DevOps, Continuous Delivery... and You
This blog post contains the slides along with a loose transcript and
additional resources from my technical talk on DevOps and Continuous
Delivery concepts given at my alma mater, the University of Virginia,
to the M.S. in Management of Information Technology program on November 2nd and 4th of 2017.
Links to learn more about the concepts presented in this talk can
be found in the sidebar and at the bottom of this page.
Hey folks, my name is
Matt Makai. I am a
software developer at Twilio
and the creator of
Full Stack Python,
which over 125,000 developers read each month to learn how to
build,
deploy and
operate Python-based applications.
You've talked about using the Agile software development methodology
on your teams, but what's the purpose? Why does Agile development matter
to you and your organization?
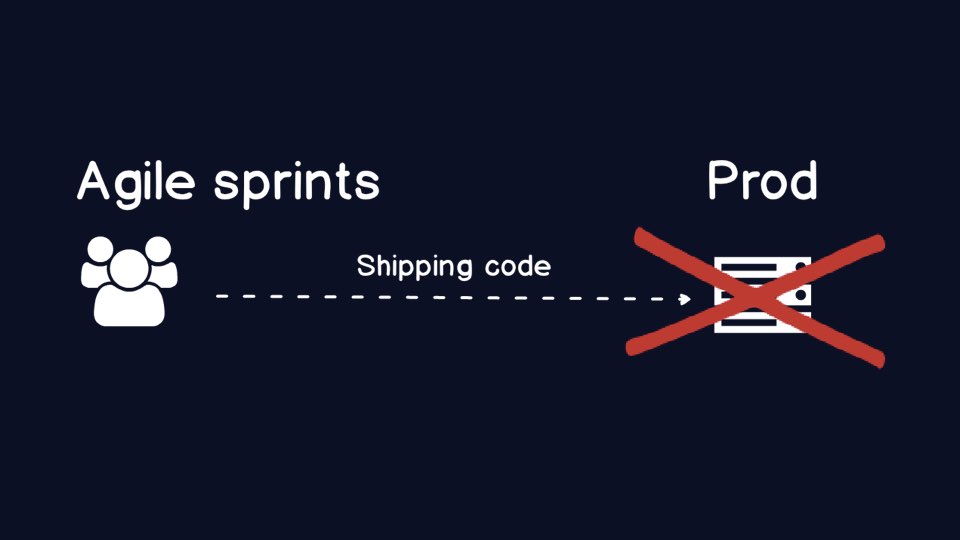
Agile matters because it allows you to ship more code, faster than
traditional "waterfall" methodology approaches.
Shipping is a common allegory in software development nowadays, because
code that is not in production, in the hands of your users, doesn't create
value for anyone.
If code is not running in production, it's not creating value. New
code created by your Agile development teams every couple of weeks does
not create more value until it is executing in production.
Shipping code is so important to high functioning companies that the
maritime theme is used across all sorts of projects, including in the Docker
logo.
As well as in the Kubernetes logo in the form of a ship steering wheel.
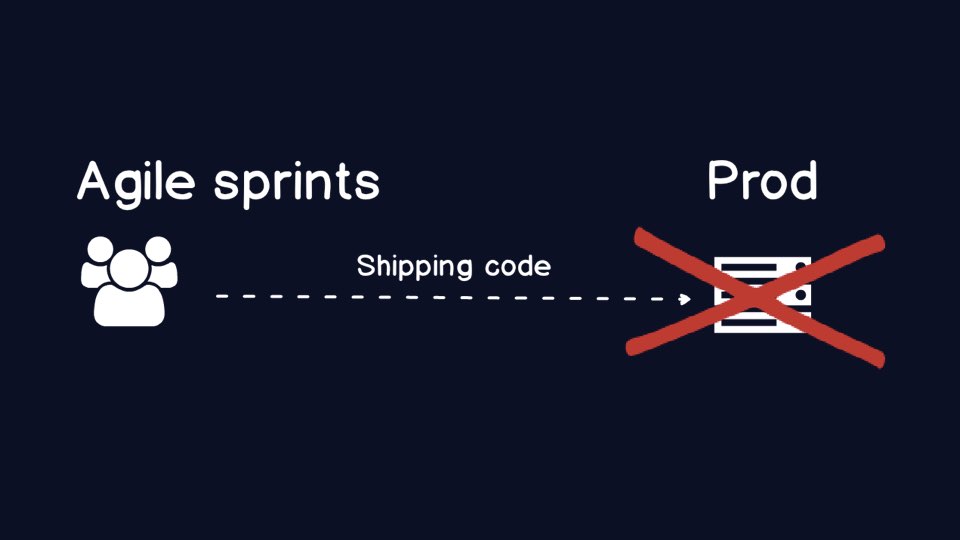
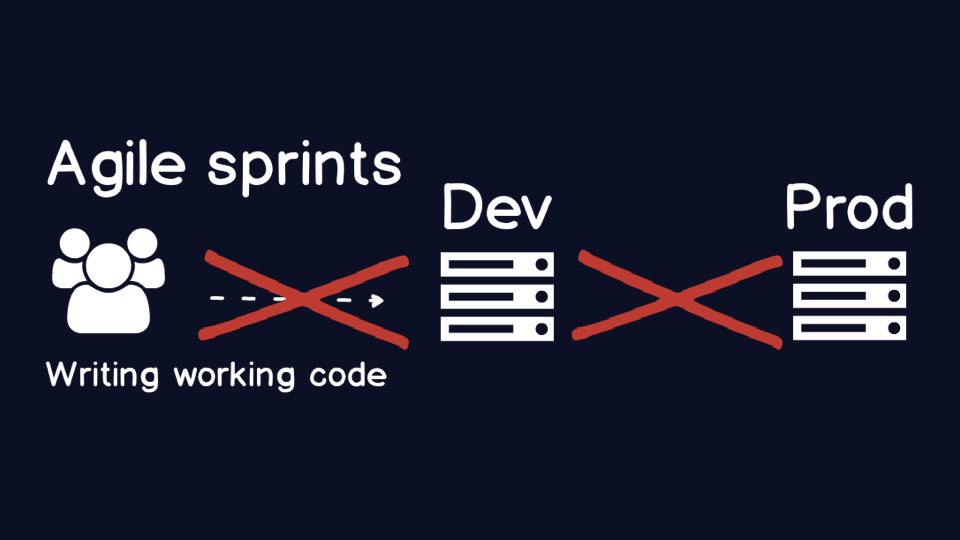
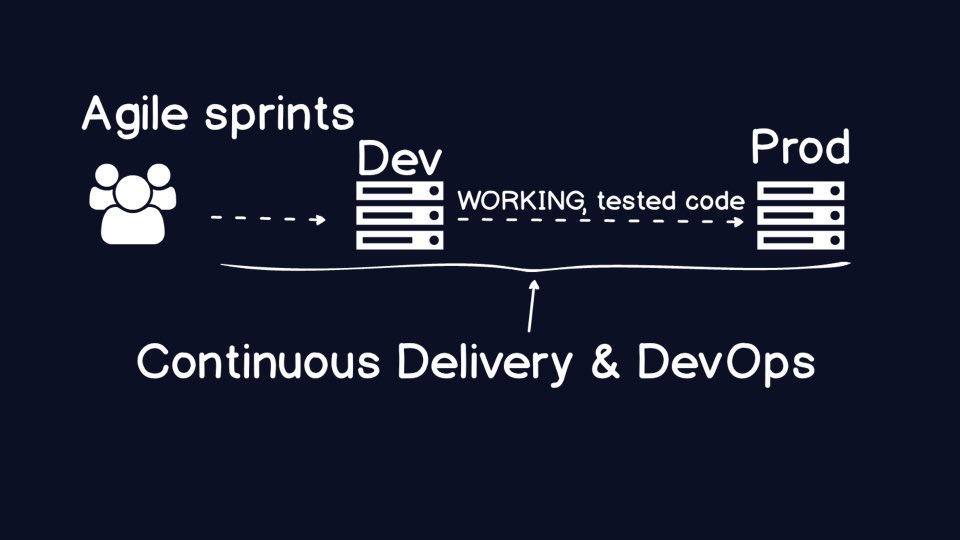
Here is a super high-level diagram of the ideal scenario we need for
Agile development teams. Create working code and get it shipped as soon
as possible into production.
Facebook's internal motto used to be "Move fast and break things." They
thought that if you aren't breaking things then you aren't moving fast
enough.
And eventually if you're constantly shipping to production and you do not
have the appropriate processes and tools in place, your applications
will break. The breakage has nothing to do with the Agile methodology
itself.
Your team and organization will come to a fork in the road when you
end up with a broken environment.
Traditionally, organizations have tried to prevent breakage by putting
more manual tools and processes in place. Manual labor slows... down...
your... ability... to... execute.
This is one path provided by the fork in the road. Put your "Enterprise
Change Review Boards" in place. Require production sign-offs by some
Executive Vice President who has never written a line of code in his life.
Put several dozen "technical architects" in a room together to argue over
who gets to deploy their changes to production that month.
The manual path is insanity. Eventually the best developers in your
organization will get frustrated and leave. Executives will ask why
nothing ever gets done. Why does it take our organization three years
to ship a small change to a critical application?
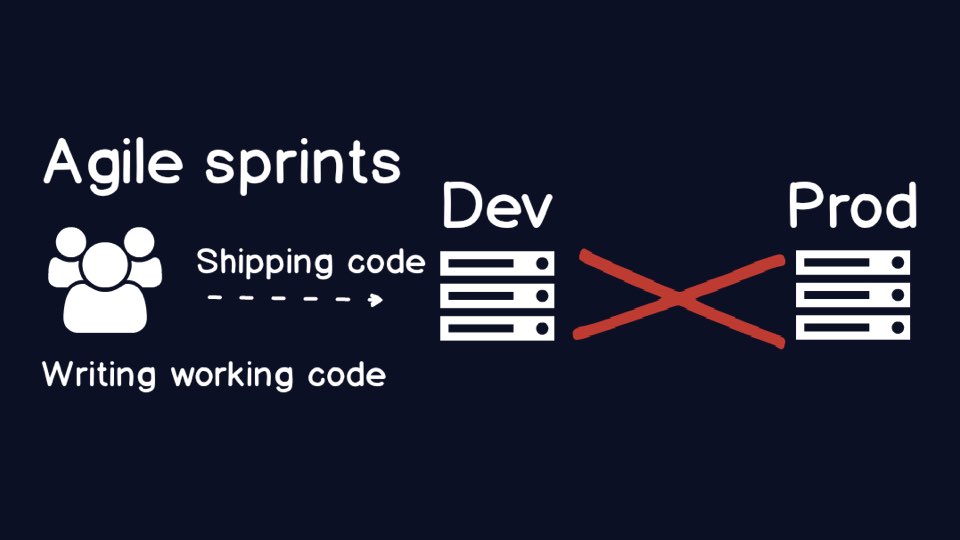
Some development teams try to get around the manual production challenges
by shipping everything to a development environment. The dev environment is
under their control.
But what's the huge glaring problem in this situation?
If you are not shipping to production, then you are not creating any value
for your users. The teams have made a rational decision to ship to development
but the organization still suffers due to the manual controls.
The problems we are talking about are created by the Agile methodology
because they become acute when your development team is producing code at
high velocity. Once code is created faster, you need a way to reliably,
consistently put the code into production so that it can create value for
its users.
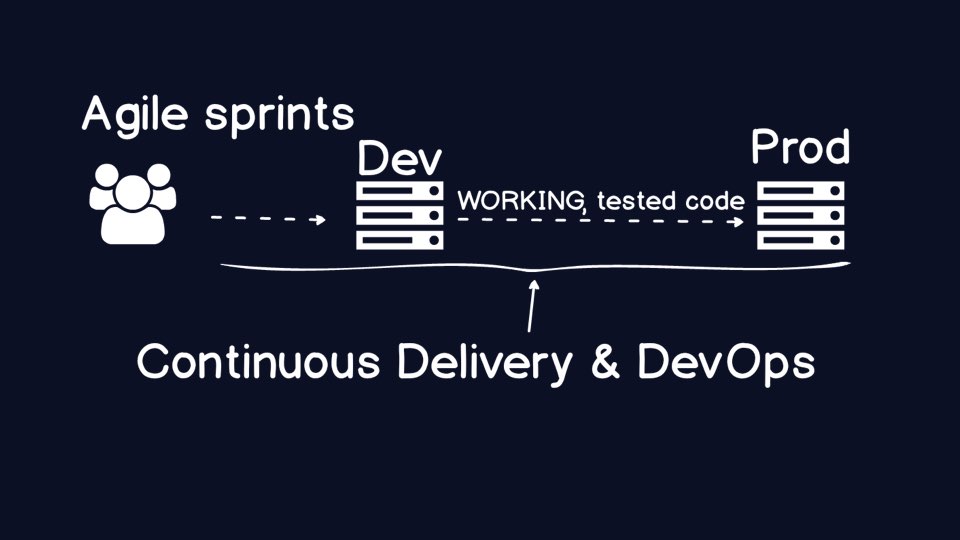
DevOps and Continuous Delivery are the broad terms that encompass how to
reliably ship code to production and operate it when the code is running in
production.
We are going to use the terms "DevOps" and "Continuous Delivery" a lot today,
so let's start by defining what they mean. In fact, the term "DevOps" has
already accumulated a lot of buzzword baggage, so we'll start by defining
what DevOps is
not.
First,DevOps is not a new role. If you go hire a bunch of people and call them
"DevOps engineers" then sit them in the middle of your developers and system
admin/ops folks, you are going to have a bad time. You just added a new layer
between the two groups you need to pull closer together.
Second, DevOps is not a specific tool or application. You do not need to
use Docker or Puppet to do DevOps in your organization. The processes that
make DevOps work are made much easier by some tools such as cloud platforms
where infrastructure is transient, but even those platforms are not required
to do DevOps right.
Third, DevOps is not tied to a specific programming language ecosystem. You
do not need to use Node.js or Ruby on Rails. You can still use DevOps
in a COBOL- or J2EE-only organization.
With those misconceptions out of the way, let's talk about what DevOps IS.
First, at the risk of being way too obvious, DevOps is the combination of the
two words Development and Operations. This combination is not a random
pairing, it's an intentional term.
Second, DevOps means your application developers handle operations. Not
necessarily all operations work, but ops work that deals with the code they
write and deploy as part of their sprints. The developers also will likely
become intimately familiar with the underlying infrastructure such as the
web application servers, web servers and
deployment code for
configuration management tools.
Third, DevOps allows your organization to be more efficient in handling
issues by ensuring the correct person is handling errors and application
failures.
We are not going to go through Continuous Delivery (CD) by defining what it is
not, but there are a couple bits to say about it. First, CD is a collection of
engineering practices aimed at automating the delivery of code from
version control check-in until it is running in a production environment.
The benefit of the automation CD approach is that your organization will have
far greater confidence in the code running in production even as the code
itself changes more frequently with every deployment.
Facebook's original motto changed a few years ago to "Move Fast and Build
Things" because they realized that breaking production was not a byproduct
of moving fast, it was a result of immature organizational processes and
tools. DevOps and Continuous Delivery are why organizations can now deploy
hundreds or thousands of times to production every day but have increasing,
not decreasing, confidence in their systems as they continue to move faster.
Let's take a look at a couple of example scenarios that drive home what
DevOps and CD are all about, as well as learn about some of the processes,
concepts and tools that fall in this domain.
Here is a beautiful evening picture of the city I just moved away from, San
Francisco.
The company I work for,
Twilio is located in
San Francisco. If you ever fly into the SFO airport and catch a ride towards
downtown, you will see our billboard on the right side of the road.
Twilio makes it easy for software developers to add communications, such as
phone calling, messaging and video, into their applications. We are a
telecommunications company built with the power of software that eliminates
the need for customers to buy all the expensive legacy hardware that they
used to have to acquire. As a telecomm company, we can never go down, or
our customers are hosed and then our business is hosed.
However, we have had challenges in our history that have forced us to
confront the fork in the road between manual processes and moving faster via
trust in our automation.
In August 2013, Twilio faced an infrastructure failure.
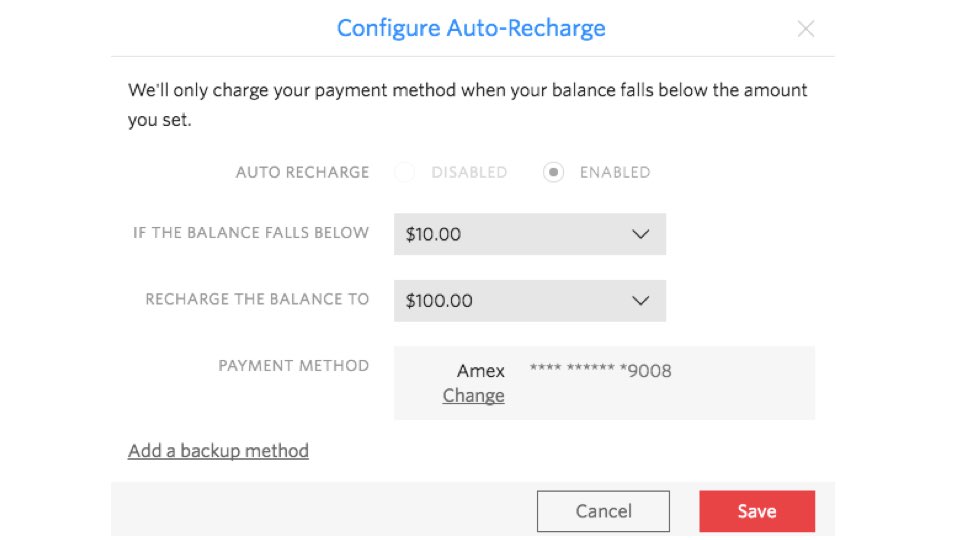
First, some context. When a developer signs up for Twilio, she puts some
credit on their account and the credit is drawn upon by making phone calls,
sending messages and such. When credit runs low we can re-charge your card
so you get more credit.
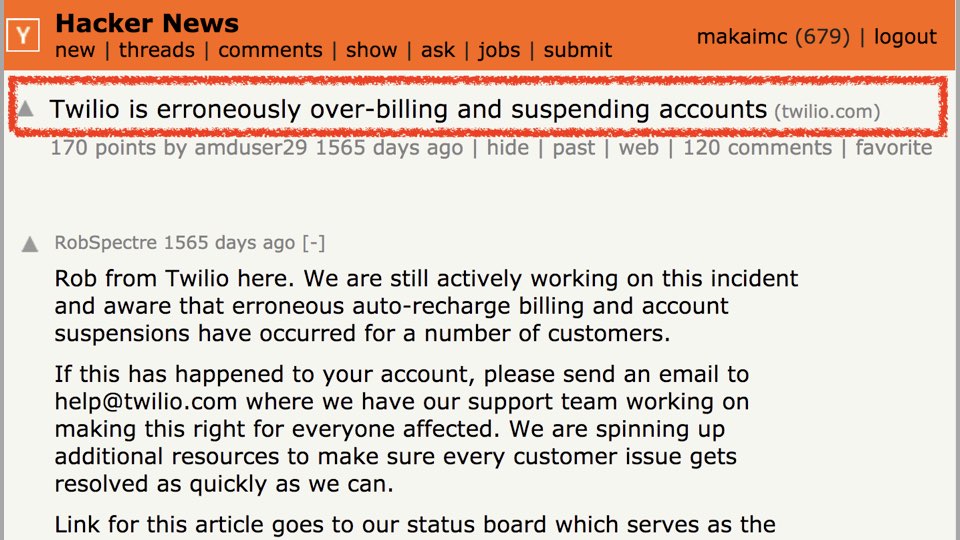
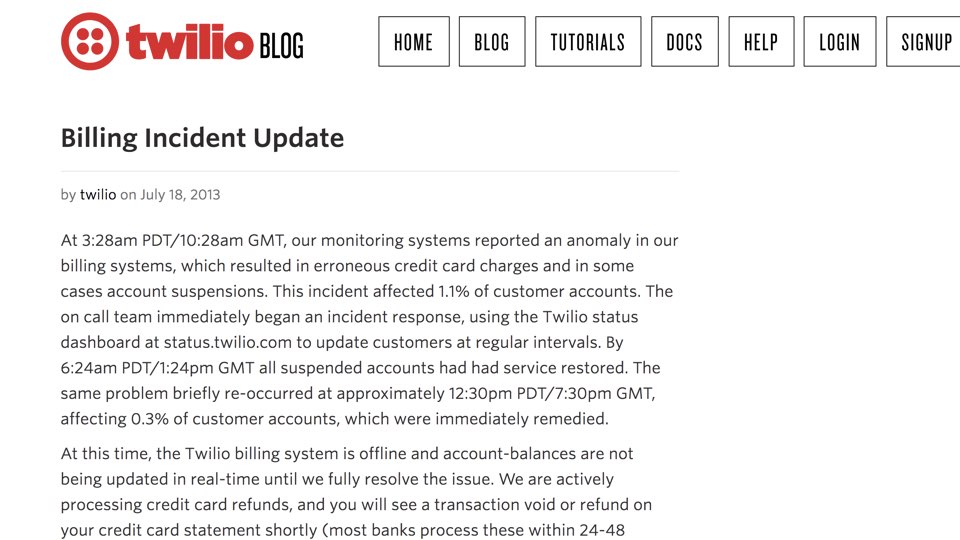
There was a major production issue with the recurring charges in August 2013.
Our engineers were alerted to the errors and the issue blew up on the top of
Hacker News, drawing widespread atttention.
So now there is a major production error... what do we do?
(Reader note: this section is primarily audience discussion based on their
own experiences handling these difficult technical situations.)
One step is to figure out when the problem started and whether or not it
is over. If it's not over, triage the specific problems and start
communicating with customers. Be as accurate and transparent as possible.
The specific technical issue in this case was due to our misconfiguration of
Redis instances.
We know the particular technical failure was due to our Redis mishandling,
but how do we look past the specific bit and get to a broader understanding
of the processes that caused the issue?
Let's take a look at the resolution of the situation and then learn about
the concepts and tools that could prevent future problems.
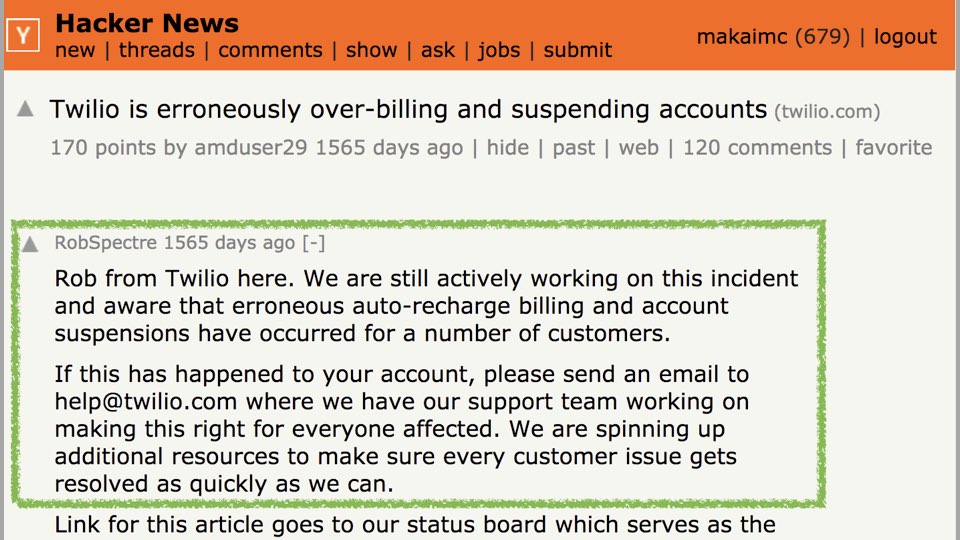
In this case, we communicated with our customers as much about the problem
as possible. As a developer-focused company, we were fortunate that by being
transparent about the specific technical issue, many of our customers gained
respect for us because they had also faced similar misconfigurations in their
own environments.
Twilio became more transparent with the status of services, especially with
showing partial failures and outages.
Twilio was also deliberate in avoiding the accumulation of manual processes
and controls that other organizations often put in place after failures. We
doubled down on resiliency through automation to increase our ability to
deploy to production.
What are some of the tools and concepts we use at Twilio to prevent future
failure scenarios?
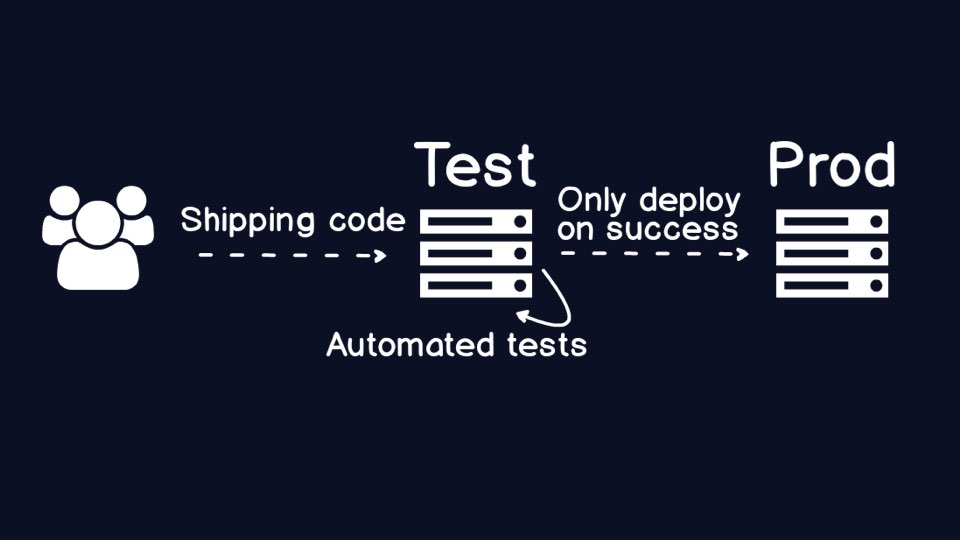
If you do not have the right tools and processes in place, eventually you
end up with a broken production environment after shipping code. What is
one tool we can use to be confident that the code going into production is
not broken?
Automated
testing, in its many forms, such as unit testing,
integration testing, security testing and performance testing, helps to
ensure the integrity of the code. You need to automate because manual
testing is too slow.
Other important tools that fall into the automated testing bucket but are
not traditionally thought of as a "test case" include code coverage and
code metrics (such as Cyclomatic Complexity).
Awesome, now you only deploy to production when a big batch of automated
test cases ensure the integrity of your code. All good, right?
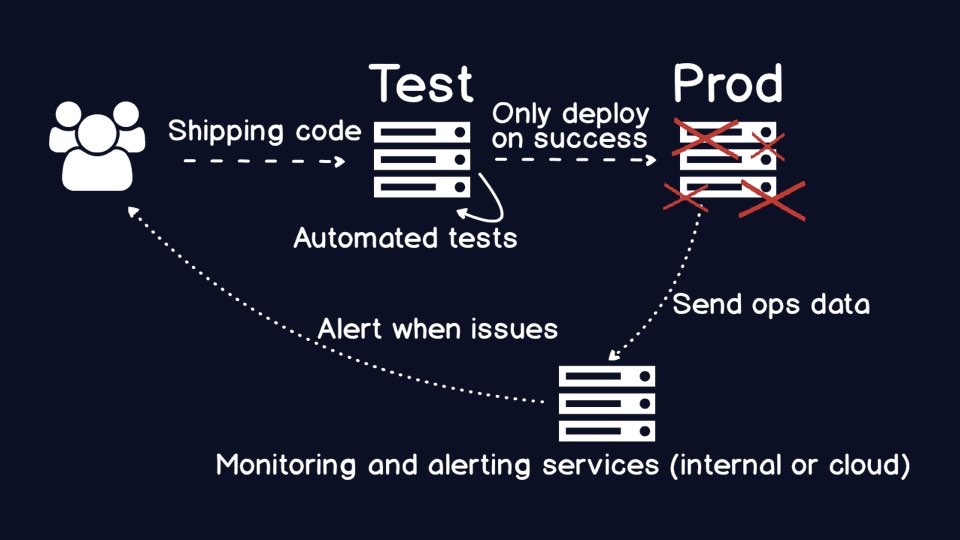
Err, well no. Stuff can still break in production, espcially in environments
where for various reasons you do not have the same exact data in test
that you do in production. Your automated tests and code metrics will
simply not catch every last scenario that could go wrong in production.
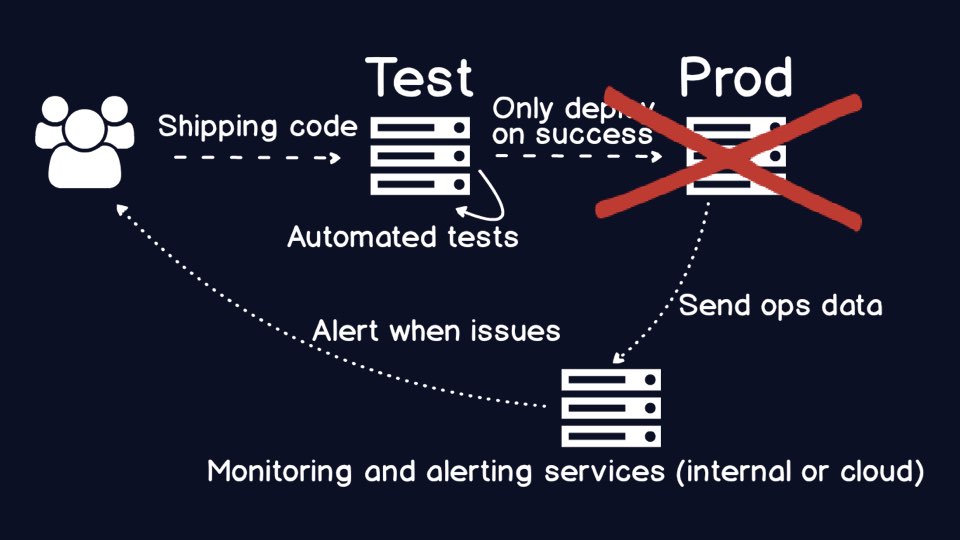
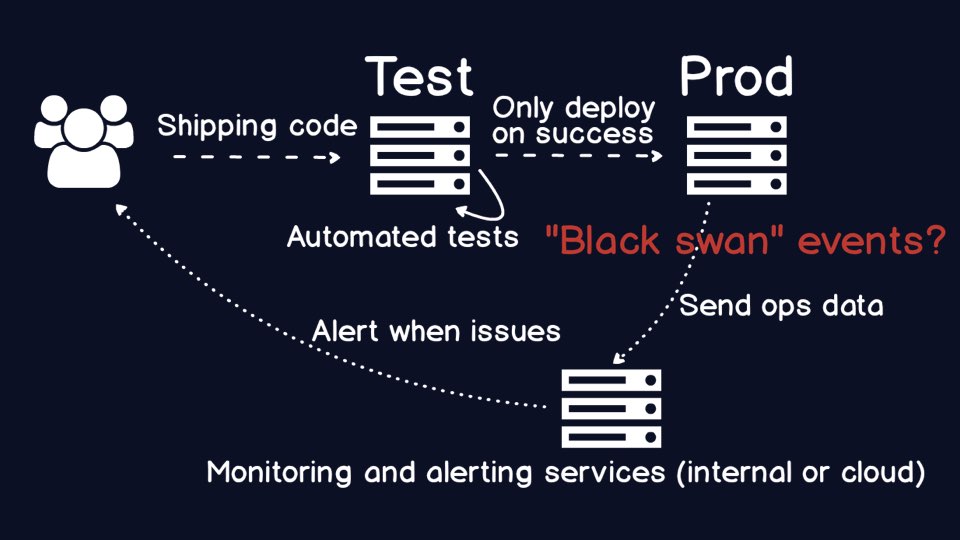
When something goes wrong with your application, you need monitoring to
know what the problem is, and alerting to tell the right folks. Traditionally,
the "right" people were in operations. But over time many organizations
realized the ops folks ended up having to call the original application
developers who wrote the code that had the problem.
A critical piece to DevOps is about ensuring the appropriate developers
are carrying the pagers. It sucks to carry the pager and get woken up in the
middle of the night, but it's a heck of a lot easier to debug the code that
your team wrote than if you are a random ops person who's never seen the
code before in her life.
Another by-product of having application developers carry the "pagers" for
alerts on production issues is that over time the code they write is more
defensive. Errors are handled more appropriately, because otherwise you know
something will blow up on you later on at a less convenient time.
Typically you find though that there are still plenty of production errors
even when you have defensive code in place with a huge swath of the most
important parts of your codebase being constantly tested.
That's where a concept known as "chaos engineering" can come in. Chaos
engineering breaks parts of your production environment on a schedule and
even unscheduled basis. This is a very advanced technique- you are not going
to sell this in an environment that has no existing automated test coverage
or appropriate controls in place.
By deliberately introducing failures, especially during the day when your
well-caffeinated team can address the issues and put further safeguards in
place, you make your production environment more resilient.
We talked about the failure in Twilio's payments infrastructure several years
ago that led us to ultimately become more resilient to failure by putting
appropriate automation in place.
Screwing with other people's money is really bad, and so is messing with
people's lives.
Let's discuss a scenario where human lives were at stake.
To be explicit about this next scenario, I'm only going to talk about public
information, so my cleared folks in the audience can relax.
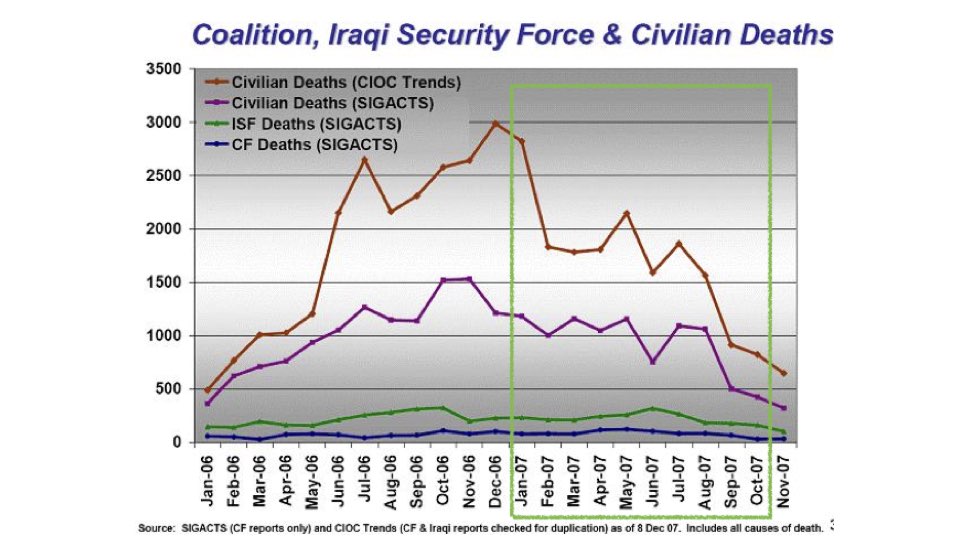
During the height of U.S forces' Iraq surge in 2007, more improvised explosive
devices were killing and maiming soldiers and civilians than ever before. It
was an incredible tragedy that contributed to the uncertainty of the time in
the country.
However, efforts in biometrics were one part of the puzzle that helped to
prevent more attacks, as shown in this picture from General Petraeus' report
to Congress.
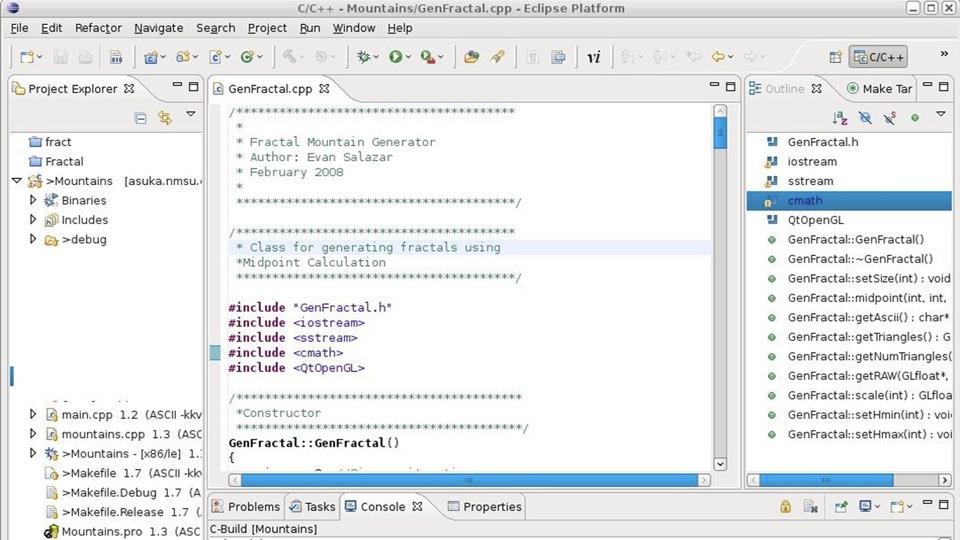
One major challenge with the project was a terrible manual build process that
literally involved clicking buttons in an integrated
development environment to create the
application artifacts. The process was too manual and the end result was that
the latest version of the software took far too long to get into production.
We did not have automated deployments to a development environment, staging
or production.
Our team had to start somewhere, but with a lack of approved tools, all we
had available to us was shell scripts. But shell scripts were a start. We were
able to make a very brittle but repeatable, automated deployment process to
a development environment?
There is still a huge glaring issue though: until the code is actually
deployed to production it does not provide any value for the users.
In this case, we could never fully automate the deployment because we had to
burn to a CD before moving to a physically different computer network. The
team could automate just about everything else though, and that really mattered
for iteration and speed to deployment.
You do the best you can with the tools at your disposal.
What are the tools and concepts behind automating deployments?
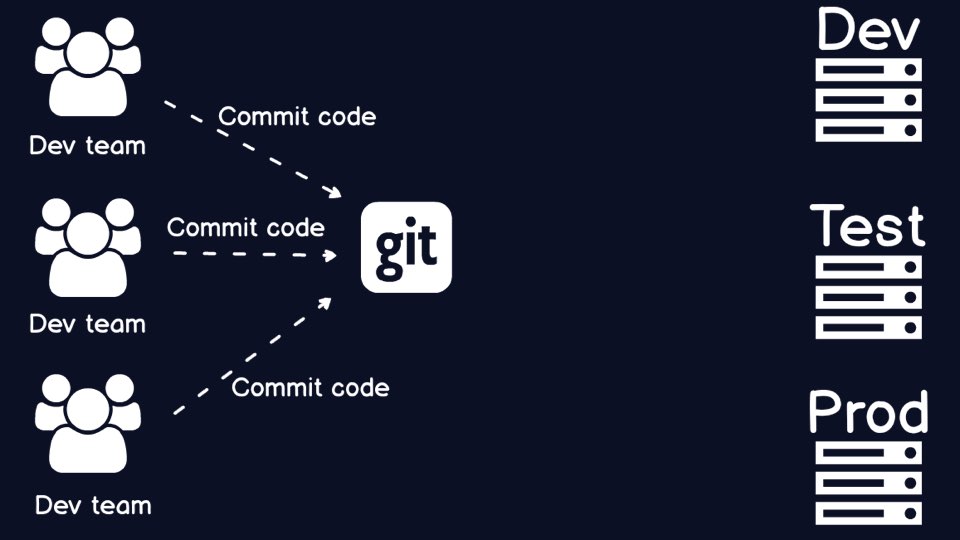
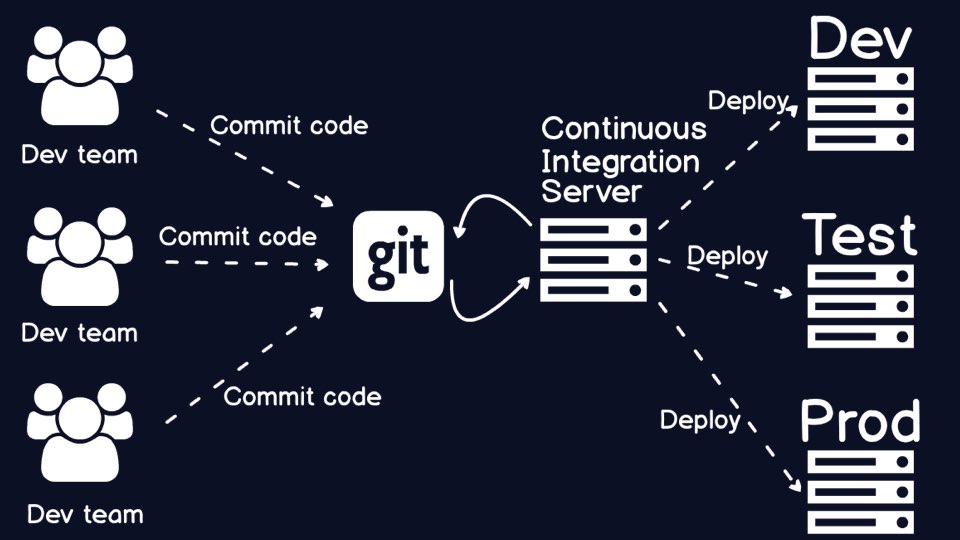
Source code is stored in a
source control (or version control) repository.
Source control is the start of the automation process, but what do we need
to get the code into various environments using a repeatable, automated
process?
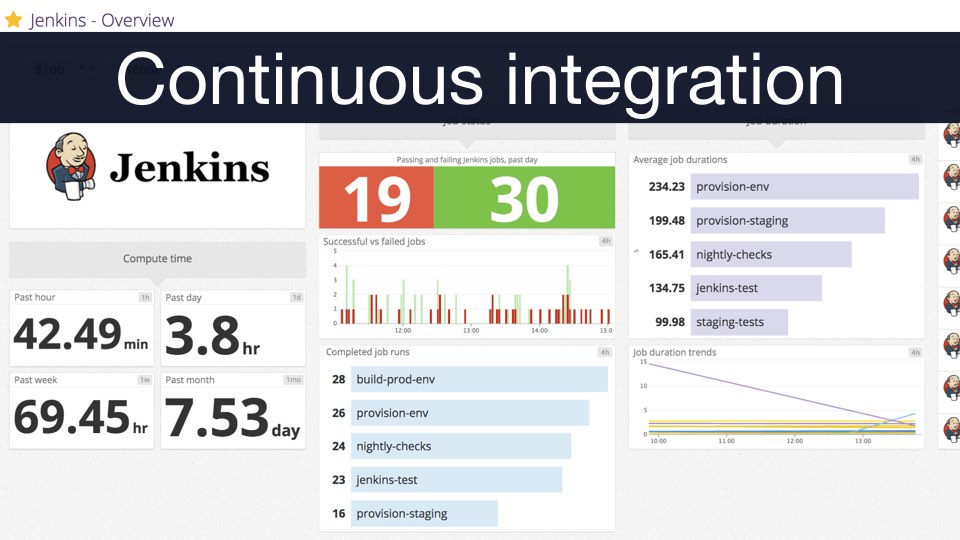
This is where
continuous integration comes
in. Continuous integration takes your code from the version control system,
builds it, tests it and calculate the appropriate code metrics before the
code is deployed to an environment.
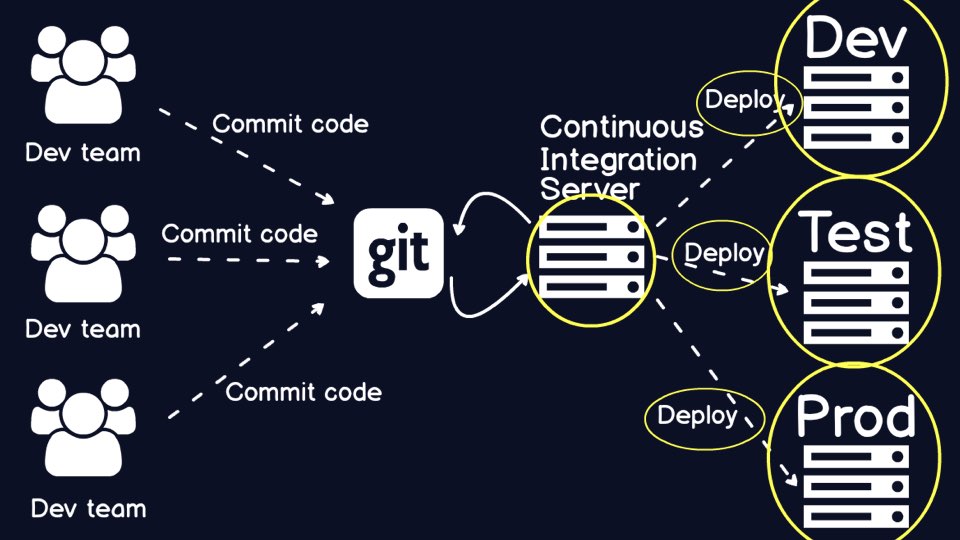
Now we have a continuous integration server hooked up to source control, but
this picture still looks odd.
Technically, continuous integration does not handle the details of the build
and how to configure individual execution environments.
Configuration management tools handle the
setup of application code and environments.
Those two scenarios provided some context for why DevOps and Continuous
Delivery matter to organizations in varying industries. When you have high
performing teams working via the Agile development methodology, you will
encounter a set of problems that are not solvable by doing Agile "better". You
need the tools and concepts we talked about today as well as a slew of other
engineering practices to get that new code into production.
The tools and concepts we covered today were
automated testing,
monitoring, chaos
engineering,
continuous integration and
configuration management.
There are many other practices you will need as you continue your journey.
You can learn about
all of them on Full Stack Python.
That's all for today. My name is Matt Makai
and I'm a software developer at Twilio and the
author of Full Stack Python.
Thank you very much.
Additional resources to learn more about the following topics can be found
on their respective pages: