

boltdb 1.3.0实现分析(四) - codedump的网络日志
source link: https://www.codedump.info/post/20200726-boltdb-4/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章:
本文的写作,主要参考了《区块的持久化之BoltDB》系列文章以及boltdb 源码分析
前面的章节中,分别讲解了boltdb的页面结构、Bucket结构以及事务相关的逻辑,最后一节讲解boltdb如何实现MVCC。
MVCC概述
数据库的ACID特性中,Isolation即隔离性是一个较难实现的特性。
一个数据库被修改时,在这次事务提交之前,不希望其他事务操作读到修改的结果。一种常见的办法就是加锁,但是锁的粒度如果很大,就会影响数据库的并发性能,即在写操作完成之前不能进行其他操作。
MVCC(Multiversion concurrency control,多版本并发控制)是解决这个问题的一种方式。它的做法是:保存数据库中的多个版本,修改的是一个版本,而同时进行的读操作读取到的数据是旧版本的数据,这样即便读到了旧的数据也不影响,只要不是写操作中间的数据就好。
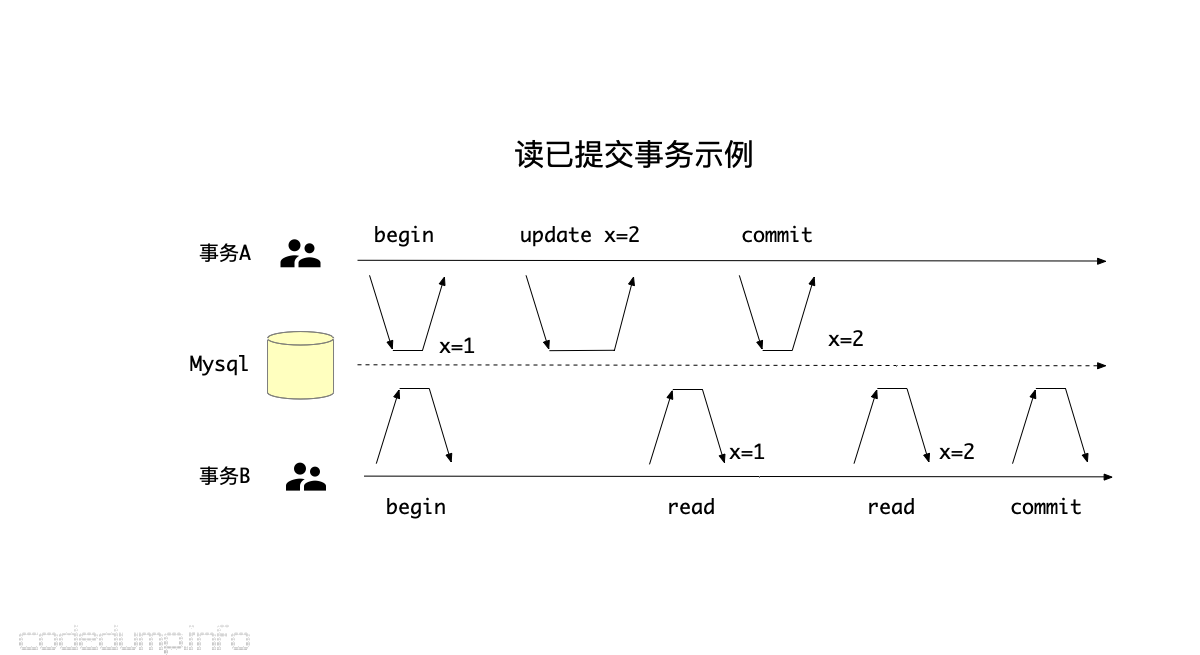
如上图所示,事务A修改了x的值为2,在这个事务提交之前,读事务B读取到的还是修改之前的值1,因为存在有两个该数据的不同版本,并且并没有因为有写操作同时存在而必须等待写操作完成才能进行读操作。在事务A提交之后,才能读到新的值2。(但是这个图里还有另外的问题,即同一个读事务的过程中,前后读到了同一个数据两次不同的值,这叫“不可重复读”,这就是另外一个问题了不在这里展开讨论。)
本节讲解boltdb如何实现MVCC操作,在开始讨论之前先看看boltdb如何管理数据库文件的。
映射文件的使用
boltdb通过mmap系统调用将数据库文件映射到内存中,64位体系下一个进程的虚拟内存空间有128TB,足够映射一个文件了。在把磁盘文件映射到内存之后,对磁盘文件的读写可以直接使用读写内存的操作,由操作系统内核来决定什么时候将哪部分的虚拟内存换入、换出物理内存。
看上去这个好像方便了很多,其实并不建议在存储引擎中使用内存映射这样“偷懒”的技术。原因在于:操作系统内核除了知道什么时候换入换出物理内存之外,对数据库的其他操作一无所知,并不能很精准的控制其行为。
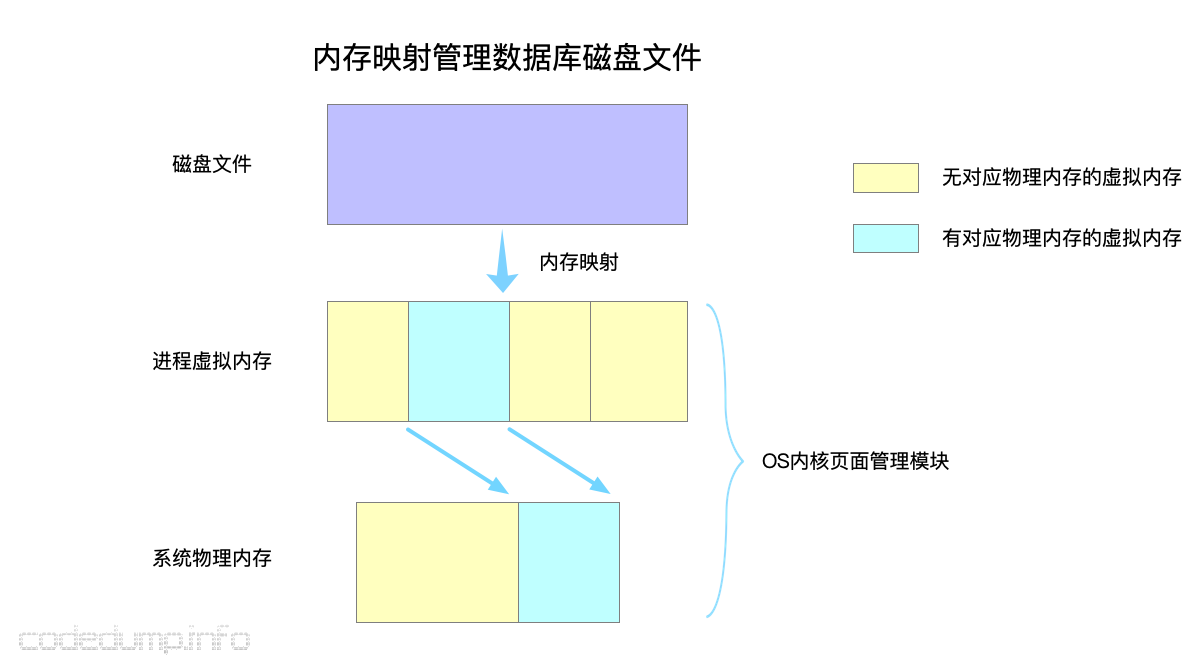
对数据库进行内存映射的操作在函数db.mmap函数中进行,大体流程如下:
func (db *DB) mmap(minsz int) error { db.mmaplock.Lock() defer db.mmaplock.Unlock() // 计算至少要多大的文件大小才能满足minsz需求 // Memory-map the data file as a byte slice. if err := mmap(db, size); err != nil { return err |
这个函数只有在以下两种情况会被调用到:
- db初始化时,即初次加载db文件到内存映射中。
- 当前文件不够大,需要进行扩容时,即在
db.allocate中分配新页面而当前页面不足需要扩充文件大小时。
后者也被称为remmap操作,即以新的大小重新映射文件进行内存中。为了避免每次增加了文件大小都需要重新进行文件内存映射操作,实际上boltdb是对文件大小做了over allocate操作,具体的计算新文件大小的逻辑在函数DB.mmapSize函数中实现的,这里不做展开了。
boltdb的更新流程
了解了boltdb使用内存映射的机制,下面根据上一节的内容,进一步了解boltdb的更新流程。当db有更新时,无非就是以下两种情况的组合:
- 是否需要增加文件大小。
- 是否需要进行remmap。
以下分这几种情况进行讨论。
数据库文件的页面初始情况如下图:
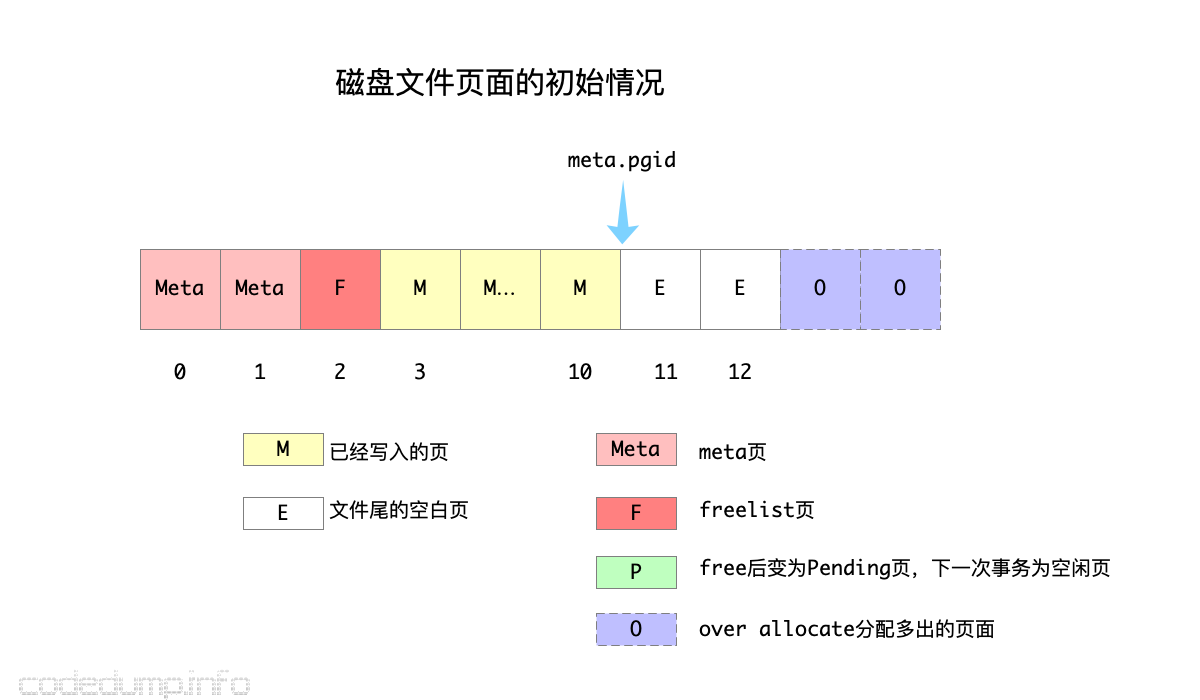
[0,1]页面为meta页面,这两个人meta页面一定是最开始的两个页面不会发生变更。2页面为freelist页面,由于页面的分配情况经常发生修改,所以freelist页面ID会经常发生变化,freelist页面ID做为数据库meta内容的一部分存储在meta页面中。[3,10]页面当前已经写入内容,而meta.pgid保存的是当前最大的页面id,目前为10,这个ID是用于判断当前是否需要增加文件大小的依据。[11,12]为目前还未分配出去的空闲页面,此时这两个页面在freelist的空闲页面id中。[13,14]为当前over allocate多出的页面,此时这两个页面还不在freelist的空闲页面id中。
需要增加文件大小,不需要remmap
假设写事务第一次修改页面[3,10],但是在事务提交时,即rebalance和spill操作之后,都没有新增页面。但是已经脏的页面,如这里的页面[3,10],会分配一个新的页面进行存储,旧的脏页面会在这一次事务之后变成空闲页面。除此之外,由于页面的分配情况发生了变化,因此freelist页面也需要发生变化。
总结起来就是:
- 写事务导致的脏页面需要分配新的页面存储脏数据,假设旧的脏页面3和10对应的是页面
[11,12]。 - 页面分配情况发生了变化,
freelist页面也变成了脏页面,新的freelist页面是页面13。 - 这一次事务对应的
pending页面就是页面[2,3,10](2为freelist页面),因为已经有新的页面保存它们的内容,在事务提交之后,下一次事务操作时,这三个页面就是空闲页面了。
因此,事务结束之后的页面分配情况如下图所示:
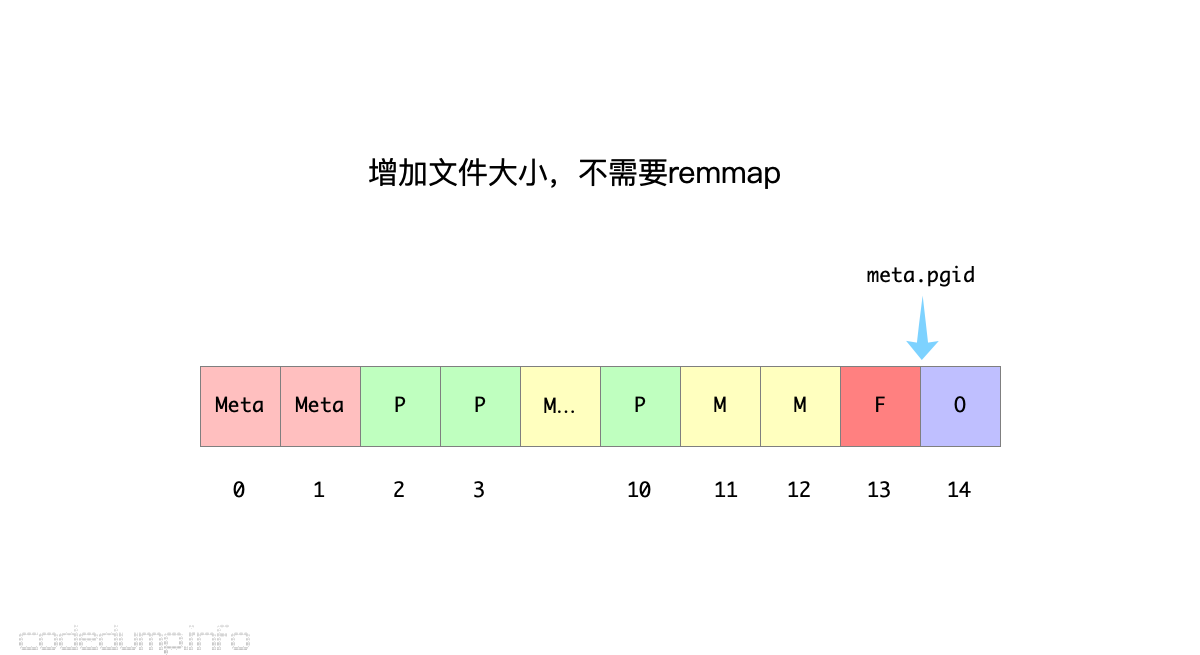
即这种情况下,虽然增加了文件的大小(新增了页面13),但是由于在原先的over allocate范围之内,所以不需要重新remmap文件。
这里的一个问题是:为什么在页面变脏之后,需要重新使用一个页面存储脏页面内容,而不是直接在原先的页面上修改?答案是为了做到MVCC,下面将展开分析。
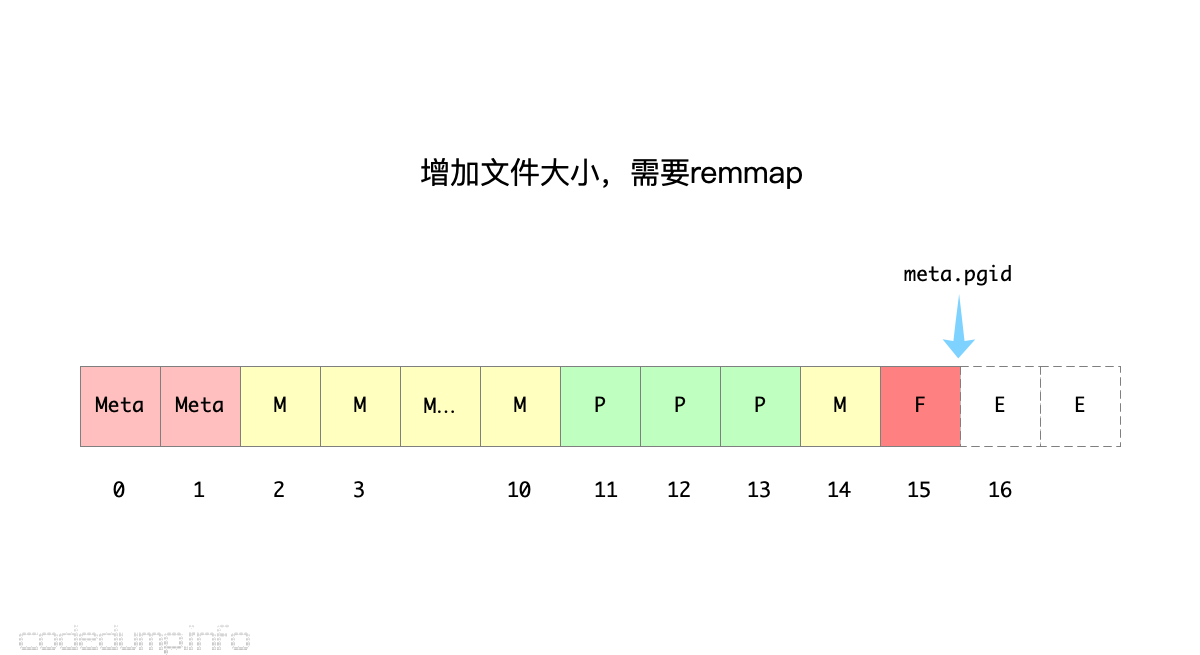
需要增加文件大小,需要remmap
接下来,开始了一个新的写事务操作,此时上一个事务的pending页面[2,3,10]在这个新的写事务中变成了可用的空闲页面。
假设这个写事务修改了页面[11,12],并且提交修改的时候发现超过了页面填充率的阈值,需要进行分裂。于是两个页面进行分裂,就需要4个新的页面来存储分裂后的数据。于是,旧的页面[11,12,13](页面13是freelist页面)成为这次事务的pending页面。由于当前可用的空闲页面不够用,于是只能增加文件大小,同时进行了remmap操作,meta.pgid移动到了16。
这次事务操作之后的页面分配情况如下图所示:
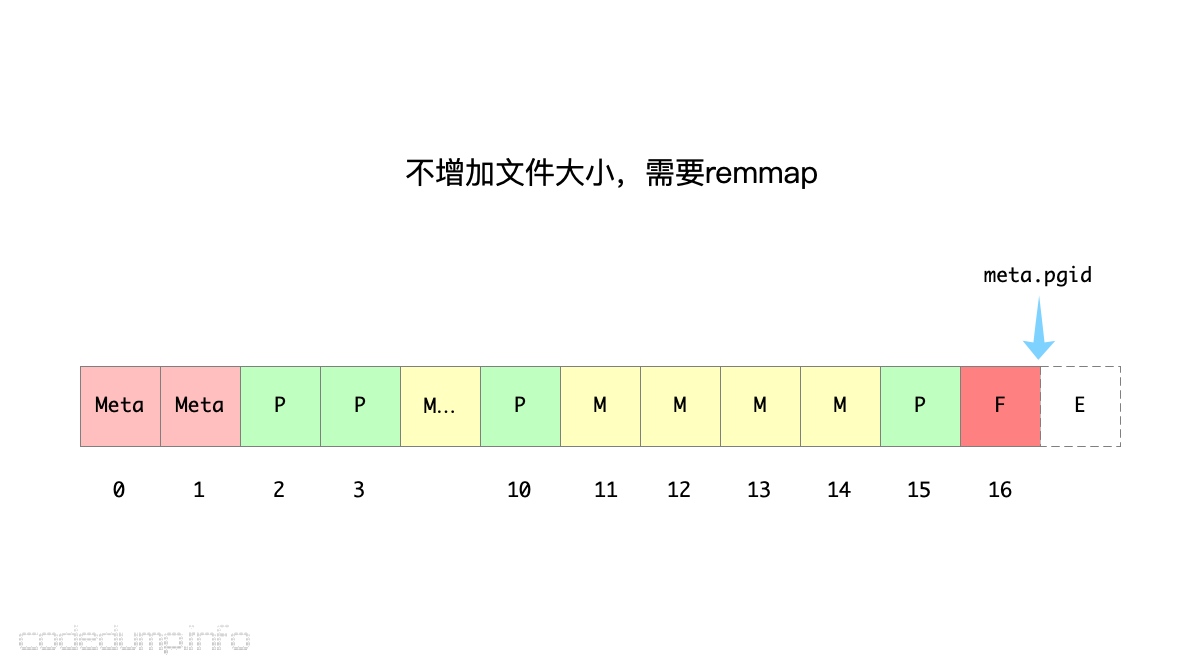
不需要增加文件大小,需要remmap
接下来,开始了一个新的写事务操作,此时上一个事务的pending页面[11,12,13]在这个新的写事务中变成了可用的空闲页面。
假设这一次写事务修改了页面[2,3,10],将它们变成了pending页面,且页面[11,12,13]被依次分配给这三个页面存储新的页面数据。这时freelist页面就没有空闲页面来存储了,为了分配新页面,需要remmap将映射范围移动到下一页及页面17,而页面还在文件范围之内,因此不需要增加文件大小。
这次事务操作之后的页面分配情况如下图所示:
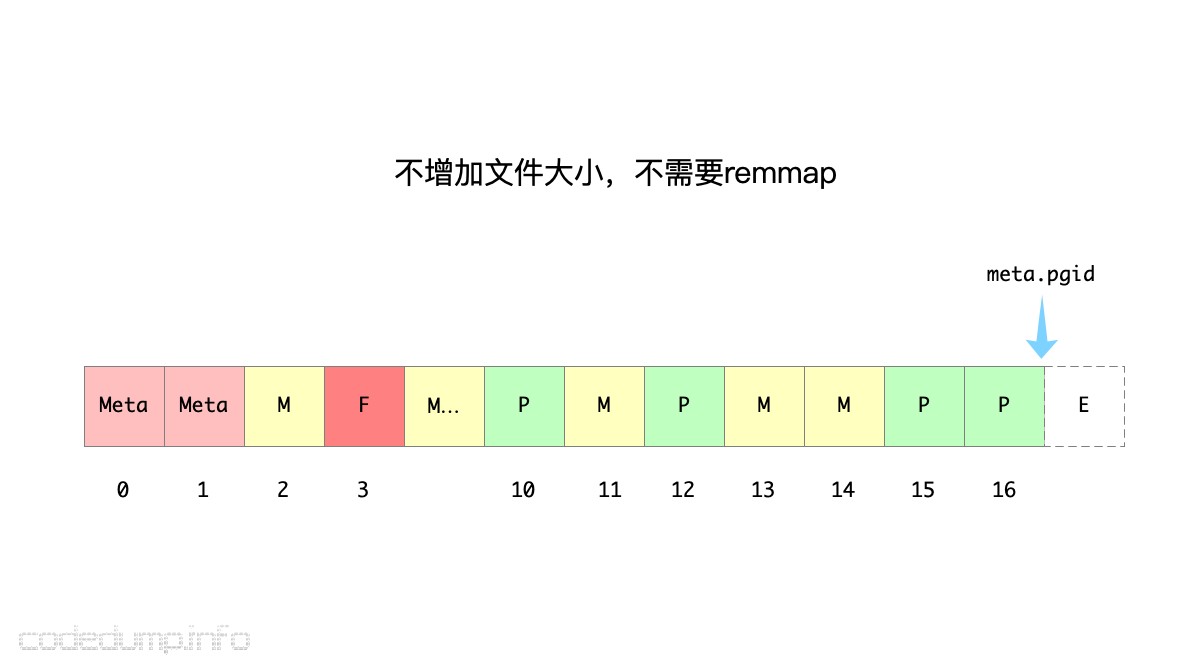
不需要增加文件大小,不需要remmap
接下来,开始了一个新的写事务操作,此时上一个事务的pending页面[2,3,10,15]在这个新的写事务中变成了可用的空闲页面。
如果这一次写事务只修改了页面12,并且提交事务时不需要分裂,那么只需要一个空闲页面就能存储这个修改的脏页面,于是页面2做为这个新的页面被分配了出去,而页面12变成了这次事务操作之后的pending页面。同时freelist页面由页面16变成了页面3,因为有足够的空闲页面存储这一次的修改,于是既不会增加文件大小也不需要remmap操作。
这次事务操作之后的页面分配情况如下图所示:
boltdb如何实现MVCC
从上面的分析可以看出:当一个页面被修改时,修改结果并不马上覆盖旧的页面,而是:
- 分配一个空闲页面,将新的页面内容存储到这个空闲页面上。
- 将旧的页面设置为这一次事务操作的
pending页面,在事务提交之后,pending页面变成空闲页面。
为什么不直接使用新的页面数据覆盖页面,而是一直保存到事务提交时?
原因是为了实现MVCC操作。
实现MVCC操作的核心:保存当前数据的多个版本,这样写事务操作的同时,允许有多个读事务操作进行,只是读事务不会马上读到写事务修改的数据,直到这个写事务提交为止。
boltdb有两个meta页面,也是为了实现MVCC功能,以下图为例:
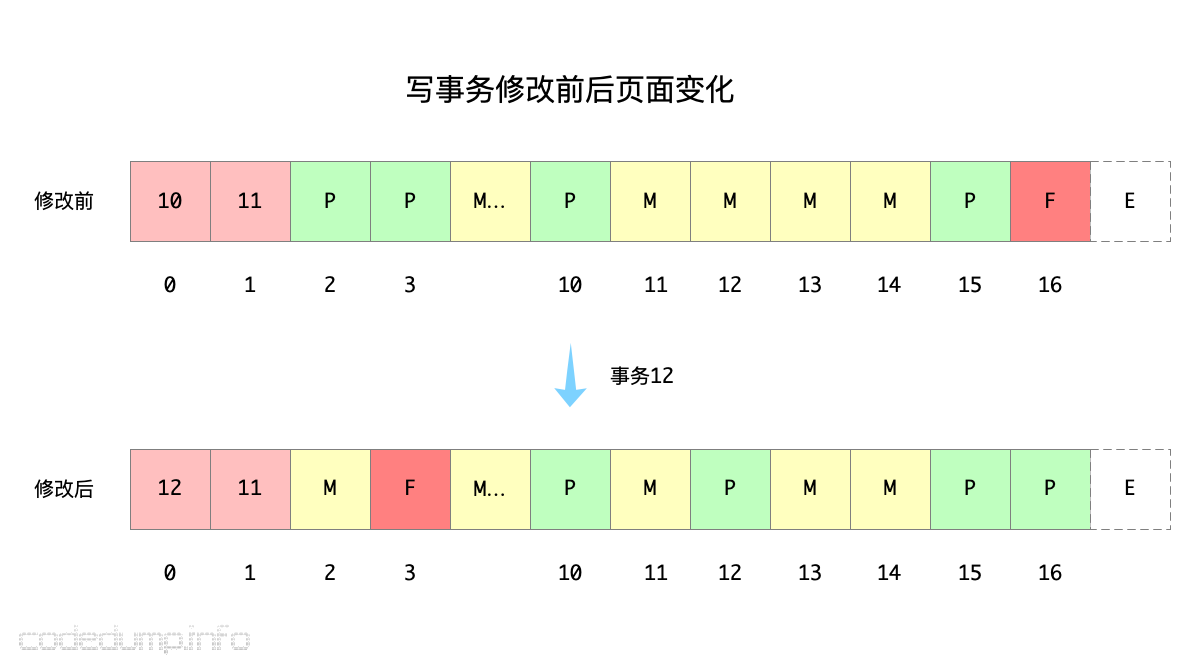
其流程大体如下:
- 在写事务开始之前,
meta页面存储的事务ID是10和11,于是新的写事务ID是12。写事务12开始之前,拷贝的是页面1即事务11的meta内容,而在提交时将覆盖页面0即事务10的meta内容。 - 写事务12修改之后,对应的
pending页面是[10,12,15,16],即这些页面的数据发生了修改,但是并没有覆盖这些页面的内容,而是另外有新的空闲页面被分配出去存储这几个页面的修改内容。 - 如果有这个写事务提交之前的任何读操作,同样也是读到的页面1的事务11的
meta内容,对数据库进行查询,过程中可能会访问到有内容变更的页面[10,12,15,16],但是这几个页面内容并没有被覆盖,所以还是和事务11时候的内容是一样的。 - 最后事务12提交其修改,此时写事务只需要修改
freelist和页面0的meta页面,将事务12写入页面0即可释放写锁。下一次再来新的事务,选择的是两个meta页面中事务ID更大的那个meta数据,于是读取的页面0的meta页面内容得到数据库的信息。
从上面流程可以看出,双meta页面目的是为了实现读写操作时候的MVCC,让写操作不影响读操作的进行。
至此,大体分析完毕boltdb的实现,其特点如下:
- 使用内存映射将磁盘文件映射到进程的虚拟内存中,好处是读写起来方便,由OS内核来控制虚拟内存的映射分配,但是这种做法很偷懒。LMDB等也是使用的这种方式管理数据库文件。
- 由几个存储元信息的页面保存数据库的元信息:
meta页面保存数据库的元信息,freelist页面保存页面的分配信息信息,而meta页面肯定是数据库文件最开始的两个页面,之所以有两个meta页面是为了实现MVCC操作。 - boltdb同时允许一个写操作事务和多个读操作事务,实现
MVCC操作的核心是使用了append B+树的方式:即写事务不直接覆盖需要修改的页面内容,而是写到新分配的空闲页面中,这样读操作即便读到了有内容修改的页面也还是上一个事务的内容,直到写事务提交时才一次性加锁修改数据库的元信息使修改生效。
整体来看,代码量很精简,核心只有几千行的Go代码,也是生产级别的存储引擎,在这里学习到了B+树的实现以及MVCC实现的方式,学习的性价比还是很高的。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK