

The difference between me and you is that I’m not on fire
source link: https://statmodeling.stat.columbia.edu/2018/01/18/difference-im-not-fire/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
The difference between me and you is that I’m not on fire
“Eat what you are while you’re falling apart and it opened a can of worms. The gun’s in my hand and I know it looks bad, but believe me I’m innocent.” – Mclusky
While the next episode of Madam Secretary buffers on terrible hotel internet, I (the other other white meat) thought I’d pop in to say a long, convoluted hello. I’m in New York this week visiting Andrew and the Stan crew (because it’s cold in Toronto and I somehow managed to put all my teaching on Mondays. I’m Garfield without the spray tan.).
So I’m in a hotel on the Upper West Side (or, like, maybe the upper upper west side. I’m in the 100s. Am I in Harlem yet? All I know is that I’m a block from my favourite bar [which, as a side note, Aki does not particularly care for] where I am currently not sitting and writing this because last night I was there reading a book about the rise of the surprisingly multicultural anti-immigration movement in Australia and, after asking what my book was about, some bloke started asking me for my genealogy and “how Australian I am” and really I thought that it was both a bit much and a serious misunderstanding of what someone who is reading book with headphones on was looking for in a social interaction.) going through the folder of emails I haven’t managed to answer in the last couple of weeks looking for something fun to pass the time.
And I found one. Ravi Shroff from the Department of Applied Statistics, Social Science and Humanities at NYU (side note: applied statistics gets a short shrift in a lot of academic stats departments around the world, which is criminal. So I will always love a department that leads with it in the title. I’ll also say that my impression when I wandered in there for a couple of hours at some point last year was that, on top of everything else, this was an uncommonly friendly group of people. Really, it’s my second favourite statistics department in North America, obviously after Toronto who agreed to throw a man into a volcano every year as part of my startup package after I got really into both that Tori Amos album from 1996 and cultural appropriation. Obviously I’m still processing the trauma of being 11 in 1996 and singularly unable to sacrifice any young men to the volcano goddess.) sent me an email a couple of weeks ago about constructing interpretable decision rules.
(Meta-structural diversion: I starting writing this with the new year, new me idea that every blog post wasn’t going to devolve into, say, 500 words on how Medúlla is Björk’s Joanne, but that resolution clearly lasted for less time than my tenure as an Olympic torch relay runner. But if you’ve not learnt to skip the first section of my posts by now, clearly reinforcement learning isn’t for you.)
To hell with good intentions
Ravi sent me his paper Simple rules for complex decisions by Jongbin Jung, Connor Concannon, Ravi Shroff, Sharad Goel and Daniel Goldstein and it’s one of those deals where the title really does cover the content.
This is my absolute favourite type of statistics paper: it eschews the bright shiny lights of ultra-modern methodology in favour of the much harder road of taking a collection of standard tools and shaping them into something completely new.
Why do I prefer the latter? Well it’s related to the age old tension between “state-of-the-art” methods and “stuff-people-understand” methods. The latter are obviously preferred as they’re much easier to push into practice. This is in spite of the former being potentially hugely more effective. Practically, you have to balance “black box performance” with “interpretability”. Where you personally land on that Pareto frontier is between you and your volcano goddess.
This paper proposes a simple decision rule for binary classification problems and shows fairly convincingly that it can be almost as effective as much more complicated classifiers.
There ain’t no fool in Ferguson
The paper proposes a Select-Regress-and-Round method for constructing decision rules that works as follows:
- Select a small number
of features
that will be used to build the classifier
- Regress: Use a logistic-lasso to estimate the classifier
.
- Round: Chose
possible levels of effect and build weights

The new classifier (which chooses between options 1 and 0) selects 1 if
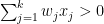
In the paper they use 

: The
th feature has no effect
: The
: The
: The
A couple of key things here that makes this idea work. Firstly, the initial selection phase allows people to “sense check” the initial group of features while also forcing the decision rule to only depend on a small number of features, which greatly improves the ability for people to interpret the rule. The second two phases then works out which of those features are used (the number of active features can be less than
This is a transparent way of building a decision rule, as the effect of each feature used to make the decision is clearly specified. But does it work?
She will only bring you happiness
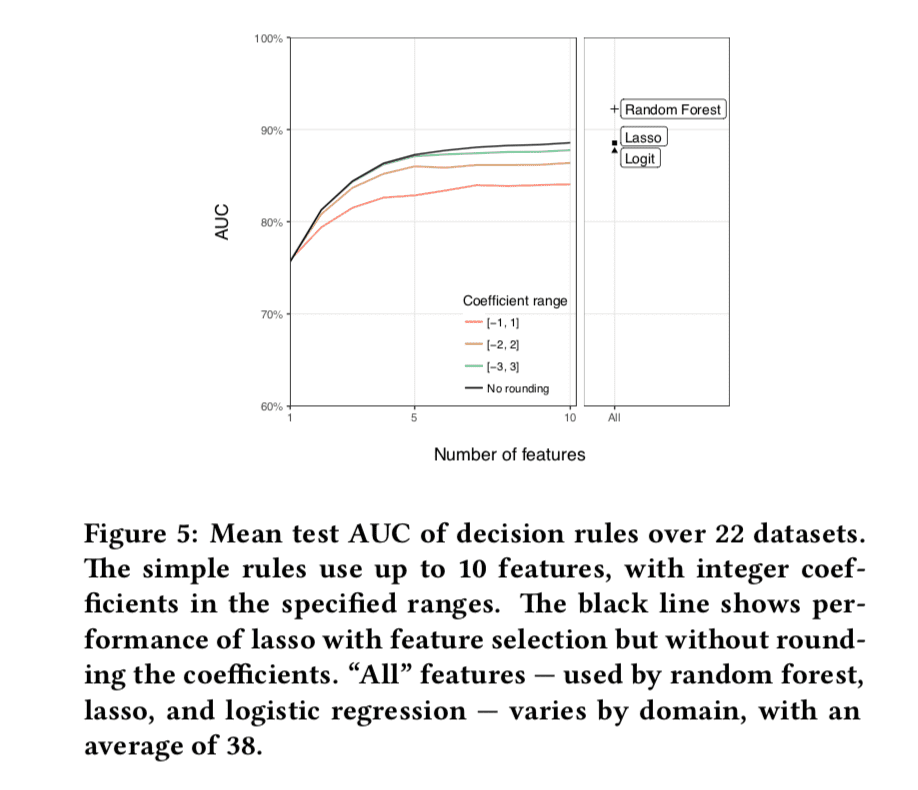
The most surprising thing in this paper is that this very simple strategy for building a decision rule works fairly well. Probably unsurprisingly, complicated, uninterpretable decision rules constructed through random forests typically do work better than this simple decision rule. But the select-regress-round strategy doesn’t do too badly. It might be possible to improve the performance by tweaking the first two steps to allow for some low-order interactions. For binary features, this would allow for classifiers where neither X nor Y are strong indicators of success, but the co-occurance of them (XY) is.
Even without this tweak, the select-regress-round classifier performs about as well as logistic regression and logistic lasso models that use all possible features (see the above figure from the paper), although it performs worse than the random forrest. It also doesn’t appear that the rounding process has too much of an effect on the quality of the classifier.
This man will not hang
The substantive example in this paper has to do with whether or not a judge decides to grant bail, where the event you’re trying to predict is a failure to appear at trial. The results in this paper suggest that the select-regress-round rule leads to a consistently lower rate of failure compared to the “expert judgment” of the judges. It also works, on this example, almost as well as a random forest classifier.
There’s some cool methodology stuff in here about how to actually build, train, and evaluate classification rules when, for any particular experimental unit (person getting or not getting bail in this case), you can only observed one of the potential outcomes. This paper uses some ideas from the causal analysis literature to work around that problem.
I guess the real question I have about this type of decision rule for this sort of example is around how these sorts of decision rules would be applied in practice. In particular, would judges be willing to use this type of system? The obvious advantage of implementing it in practice is that it is data driven and, therefore, the decisions are potentially less likely to fall prey to implicit and unconscious biases. The obvious downside is that I am personally more than the sum of my demographic features (or other measurable quantities) and this type of system would treat me like the average person who has shares the
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK