

Papers
source link: https://andrewpwheeler.com/2020/10/08/recent-papers-on-hot-spots-of-crime-in-dallas/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Recent Papers on Hot Spots of Crime in Dallas
So I have two different papers that were published recently. Both are on hot spots in Dallas, so might as well discuss them together.
- Wheeler, A. P., & Steenbeek, W. (2020). Mapping the risk terrain for crime using machine learning. Journal of Quantitative Criminology Online First
- Wheeler, A.P., & Reuter, S. (2020). Redrawing hot spots of crime in Dallas, Texas. Police Quarterly Online First.
For each I have posted the code to replicate the results (and that spreadsheet has links to preprints as well).
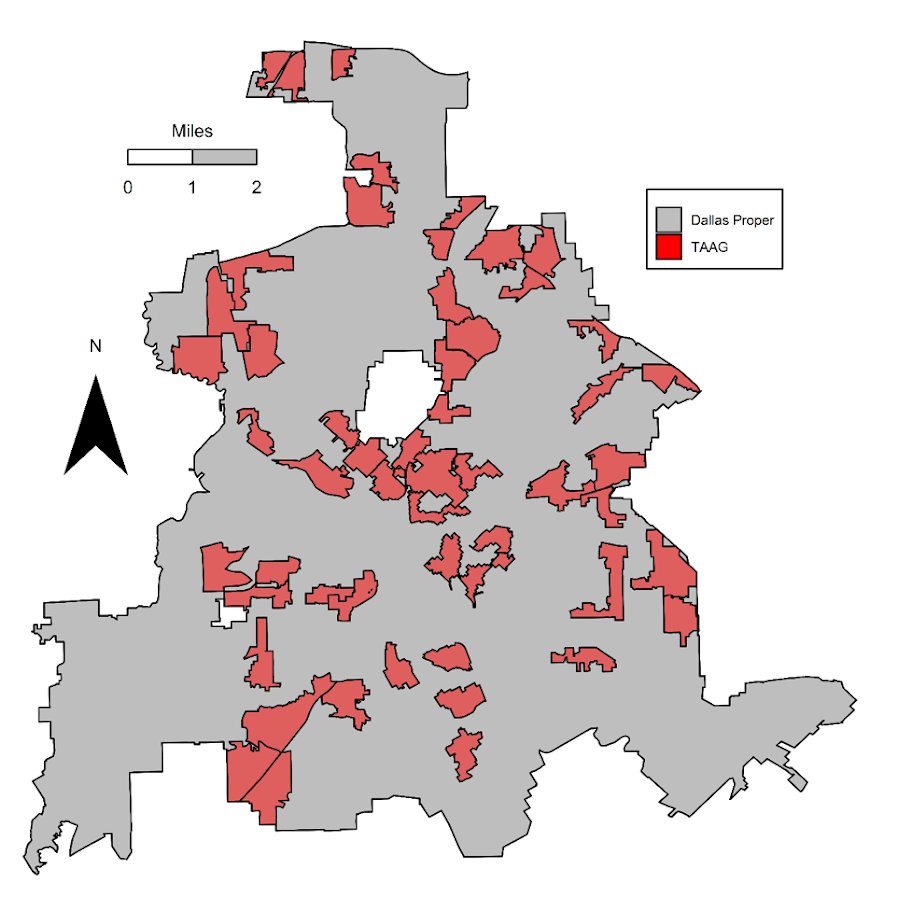
For each as a bit of a background as to the motivation for the projects, Dallas has had official hot spots, named TAAG (Target Area Action Grid). These were clearly larger than what would be considered best practice in identifying hot spots (they were more like entire neighborhoods). I realize ‘best practices’ is a bit wishy-washy, but the TAAG areas ended up covering around 20% of the city (a smidge over 65 square miles). Here is a map of the 2017 areas. There were 54 TAAG areas that covered, so on average each is alittle over 1 square mile.
Additionally I knew the Dallas police department was interested in purchasing the RTM software to do hot spots. And a separate group, the Dallas Crime Task Force was interested in using the software as well for non-police related interventions.
So I did these projects on my own (with my colleagues Wouter and Sydney of course). It wasn’t paid work for any of these groups (I asked DPD if they were interested, and had shared my results with folks from CPAL before that task force report came out, but nothing much came of it unfortunately). But my results for Dallas data are very likely to generalize to other places, so hopefully they will be helpful to others.
Machine Learning to Predict and Understand Hot Spots
So I see the appeal for folks who want to use RTM. It is well validated in both theory and practice, and Joel has made a nice software as a service app. But I knew going in that I could likely improve upon the predictions compared to RTM.
RTM tries to find a middle ground between prediction and causality (which isn’t a critique, it is sort of what we are all doing). RTM in the end spits out predictions that are like “Within 800 feet of a Subway Entrances is Risk Factor 1” and “The Density of Bars within 500 Feet is Risk Factor 2”. So it prefers simple models, that have prognostic value for PDS (or other agencies) to identify potential causal reasons for why that location is high crime. And subsequently helps to not only identify where hot spots are, but frame the potential interventions an agency may be interested it.
But this simplicity has a few drawbacks. One is that it is a global model, e.g. “800 feet within a subway entrance” applies to all subway entrances in the city. Most crime generators have a distribution that makes it so most subway entrances are relatively safe, only a few end up being high crime (for an example). Another is that it forces the way that different crime generators predict crime to be a series of step functions, e.g. “within 600 ft” or “a high density within 1000 ft”. In reality, most geographic processes follow a distance decay function. E.g. if you are looking at the relationship between check-cashing stores and street robbery, there are likely to be more very nearby the store, and it tails off in a gradual process the further away you get.
So I fit a more complicated random forest model that has neither of those limitations and can learn much more complicated functions, both in terms of distance to crime generators as well as spatially varying over the city. But because of that you don’t get the simple model interpretation – they are fundamentally conflicting goals. In terms of predictions either my machine learning model or a simpler comparison of using prior crime = future crime greatly outperforms RTM for several different predictive metrics.
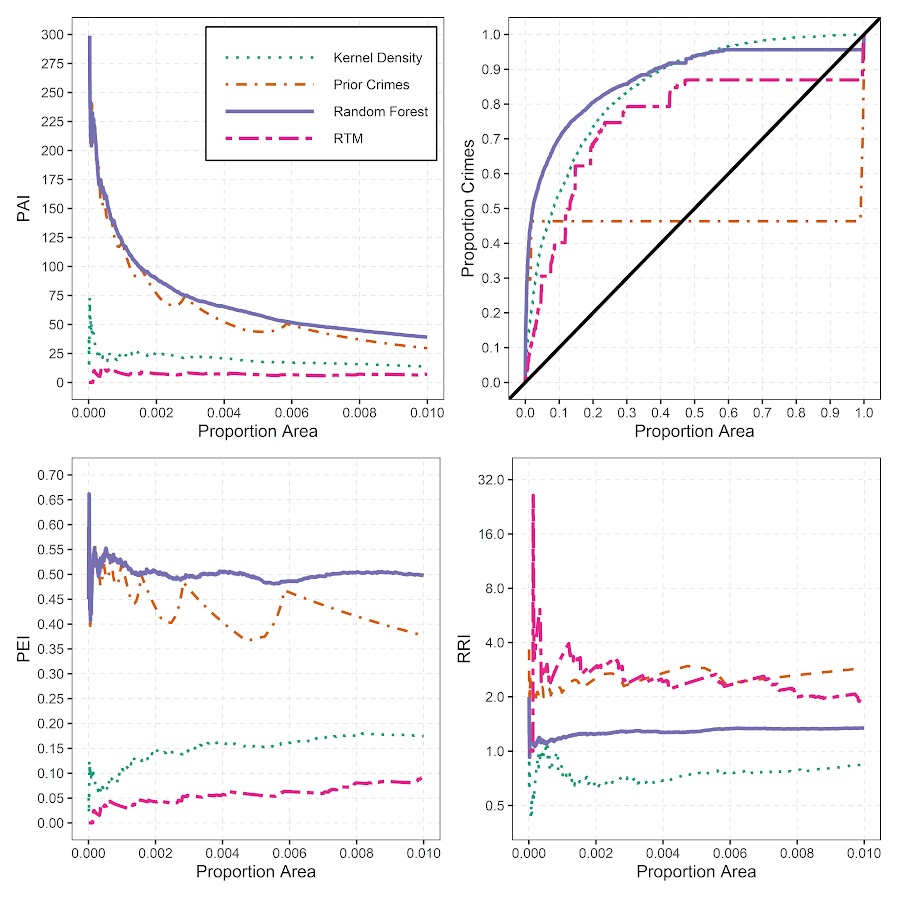
So this shows the predictions are better for RTM no matter how you slice the hot spot areas, but again you lose out the prognostic value of RTM. To replace that, I show local interpretability scores for hot spots. I have an online map here for an example. If you click on one of the high crime predicted areas, it gives you a local breakdown of the different variables that contributes to the risk score.
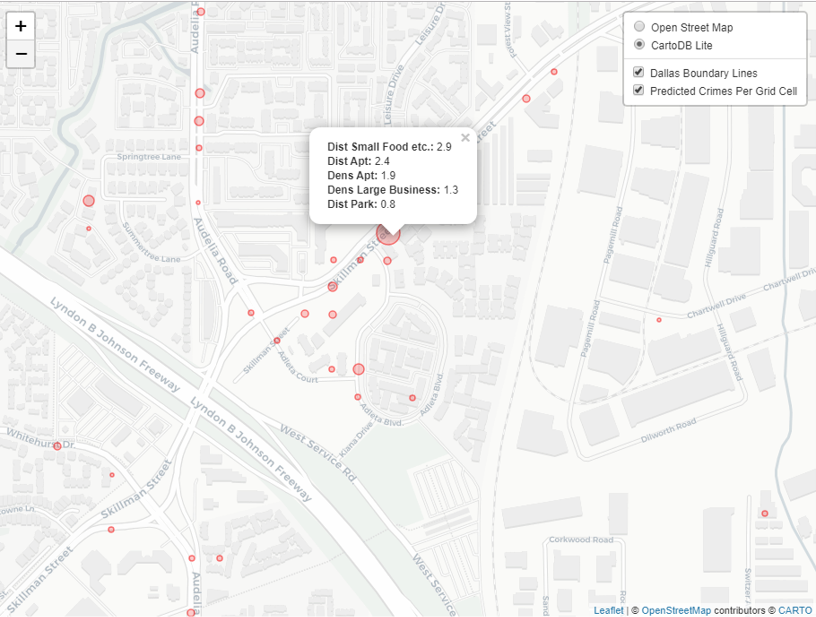
So it is still more complicated than RTM, but gets you a local set of factors that potentially contribute to why places are hot spots. (It is still superficial in terms of causality, but PDs aren’t going to be able to get really well identified causal relationships for these types of predictions.)
Return on Investment for Hot Spots Policing
The second part of this is that Dallas is no doubt in a tight economic bind. And this was even before all the stuff about reforming police budgets. So policing academics have been saying PDs should shift many more resources from reactive to proactive policing for years. But how to make the argument that it is in police departments best interest to shift resources or invest in additional resources?
To do this I aimed to calculate a return on investment on investing in hot spots policing. Priscilla Hunt (from RAND) recently came up with labor cost estimates for crime specifically relevant for police departments. So if an aggravated assault happens PDs (in Texas) typically spend around $8k in labor costs to respond to the crime and investigate (it is $125k for a homicide). So based on this, you can say, if I can prevent 10 agg assaults, I then save $80k in labor costs. I use this logic to estimate a return on investment for PDs to do hot spots policing.
So first I generate hot spots, weighting for the costs of those crimes. Here is an interactive map to check them out, and below is a screenshot of the map.
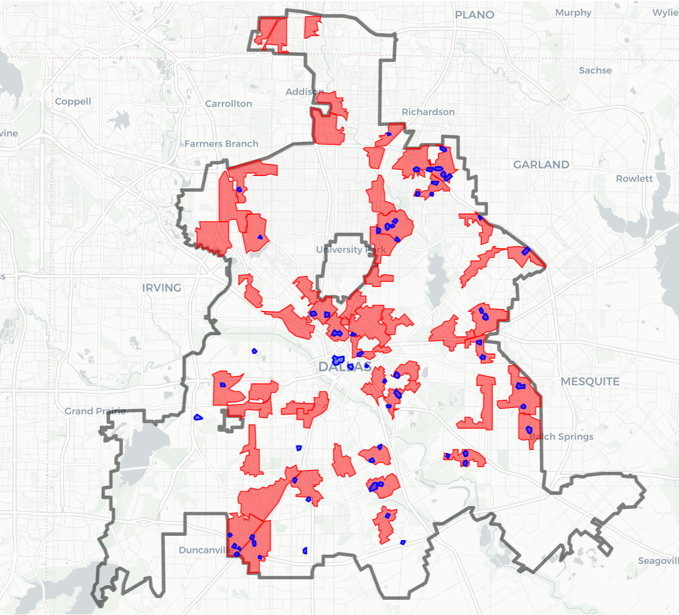
I have an example of then calculating a return on investment for the hot spot area that captured the most crime. I get this estimate by transforming meta-analysis estimates of hot spots policing, estimating an average crime reduction, and then backing out how much labor costs that would save a police department. So in this hot spot, an ROI for hot spots policing (for 1.5 years) is $350k.
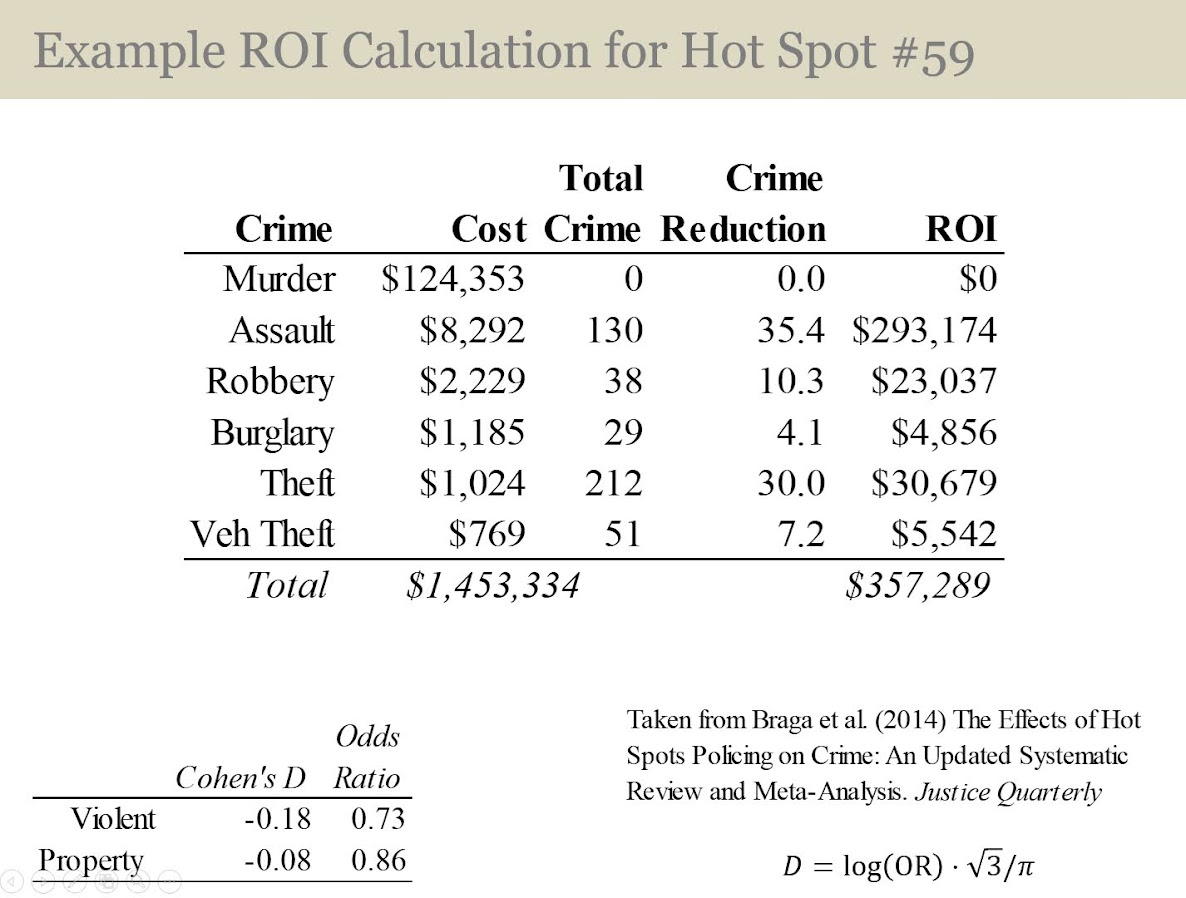
That return would justify at least one (probably more like two) full time officers just to be assigned to that specific hot spot. So if you actually hire more officers, it will be around net-zero in terms of labor costs. If you shift around current officers it should be a net gain in labor resources for the PD.
So most of the hot spots I identify in the study if you do this ROI calculation likely aren’t hot enough to justify hot spots policing from this ROI perspective (these would probably never justify intensive overtime that is typical of crackdown like interventions). But a few clearly are, and definitely should be the targets of some type of hot spot intervention.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK