

聊聊 Redis 高可用原理
source link: https://www.51cto.com/article/712063.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
大家好,我是楼仔!
Redis 的高可用,太重要啦!之前找工作面试,这个问题面试的频率都能排到前几,尤其是一些大厂,先不要着急看文章,如果面试官给你抛这么个问题,你会怎么回答呢,可以先想 5 分钟。
这里要等待 5 分钟 ...
其实我也可以偷个懒,完全转载其它博客,但是没有找到我想要的,为了不辜负广大粉丝,楼哥还是单独给大家写一篇,主要根据这块知识,再结合之前的一些面试情况,给大家唠唠。
1. Redis 分片策略
1.1 Hash 分片
我们都知道,对于 Reids 集群,我们需要通过 hash 策略,将 key 打在 Redis 的不同分片上。
假如我们有 3 台机器,常见的分片方式为 hash(IP)%3,其中 3 是机器总数。
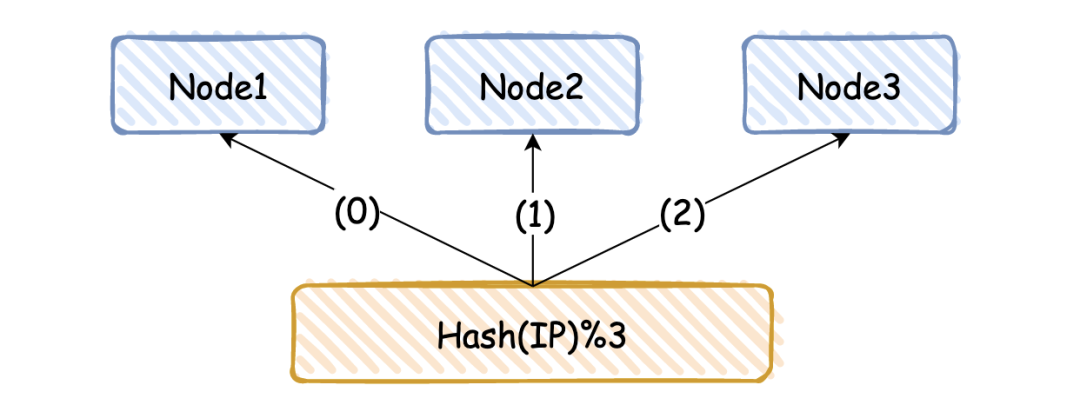
目前很多小公司都这么玩,上手快,简单粗暴,但是这种方式有一个致命的缺点:当增加或者减少缓存节点时,总节点个数发生变化,导致分片值发生改变,需要对缓存数据做迁移。
那如何解决该问题呢,答案是一致性 Hash。
1.2 一致性 Hash
一致性哈希算法是 1997 年由麻省理工学院提出的一种分布式哈希实现算法。
环形空间:按照常用的 hash 算法来将对应的 key 哈希到一个具有 2^32 次方个桶的空间中,即 0~(2^32)-1 的数字空间中,现在我们可以将这些数字头尾相连,想象成一个闭合的环形。
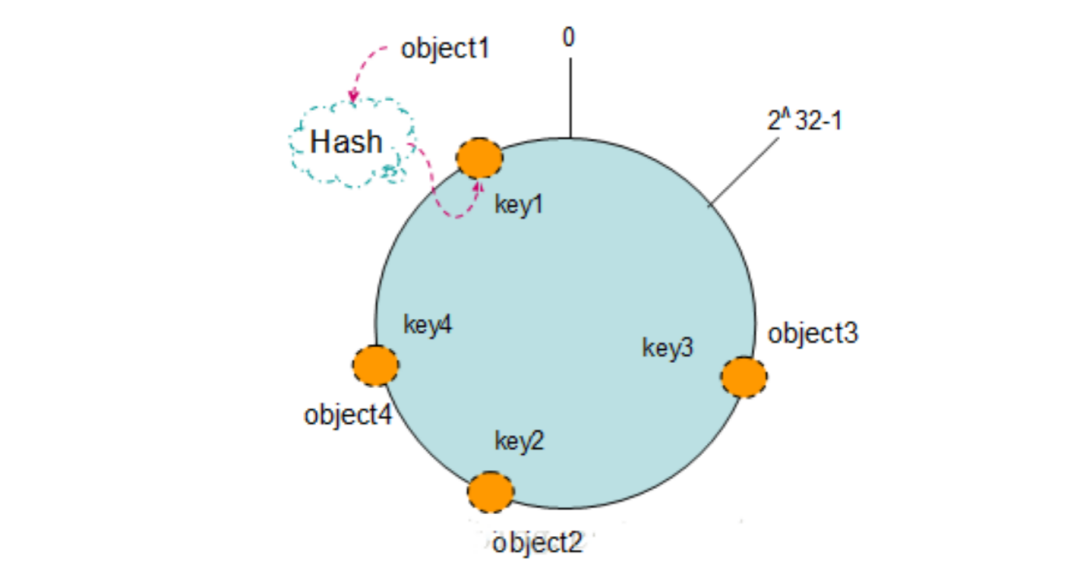
Key 散列 Hash 环:现在我们将 object1、object2、object3、object4 四个对象通过特定的 Hash 函数计算出对应的 key 值,然后散列到 Hash 环上。
机器散列 Hash 环:假设现在有 NODE1、NODE2、NODE3 三台机器,以顺时针的方向计算,将所有对象存储到离自己最近的机器中,object1 存储到了 NODE1,object3 存储到了 NODE2,object2、object4 存储到了 NODE3。
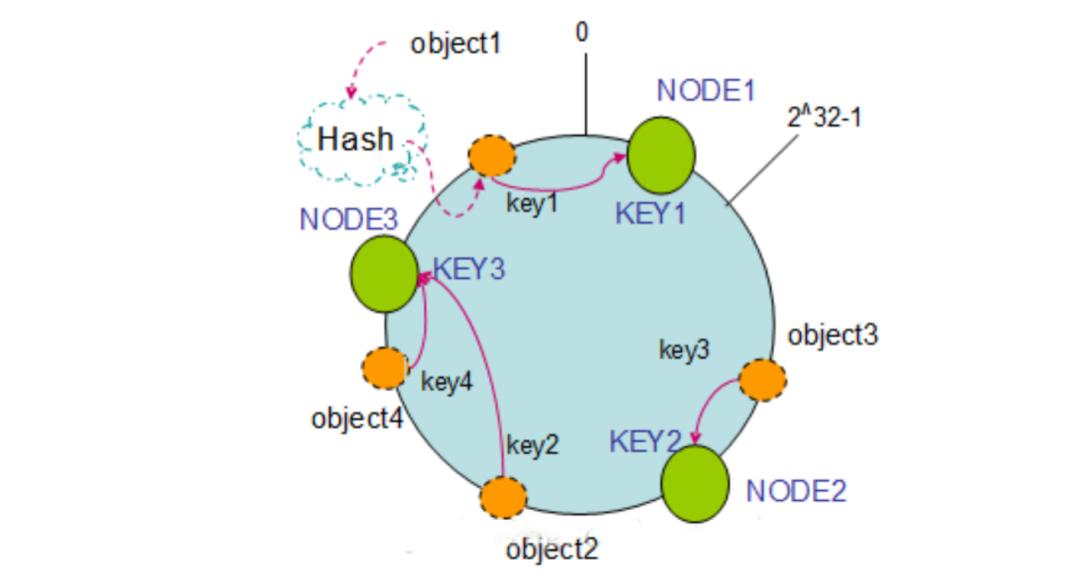
节点删除:如果 NODE2 出现故障被删除了,object3 将会被迁移到 NODE3 中,这样仅仅是 object3 的映射位置发生了变化,其它的对象没有任何的改动。
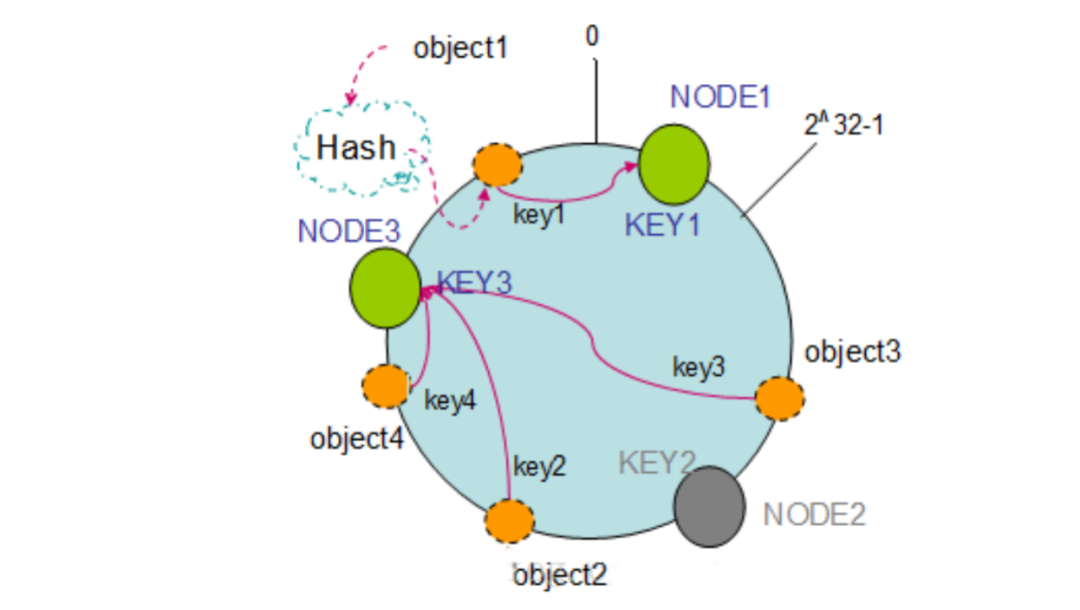
添加节点:如果往集群中添加一个新的节点 NODE4,object2 被迁移到了 NODE4 中,其它对象保持不变。
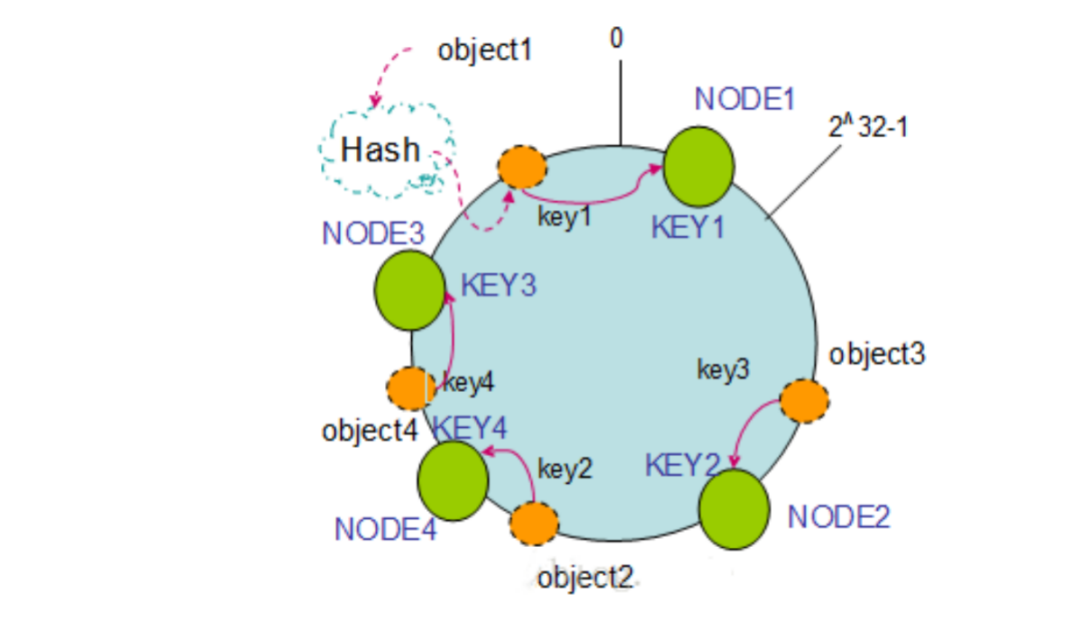
通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还使数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
如果机器个数太少,为了避免大量数据集中在几台机器,实现平衡性,可以建立虚拟节点(比如一台机器建立 3-4 个虚拟节点),然后对虚拟节点进行 Hash。
2. 高可用方案
很多时候,公司只给我们提供一套 Redis 集群,至于如何计算分片,我们一般有 2 套成熟的解决方案。
客户端方案:也就是客户端自己计算 Redis 分片,无论你使用Hash 分片,还是一致性 Hash,都是由客户端自己完成。
客户端方案简单粗暴,但是只能在单一语言系统之间复用,如果你使用的是 PHP 的系统,后来 Java 也需要使用,你需要用 Java 重新写一套分片逻辑。
为了解决多语言、不同平台复用的问题,就衍生出中间代理层方案。
中间代理层方案:将客户端解决方案的经验移植到代理层中,通过通用的协议(如 Redis 协议)来实现在其他语言中的复用,用户无需关心缓存的高可用如何实现,只需要依赖你的代理层即可。
代理层主要负责读写请求的路由功能,并且在其中内置了一些高可用的逻辑。
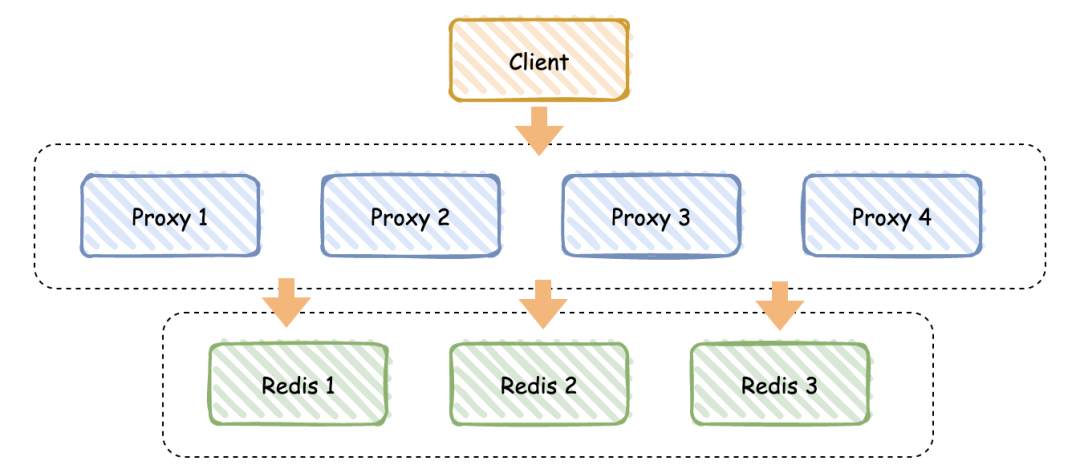
你可以看看,你们公司的 Redis 使用的是哪种方案呢?对于“客户端方案”,其实有的也不用自己去写,比如负责维护 Redis 的部门会提供不同语言的 SDK,你只需要去集成对应的 SDK 即可。
3. 高可用原理
3.1 Redis 主从
Redis 基本都通过“主 - 从”模式进行部署,主从库之间采用的是读写分离的方式。
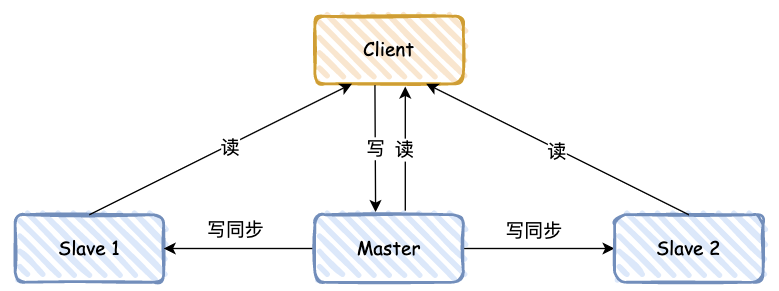
同 MySQL 类似,主库支持写和读,从库只支持读,数据会先写到主库,然后定时同步给从库,具体的同步规则,主要将 RDB 日志从主库同步给从库,然后从库读取 RDB 日志,这里比较复杂,其中还涉及到 replication buffer,就不再展开。
这里有个问题,一次同步过程中,主库需要完成 2 个耗时操作:生成 RDB 文件和传输 RDB 文件。
如果从库数量过多,主库忙于 fock 子进程生成 RDB 文件和数据同步,会阻塞主库正常请求。
这个如何解决呢?答案是 “主 - 从 - 从” 模式。
为了避免所有从库都从主库同步 RDB 日志,可以借助从库来完成同步:比如新增 3、4 两个 Slave,可以等 Slave 2 同步完后,再通过 Slave 2 同步给 Slave 3 和 Slave 4。
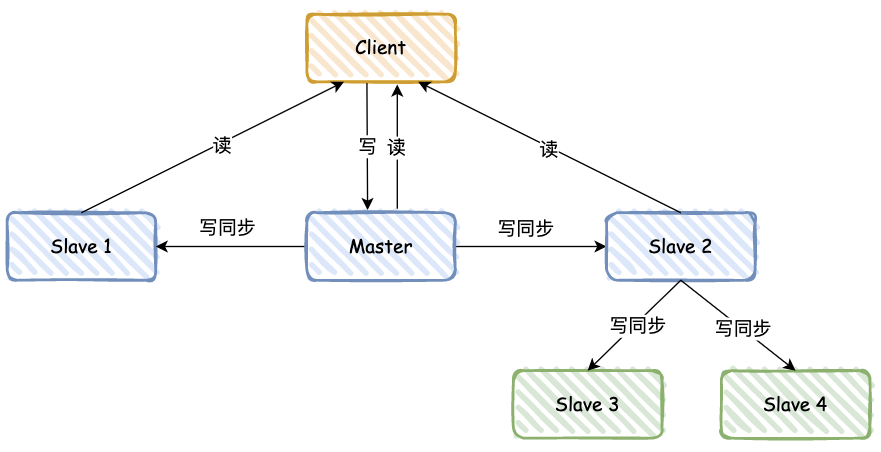
如果我是面试官,我可能会继续问,如果数据同步了 80%,网络突然终端,当网络后续又恢复后,Redis 会如何操作呢?
3.2 Redis 分片
这个有点像 MySQL 分库分表,将数据存储到不同的地方,避免查询时全部集中到一个实例。
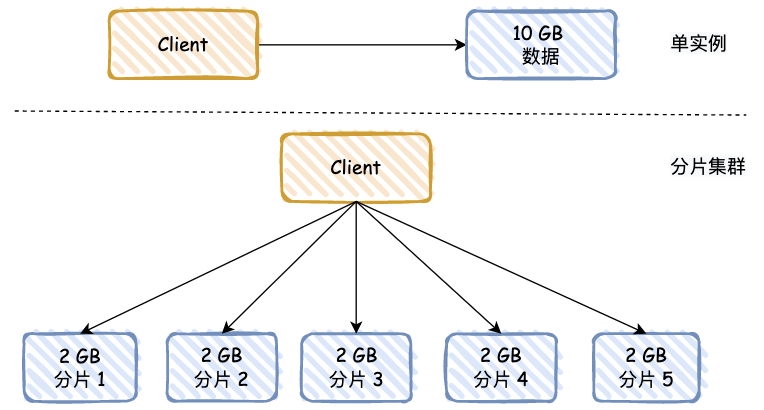
其实还有一个好处,就是数据进行主从同步时,如果 RDB 数据过大,会严重阻塞主线程,如果用分片的方式,可以将数据分摊,比如原来有 10 GB 的数据,分摊后,每个分片只有 2 GB。
可能有同学会问,Redis 分片,和“主 - 从”模式有啥关系呢?你可以理解,图中的每个分片都是主库,每个分片都有自己的“主 - 从”模式结构。
那么数据如何找到对应的分片呢,前面其实已经讲过,假如我们有 3 台机器,常见的分片方式为 hash(IP)%3,其中 3 是机器总数,hash 值为机器 IP,这样每台机器就有自己的分片号。
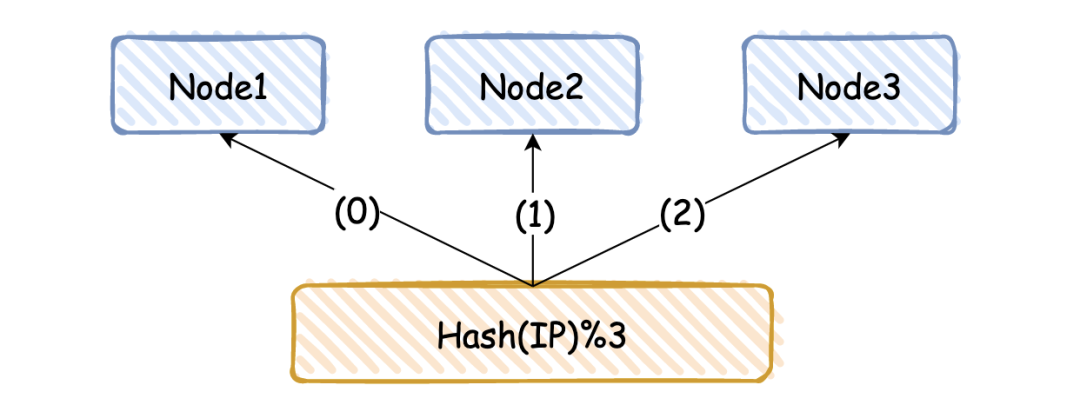
对于 key,也可以采用同样的方式,找到对应的机器分片号 hash(key)%3,hash 算法有很多,可以用 CRC16(key),也可以直接取 key 中的字符,通过 ASCII 码转换成数字。
3.3 Redis 哨兵机制
3.3.1 什么是哨兵机制 ?
在主从模式下,如果 master 宕机了,从库不能从主库同步数据,主库也不能提供读写功能。
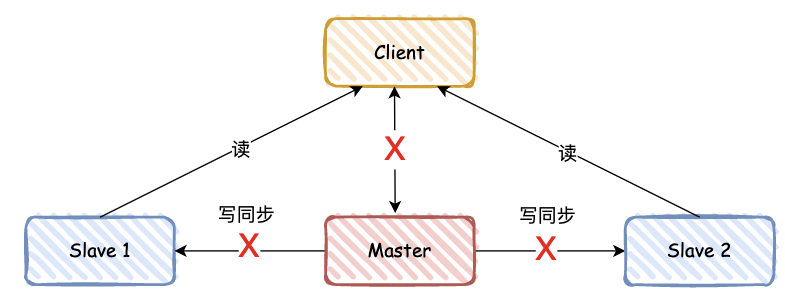
怎么办呢 ?这时就需要引入哨兵机制 !
哨兵节点是特殊的 Redis 服务,不提供读写服务,主要用来监控 Redis 实例节点。
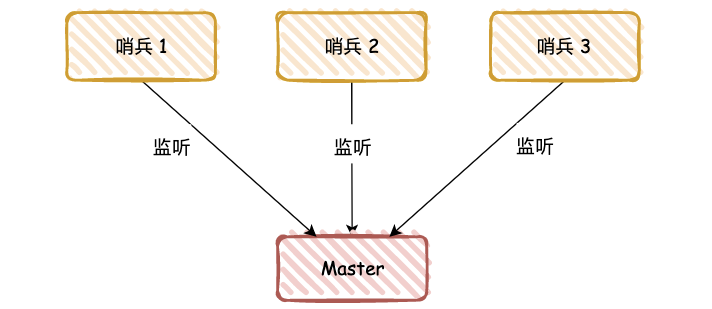
那么当 master 宕机,哨兵如何执行呢?
3.3.2 判断主机下线
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状态,如果哨兵发现主库或从库对 PING 命令的响应超时了,哨兵就会先把它标记为“主观下线”。
那是否一个哨兵判断为“主观下线”,就直接下线 master 呢?
答案肯定是不行的,需要遵循 “少数服从多数” 原则:有 N/2+1 个实例判断主库“主观下线”,才判定主库为“客观下线”。
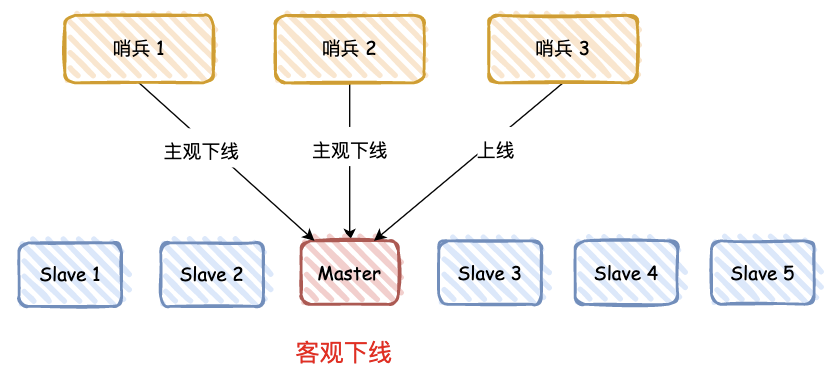
比如上图有 3 个哨兵,有 2 个判断 “主观下线”,那么就标记主库为 “客观下线”。
3.3.3 选取新主库
我们有 5 个从库,需要选取一个最优的从库作为主库,分 2 步:
筛选:检查从库的当前在线状态和之前的网络连接状态,过滤不适合的从库;
打分:根据从库优先级、和旧主库的数据同步接近度进行打分,选最高分作为主库。
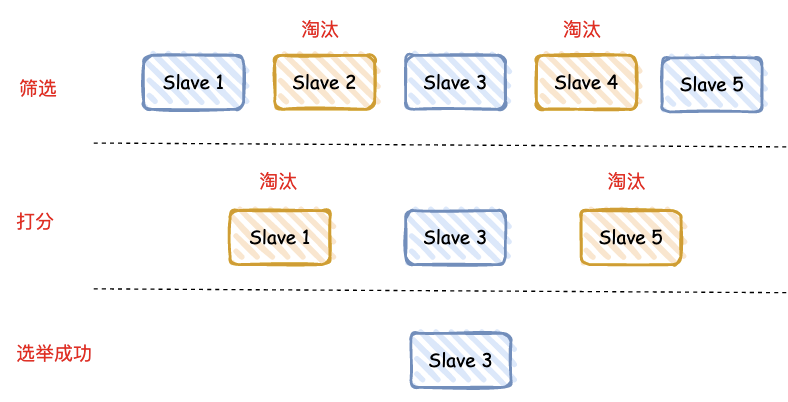
如果分数一致怎么办 ? Redis 也有一个策略:ID 号最小的从库得分最高,会被选为新主库。
当 slave 3 选举为新主库后,会通知其它从库和客户端,对外宣布自己是新主库,大家都得听我的哈!
今天就讲这么多,我们下期见,大家都学废了么 ?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK