

boltdb 1.3.0实现分析(一) - codedump的网络日志
source link: https://www.codedump.info/post/20200625-boltdb-1/?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
boltdb 1.3.0实现分析(一)
本文基于boltdb 1.3.0对其实现进行分析。boltdb是etcd系统存储数据使用的KV嵌入式DB,使用Go编码实现,内部是一个B+树结构体。关于etcd、raft协议以及B+树,可以参考之前的文章:
本文的写作,主要参考了《区块的持久化之BoltDB》系列文章以及boltdb 源码分析
boltdb是etcd项目使用的kv存储引擎,代码量不大,不算测试用例的话仅有几千行代码量,是入门存储引擎不错的参考项目。
boltdb中与mysql这类的关系数据库相对应的概念列举如下:
| boltdb | mysql |
|---|---|
| db | database |
| bucket | table |
即:在boltdb中,db代表一个数据库,对应一个db文件;而一个数据库中可能有多个表,对应的概念就是boltdb中的bucket。
另外,对B+树有了解的都知道,B+树中为了减少磁盘读写次数,每次读写都是以页为单位的,对应到boltdb中用page数据结构表示,page只是描述磁盘上一个页面的数据结构,当一个页面读取到内存中时,就使用node结构体来描述。另外,既然落地到磁盘的单位是页,就需要有数据结构来管理页面的分配,这部分使用freelist这个数据结构来管理。
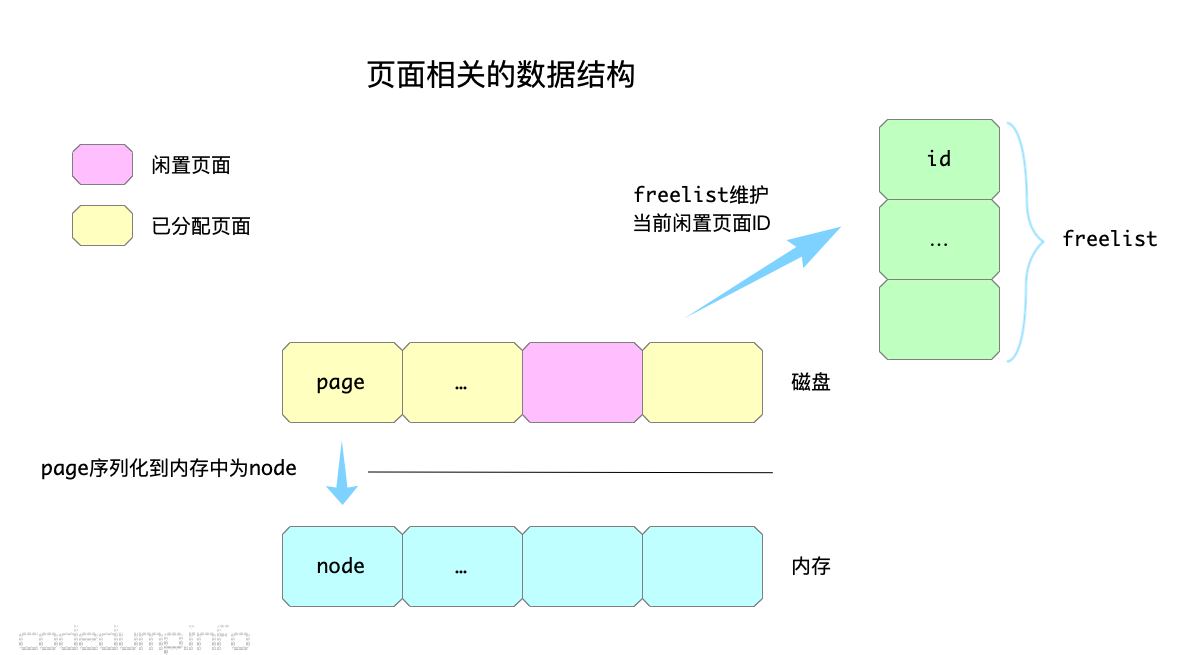
以下,首先展开对页面相关核心数据结构的分析。
数据库文件的磁盘布局和页面
前面提到过,boltdb中以页面为单位来进行磁盘的读写操作,一个页面的大小一般而言与操作系统的页面一致,即4K大小。在boltdb中,分为以下几种类型的页面:
- 存储meta元数据的页面。
- 存储freelist,即管理页面数据的页面。
- Branch页面,存储B+树索引节点,也就是内部节点的页面。
- Leaf页面,存储B+树数据节点,也就是叶子节点的页面。
boltdb代码中定义页面类型如下:
const ( branchPageFlag = 0x01 leafPageFlag = 0x02 metaPageFlag = 0x04 freelistPageFlag = 0x10 |
这四种页面,在boltdb的数据库文件的布局大体如下:

从上图中可以看出:
- 最开始的两个页面是两个meta页面,至于为什么是两个,后面再展开讨论。
- 紧跟着的一个页面是freelist页面。
- 从上面可知,数据库文件中最开始的三个页面存的都是管理信息,此后数据数据型的branch以及leaf页面了。
接下来就这几种页面具体的结构展开说明,不过在此之前还是首先来看看page结构体,它用于表示一个磁盘页面的数据结构。
page结构体
page结构体的定义如下:
type pgid uint64 type page struct { id pgid flags uint16 count uint16 overflow uint32 ptr uintptr |
- id:页面ID。
- flags:标志位,不同类型的页面用不同的标志位来区分。分为:metaPageFlag、freelistPageFlag、branchPageFlag、leafPageFlag。
- count:页面中存储的数据数量,仅在页面类型是branch以及leaf的时候起作用。
- overflow:当前页面如果还不够存放数据,就会有后续页面,这个字段表示后续页面的数量。
- ptr:指向页表头数据结尾,也就是页面数据的起始位置。一个页面的页表头由前面的id、flags、count和overflow字段构成,而ptr并不是页表头的一部分。
根据以上的分析,一个页面的格式如下:
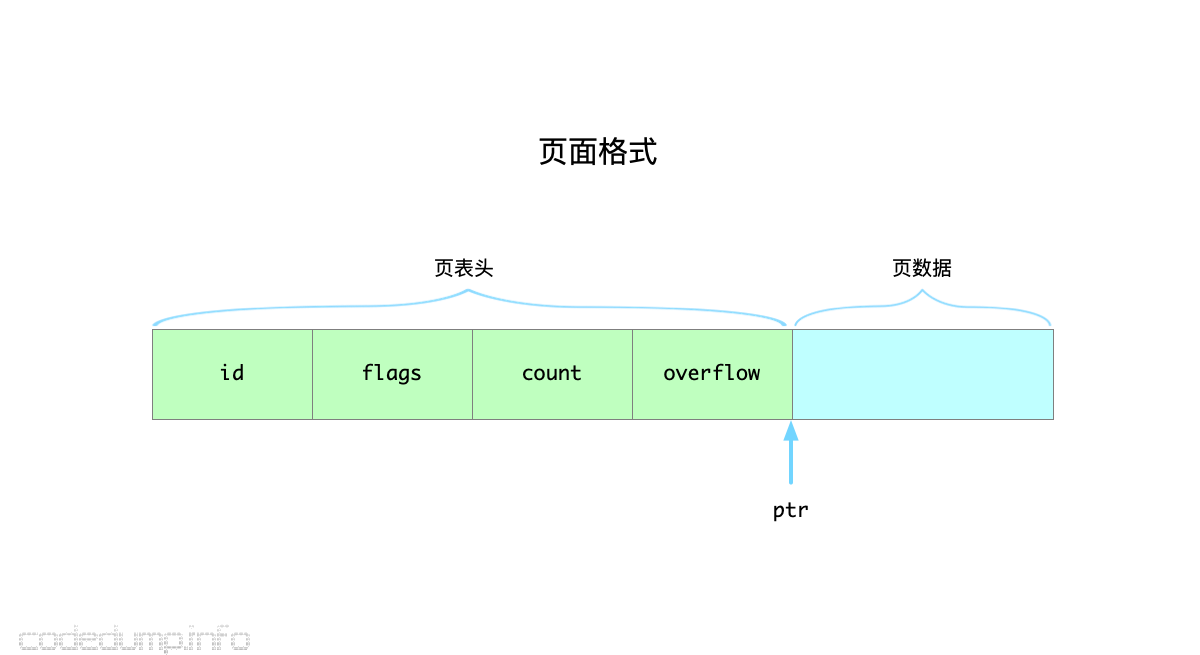
有了对页面的初步认识,接着下来看具体的几种不同类型页面的格式。
meta页面
meta页面用于存储表示整个数据库信息的元数据,其格式如下:
type meta struct { magic uint32 version uint32 pageSize uint32 flags uint32 root bucket freelist pgid pgid pgid txid txid checksum uint64 |
- magic:boltdb的magic number,值为“0xED0CDAED”。
- version:boltdb的版本号,当前为2。
- pageSize:boltdb文件的页面大小。
- flags:保留字段,暂时未使用。
- root:保存boltdb的根bucket的信息,后续介绍bucket时详细展开。
- freelist:保存freelist页面的页面ID。
- pgid:保存当前总的页面数量,即最大页面号加一。
- txid:上一次写数据库的事务ID,可以看作是当前boltdb的修改版本号,每次写数据库时加1,只读时不改变。
- checksum:校验码,用于校验元数据页面是否出错的。
从上面对page结构体的分析,ptr指向具体的页面数据内容,据此,从page结构体中返回meta指针的函数如下:
func (p *page) meta() *meta { return (*meta)(unsafe.Pointer(&p.ptr)) |
即:将page的ptr指针转换为meta类型返回。
因此,一个meta页面的格式如下:
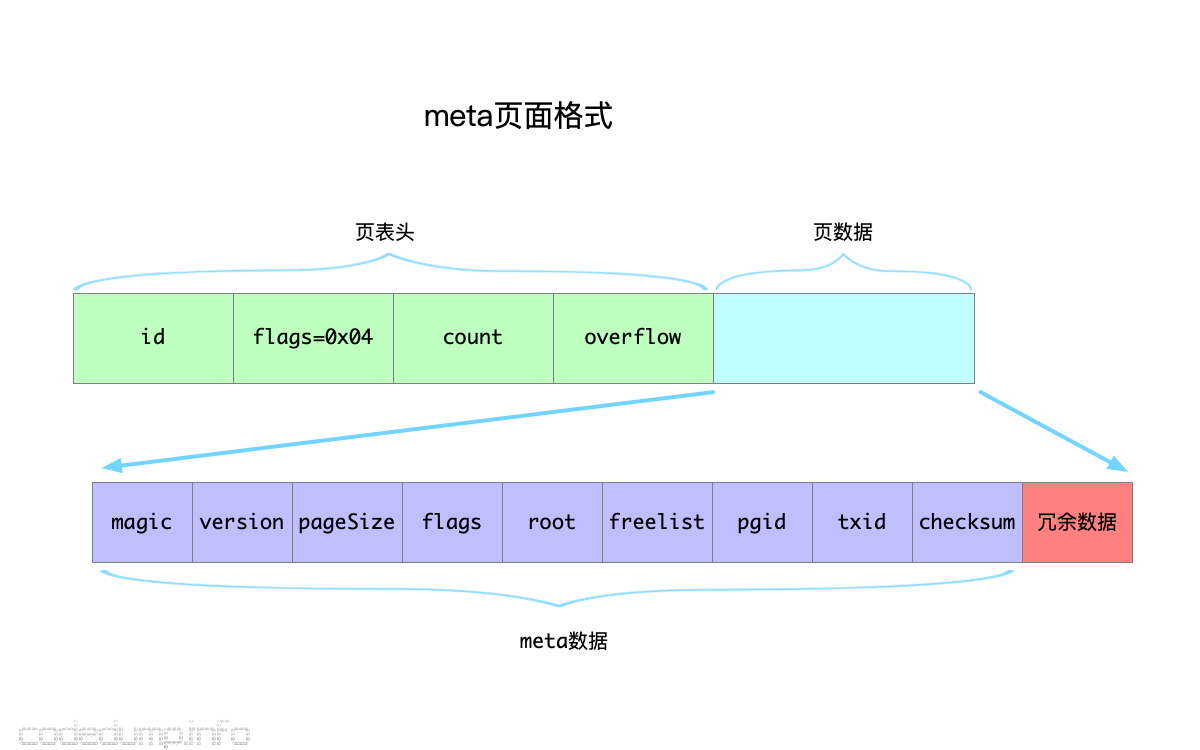
freelist页面
接下来看freelist页面的构成。由于boltdb磁盘分配的单位是页面,所以当前哪些页面可用、哪些闲置,就需要用一个数据结构来描述,这部分信息就由freelist页面来维护。如果当前磁盘页面已经不够分配了,boltdb就需要扩大磁盘文件的大小,创建出更多可用的闲置页面供分配。
来看freelist的数据结构定义:
type freelist struct { ids []pgid // all free and available free page ids. pending map[txid][]pgid // mapping of soon-to-be free page ids by tx. cache map[pgid]bool // fast lookup of all free and pending page ids. |
- ids:保存当前闲置页面id的数组。
- pending:保存事务操作对应的页面ID,键为事务ID,值为页面ID数组。这部分的页面ID,在事务操作完成之后即被释放。
- cache:标记一个页面ID可用,即这个成员中的所有键都是页面ID,而这些页面ID当前都是闲置可分配使用的。
在这三个成员中,并不是所有成员都是需要保存到磁盘上的数据,实际上读写freelist页面时是这样操作的:
- 读页面内容到内存:对应操作在
freelist.read中,页面数据部分保存的是当前闲置页面ID数组,将其读入ids成员中。 - 写页面内容到磁盘:对应操作在
freelist.write中,读取ids数组和pending中的页面id,拼接、排序之后在一起写入磁盘。
即:freelist页面的数据部分,仅存储的是可用的页面ID数组。这一部分在读取到内存时,写入ids成员中,而pending和cache,都是boltdb分配页面流程中的中间产物。
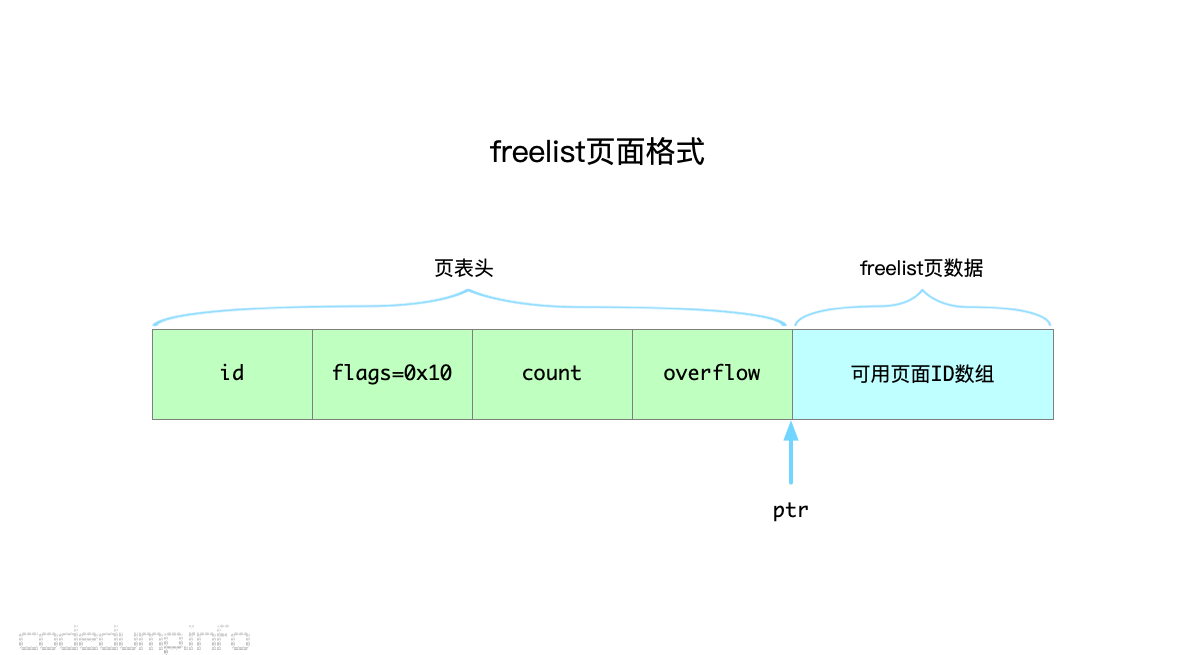
freelist中的一些操作与事务有关,这里暂时不展开这部分的讨论,先来看看基本的页面分配是怎么完成的。
freelist对外提供allocate函数,该函数的参数是一个整数n,表示希望能分配连续的n个页面,返回这些页面中第一个页面的页面ID。实际情况肯定不是每次这样分配就能成功的,在不成功的时候,boltdb就只能再进行mmap操作,扩大数据库磁盘文件的大小了:
// allocate returns a contiguous block of memory starting at a given page. func (db *DB) allocate(count int) (*page, error) { // ... // Use pages from the freelist if they are available. // 分配页面id,传入的count表示需要多少个连续的id if p.id = db.freelist.allocate(count); p.id != 0 { return p, nil // 前面分配页面id失败,说明当前已经不够用了,所以需要重新mmap分配更大的空间出来 // Resize mmap() if we're at the end. p.id = db.rwtx.meta.pgid // 计算需要的最小文件大小 var minsz = int((p.id+pgid(count))+1) * db.pageSize // 如果大于当前文件大小,需要重新分配 if minsz >= db.datasz { if err := db.mmap(minsz); err != nil { return nil, fmt.Errorf("mmap allocate error: %s", err) // Move the page id high water mark. // 保存目前最高的页面id db.rwtx.meta.pgid += pgid(count) return p, nil |
从以上代码可以看到:
- 首先调用
freelist.allocate分配count个连续页面,返回起始页面ID。 - 这个过程一旦失败,意味着当前系统中已经没有了count个连续页面,此时计算满足条件需要的最小文件大小,如果超过了当前数据库文件大小,就调用
db.mmap函数对磁盘文件扩容。
继续看db.mmap函数的实现,这里仅仅列举出核心的代码:
// mmap opens the underlying memory-mapped file and initializes the meta references. // minsz is the minimum size that the new mmap can be. func (db *DB) mmap(minsz int) error { // Unmap existing data before continuing. if err := db.munmap(); err != nil { return err // Memory-map the data file as a byte slice. if err := mmap(db, size); err != nil { return err // Save references to the meta pages. // 前两页是两个meta数据 db.meta0 = db.page(0).meta() db.meta1 = db.page(1).meta() |
在上面的代码中:
- mmap操作之前首先调用
munmap函数取消内存映射,再重新调用一次mmap函数扩大文件大小之后映射进入内存。 - 由于以上的操作,磁盘大小发生了变化,那么肯定就需要更新
meta页面信息。
branch页面
branch页面就是用于存储B+树中的内部节点的页面,即这里的数据只有索引数据,由于只有索引数据,所以branch中并不会存储值。
branch页面的数据部分划分为两个部分:
- branchPageElement数组,即存储每个branch元素的元信息。
- 真实的数据部分。
来看看branchPageElement结构体的定义,该结构体定义每个branch中的元素的信息:
// branchPageElement represents a node on a branch page. type branchPageElement struct { pos uint32 ksize uint32 pgid pgid |
- pos:存储键相对于当前页面数据部分的偏移量。
- ksize:键的大小。
- pgid:子节点的页面ID。
branch页面的格式布局也可以从page序列化到内存中的node结构体的代码中看出,以下列出核心的几个函数:
// branchPageElement retrieves the branch node by index func (p *page) branchPageElement(index uint16) *branchPageElement { return &((*[0x7FFFFFF]branchPageElement)(unsafe.Pointer(&p.ptr)))[index] func (n *branchPageElement) key() []byte { buf := (*[maxAllocSize]byte)(unsafe.Pointer(n)) return (*[maxAllocSize]byte)(unsafe.Pointer(&buf[n.pos]))[:n.ksize] func (n *node) read(p *page) { for i := 0; i < int(p.count); i++ { inode := &n.inodes[i] if n.isLeaf { } else { elem := p.branchPageElement(uint16(i)) inode.pgid = elem.pgid inode.key = elem.key() |
以上代码中可以看到:
- 根据
page.branchPageElement函数的实现,在branch类型的页面中,page.ptr实际上指向的是一个branchPageElement类型的数组,于是将ptr指针转换成branchPageElement数组类型之后,就可以使用索引值取到对应位置的branchPageElement。 - 而根据
branchPageElement.key函数的实现,一个branchPageElement的key,位置在这个元素的pos位置开始,长度为key。
因此,branch页面的格式如下图:
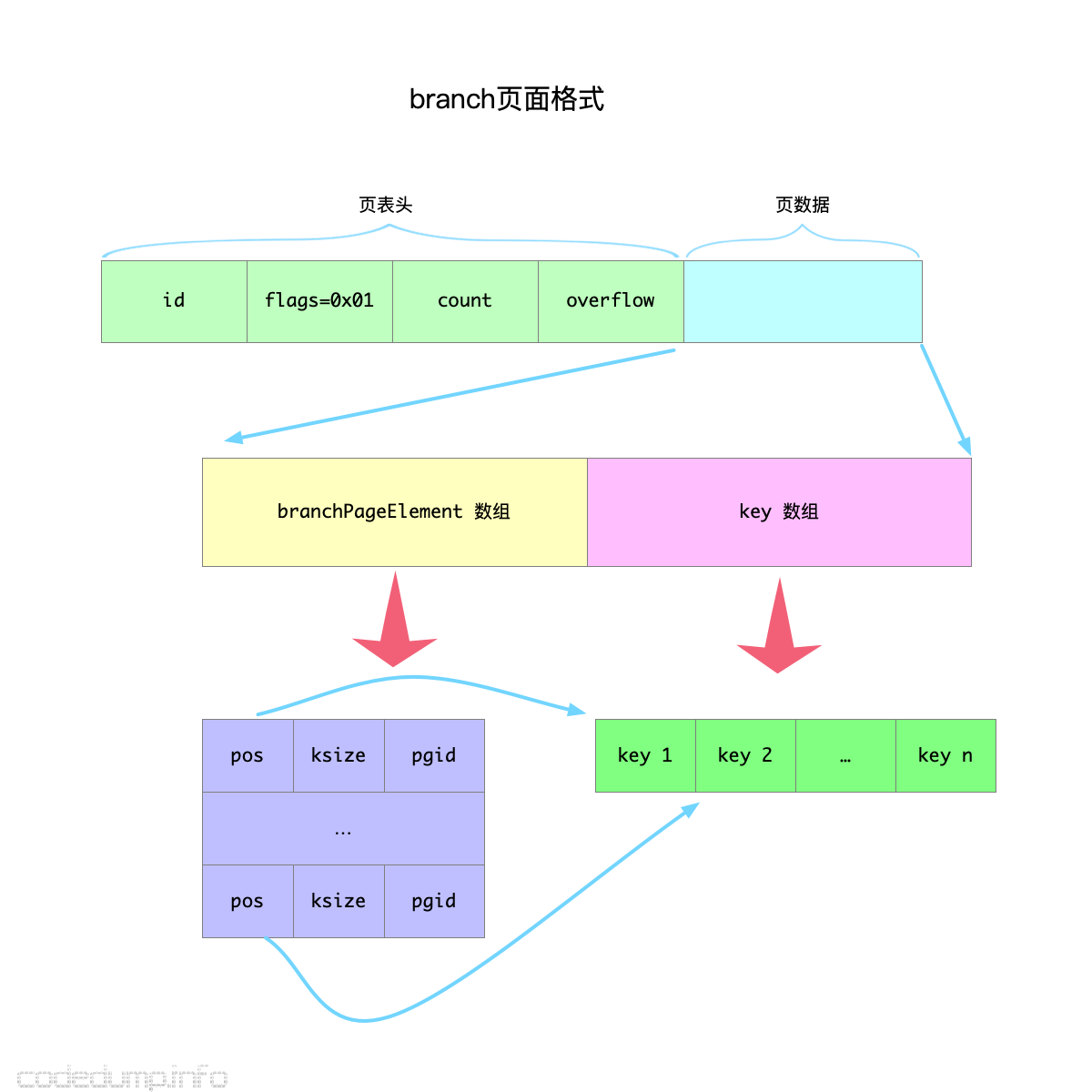
leaf页面
leaf页面就是B+树中存储数据的叶子节点,其页面元素定义如下:
// leafPageElement represents a node on a leaf page. type leafPageElement struct { flags uint32 pos uint32 ksize uint32 vsize uint32 |
与branch不同的是,leaf页面元素有以下成员:
- flags:标志位,为0的时候表示就是普通的叶子节点,而为1的时候表示是子bucket,子bucket后面再展开说明。
- vsize:存储数据的大小。
与branch页面类似,leaf页面也分为两大部分:
- 存储
leafPageElement类型数据的数组。 - 存储key、value数据的数组。
可以看到,leaf节点元素与branch节点元素类似,在这里就不再加以说明,仅把格式示意图列在下面,读者可以自己参考代码阅读:
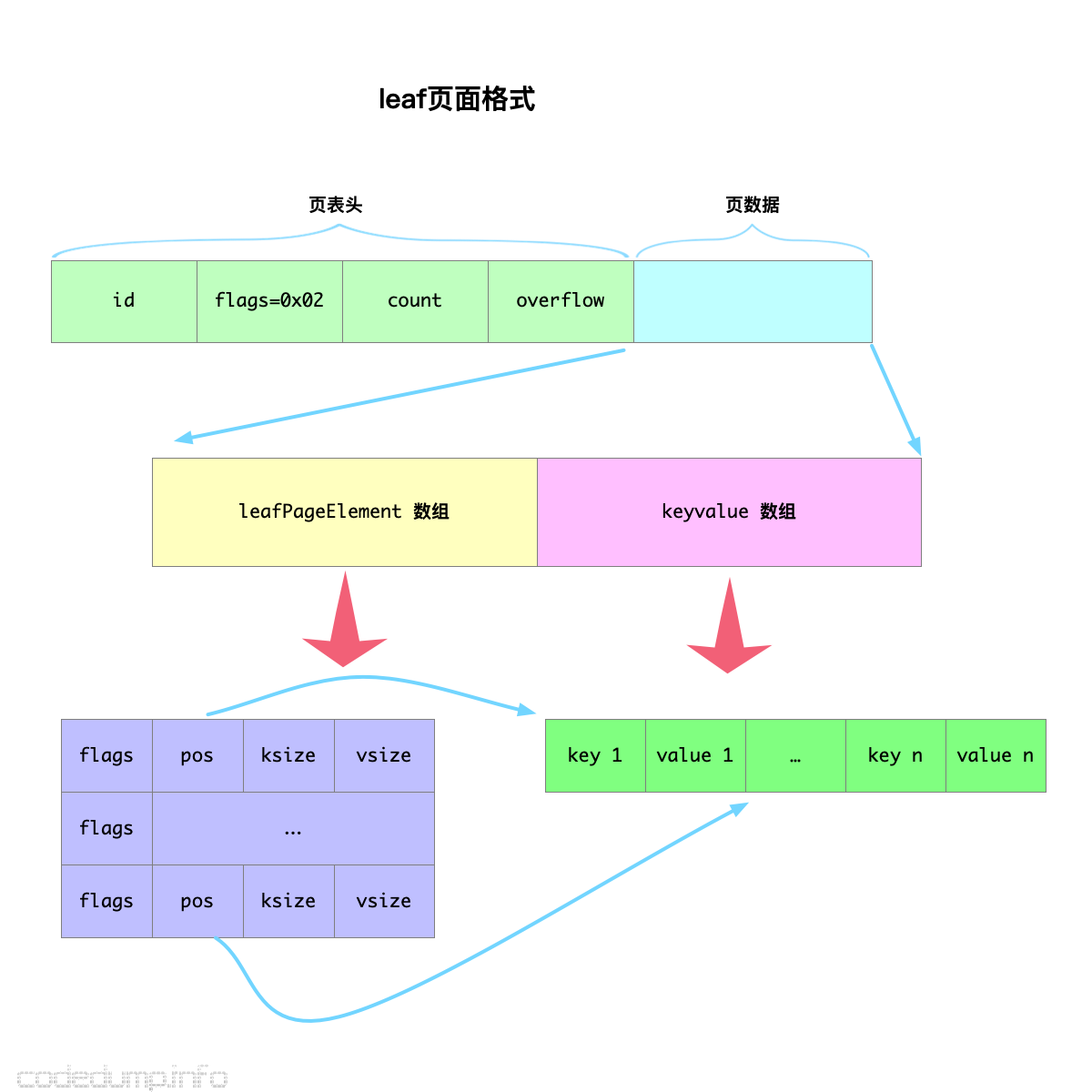
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK