

boltdb 源码分析
source link: https://youjiali1995.github.io/storage/boltdb/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

boltdb 源码分析
更新: CMU15-445/645 小结
boltdb 是 go 语言实现的嵌入式 K/V 数据库,核心代码在4000行左右,容易学习。
boltdb 有如下性质:
K/V型存储,使用B+树索引。- 支持
namespace,每对K/V存放在一个Bucket下,不同Bucket可以有相同的key,支持嵌套的Bucket。 - 支持事务(
ACID),使用MVCC和COW,允许多个读事务和一个写事务并发执行,但是读事务有可能会阻塞写事务,适合读多写少的场景。
下面这段代码实现了最基本的功能:
- 打开文件
my.db对应的数据库; - 开始一个写事务
- 在该事务中创建
Bucket:MyBucket; - 在
MyBucket中写入key: foo, value: bar; - 提交事务。
// Open the my.db data file in your current directory.
// It will be created if it doesn't exist.
db, err := bolt.Open("my.db", 0600, nil)
if err != nil {
log.Fatal(err)
}
defer db.Close()
// Start a writable transaction.
tx, err := db.Begin(true)
if err != nil {
return err
}
defer tx.Rollback()
// Use the transaction...
bucket, err := tx.CreateBucket([]byte("MyBucket"))
if err != nil {
return err
}
bucket.Put([]byte("foo"), []byte("bar"))
// Commit the transaction and check for error.
if err := tx.Commit(); err != nil {
return err
}
概括来讲,boltdb 的存储有如下特点:
- 每个
db对应一个文件,文件按照page size(一般为4096 Bytes) 划分为page:- 前2个
page保存metadata; - 特殊的
page保存freelist,存放空闲page的id; - 剩下的
page构成一个B+树结构。
- 前2个
- 每个
Bucket是一个完整的B+树; B+树的每个结点对应一个或多个连续的page;- 因为内存比磁盘小,一般会实现
page cache缓存部分page,比如使用LRU算法。boltdb没有实现,而是使用mmap()创建共享、只读的文件映射并调用madvise(MADV_RANDOM),由操作系统 管理page cache; - 没有
WAL,事务中所有操作都在内存中进行,只有commit时才会写到磁盘; commit时会将dirty page写入新的page,从而保证同时读的事务不受到影响。
B+ 树索引
boltdb 中典型的 B+ 树结构如下:
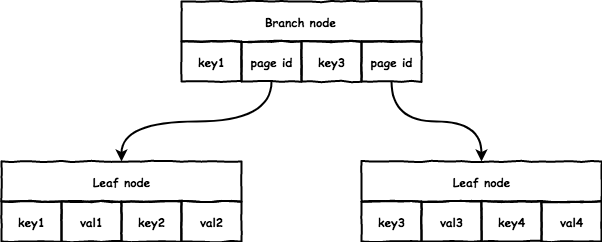
它的实现和通常意义上的 B+ 树有些不同,结点上的 key 和 val 个数是相同的,而一般 B+ 树 val 会比 key 多一个:
branch: 每对key/val指向一个子节点,key是子节点的起始range,val存放子节点的page id;leaf: 每对key/val存放数据,没有指针指向sibiling node;通常的B+树多出的一个指针会指向sibiling node。
boltdb 中有 3 个结构和 B+ 树密切相关:
page: 大小一般为4096 bytes,对应文件里的每个page,读写文件都是以page为单位。node:B+树的单个结点,访问结点时首先将page的内容转换为内存中的node,每个node对应一个或多个连续的page。Bucket: 每个Bucket都是一个完整的B+树,所有操作都是针对Bucket。
一个典型的查找过程如下:
- 首先找到
Bucket的根节点,也就是B+树的根节点的page id; - 读取对应的
page,转化为内存中的node; - 若是
branch node,则根据key查找合适的子节点的page id; - 重复2、3直到找到
leaf node,返回node中对应的val。
文件被组织为 page size(4096 bytes) 的 page,对应的结构如下:
type page struct {
id pgid // page id
flags uint16 // 区分不同类型的 page
count uint16 // page data 中的数据个数
overflow uint32 // 若单个 page 大小不够,会分配多个 page
ptr uintptr // 存放 page data 的起始地址
}
ptr 是保存数据的起始地址,不同类型 page 保存的数据格式也不同,共有4种 page, 通过 flags 区分:
meta page: 存放db的meta data。freelist page: 存放db的空闲page。branch page: 存放branch node的数据。leaf page: 存放leaf node的数据。
磁盘上的格式和结构体相同,将数据写入文件会首先分配一个 page,然后设置 page header 和 page data:

boltdb 直接将 page 结构体的二进制格式写入文件,避免了序列化和反序列化的开销:
- 写的时候直接将需要写入的结构体转换为
byte数组写入文件:ptr := (*[maxAllocSize]byte)(unsafe.Pointer(p)) - 读的时候直接将
byte数组转换为对应结构体即可:// page retrieves a page reference from the mmap based on the current page size. func (db *DB) page(id pgid) *page { pos := id * pgid(db.pageSize) return (*page)(unsafe.Pointer(&db.data[pos])) } - 需要注意只能转换为数组而不是
slice,否则会受到sliceHeader的影响。
page cache
boltdb 没有实现 page cache,而是调用 mmap() 将整个文件映射进来,并调用 madvise(MADV_RANDOM) 由操作系统管理 page cache,后续对磁盘上文件的所有读操作直接读取 db.data 即可,简化了实现:
// mmap memory maps a DB's data file.
func mmap(db *DB, sz int) error {
// Map the data file to memory.
b, err := syscall.Mmap(int(db.file.Fd()), 0, sz, syscall.PROT_READ, syscall.MAP_SHARED|db.MmapFlags)
if err != nil {
return err
}
// Advise the kernel that the mmap is accessed randomly.
if err := madvise(b, syscall.MADV_RANDOM); err != nil {
return fmt.Errorf("madvise: %s", err)
}
// Save the original byte slice and convert to a byte array pointer.
db.dataref = b
db.data = (*[maxMapSize]byte)(unsafe.Pointer(&b[0]))
db.datasz = sz
return nil
}
leaf node 在文件中的格式如下:
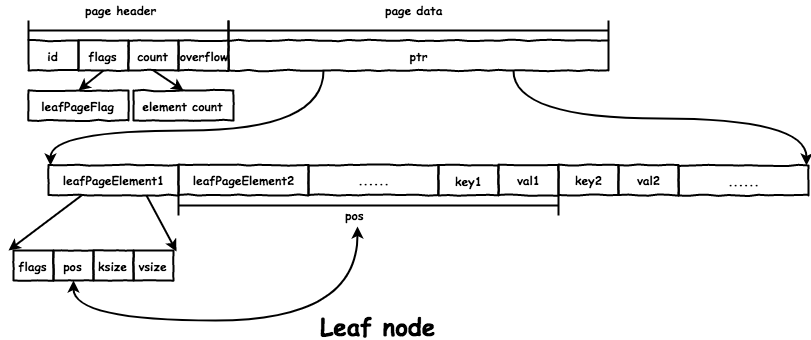
node 的数据存放在 page.ptr 的位置:
- 首先是所有的
leafPageElement:// leafPageElement represents a node on a leaf page. type leafPageElement struct { flags uint32 // 通过 flags 区分 subbucket 和普通 value pos uint32 // key 距离 leafPageElement 的位移 ksize uint32 vsize uint32 } - 然后是所有的
key和value。 - 通过
pos、ksize和vsize获取对应的key/value的地址:&leafPageElement + pos == &key。&leafPageElement + pos + ksize == &val。
branch node 在文件中的格式如下:
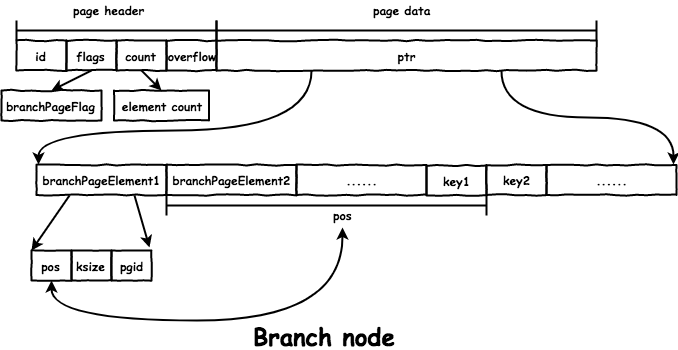
和 leaf node 的区别是:branch node 的 value 是子节点的 page id,存放在 branchPageElement 里,而 key 的存储相同都是通过 pos 得到:
// branchPageElement represents a node on a branch page.
type branchPageElement struct {
pos uint32
ksize uint32
pgid pgid
}
将 item header 和 item 分开存储减少了查找的时间:
O(1)的时间获取所有的item header,二分查找对应的item。inodes := p.leafPageElements() index := sort.Search(int(p.count), func(i int) bool { return bytes.Compare(inodes[i].key(), key) != -1 })- 若是以
[item header][item][...]这种格式存储,需要按顺序遍历查找。
访问结点时,首先要将 page 反序列化后得到得到 node 结构体,代表 B+ 树中一个结点:
// node represents an in-memory, deserialized page.
type node struct {
bucket *Bucket
isLeaf bool // 区分 branch node 和 leaf node
unbalanced bool
spilled bool
key []byte // 该 node 的起始 key
pgid pgid
parent *node
children nodes
inodes inodes // 存放 node 的数据
}
inodes 保存了该 node 的 K/V 数据:
// inode represents an internal node inside of a node.
// It can be used to point to elements in a page or point
// to an element which hasn't been added to a page yet.
type inode struct {
flags uint32 // 用于 leaf node,区分是正常 value 还是 subbucket
pgid pgid // 用于 branch node, 子节点的 page id
key []byte
value []byte
}
node 和 page 的相互转换通过 node.read(p *page) 和 node.write(p *page),具体实现不再赘述。
Bucket
有了上面的铺垫,现在可以看一下 get/put 等操作的实现了。
操作都是对 Bucket 进行操作,Bucket 是一个 namespace,相当于一张表,一个 Bucket 代表一个完整的 B+ 树,结构如下:
// Bucket represents a collection of key/value pairs inside the database.
type Bucket struct {
*bucket
tx *Tx // the associated transaction
buckets map[string]*Bucket // subbucket cache
page *page // inline page reference
rootNode *node // materialized node for the root page.
nodes map[pgid]*node // node cache
// Sets the threshold for filling nodes when they split. By default,
// the bucket will fill to 50% but it can be useful to increase this
// amount if you know that your write workloads are mostly append-only.
//
// This is non-persisted across transactions so it must be set in every Tx.
FillPercent float64
}
// bucket represents the on-file representation of a bucket.
// This is stored as the "value" of a bucket key. If the bucket is small enough,
// then its root page can be stored inline in the "value", after the bucket
// header. In the case of inline buckets, the "root" will be 0.
type bucket struct {
root pgid // page id of the bucket's root-level page
sequence uint64 // monotonically incrementing, used by NextSequence()
}
假设我们现在获取了一个 Bucket,get/put 操作首先都要查找到 key 对应的位置,boltdb 通过 Cursor 实现:
// Cursor creates a cursor associated with the bucket.
// The cursor is only valid as long as the transaction is open.
// Do not use a cursor after the transaction is closed.
func (b *Bucket) Cursor() *Cursor {
// Update transaction statistics.
b.tx.stats.CursorCount++
// Allocate and return a cursor.
return &Cursor{
bucket: b,
stack: make([]elemRef, 0),
}
}
type Cursor struct {
bucket *Bucket
stack []elemRef
}
type elemRef struct {
page *page
node *node
index int
}
首先从 Bucket.root 对应的 page 开始,递归的进行查找,直到 leaf node。Cursor.stack 中保存了查找对应 key 的路径,栈顶保存了 key 所在的结点和位置:
get操作返回栈顶结点中对应的key/val:// keyValue returns the key and value of the current leaf element. func (c *Cursor) keyValue() ([]byte, []byte, uint32) { ref := &c.stack[len(c.stack)-1] if ref.count() == 0 || ref.index >= ref.count() { return nil, nil, 0 } // Retrieve value from node. if ref.node != nil { inode := &ref.node.inodes[ref.index] return inode.key, inode.value, inode.flags } // Or retrieve value from page. elem := ref.page.leafPageElement(uint16(ref.index)) return elem.key(), elem.value(), elem.flags }put操作将对应的key/val添加到栈顶结点:c.node().put(key, key, value, 0, 0) // c.node() 返回栈顶对应的结点 // put inserts a key/value. func (n *node) put(oldKey, newKey, value []byte, pgid pgid, flags uint32) { if pgid >= n.bucket.tx.meta.pgid { panic(fmt.Sprintf("pgid (%d) above high water mark (%d)", pgid, n.bucket.tx.meta.pgid)) } else if len(oldKey) <= 0 { panic("put: zero-length old key") } else if len(newKey) <= 0 { panic("put: zero-length new key") } // Find insertion index. index := sort.Search(len(n.inodes), func(i int) bool { return bytes.Compare(n.inodes[i].key, oldKey) != -1 }) // Add capacity and shift nodes if we don't have an exact match and need to insert. exact := (len(n.inodes) > 0 && index < len(n.inodes) && bytes.Equal(n.inodes[index].key, oldKey)) if !exact { n.inodes = append(n.inodes, inode{}) copy(n.inodes[index+1:], n.inodes[index:]) } inode := &n.inodes[index] inode.flags = flags inode.key = newKey inode.value = value inode.pgid = pgid _assert(len(inode.key) > 0, "put: zero-length inode key") }
subbucket
boltdb 支持嵌套的 Bucket,对于父 Bucket 而言,subbucket 只是特殊的 value 而已,设置 leafPageElement.flags = bucketLeafFlag 标记,而 subbucket 本身是一个完整的 B+ 树:
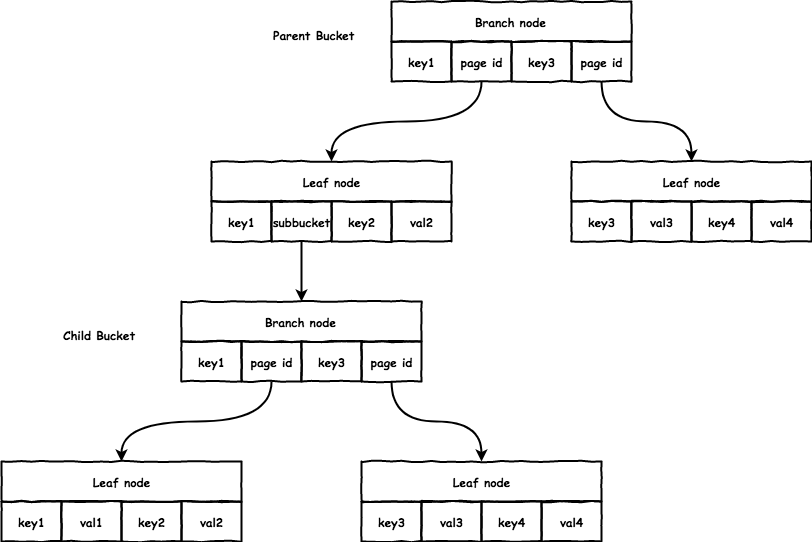
subbucket 在父 bucket 的 leaf node 中存储格式如下:
root:subbucket的root结点的page id。sequence:boltdb支持每bucket的自增id,即这里的sequence。// bucket represents the on-file representation of a bucket. // This is stored as the "value" of a bucket key. If the bucket is small enough, // then its root page can be stored inline in the "value", after the bucket // header. In the case of inline buckets, the "root" will be 0. type bucket struct { root pgid // page id of the bucket's root-level page sequence uint64 // monotonically incrementing, used by NextSequence() }
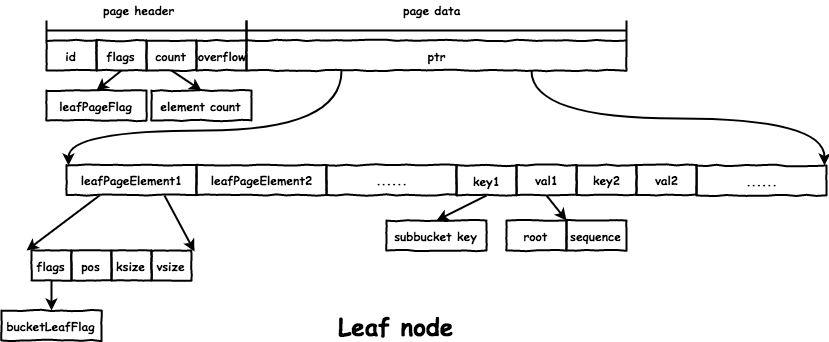
为了实现的统一,db 有一个 root Bucket,也就是整个文件构成的 B+ 树的 root 结点对应的 Bucket,之后创建的 Bucket 都是 root Bucket 的 subbucket。
inline bucket
从上面看到,父 bucket 中只保存了 subbucket 的 bucket header,每个 subbucket 都会占据至少一个 page,若 subbucket 中的数据很少,会造成磁盘空间的浪费。inline bucket 是将小的 subbucket 的
值完整放在父 bucket 的 leaf node 上,从而减少 page 的个数。inline bucket 的限制如下:
- 没有
subbucket; - 整个
Bucket的大小不能超过page size/4。// inlineable returns true if a bucket is small enough to be written inline // and if it contains no subbuckets. Otherwise returns false. func (b *Bucket) inlineable() bool { var n = b.rootNode // Bucket must only contain a single leaf node. if n == nil || !n.isLeaf { return false } // Bucket is not inlineable if it contains subbuckets or if it goes beyond // our threshold for inline bucket size. var size = pageHeaderSize for _, inode := range n.inodes { size += leafPageElementSize + len(inode.key) + len(inode.value) if inode.flags&bucketLeafFlag != 0 { return false } else if size > b.maxInlineBucketSize() { return false } } return true } // Returns the maximum total size of a bucket to make it a candidate for inlining. func (b *Bucket) maxInlineBucketSize() int { return b.tx.db.pageSize / 4 }
inline bucket 在父 bucket 的存放的格式如下,可以看出来是把完整的 page 格式追加到了 bucket header 后面,很好的复用了代码:
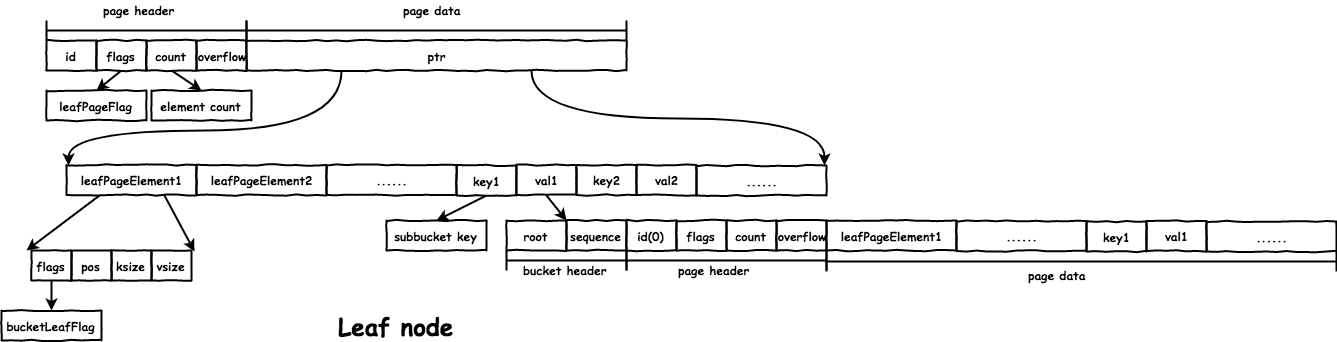
B+ 树的平衡
boltdb 事务中的所有操作都是在内存中进行,比如删除或增加 key/val 都是操作对应 leaf node 的 inodes。直到事务提交时,才会进行 B+ 树的分裂与合并,这样可以避免事务回滚时做无用功。
B+ 树的平衡分为2步:
- 合并结点(
rebalance):会将任何删除过key且大小和key数量不满足要求的node与sibiling合并。 - 分裂结点(
spill):将大小超过page size * FillPercent的node分解为多个node。
这里也不再详细介绍实现,重点是理解 subbucket 和 parent bucket 的关系还有递归。subbucket 对于 parent bucket 就是 leaf node 的一对 K/V,
在合并的时候,会先把当前 Bucket 在事务中遍历到的所有 node 进行合并,然后再递归地合并 subbucket;在分裂的时候,会首先分裂所有的 subbucket 然后才是当前 Bucket 中的 node。
boltdb 支持完整的事务特性(ACID),使用 MVCC 并发控制,允许多个读事务和一个写事务并发执行,但是读事务有可能会阻塞写事务。它的特点如下:
Durability: 写事务提交时,会为该事务修改的数据(dirty page)分配新的page,写入文件。Atomicity: 未提交的写事务操作都在内存中进行;提交的写事务会按照B+树数据、freelist、metadata的顺序写入文件,只有metadata写入成功,整个事务才算完成,只写入前两个数据对数据库无影响。Isolation: 每个读事务开始时会获取一个版本号,读事务涉及到的page不会被写事务覆盖;提交的写事务会更新数据库的版本号。
boltdb 所有操作都会分配一个事务 Tx,结构如下:
// Tx represents a read-only or read/write transaction on the database.
// Read-only transactions can be used for retrieving values for keys and creating cursors.
// Read/write transactions can create and remove buckets and create and remove keys.
//
// IMPORTANT: You must commit or rollback transactions when you are done with
// them. Pages can not be reclaimed by the writer until no more transactions
// are using them. A long running read transaction can cause the database to
// quickly grow.
type Tx struct {
writable bool
managed bool
db *DB
meta *meta
root Bucket
pages map[pgid]*page
stats TxStats
commitHandlers []func()
// WriteFlag specifies the flag for write-related methods like WriteTo().
// Tx opens the database file with the specified flag to copy the data.
//
// By default, the flag is unset, which works well for mostly in-memory
// workloads. For databases that are much larger than available RAM,
// set the flag to syscall.O_DIRECT to avoid trashing the page cache.
WriteFlag int
}
写事务的流程如下:
- 根据
db初始化事务:拷贝一份metadata,初始化root bucket,自增txid; - 从
root bucket开始,遍历B+树进行操作,所有的修改在内存中进行; - 提交写事务:
- 平衡
B+树,在分裂的时候会给每个修改过的node分配新的page; - 给
freelist分配新的page; - 将
B+树数据和freelist数据写入文件; - 将
metadata写入文件。
- 平衡
读事务的流程如下:
- 根据
db初始化事务:拷贝一份metadata,初始化root bucket; - 将当前读事务添加到
db.txs中; - 从
root bucket开始,遍历B+树进行查找; - 结束时,将自身移出
db.txs。
Durability
数据库的前两个 page 保存 metadata,从而保证重启时恢复 db 的信息:
type meta struct {
magic uint32
version uint32
pageSize uint32
flags uint32
root bucket // root bucket 的 page id
freelist pgid // freelist 的 page id
pgid pgid // 文件的 page 个数
txid txid // 当前 db 提交的最大的写事务 id
checksum uint64
}
文件格式如下:
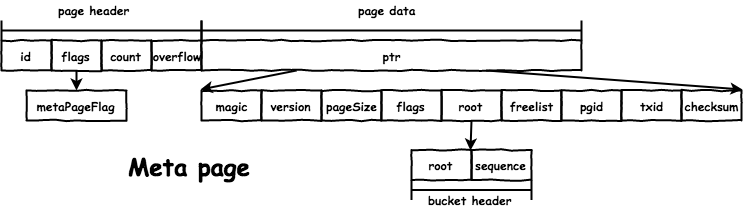
在写事务 commit 时,会为脏 node 分配新的 page,同时将之前使用的 page 释放。freelist 中维护了当前文件中的空闲 page id,分配时会从 freelist.ids 中寻找合适的 page:
// freelist represents a list of all pages that are available for allocation.
// It also tracks pages that have been freed but are still in use by open transactions.
type freelist struct {
ids []pgid // all free and available free page ids.
pending map[txid][]pgid // mapping of soon-to-be free page ids by tx.
cache map[pgid]bool // fast lookup of all free and pending page ids.
}
文件格式如下:
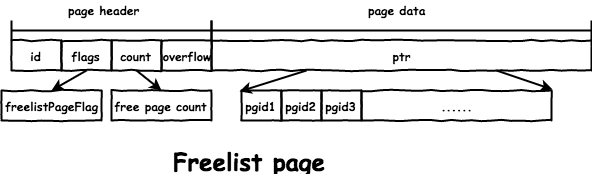
这里的分配 page 不是真的分配文件中某一 page 来写,而是分配了一个 buffer 和起始的 page id,首先将 node 的信息写入这个 buffer,之后统一的写入 page id 对应的文件位置:
// allocate returns a contiguous block of memory starting at a given page.
func (db *DB) allocate(count int) (*page, error) {
// Allocate a temporary buffer for the page.
var buf []byte
if count == 1 {
buf = db.pagePool.Get().([]byte) // db.pagePool 是 sync.pool,缓存了大小为 page size 的 buffer
} else {
buf = make([]byte, count*db.pageSize)
}
p := (*page)(unsafe.Pointer(&buf[0]))
p.overflow = uint32(count - 1)
// Use pages from the freelist if they are available.
if p.id = db.freelist.allocate(count); p.id != 0 { // db.freelist.allocate() 查找合适的连续的 page,返回首 page id
return p, nil
}
// Resize mmap() if we're at the end.
p.id = db.rwtx.meta.pgid
var minsz = int((p.id+pgid(count))+1) * db.pageSize
if minsz >= db.datasz {
if err := db.mmap(minsz); err != nil {
return nil, fmt.Errorf("mmap allocate error: %s", err)
}
}
// Move the page id high water mark.
db.rwtx.meta.pgid += pgid(count)
return p, nil
}
Atomicity
事务要求完全执行或完全不执行:
- 若事务未提交时出错,因为
boltdb的操作都是在内存中进行,不会对数据库造成影响。 - 若是在
commit的过程中出错,如写入文件失败或机器崩溃,boltdb写入文件的顺序也保证了不会造成影响:- 先写入
B+树数据和freelist数据; - 后写入
metadata。
- 先写入
因为 db 的信息如 root bucket 的位置、freelist 的位置等都保存在 metadata 中,只有成功写入 metadata 事务才算成功。
如果第一步时出错,因为数据会写在新的 page 不会覆盖原来的数据,且此时的 metadata 不变,后面的事务仍会访问之前的完整一致的数据。
关键就是要保证 metadata 写入出错也不会影响数据库:
meta.checksum用于检测metadata的corruption。metadata交替保存在文件前2个page中,当发现一个新写入的metadata出错时会使用另一个:// write writes the meta onto a page. func (m *meta) write(p *page) { if m.root.root >= m.pgid { panic(fmt.Sprintf("root bucket pgid (%d) above high water mark (%d)", m.root.root, m.pgid)) } else if m.freelist >= m.pgid { panic(fmt.Sprintf("freelist pgid (%d) above high water mark (%d)", m.freelist, m.pgid)) } // Page id is either going to be 0 or 1 which we can determine by the transaction ID. p.id = pgid(m.txid % 2) p.flags |= metaPageFlag // Calculate the checksum. m.checksum = m.sum64() m.copy(p.meta()) } // meta retrieves the current meta page reference. func (db *DB) meta() *meta { // We have to return the meta with the highest txid which doesn't fail // validation. Otherwise, we can cause errors when in fact the database is // in a consistent state. metaA is the one with the higher txid. metaA := db.meta0 metaB := db.meta1 if db.meta1.txid > db.meta0.txid { metaA = db.meta1 metaB = db.meta0 } // Use higher meta page if valid. Otherwise fallback to previous, if valid. if err := metaA.validate(); err == nil { return metaA } else if err := metaB.validate(); err == nil { return metaB } // This should never be reached, because both meta1 and meta0 were validated // on mmap() and we do fsync() on every write. panic("bolt.DB.meta(): invalid meta pages") }
Isolation
boltdb 支持多个读事务与一个写事务同时执行,写事务提交时会释放旧的 page,分配新的 page,只要确保分配的新 page 不会是其他读事务使用到的就能实现 Isolation。
在写事务提交时,释放的老 page 有可能还会被其他读事务访问到,不能立即用于下次分配,所以放在 freelist.pending 中,
只有确保没有读事务会用到时,才将相应的 pending page 放入 freelist.ids 中用于分配:
freelist.pending: 维护了每个写事务释放的page id。freelist.ids: 维护了可以用于分配的page id。
每个事务都有一个 txid,db.meta.txid 保存了最大的已提交的写事务 id:
- 读事务:
txid == db.meta.txid。 - 写事务:
txid == db.meta.txid + 1。 - 当写事务成功提交时,会更新
metadata,也就更新了db.meta.txid。
txid 相当于版本号,只有低版本的读事务才有可能访问高版本写事务释放的 node,当没有读事务的 txid 比该写事务的 txid 小时,就能释放 pending page 用于分配。
db 中维护了正在进行的读事务:
- 创建读事务时,会追加到
db.txs:// Keep track of transaction until it closes. db.txs = append(db.txs, t) - 当读事务
rollback时(boltdb的读事务完成要调用Tx.Rollback()),会从中移除:tx.db.removeTx(tx)
在创建写事务时,会找到 db.txs 中最小的 txid,释放 freelist.pending 中所有 txid 小于它的 pending page:
// Free any pages associated with closed read-only transactions.
var minid txid = 0xFFFFFFFFFFFFFFFF
for _, t := range db.txs {
if t.meta.txid < minid {
minid = t.meta.txid
}
}
if minid > 0 {
// 这里传入的是 minid - 1,传入 minid 应该就行,读该版本数据的事务不会访问该版本写事务释放的 page
db.freelist.release(minid - 1) // 会将 pending 中 txid 小于 minid - 1 的事务释放的 page 合入 ids
}
还有一点值得注意,把 freelist 写入文件时会写入 freelist.ids 和 freelist.pending,只有重启时才会访问 freelist page,重启时所有读事务都会关闭,当然所有的 pending page 都
可以用于分配。
或许有人会考虑:能不能在写事务提交的时候判断旧的 page 能不能用于分配,而不是在下一个写事务开始时清理?是可以的,不过要求在写入 freelist 和 metadata 的时候不能有新的读事务进行,不如
boltdb 的实现方式好。
读事务阻塞写事务
因为 boltdb 使用 mmap() 将整个文件映射进来,同时读事务加上了读锁:
// Obtain a read-only lock on the mmap. When the mmap is remapped it will
// obtain a write lock so all transactions must finish before it can be
// remapped.
db.mmaplock.RLock()
写事务提交时需要分配 page,如果当前文件没有足够的 free page,需要扩大文件并重新 mmap():
// Resize mmap() if we're at the end.
p.id = db.rwtx.meta.pgid
var minsz = int((p.id+pgid(count))+1) * db.pageSize
if minsz >= db.datasz {
if err := db.mmap(minsz); err != nil {
return nil, fmt.Errorf("mmap allocate error: %s", err)
}
}
而 mmap() 中加上了写锁:
db.mmaplock.Lock()
defer db.mmaplock.Unlock()
在这种情况下读事务会阻塞写事务。一种方法就是设置大的 Options.InitialMmapSize,增大打开数据库时的初始 mmap() 大小:
// InitialMmapSize is the initial mmap size of the database
// in bytes. Read transactions won't block write transaction
// if the InitialMmapSize is large enough to hold database mmap
// size. (See DB.Begin for more information)
//
// If <=0, the initial map size is 0.
// If initialMmapSize is smaller than the previous database size,
// it takes no effect.
InitialMmapSize int
boltdb 不支持多个写事务同时执行,在创建写事务的时候会加上锁:
// Obtain writer lock. This is released by the transaction when it closes.
// This enforces only one writer transaction at a time.
db.rwlock.Lock()
在现在的实现上支持写写并发会增加很多复杂度,不过 boltdb 提供了 db.Batch():
- 当多个
goroutine同时调用时,会将多个写事务合并为一个大的写事务执行。 - 若其中某个事务执行失败,其余的事务会重新执行,所以要求事务是幂等的。
boltdb 的模型很简单,实现的也很漂亮,各模块之间的接口设计值得学习。
Recommend
-
84
boltdb中文网
-
33
boltdb 1.3.0实现分析(一) 2020-06-25 本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系...
-
31
本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章:
-
35
本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章: 本文的写作,主要参考了
-
28
boltdb 1.3.0实现分析(三) 2020-07-25 本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系...
-
31
本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章: 本文的写作,主要参考了
-
6
本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章: 本文的写作,主要参考了
-
10
自底向上剖析 boltdb 源码(1)已认证的官方帐号作者:jaydenwen,腾讯 PCG 后台开发工程师前言本文采用自底向上的方式来介绍 boltdb 内部的实现原理。其...
-
18
自底向上分析boltdb源码自底向上分析boltdb源码本书是采用...
-
5
第二章 boltdb的核心数据结构分析第二章 boltdb的核心数...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK