

boltdb 1.3.0实现分析(三) - codedump的网络日志
source link: https://www.codedump.info/post/20200725-boltdb-3/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
boltdb 1.3.0实现分析(三)
本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章:
本文的写作,主要参考了《区块的持久化之BoltDB》系列文章以及boltdb 源码分析
在前面的文章里,分别介绍了boltdb的几种页面格式、Bucket以及Cursor结构,本文介绍boltdb的事务(Transaction)。
boltdb支持事务的ACID特性,使用MVCC来做并发控制,同时可以执行一个写事务和多个读事务:
- 原子性(Atomicity):未提交的写事务操作都在内存中。在提交写事务的时候,按照B+树数据、freelist、meta元数据的顺序写入文件。在meta元信息写入之前,都可以进行回滚(rollback)操作,只有meta元信息写入成功才能认为写操作执行成功。
- 隔离性(Isolation):每个读事务开始的时候获得一个版本号,读事务涉及到的页面不会被同时进行的写事务所覆盖;而每次写事务都会更新一个版本号。
- 持久性(Durability):写事务在提交的时候,会将这次写操作修改的数据(dirty page)分配新的页面,写入文件持久化。
本节首先讲解boltdb的事务基本实现,下一节讲解boltdb事务如何实现MVCC。
事务初始化
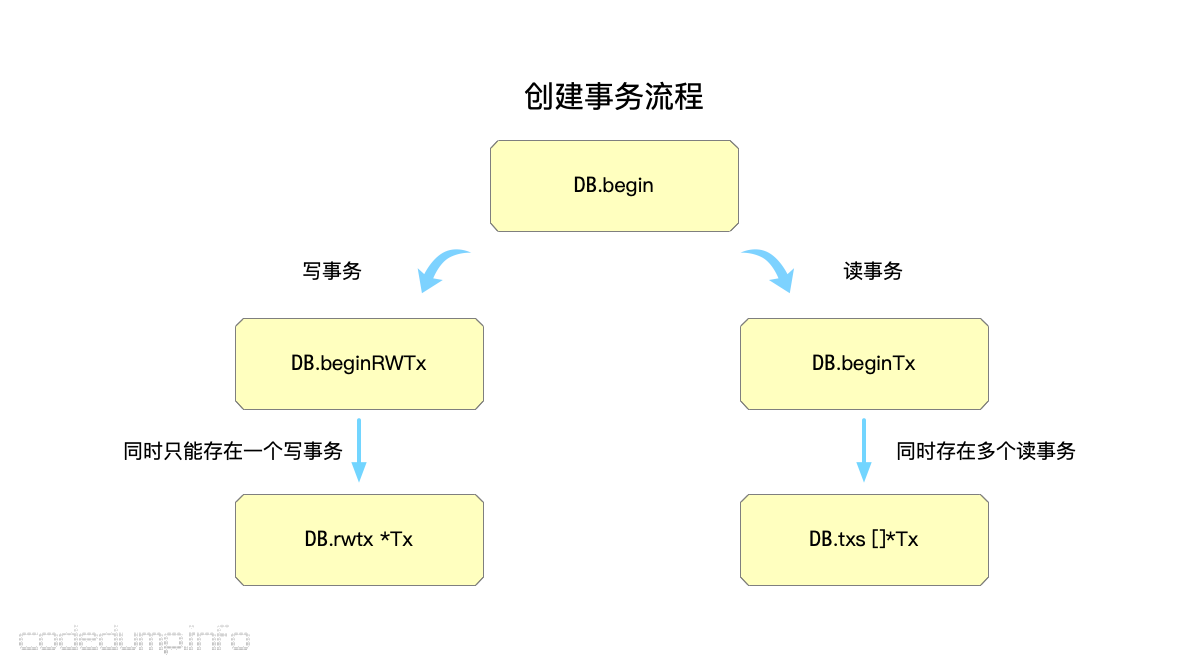
boltdb中,任何一次读写操作,都有一个事务与之对应。这时候首先会调用DB.Begin函数返回一个事务,而传入的参数会根据情况分别创建写和读事务:
func (db *DB) Begin(writable bool) (*Tx, error) {
if writable {
return db.beginRWTx()
}
return db.beginTx()
}
可以看到,根据是否是写事务,会分别调用beginRWTx和beginTx来创建读写事务和只读事务。
DB结构体中,仅有一个写事务成员,而读事务则可以同时存在多个,因此同一个时间只能有一个写事务:
type DB struct {
// ...
rwtx *Tx // 同一时间只能有一个未完成的写事务
txs []*Tx // 保存未完成的读事务的,读事务可以有多个,写事务一个时间只能有一个,就在rwtx里面
}
了解了在DB中如何使用事务,下面来看事务结构体的定义:
type Tx struct {
writable bool // 是否写事务
managed bool //
db *DB // 对应的db
meta *meta // 对应的meta数据指针
root Bucket
pages map[pgid]*page // 涉及到的page
stats TxStats
commitHandlers []func() // commit回调函数数组
WriteFlag int
}
成员释义如下:
- writable:是否是可写的事务。
- managed:表示当前的事务操作是否被db托管,即通过db的成员函数来读写数据库。boltdb还支持直接调用事务相关的成员函数来读写的,此时managed字段为false。
- db:指向当前读写操作的db对象。
- meta:开始事务时,会首先从db中初始化meta信息。
- root:事务开始时的根Bucket,上一节中介绍了Bucket相关信息。
- pages:存储该事务操作中读写所涉及到page。
- stats:事务操作统计相关。
- commitHandlers:存储事务在提交之后的回调函数。
- WriteFlag: 复制或移动数据库文件时,指定的文件打开模式。
上面这些成员中,最重要的就是meta和root字段,下面接着看看事务的初始化流程。
func (tx *Tx) init(db *DB) {
tx.db = db
tx.pages = nil
// Copy the meta page since it can be changed by the writer.
tx.meta = &meta{}
// tx的meta数据拷贝当前的db meta数据
db.meta().copy(tx.meta)
// Copy over the root bucket.
tx.root = newBucket(tx)
tx.root.bucket = &bucket{}
*tx.root.bucket = tx.meta.root
// Increment the transaction id and add a page cache for writable transactions.
if tx.writable {
// 如果是写操作,需要分配页面数组内存
tx.pages = make(map[pgid]*page)
// 递增一个事务id
tx.meta.txid += txid(1)
}
}
首先来看meta的初始化流程。前面提到,db数据结构中,存在两个meta信息分别存储在数据库文件的第一和第二个页面,在db.meta函数中,将选择两者中校验有效且事务ID更大的meta返回:
func (db *DB) meta() *meta {
// We have to return the meta with the highest txid which doesn't fail
// validation. Otherwise, we can cause errors when in fact the database is
// in a consistent state. metaA is the one with the higher txid.
metaA := db.meta0
metaB := db.meta1
if db.meta1.txid > db.meta0.txid {
metaA = db.meta1
metaB = db.meta0
}
// Use higher meta page if valid. Otherwise fallback to previous, if valid.
if err := metaA.validate(); err == nil {
return metaA
} else if err := metaB.validate(); err == nil {
return metaB
}
// This should never be reached, because both meta1 and meta0 were validated
// on mmap() and we do fsync() on every write.
panic("bolt.DB.meta(): invalid meta pages")
}
可以看到有两个meta页面的原因在于:由于轮换使用两个meta页面,这样两次不同的写事务操作,分别对应这两个meta页面中的一个,假如其中一次失败了,也只是影响了其中一个页面。
拿到了这一次操作的meta信息之后,就是根据这些信息来初始化root的Bucket信息:
func (tx *Tx) init(db *DB) {
// ....
tx.root = newBucket(tx)
tx.root.bucket = &bucket{}
*tx.root.bucket = tx.meta.root
// ...
}
在这里,根据拷贝出来的meta信息,调用newBucket函数创建了Bucket返回到tx.root中。一个Bucket的bucket成员,其内容是Bucket的根节点page id以及序列号:
type bucket struct {
// 根节点的page id
root pgid // page id of the bucket's root-level page
// 单调递增的序列号
sequence uint64 // monotonically incrementing, used by NextSequence()
}
因此上面的流程就是:使用当前的meta元信息,创建了一个Bucket,该Bucket的根节点page id以及序列号也都是从当前db的根Bucket中拷贝的。
tx.init函数的最后,根据是否写事务,将拷贝回来的meta信息的事务id递增1:
func (tx *Tx) init(db *DB) {
// ....
// Increment the transaction id and add a page cache for writable transactions.
if tx.writable {
// 如果是写操作,需要分配页面数组内存
tx.pages = make(map[pgid]*page)
// 递增一个事务id
tx.meta.txid += txid(1)
}
// ...
}
这样,在最后写事务完成之后,将meta信息写回磁盘时,就比原先的事务ID加一。
前面介绍了事务的初始化流程,由于boltdb内部是一个B+树结构,所以boltdb中涉及到读写的流程就不再阐述,基本就是一个B+树的读写流程,如果不清楚这部分的原理,可以去补充一下B+树相关的知识:
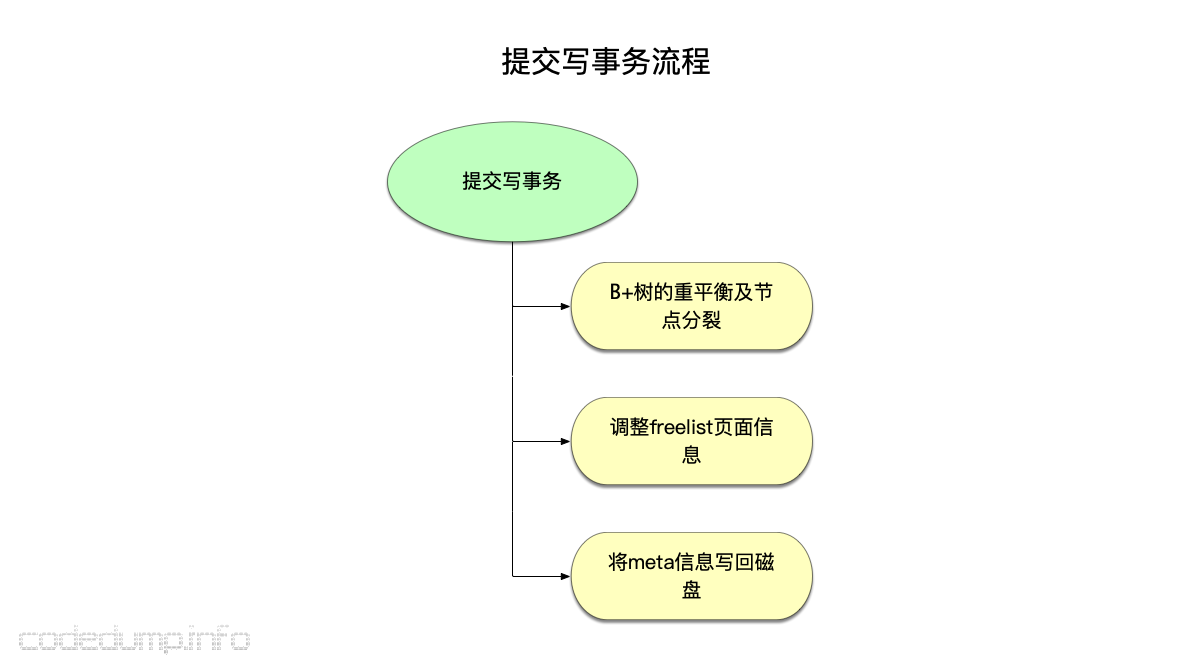
在这一小节,只介绍读写流程完毕之后的事务提交流程,这部分内容在Tx.Commit函数中实现。boltdb的事务提交流程大体分为以下几步:
- B+树的重平衡及节点分裂。
- 调整freelist页面信息。
- 将meta信息写回磁盘。
B+树的重平衡及节点分裂
在写操作过程中,中间可能会造成树的不平衡,因此在操作完毕之后,需要对整个B+树进行重平衡(rebalance)操作。重平衡操作的原理比较复杂,是一个从叶子节点一直往上进行重平衡操作,直到满足B+树平衡条件的流程。算法的原理不在这里阐述,具体可以参考 B树、B+树索引算法原理(下)#删除算法。基本上boltdb的重平衡操作也是这个流程,也就不在这里展开了。
重平衡完毕之后,boltdb还会将大小超过阈值的节点,分裂成多个节点,其大体流程是:
- Bucket遍历自己的所有子Bucket,进行
spill分裂操作。如果分裂成功,就需要在父Bucket中更新该子Bucket的信息。 - Bucket从自己的根节点开始,进行
spill分裂操作。 - 节点的
spill操作,将遍历该节点的所有子节点,如果一个子节点大小超过阈值就进行分裂;否则分裂结束。
如果在分裂操作中,产生了新的页面,则这个时候就会在freelist中分配页面给这些新的页面。由于每次写事务的freelist信息,在事务提交之前是在内存里的,所以一旦写失败,这些freelist信息就回退,并不影响其他的操作。
调整freelist页面信息
到了这一步,前面的两个调整:重平衡和分裂页面操作已经完成,过程中可能产生了新的页面,也就是freelist信息会有改变,因此要相应的调整freelist页面信息。
在这里首先来看看freelist中如何维护页面的分配信息,freelist中包括以下三个成员:
- ids:保存当前可用的页面ID数组。
- pending:pending是一个map,键是事务id,值为页面ID数组,存储的是每个事务操作时候涉及到的页面ID。
- cache:cache是一个map,键为页面ID,值为布尔值,可以从这里快速查看一个页面当前是否空闲。
以上三个成员中,cache是方便快速查找页面空闲情况的数据,可以理解为可用页面的索引;ids是存储可用页面ID的数组,每次分配一个页面出去就要对应的修改这个数组;最后,pending就是存储一个事务操作过程中间的数据。
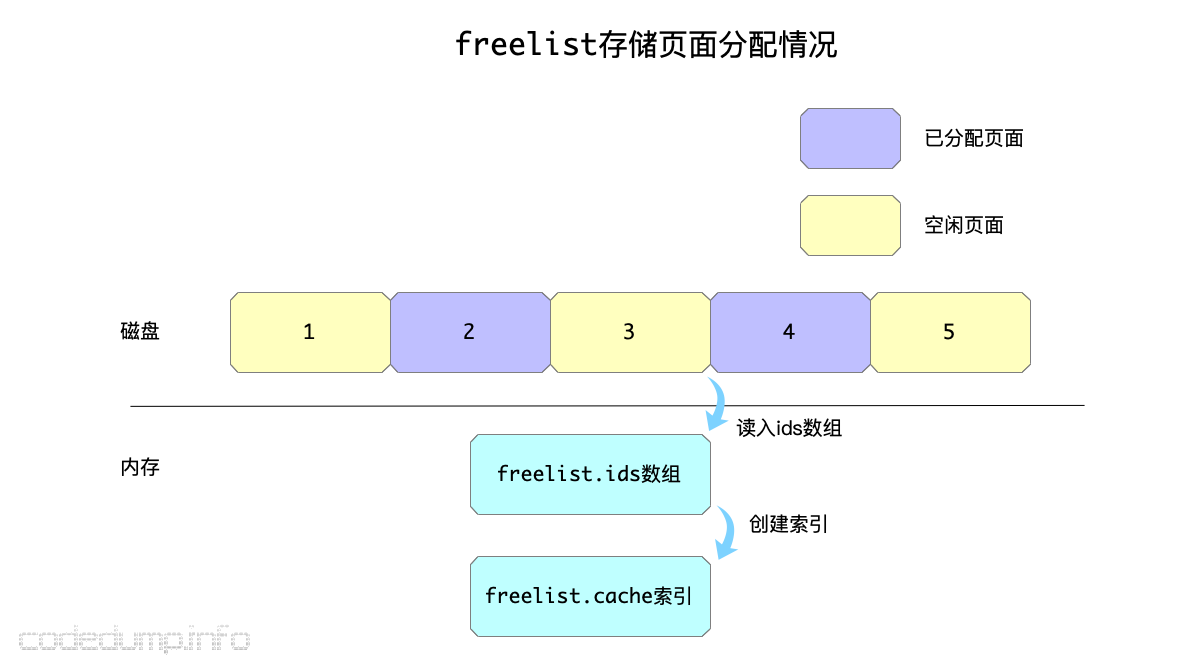
在上图中,freelist页面在磁盘中存储的当前页面id的分配数组,每一次初始化时将可用页面ID读入ids数组之后,都会再调用freelist.reindex函数来重建索引数据:
func (f *freelist) reindex() {
f.cache = make(map[pgid]bool)
for _, id := range f.ids {
f.cache[id] = true
}
for _, pendingIDs := range f.pending {
for _, pendingID := range pendingIDs {
f.cache[pendingID] = true
}
}
}
如果事务需要回滚,实际上是将pending中的页面返还回去,重新变成空闲页面:
// rollback removes the pages from a given pending tx.
func (f *freelist) rollback(txid txid) {
// Remove page ids from cache.
// 回滚就是把所有待释放的id删除,表示不释放了
for _, id := range f.pending[txid] {
delete(f.cache, id)
}
// Remove pages from pending list.
// 然后删除这个事务的pending数组
delete(f.pending, txid)
}
有了对freelist相关的了解,回到事务提交操作修改freelist部分,其代码如下:
func (tx *Tx) Commit() error {
// ...
// 释放freelist
tx.db.freelist.free(tx.meta.txid, tx.db.page(tx.meta.freelist))
// 分配一个freelist
p, err := tx.allocate((tx.db.freelist.size() / tx.db.pageSize) + 1)
if err != nil {
tx.rollback()
return err
}
if err := tx.db.freelist.write(p); err != nil {
tx.rollback()
return err
}
// ...
}
- 首先根据事务ID将原有存储
freelist页面信息的页面释放掉。 - 分配存储这一次写事务的页面信息页面。
- 写入这一次的页面信息。
将meta信息写回磁盘
最后,在更新完毕新的freelist页面信息之后,就可以把本次操作之后的meta元信息也写回磁盘了。
// writeMeta writes the meta to the disk.
// 更新meta数据到磁盘
func (tx *Tx) writeMeta() error {
// Create a temporary buffer for the meta page.
// 分配缓冲区,大小为一个页面
buf := make([]byte, tx.db.pageSize)
// 转换成page结构体
p := tx.db.pageInBuffer(buf, 0)
// 将事务的meta数据写入page中
tx.meta.write(p)
// Write the meta page to file.
// 缓冲的数据写入文件
if _, err := tx.db.ops.writeAt(buf, int64(p.id)*int64(tx.db.pageSize)); err != nil {
return err
}
if !tx.db.NoSync || IgnoreNoSync {
if err := fdatasync(tx.db); err != nil {
return err
}
}
// Update statistics.
tx.stats.Write++
return nil
}
总结下来,boltdb的写事务操作流程大体如下:
- 使用当前db数据来初始化事务:复制一份当前的meta元信息、初始化根Bucket信息、自增事务ID。
- 对B+树进行写操作,这部分在未提交之前都是存储在内存中的数据。
写操作完成之后,提交写事务:
- 平衡B+树、对超过阈值的节点进行分裂操作。分裂过程中产生的新页面将从
freelist中分配出来。 - 给
freelist分配新的页面。 - 到了这里,将B+树和
freelist数据写入文件。 - 更新meta元信息写入文件。
- 平衡B+树、对超过阈值的节点进行分裂操作。分裂过程中产生的新页面将从
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK