

万字长文,安培架构解析暨RTX3080核弹头知乎首测
source link: https://zhuanlan.zhihu.com/p/252941017
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
万字长文,安培架构解析暨RTX3080核弹头知乎首测
文:Cloud
编者按:这是我兄弟Cloud原创的RTX3080评测报告。本文无利益相关,属于工作原因接触到的样卡。限于个人水平,差错在所难免,无意当什么KOL,也不标榜客观独立,毕竟这是个人作品,人都有七情六欲,都有喜好厌恶,这不是机器人写的。
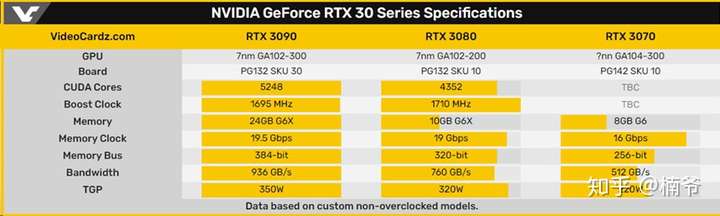
安培在发布之前,可以说是迷雾重重,特别是在发布前一周,VCZ还煞有介事的放出一张规格图,说RTX 3080和2080TI一样是4352SP,而3090也只是多20%,仅仅有5248SP。也就这样一张规格表,还真忽悠到不少人,我都差点上当。当然再仔细想想,3080和2080TI性能差不多,但320W功耗还高差不多1/4,这在工艺换代的情况下,可能吗?
但实际结果,RTX 3090直接将流处理器十分暴力的堆到10496个,相比2080TI翻一番还转个弯,而3080更是良心的采用同级的GA102,虽有屏蔽但流处理器依然是2080TI的两倍,甚至次级核心的RTX 3070都可以将2080TI干翻在地,这在历史上都是十分少见的。 这次NVIDIA在保密方面做的相当出色,在核心规格数据上是没有一点泄露。30系列的规格远远高于大多用户心理预期,我的帖子此时似乎就变成了大型打脸现场。
他们错误估计安培性能的主要原因是经验主义和媒体误导,将RTX2080Ti相对1080Ti的提升当成正常提升幅度,但这样明显是错误的。图灵首先是线宽工艺没有升级,同时硬加光线追踪和Tensor Core,在这样的双重拖累之下才使得性能提升幅度这么小。当然我也不是说经验主义完全不对,而是需要站在更为宏观和系统化的角度来看待分析。
站在更为宏观的历史角度看,NVIDIA大核心GPU规格翻翻是常有的事情,特别是在制程工艺迭代的情况下,基本是必然。制程工艺的升级,使得塞进更多的晶体管成为可能。FP32性能和晶体管增长速度成正比,2080TI FP32提升略微有些跟不上晶体管增长,是因为花费了更多的晶体管去做RT Core和Tensor Core,还有INT32缘故。而RTX3090的FP32性能提升幅度却明显大于晶体管的增长幅度,具体缘由我们会在稍后进行解析。
在理论密度上图灵使用的TSMC 12nm其实就是16nm的优化,密度在2800万晶体管/mm2,而安培游戏卡采用的是三星8nm工艺,三星的8nm其实是10nm的改进工艺,理论密度大概是6100万/mm2。这样的理论密度相比之前的12nm差不多提升了一倍。但相比A100和AMD NAVI采用的台积电7nm 9500万的密度还是有很大的差距。
当然,上面仅仅只是理论密度,实际做出来还是有很大的差别.做个简单的除法,晶体管数量除以核心面积,来看看GPU的实际的晶体管密度。2080TI是2400万,而RTX 3090实际密度是44万,8nm相比12nm密度大概提升了80%。再来看看使用台积电7nm的NAVI 10,也就是5700XT,10300M晶体管,251mm2,这样算下来密度是4100万/mm2。这就是说NVIDIA用落后差不多一代的8nm工艺实现了比NAVI 10 7nm更高的晶体管密度。
NVIDIA的计算卡A100规模相比游戏卡更大,542亿晶体管巨无霸必须使用7nm才做的出来,同时也有足够利润空间可以支撑使用更为昂贵的台积电7nm。但即使如此,A100的核心面积也高达826mm2,还是用晶体管数量除以面积,A100密度就是6500万/mm2,相比NAVI 10更是高了一半。在RTX 30系列上NVIDIA即使是使用不是最先进的工艺,但得益于更高的设计布线水平,还是可以做出比AMD 7nm更高密度,这点还是颇为难能可贵。
再来说安培为什么用三星不那么先进的8nm呢 当然是便宜啦 一个便宜三个爱。既然NVIDIA可以用三星便宜的8nm能够达到AMD使用更贵台积电7nm才能达到的密度,为什么不选便宜的?此外三星的8nm不像台积电7nm 要和apple 高通 华为 AMD抢破头,没什么人用的三星自然也比较好砍价。
意料之外 常理之中的价格
说到砍价,再来说说价格。大众对30系列除了规模误判,另外一个误判就是价格,其实在发布之前,大家都已经对安培的高价做好了心理准备。
但在老黄公布Twice performance same price的时候,B站熬夜昏昏欲睡的大伙似乎都精神了,纷纷刷起真香的弹幕起来。

这次采用GA102大核心的3080和之前采用TU104次级核心的2080同价,24GB显存的3090也“仅”11999,可以说价格远低于预期,当然这个低于预期也有一定期望值管理的结果。但不过有一说一这次NVIDIA的官方指导价汇率3070/3080仅为7.8,3090也仅为8,相比动辄10的intel汇率,老黄这次对于国内玩家可以说是颇为厚道的。
当然,在这个时间也有人就不那么精神了,如手上还持有老卡的玩家,20系列旧卡咸鱼价格顿时雪崩,要知道比2080TI纸面规格更高的RTX3070官价也仅3899,所以8月开9000的2080TI现在9月腰斩挂四五千也不太容易卖不出去。
显卡的价格大头在GPU,其次是显存,而GPU的成本主要由核心面积决定,在大多情况NVIDIA的大核心GPU面积基本都在500mm2左右,这么多年来价格也基本在500-700美元,虽然整体价格有一定上涨,但涨幅甚至远远赶不上CPI。而2080TI由于没有采用新工艺,又加光追 TensorCore,使得核心面积高达754mm2,价格也随核心面积的水涨船高,价格高达999美元其实也是可以理解,其基本不是一个正常策略的产品。RTX 3090核心面积又回归到比较正常的627mm2,但价格高达1499美元,看上去很高,但实际我们也需要注意到,RTX 3090基本是TITAN定位,并且有高达24GB的最新GDDR6X,并且其价格已不像之前TITAN动辄2万那样高不可攀。另外我们还需要记得3090还有个同核心的小弟弟3080也才699美元,这完全可以说是回归了正常的价格区间。当然这样的低价很大程度也得益于三星8nm相对便宜的代工价格。
不仅仅是规模 效率优先的安培
家用机论坛特别喜欢讨论算力多少T,这个其实就是FP32的理论运算能力,我们也来简单算算。其实这个理论运算能力很容易算,直接拿流处理器数量乘以核心频率再乘2就出来了。因此在核心频率差不多的情况下,这个算力就完全和流处理器数量成正比。并且这个算力可以在很大程度反应光栅化的游戏性能水平。RTX 3090/3080流处理器数翻翻,再加名义上的Boost高频率,这样就使得FP32的算力可以轻松翻翻再转个弯。
将在今年年底发布的次世代主机Xbox series X和PS5两者即使是按灰烬频率也仅仅是10T出头,其还是又再次的被RTX3080/3090远远抛离,主要还是两三千的SP还是不能和上万的流处理器的暴力媲美。硬件未发售就落后,弟弟永远还是弟弟。
这次安培最让人惊奇的是NVIDIA是怎么把流处理器堆到10000多的。要搞清楚这个问题要从SM层次说起。
先来回顾下图灵的SM结构,一个图灵的SM有4个块,每个块有16个FP32和16个INT32。INT32单元是在图灵架构时候引入,是用来处理占比大概1/3的INT32任务。
INT32整数任务虽然占比不高,并且相比FP32浮点运算量不大,但在图灵之前的GPU跑INT32还是要浪费宝贵的FP32单元时钟周期来处理。图灵增加了复杂度不高的INT32单元以后,INT32和FP32就可以并行运行。以古墓丽影暗影为例,之前单纯依靠FP32单元切换任务轮流跑FP32和INT32需要100个周期的任务,现在INT32和FP32并行处理就只需要62个周期。增加简化的INT32单元,就可以在增加成本不多的情况下,解放高复杂度FP32的性能,将其从INT32的琐事中解放出来。
而安培在单个块里,有两组16个FP32和一组16个的INT32,但仅有2个数据通路,其中一组FP32独占一组数据通路,另外一组FP32和INT32共享一组,在共享的一组里FP32和IINT32不能同时执行,只能两者选其一。这样的设计在一个时钟周期内,要不跑16+16个FP32操作,要不跑16个FP32操作+16个INT32操作。
这是一个典型的光线追踪单桢的渲染时间,我们可以发现紫色的INT32虽然几乎全程都有参与,但其实占比很少,真正大头还是FP32。之前安培的FP32和INT32单元数量是1:1的比例,这样其实INT32的利用率并不高。而安培这样的一组FP32和INT32共享数据通路的设计,GPU可以依据应用需求,自由调节工作模式,在典型的游戏应用,可以在更多的块跑FP32,而仅用少数的块跑INT32。这样的设计虽然并不能使得所有的FP32都能同时工作,但可以在芯片复杂度提高不太多的情况下,大幅提升占比最大的FP32的性能,而次要的INT32也可以按需分配满足需求。使用不高成本提升最为经常性工作的效率,无疑是很聪明的做法。
由于FP32规模翻倍,也使得对缓存结构带来更高需求。安培SM里的L1缓存从图灵的96KB提升到128KB,单周期传输容量从图灵的32B提升到64B,这样RTX 3080 L1带宽就高达219GB/S,而之前的2080S仅为116GB/S,差不多翻番了。
再来说说反传统性能部分。安培的RT Core相比图灵增加了一组三角形求交模块,然后添加了全新的三角形位置内插模块。特别是后者可以在求交计算时候预判目标三角形的位置来提升求交计算的效能,这样可以明显改善运动模糊场景的光追性能表现。
当然 光线的模拟追踪计算并不是RTX的全部,后续还有降噪的问题,RTX显卡是依靠独立的Tensor Core硬件来实现,而安培配备的是第三代的Tensor Core处理器。
之前图灵的Tensor Core在处理FP16的情况下,可以看成4×4和4×4的矩阵,一共64个乘法单元核心,但到了RTX 30的安培,就变成了8×4和4×4的矩阵,这样就有128个FP16乘法单元核心。单个Tensor Core的性能实现了翻倍。
当然,除了单个Tensor Core规模的翻倍,安培的第三代Tensor Core在算法上也有很大的优化,其主要改进是稀疏化,稀疏化打个比方, 就是做模拟试题,不做全套,选择性的挑着有代表性的做,这样可以节约时间,但最终又可以得到八九不离十的训练效果。稀疏化就是通过这样取巧的方式来提升效能。
安培单个Tensor Core在未稀疏化的情况下,一个周期可以进行128次操作,是图灵的2倍,在稀疏化以后性能是图灵的4倍。虽然安培的单个SM的Tensor Core数量从图灵的8个减到4个。但在未稀疏化的情况下还是可以维持之前的性能,而在进行稀疏化之后,安培相比图灵还是性能翻翻了。并且这个还是单个SM的情况,我们还是需要考虑安培比同级别的图灵有更多的SM。
游戏中的每一帧都是各个部分分工协作完成,黄色的FP32负责传统光栅化,绿色的RT Core进行光线追踪的模拟计算,紫色的Tensor Core用来降噪,当然也可以用来处理DLSS,用较低分辨率这样不仅可以大幅提升光栅化的性能,还可以大幅降低光线的计算需求。以重返德军总部为例,没有Tensor Core参与大概只有50FPS,而通过Tensor Core来进行降噪和DLSS,就可以达到80FPS以上的性能。
从Xbox Series X的PDF初探RDNA2的光线追踪部分,其一个CU在一个时钟周期可以进行4次纹理或者光线操作,先不说其具体理论性能,需要注意的是“OR”,就是说纹理单元和光线追踪并不能同时进行,贴图和光线追踪会互相挤占性能。此外也没类似Tensor Core的专用单元,只能使用FP32来进行后期降噪,这也将挤占传统的光栅化性能。因此RNDA 2的光追性能现在看并不太乐观。
再来看看整体架构。满规格的TU102有6个GPC,每个GPC有12个SM,总计有72个SM。单个SM有64个SP。RTX2080TI实际屏蔽了4个SM,剩下的68个SM就是4352个SP。
而GA102有7个GPC,每个GPC和图灵一样也是12个SM,7个GPC满规格就84个SM,但实际RTX3090屏蔽了2组SM,就有82组。单组SM安培从图灵的64个FP32翻倍到了128个,这样总计就有10496个FP32流处理器。此外每个GPC有一个光栅化引擎,里面有2个区域,每个区域有8个ROP,这样一个GPC有16个ROP,7个GPC一共有112个ROP。
这个是GA102的核心,我再这胡猜乱画的分布,红色的是7个GPC 蓝色是12个32bit内存控制器,黄色的是ROP,紫色的是L2缓存,绿色的是PCIE NVLINK等IO部分。
而RTX 3080屏蔽一组完整的GPC加4个SM,这样就是68个SM,这个SM数字和RTX 2080Ti一样。但单个SM的FP32从64翻翻到128,那整体的SP数量也从4352翻翻到8704个。完整的GA102有12组32bit的内存控制器,合计384bit,RTX3080屏蔽了2组,这样就剩下320Bit。此外RTX 3080还屏蔽了NVLink,使得其不具备SLI的能力。
其实这次安培的市场布局,对于老玩家而言,很容易让人想起14年前的G80,当时旗舰8800GTX是384bit 768MB,下面是320bit 320MB/640MB的8800GTS,这次3080 10GB规格完全对应8800GTS 320MB,当然不出意外稍后还会发布一个3080 20GB,那规格布局就一模一样了。
这次显存频率从原有的14Gbps提升到19.5Gbps,是因为采用了全新的美光GDDR6X,其相比之前的内存,一个周期高低电压电平传送1个bit 2个状态,变成4个0.25v间隔的电压位的PAM4信号,这样在一个时钟周期就可以传送2个bit 4个状态,这样一个时钟周期的传输速率就翻倍了,这样的差别比较像SSD SLC和MLC的差别。
从GPU-Z 看,GDDR6的实际工作频率需要在频率上x8,而GDDR6X则需要X16,1188×16就是19GHz,GDDR6虽然等效频率很高,但实际工作频率反而很低,因此依然有比较大的超频空间,上到21GHz还是很轻松的,不过对于RTX 3080显存带宽并不是瓶颈,超显存并不能带来明显的性能提升。
安培除了提升图形性能和深度学习性能,现在还狗拿耗子帮忙提升了下磁盘性能。现在GPU读取游戏数据,需要从SSD读取,通过PCIE总线,再到CPU,写入内存,再从内存读到CPU,再次通过PCIE传送到GPU,最后还需要写入显存,这样绕一大圈才完成操作。上面这个还是理想情况,实际情况是大多游戏为了控制容量,都会采用压缩数据,这样在到达内存之后,CPU需要再次读取解压再写入内存,还需要多一个来回,并且这个解压对于处理器的负载很高,甚至需要使用24个核心。
而RTX 30系列支持RTX IO,可以无需CPU和内存的干预,SSD的数据可以直接由PCIE总线传到GPU,并完成解压写入显存。这样大大简化了流程步骤,提升了性能,同时大幅降低了处理器的使用率。
现在3A游戏越来越多是大沙盘,视野距离越来越大,同屏物件也越来越多,因此RTX IO这样技术可以以串流的方式,无需CPU干预必然可以大幅提升游戏体验。当然为了实现RTX IO,还需要系统和游戏的支持,Windows 10估计需要等到下版甚至下下版才会实装Direct Stroage。而游戏支持方面,大多3A都是要登录Xbox series X,游戏支持方面应该也应该问题不大,估计年底以后新发布的大多数3A都会支持。
.华硕电竞特工TUF RTX 3080 GAMING O10G赏析
前面空对空讲了半天产品逻辑和架构,再来看看RTX 3080的实物。我们本次RTX 3080测试卡是由华硕提供的电竞特工TUF RTX 3080 GAMING O10G.。这代RTX 3080由于功耗高达320W,TUF GAMING采用的是三风扇设计。
不过整体长度并没太夸张,仅仅为30cm,一般尺寸的机箱就可以装下。
供电方面采用传统双8pin的设计,而没有采用Founder Edition的12pin供电接口。散热器的厚度大概是2.7槽位,安装时候需要考虑主板其他设备的空间问题。
显卡的PCB并延未续到整个散热器长度,GPU背面有个X字形的金属支架。
背板前端有一部分镂空,可以让前部风扇风道更为通畅而无阻碍。此外背板后面有个小开关,可以在性能模式和静音模式两个BIOS之间切换,两个BIOS的频率和风扇控制策略存在一些差别。
这次TUF RTX 3080 GAMING O10G也相续使用了之前STRIX20系列的轴流技术风扇,外部的边框一方面可以使得气流更有导向型,能够更好的通过散热片,风压更大,另外一方面也可以使得扇叶结构更为坚固,动平衡更好,避免结构不稳定造成的噪音加大。此外风扇支持智能启停,在 GPU温度低于55度的时候,风扇是停转的。
从前部看TUF RTX 3080 GAMING O10G有6热管,相比STRIX 2080Ti的5热管多一根。此外背板延续到顶端还有个弯折的结构,上面有2个螺丝孔,这应该是给系统集成商固定显卡支架用,这种高端自重极大,仅仅依靠PCIE和后PCI螺丝是固定不住的,不做额外的多点结构加固是根本不能装机发货的。

之前STRIX的ID设计从1080TI用到2080Ti,略微有点审美疲劳,再就其一直是单色AURA同步,而这次TUF RTX 3080 GAMING O10G终于支持可寻址,能够展现更为细腻的流光溢彩的过渡变化,玩家可以通过军火库软件同主板和其他支持AURA的设备进行整体同步。
TUF RTX 3080 O10G提供了3组DP和2组HDMI,原有RTX20的VirtualLink口被放弃。
30系列的HDMI从2.0升级到了2.1,不仅可以提供更高的带宽上到更高的分辨率和刷新率,还可以支持DSC数字压缩串流技术,在分辨率刷新率需求带宽超过HDMI带宽的时候,如8K 60Hz或者120Hz的时候,可以继续用压缩提供支持。而DP依旧是1.4,并未升级到2.0,DP 1.4相比HDMI 2.1不能在不压缩的情况下实现4K 144 4:4:4,除非显示器支持DSC,如ROG新款的XG27UQ。后面就是拆解部分。
散热器在拆下之后,我们更可以感觉TUF RTX 3080 GAMING的散热规模的巨大,6根热管横穿整个散热本体。
在主散热器之下,还有独立的显存散热器,由热管串联,并且鰭片有一定高度,可以让风扇下压转向气流吹过,并且这样独立的散热片设计使得显存不会被核心热量所煎熬。
再来看看核心本体,RTX 3080的核心GA102-200-KD-A1,是台湾生产。什么不应该是三星韩国的么? 其实这并不奇怪,之前有些核心就韩国生产晶圆再在台湾切割封装。GA102核心面积为627mm2,明显比之前TU102要小一圈。另外我们还可以发现核心基板四角有四个白色的贴胶,这个可以进一步加强核心和PCB的连接强度,能够在一定程度减少GPU脱焊的情况发生。核心周围一共有10颗镁光的GDDR6X颗粒,总计320bit.GDDR6X颗粒频率为19GHz,经测试可以超频到21GHz之上。
由于RTX 3080的功耗高达320W,TUF RTX 3080 O10G供电规模也是前所未有的夸张,核心16相,显存4相,一共20相,并且华硕采用的“超合金”供电,散热效果更好温度更低。 此外华硕显卡的原件是通过全自动化制造工艺焊接到PCB上,这样可以杜绝人工焊接出错的风险,品质更为可靠。并且在下线之后,所有显卡要经过144小时的老化测试没有Fail才能出厂交付给花钱的你。
我们本次测试平台如上,基本是华硕+浦科特全家桶,处理器也超频到全核5GHz.有人说游戏性能内存要高频,我也直接上了TT的 DDR4 4400,好让挑剔党没话说。SSD本来是一个浦科特M9P Plus 512GB,但后来发现装不下测试游戏,又加了张PCIE的M9PEY+。
为了测试PCIE 4.0的带宽延展性和全面战争特洛伊的性能,我们也准备了Ryzen 9 3950X+华硕TUF B550M GAMING的配置,内存依然是使用的是TT DDR4 4400,不过收到FCLK限制,运行在3800MHz频率。
游戏性能测试
由于我并不洽NV的饭,因此我在选择测试项目上并不用遵循NVIDIA的Review Guide,而可以更多综合从技术代表性和流行性上进行考虑,也不用顾及The Way和Gaming Evolved游戏阵营的选择问题,只是选择在目标用户中存在的真实应用。
绝地求生相比17-18年巅峰时刻已经凉了不少,但实际还是找不出一个流行程度比吃鸡更好的射击类电竞游戏。大多玩家吃鸡一般不会设置全最高画质,而是一般设置成纹理、视野距离和抗锯齿最高,其他最低,这样的设置能够在画质和性能之间能够较好的平衡,同时画面也较为干净方便索敌。甚至还有一些玩家设置的更低。测试我们使用游戏回放erangel海岛图过程,使用Fraps记录游戏最后5分钟的平均/最低FPS,最后的决赛圈有大量的战斗,并且伴随大量的手雷烟雾弹使用,可以说是相对极端的游戏负载。
我们首先使用纹理、视野距离和抗锯齿最高,其他最低 3MAX设置进行测试1440p分辨率。但我们发现2080ti和3080性能没什么区别, 在绝大多数时间GPU占用比较低,这说明在这样设置情况下,性能瓶颈在CPU,GPU的性能收到了限制。甚至出现了1440p 3max 2080ti平均FPS比3080高的情况,但我们也注意到大量烟雾弹的极端情况,GPU还是出现了短时间的满负载,这个时候3080比2080ti的FPS要高40FPS,稳定性还是好得多。
为了完全发挥性能,我们也使用4K全最高设置进行测试。在4K全开的情况下,3080的平均帧数也接近120FPS,相比2080ti提升了25%。另外在4K 3MAX的情况下,GPU也可以满载,平均帧数更是高达177FPS,最低FPS相比2080ti也提高了1/3,这样的性能对于ROG PG27UQ这种4K 144显示器玩家而言还是很有意义的。
地平线 零之曙光
索尼第一方的4A游戏地平线 零之曙光已经登陆PC平台,其由SONY第一方的游击队工作室开发,采用的是自家的Decima引擎。Decima是在PS4的护航大作杀戮地带暗影中被首次使用,后续小岛秀夫的死亡搁浅也是采用的这个引擎,但小岛工作室作为第三方使用,在引擎使用上并没有全部发挥实力,如植被就没有AO效果。
PC版的地平线 零之曙光相比PS4 Pro版,解除了FPS的限制,增强了动态植被和反射效果。我们视频演示的是4K分辨率全特效的对比测试,使用的是游戏自带的Benchmark。
地平线 零之曙光RTX 3080相比2080TI提升了30%,特别是4K分辨率,从57提升到75,从基本可玩提升到流畅。但需要注意的是地平线4K分辨率显存占用超过了10GB而刚好不到11GB,就说3080爆了显存而2080ti没有,我们可以到注意FPS曲线2080ti的更为平滑,而3080有突起,特别是在场景剧烈变化的时候。
全面战争特洛伊
CA推出的全战三国由于中国题材在国内大获成功,而其续作全战特洛伊又将战场带回到古欧洲的经典时代,讲述特洛伊木马屠城的故事。本游戏是intel赞助游戏,针对多核心有极好的优化,最多可以充分利用16核心32线程,游戏性能会随核心数量线性增加。但这样特洛伊在核心数更多的AMD Ryzen 9上面有更佳的性能表现,我们甚至可以说intel是为他人做了嫁衣。因此我们在特洛伊的测试上并没有采用5GHz的10900K平台,而是使用的Ryzen 9 3950X。具体测试我们使用的是游戏自带的战场Benchmark,设置的是极高画质。
在1080p分辨率下,即使是使用的16核心的3950x CPU在大部分时间都出现了瓶颈,使得3080和2080ti的差距拉不开。而到2K和4K分辨率下才拉开距离,在4K分辨率下,虽然3080也没能够达到平均60FPS,但对于一个同屏万人的慢节奏游戏,这个FPS也是够用的,即使联网对战,我也相信对面的玩家FPS肯定比用3080的你更低。
幽灵行动断点
幽灵行动断点在商业上并不成功,典型的ubi公式化沙盘的游戏性和过于膨胀的数值系统在发售时候也备受玩家非议,但游戏随着内容更新和完善,也慢慢的挽回了一些口碑。我们设置超高画质使用游戏自带的Benchmark进行测试。
幽灵行动有极大的多样化场景,并且还有不错的细节精度,在4k分辨率超高画质下,2080ti的性能不能满足需求,而3080平均FPS超过了60,但在场景复杂或者激烈交火的情况下,依然会有掉帧,不能完全满足心里需求。这个时候你有两个选择,一是稍微降低一点画质,二是继续加钱上RTX 3090。
荒野大镖客救赎2
荒野大镖客救赎2可以说是让我们提前看到了下个世代的游戏,其画面表现在已经发售的开放世界游戏中当之无愧的最强,并且没有之一。在巨大的开放世界沙盘依然提供了足够精细的细节,并且全动态的光照和天气系统,将19世纪末的美国再现得栩栩如生。我们设置DX12质量优先,常规画面设置最高,高级设置默认的设定,使用游戏自带的Benchmark进行测试。
荒野大镖客2救赎有极高的系统需求,之前2080ti在4k分辨率下,大概就40FPS水平,虽然不能说不能玩,但至少是玩不爽,而RTX 3080着可以达到60FPS的水平,对于一个主要用手柄有自动瞄准的游戏,这样的FPS可以正常的体验游戏了。
古墓丽影暗影
古墓丽影暗影是最早支持RTX的游戏之一,后续又增加了对DLSS的支持。我们设定最高画质,使用游戏自带的Benchmark进行测试。古墓丽影暗影的RTX作用主要是用于强化阴影,这在动态光源场景对于画面的真实度有比较明显的改善。
RTX 3080在4K原生分辨率下性能依然不能接受,但开启DLSS以后,3080性能提升了38%,最低FPS也接近60FPS,对于动作游戏而言是可玩了。我们需要注意的是2080Ti DLSS的提升幅度要大于3080,这个和起点低有关系。
地铁离去可以说是这些年来最为优秀的单机剧情向FPS,其优秀不仅仅是剧情,人物科幻还有关卡设计,其优秀的画面表现也为其增彩不少,地铁离去支持RTX,RTX主要是强化阴影的AO部分,使用RTX AO来模拟全局光照漫反射和遮蔽。我们设定最高画质,使用游戏自带的Benchmark进行测试。
地铁的RTXRTX3080在4k分辨率下相比2080ti提升了35%,但依然不能流畅运行,这个时候就得靠DLSS出场了,在开启dlss后,3080性能提升了36%,在大多情况都可以跑在60fps的水平。古墓和地铁这2个3A RTX游戏情况差不多,4K+光追用通常首发都不能搞定,但在开启Dlss之后就可以流畅运行了,这是由量变到质变的典型。
德军总部新血脉
但古墓和地铁都是采用的老版DLSS,我们又增加了德军总部新血脉的测试,德军总部并非DirectX游戏,而是Vulkan。这个游戏RTX主要是展现反射面,整个游戏差不多有1/3的材质都是反射面。游戏我们采用最高画质测试河滨场景。
虽然3080在不开启DLSS的情况下,也可以稳定在60FPS以上,但在DLSS质量优先的情况下,3080的性能相比SMAA提升了42%,平均帧数超过了100,可以说是十分的流畅。如果开启性能模式,就可以在提供DLSS 1.0相同水平的画质的情况下,提供更高性能。
性能与需求
我们测试的8个游戏,性能提升最大的是德军总部,高达32%,当然这个提升幅度主要是DLSS 2.0加成的结果,而提升垫底的反而也是古墓和地铁这2个RTX+DLSS游戏。这2个游戏由于2080Ti的基数更低,在开启DLSS之后光追需要处理的光线数也大幅下降,使得瓶颈在一定程度上缓解,因此2080ti DLSS收益更大在开启DLSS之后,2080ti和3080的差距反而变小了。整体而言8个游戏平均性能提升了26.6%,但需要注意的是,我们对比的RTX 2080Ti是高频版本的ROG STRIX GAMING O11G,如果是对比的普通版本,这个差距还会更大一些。再者,现在是首发,驱动和游戏支持都不太完善,再经过一段时间的优化之后,RTX 3080相对2080Ti有个30多甚至40%的性能优势也是很正常的。
但在RTX 3080/3090公布之后,玩家对于性能还是有过高的期待,这样的期待一方面是由流处理器数量激增引起的,另一方面NVIDIA宣传的TWICE THE PERFORMANCE OF 2080也有一定影响。这个幅度虽然低于之前流处理器差距产生的预期(至于为什么游戏性能提升幅度小于流处理器数量的提升,可以看我前面架构的FP32/INT32的部分就会明白),但对于不少游戏,如荒野大镖客、古墓、幽灵行动,地铁,都是由量变到质变,从2080Ti的单卡4K不可玩到3080的单卡4K可玩,就从这一点上开说对于玩家就有很大的吸引力,并且这样的质变提升还是在3080价格相比2080Ti下降几乎一小半的情况下实现的,因此作为玩家也没什么好抱怨的,买买买就完事。
有不少人会觉得3080的10GB显存太少,经过我们测试的游戏,现在大部分游戏在4K全开的情况下,还是不到10GB,当然这个也和游戏优化有关系,地平线和使命召唤就是无脑塞纹理的典型,突破10GB,虽然显存需求明显增高,但画面上却没有明显收益。再就是生化危机3重制版开超采样,这样会用到16GB以上,当然超采样本质就是8K甚至更高分辨率,并不属于正常使用情况,就不再讨论。
那这样看来10GB就足够,更多是浪费么?
其实不然,游戏的画面提升和显存需求的提升并不是线性的,而是周期性阶梯状跃进。以土豆公司年货刺客信条系列为例。在大革命这代显存需求呈现爆发性的翻翻增长,从2GB增加到4GB。而在之前和之后的阶段显存需求的增长都还比较稳定。虽然PC的显卡基本2年一代,但游戏开发商开发游戏首先是要兼顾销量最高的家用机平台,但家用机平台长期孱弱的性能一直都拖累游戏画面水平的发展。而游戏机换代周期很长,在同代周期内,开发商大概1-2年就基本可以吃透机能,画面水平和硬件需求也会维持稳定,而主机平台升级换代就是触发点,可以大幅度的提升游戏画面和硬件需求。
游戏画面换代,很关键的就是材质纹理分辨率的提升,材质纹理分辨率的提升对于观感改善十分明显,我们可以发现本世代刺客信条大革命相比上一世代叛变有翻天覆地的变化,甚至让我们很难相信这2个是同一年发售的游戏,这样的改变很大程度就是得益于材质分辨率的提升,而材质的提升就需要更大的显存。
而现在又恰巧处于PS5和Xbox series X发布的前夕,新一代的主机提升的不仅是GPU的Gflops,还有更大的RAM。可以预见,由于拖后退的家用机下限提高,在后面2年时间游戏画面水平和显存需求也都将大幅提高。次世代的刺客信条英灵殿已经公布,其画面将有怎么样的进化,硬件和显存需求将会有怎么样的提升,我们将拭目以待。因此从长远看,更大的显存应该还是有必要的。
虚幻5可以说是树立了次世代画面的标杆,其重点是使用Nanite技术提升多边形表现,而光照采用Lumen技术,而非DXR,但却提供了优于现在所有RTX 3A游戏的光照视觉表现。
但这并不是说光线追踪没有价值,我们从这样30发布的大理石球demo就可以看出,其完全抛弃了传统的光栅化,而完全依靠光线追踪来实现,展现出了无比真实的画面。
甚至失踪多年的PHK在看完这个Demo后兴奋的评价道:
大理石球的RTX Demo 到目前为止,是NV做的最漂亮的DEMO。
虽然这个Demo仅仅是个4399,但其还是展现了光线追踪的美好未来,虽然现在的商业游戏的RTX仅仅是光栅化之上的表层特效,但必须持之以恒,完全的光线追踪这个图形学上的圣杯才有可能实现。
3DMark和体验
RTX 3080是nvidia第一块PCIE 4.0的桌面GPU(前面还有计算卡A100和笔记本亮机卡MX350),PCIE 4.0的带宽相比3.0翻了一倍。因此就有人会问 我的10900K+Z490不支持PCIE 4.0会不会拖后腿啊 我是不是应该换AMD啊。
我们使用3Dmark的PCIE带宽测试工具测试,RTX 3080在4.0下带宽的确翻翻,但3Dmark得分基本没有变化,基本就是误差范围,实际游戏也差不多,甚至在生化危机3重制版150%超采样也没明显区别。因此现在还在用3.0平台的朋友现在不用纠结这个问题,要换也应该稍微晚点,Zen 3和Rocket Lake都不远了。
我们使用3Dmark的Port Royal测试GPU的核心频率稳定性、功耗和温度。这个测试时间虽然不长,但负载很高,需要重度用到GPU的几乎所有单元。
ROG STRIX RTX2080TI GAMING 默认功耗在250-260W ,而TUF RTX 3080 O10G GAMING的功耗在340W-350W,这个功耗是高于公版的320W,基本是RTX 3090的功耗水平,并且TUF RTX 3080 O10G GAMING并没有像其他品牌的部分型号锁定了功率上限,我们可以通过软件进一步拉高,更高的功率上限使得GPU有更大的空间可以跑在更高的频率。
ROG STRIX RTX2080TI GAMING的实际Boost频率大概在1850MHz左右,而TUF RTX 3080 GAMING实际运行频率在1930MHz,大概要高于80MHz,从频率看三星8nm的高频性能还是不错的。
我们计算了芯片的每mm2的功耗,8nm的GA102相比12nm的TU102提高了61.7%,更高的功率密度给散热带来了更大的挑战,那TUF RTX 3080 GAMING的散热温度表现怎么样呢?
在25度的环境温度的情况下,TUF RTX 3080 GAMING的待机温度更高,有40度,运行负载之后温度上升也更快,但最后在62-63度稳定,最高温度甚至比STRIX RTX 2080TI GAMING更低,这在功耗从260W提升到350W以后还能保持低温这十分难得。当然能量是守恒的, TUF RTX 3080 GAMING镜面贴合的巨大散热器有能力将热量从核心带出,但这个热量还是会存在你的机箱里,如果GPU和环境温差减小,就会影响散热效能,因此我们建议大家选择风道好的机箱,并且装满系统风扇。
内容创作测试
显卡除了是游戏卡,在一定程度也是可以创造价值的生产工具,因此除开游戏,我们也测试内容创作方面的性能,主要是测试3D设计和视频处理两个方面。
Specviewperf 13是可以测试3ds Max、CATIA、Maya、Solidworks等专业软件的标准测试程序,虽然其负载相比实际环境要轻,但还是可以反应不同GPU的相对性能作为参考。整体而言RTX 3080相比RTX 2080TI正在大多测试项目有些优势,但优势并不如游戏中那样明显,甚至NX8和Solidworks性能还出现了下降,这个应该还是和首发驱动优化存在关系。另外我们还加入了TITAN RTX的测试。由于 TITAN RTX在驱动层面有一些QUADRO专业卡的特性,在能源和工业一些针对QUADRO特性进行优化的应用优势明显,这个也是TITAN高价的价值,不知道后面的RTX 3090是否也有专业卡的特性。
Adobe Media Encoder是Aodbe的编码器程序,其也被集成在PR之中,我们设置CUDA的水银加速,通过脚本处理4个视频,对其进行拼接滤镜等后处理并导出,测试RTX 2080TI和3080的完成时间,耗时越短越好。RTX 3080 Adobe编码器性能相比2080TI大概提升了7-10%,有一定的提升,但并不算太明显。
架构效能才是核心竞争力
虽然大家对安培的第一印象就是10000流处理器的暴力,但实际上从架构细节上看,安培是力中有巧。FP32和INT32的共享数据通路的方式,使得SM在规模扩大不多的情况下实现流处理器翻翻。Tensor Core的改进也是,通过稀疏化的方式,大大简化了训练的过程,而达到提升性能的目的。
NVIDIA和AMD的竞争其实架构效率的竞争,而不是绝对性能的竞争。效率高就意味着可以用相同成本实现更高性能,或者用更低成本实现相同性能。只有架构效率有优势,才有产品策略和价格策略的主动权。AN对位竞争的公版产品对比,有个简单规律,那家的公版看上去寒蝉那个就是市场的胜利者。在架构效率上落后的一方,就只能扩大芯片规模来获取性能上的平衡,但芯片规模大了,功耗就大,就必须强化的供电和散热,这样看上去就豪华了,再或者冒险采用更激进的工艺。但无论是走堆料还是工艺激进线路,结果都是成本高,成本高就会导致在价格策略上就没主动权,市场就必然玩不过。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK