute the action. The action executes within a chroot that exposes a minimal filesystem built using OverlayFS. - Finally, the blobcache snapshot serves a dual purpose, allowing the execution service access to the action’s outputs after the microVM’s termination.
Diving into an ocean of opportunities
This novel sandboxing strategy is only one of the myriad techniques our remote build system leverages to improve performance. Our remote cache service responds to GetTree RPCs by returning a recursively flattened list of files and directories from a given root directory. The flattening process can be very expensive for large directories full of third-party dependencies. Since these directories rarely change, our remote cache service itself caches the flattening results in a bespoke “TreeCache.” Then, our GetTree handler walks the children of each level of the directory tree in parallel, fetching from the TreeCache when possible to short-circuit evaluation of a cached branch.
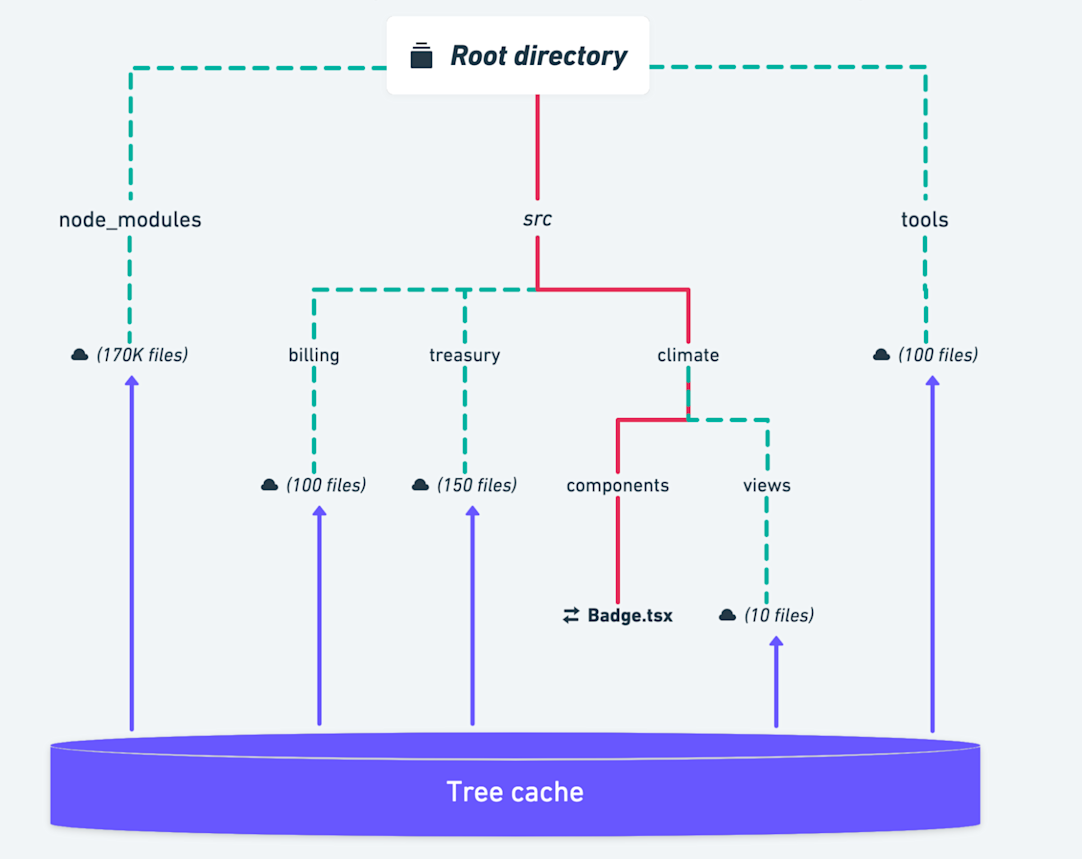
In this example, an isolated change to the src/climate/components/Badge.tsx file allows us to fetch >99.9% of the GetTree response from our TreeCache.
Branches that are unchanged and thus cached are denoted with green dashes.
On the topic of large directories, we’ve started experimenting with an alternative strategy where actions depend on a SquashFS image that bundles action dependencies which don’t change often. For example, changes to a package.json (the primary input to a large node_modules directory) are few and far between. This has led to observed performance improvements across the board: the Bazel client spends less time building an action digest, our cache service spends less time in the GetTree RPC, and our execution service creates orders of magnitude fewer hard links.
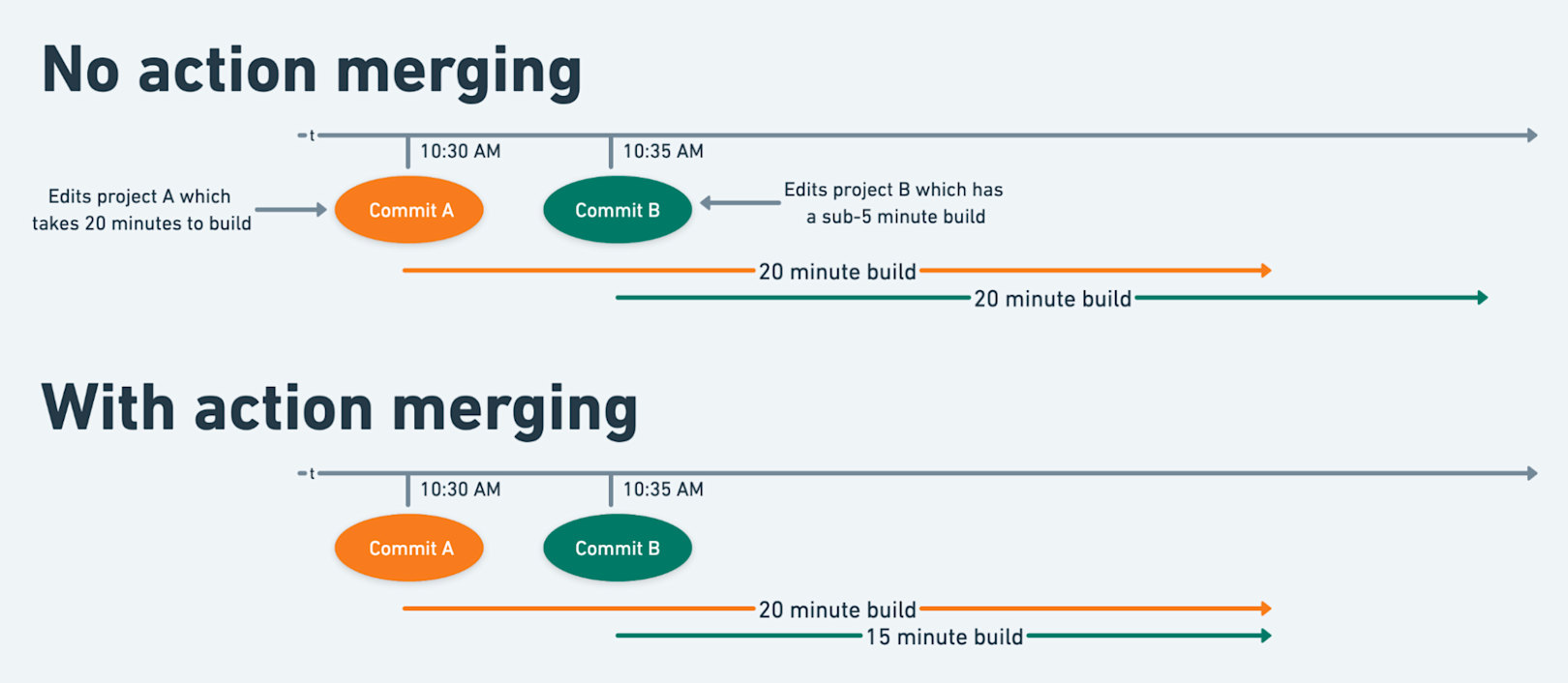
Our remote execution service has a couple other tricks up its sleeve. For example, when our distribution layer schedules an action on an executor, it checks if another executor is already running an identical action. If so, rather than reserving resources and executing the action itself, the second executor blocks on completion of the first execution and re-uses its results. Action merging consistently helps improve build performance and efficiency, especially for particularly lengthy actions. Since the Bazel client never checks the remote cache after starting an action, this optimization relies on our remote execution service.
We’re constantly on the lookout for new techniques to improve the performance, reliability and efficiency of our remote build services. For instance, we recently investigated NILFS, a log-structured filesystem that could rival LVM’s snapshotting performance. As our system grows, we’re exploring new strategies for load balancing in a highly heterogeneous environment, essentially solving a low-latency distributed scheduling problem. We’re eager to explore Firecracker’s snapshotting support which could help drive down latency in workloads where JVM startup is significant. For example, we could speed up Java compilation by scheduling actions on a microVM that has already started a JVM.
Providing our engineers with a CI system that delivers rapid feedback on their changes and tightening the development loop is a top priority for Stripe. Our solution wouldn’t be possible without Bazel. Its primitives give our engineers and platform teams a foundation for expressing rich, domain-specific build and test pipelines. Engineers across the organization benefit from a shared vocabulary and toolkit that not only streamlines their support experience, but also provides our productivity teams with a single point of extraordinarily high leverage. In particular, features like cached build results and distributed build execution are table stakes as we strive to support thousands of engineers.
Rather than spreading our investment across bespoke caching and distribution models for every language’s build/test toolchain, we’ve invested deeply in implementing Bazel’s remote caching and execution APIs. Building remote caching and execution services that can delight everyone, from the Stripes testing their Subscriptions API change to the Stripes evaluating our infrastructure’s security posture, is a significant task. Our approach relies on a unique combination of technologies to meet its performance goals while balancing security. We’re far from done. Each morning, we’re invigorated by the opportunity to raise the bar of engineering productivity at Stripe.
Footnotes
-
Stripe’s code is organized in a small number of monorepos. Only builds of our entire Java monorepo are this expensive. As we innovate on our CI systems, we’re moving towards consistently building smaller subsets of each repository as a function of an engineer’s change. However, many situations, e.g. updates to core libraries, may still require very large builds to complete successfully and efficiently.
-
This includes load-time overhead required within Stripe’s Ruby environment. For example, initializing our autoloader and our patches to open-source dependencies. In practice, engineers are running tests against a live test-server that forks for each test, amortizing a large fraction of the load-time cost. However, this amortization isn’t available when each action starts in a fresh sandbox.
-
Julia Evans has published an excellent blog post that details some of the steps involved in powering a service with Firecracker microVMs.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK