

压缩法与深度网络的泛化性
source link: https://changkun.de/blog/posts/compression-and-dnn-generalization/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
压缩法与深度网络的泛化性
Published at:
2018-03-26
|
Reading: 4362 words ~9min
|
PV/UV: 21/17
本文译自:http://www.offconvex.org/2018/02/17/generalization2/ 译者:欧长坤
本文是关于我最新的论文并提供了一些之于我之前一篇文章新的关于「泛化谜题」的观点。
这篇新论文引入了一个基于压缩的基本框架来证明泛化界。并表明深度网络的是高度噪音稳定并可进行压缩。这个框架同时还未去年的一些论文提供了简单的证据(下面会讨论)。
回忆关于泛化理论的基本定理:具有 mm 个样本的训练集则泛化误差(定义为训练数据和测试数据之差)是 Nm−−√Nm 的高阶项,其中 NN 是网络的有效参数(或复杂度度量);它最多可能是实际参数数,但实际上可能会少得多(为了便于说明,这篇文章将忽略 logNlogN等这些在计算中产生的干扰因素)。泛化之谜在于:当网络参数量高达百万级时即便当 m=50Km=50K,网络同样具有相当低的泛化误差(比如 CIFAR10)。反过来想,从某种意义上来说这似乎在告诉我们,网络的实际的参数量是远低于 50K50K 的。
这里N是网络的有效参数(或复杂性度量)的数量; 它至多是可训练参数的实际数量,但可能会少得多。 (为了便于说明,这篇文章将忽略\ logN等这些也出现在这些计算中的讨厌因素)。神秘的是,即使当m = 50K时,具有数百万参数的网络也具有低泛化误差(如在CIFAR10数据集中) ,这表明真实参数的数量实际上远低于50K。
Bartlett et al. NIPS'17 与 Neyshabur et al. ICLR'18 尝试类似于 PAC-Bayes 和 Margin 的有趣想法对复杂度度量进行量化(同时也影响了我们的论文)。但终究这种量化是不切实际的——量级比实际参数量还要多。相比之下,我们的新估计值要好几个数量级,并且更加有意义。下面的条形统计图进行了说明(所有的 bound 都忽略了干扰因素,可训练参数的数量仅用于表示比例):
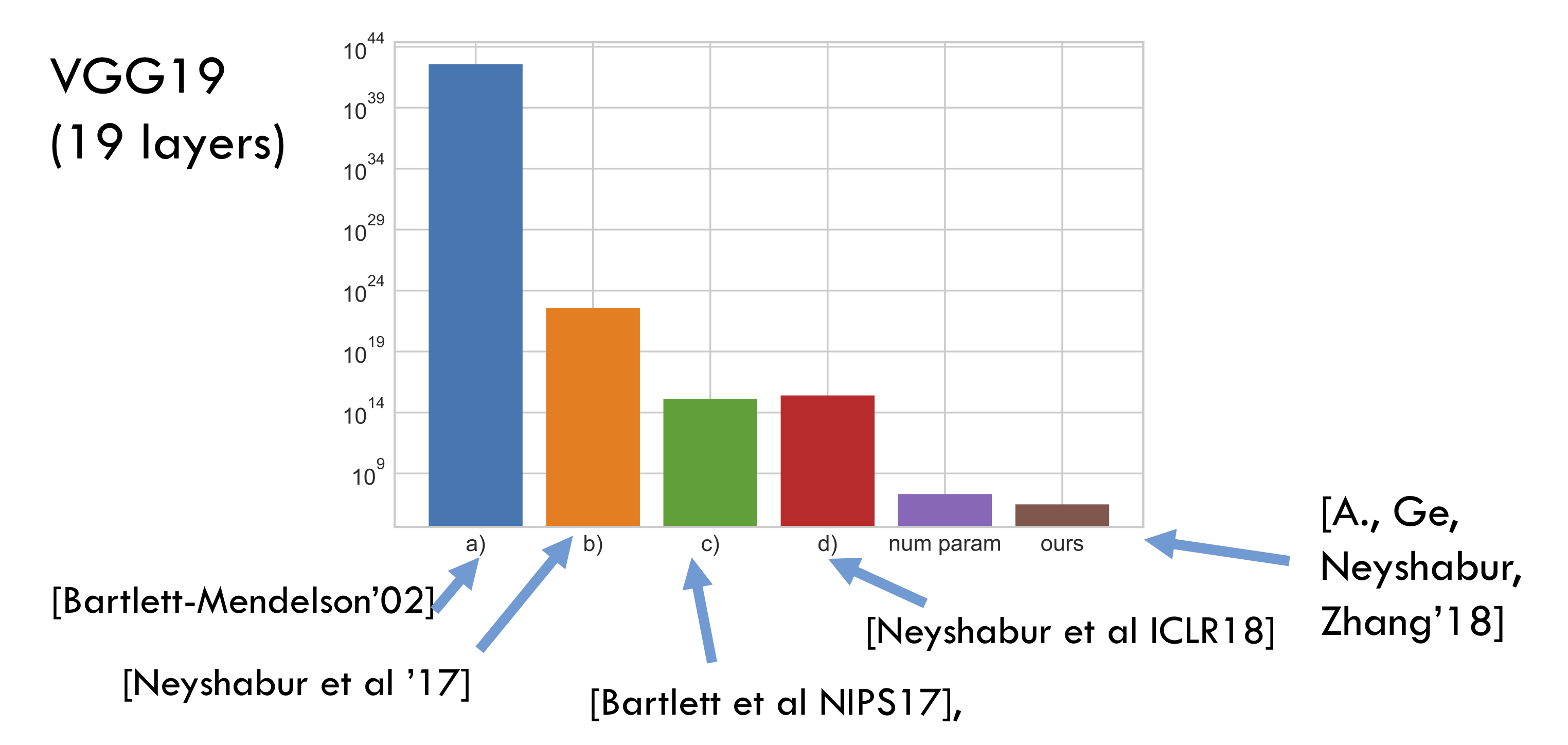
「压缩」法
压缩法尝试对一个具有 NN 个可训练参数的深度网络 CC 压缩到另一个具有更少参数 N^N^ 、几乎相同训练错误的网络 C^C^。于是,只要训练样本的数量超过 N^N^,上面的基本定理就保证了,那么 C^C^ 就可以获得更好的泛化能力(即使 CC 没有)。对这种这种方法的扩展表明,如果我们让压缩算法依赖于某个任意长的随机字符串,只要在接触训练数据之前固定这个字符串,那么就能得到相同的结论。 我们将这种依赖固定串的压缩法,并以此为基础。
请注意,上述方法仅证明了压缩后的 C^C^ 具有较好的泛化性能,而并没有对原始的 CC 加以保障。(我觉得这些想法可能延伸到证明原始 CC 同样具有良好泛化能力,这种障碍应该只是技术性的)。一些早期的使用 PAC-Bayes 界的方法,这也证明了一些与 CC 相关的网络的泛化,而不是 CC 本身的泛化。 (经典文献 Langford-Caruana2002 的标题说明了一切。)
在实践中,深度网络可以使用一系列想法进行压缩,见这篇综述。然而,通常这种类型的压缩通常还包含对神经网络的再次训练,而我们的论文则没有考虑再训练的情况(因为他涉及对损失函数的推理),这也是未来的研究方向。
平坦极小值与噪声稳定性
如今的泛化能力结果通过对损失函数_平坦极小值(flat minimum)_的形式化进行处理。最早在上个世纪九十年代,Hochreiter 和 Schmidhuber 1995 就猜测平坦极小值是表现出泛化的根源。最近 Keskar et al 2016 的经验研究表明,损失函数的平坦度确实与泛化性存在一些关系。我们将在后面的文章中讨论这个问题到底有多复杂。
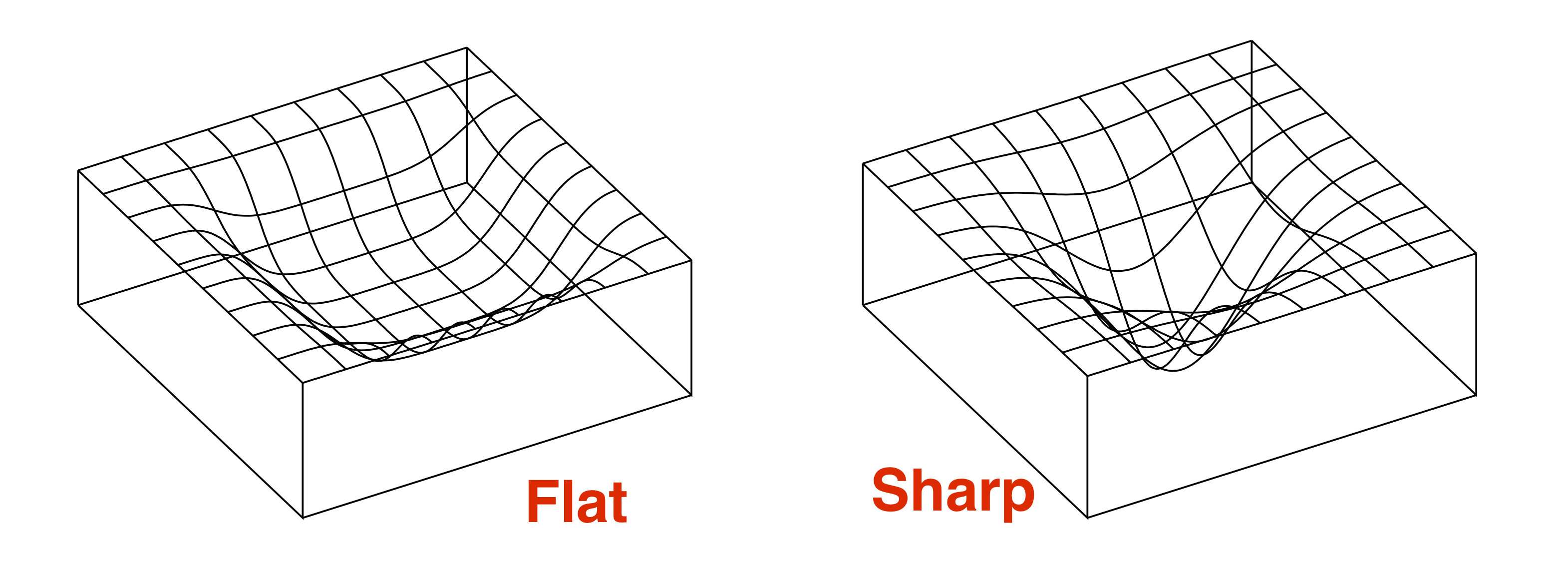
我们先来聊一聊关于平坦极小值为什么会泛化得更小的原因(由 Hinton and Camp 1993 提出)。简单来说,如果在平坦极小值所在的区域是一个在损失函数表面上占据大小为 ττ 的「体积」的区域(如果极小值区域越平,则ττ越大)于是损失函数中,严格平坦极小值区域的数量最多为 S=总「体积」τS=总「体积」τ。因此,我们可以将全部的平坦极小值区域从 1 到 SS 进行编号,这也就意味着平坦极小值可以用 logSlogS 个 bit 进行表示(信息编码的结果,译者注)。那么文章最前面提到的基本定理其实就意味着如果训练样本的数量超过 logSlogS 那么平坦极小值就会泛化得更好。
PAC-Bayes 方法试图通过定义平坦极小值来形式化上述直觉:如果网络 CC中,使得其训练样本增加适当比例的高斯噪声并不会大大影响训练误差,那我们就称这样的区域为一个平坦极小值区域。这样可以根据概率/度量来对上面所说的「体积」一词进行量化(具体参见我的讲义或这篇Dziugaite-Roy论文),并对样本复杂性进行一些明确的估计。可惜的是,我们已经证明了从这个计算中要获得良好的定量估计相当困难,正如前面的条形图所示。
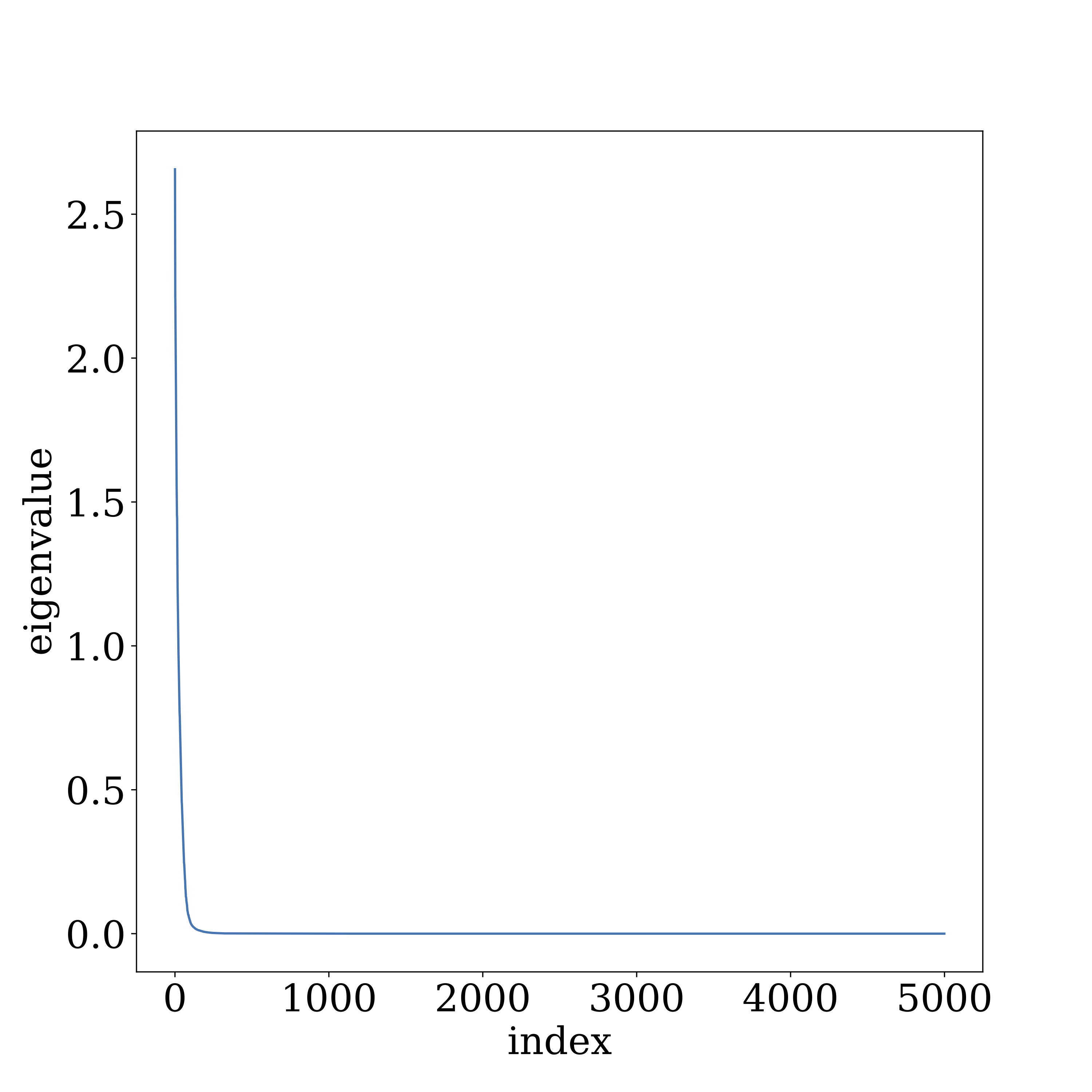
现在我们使用稍微不同的噪声稳定性来对「平坦最小值」进行形式化描述。 简单地说,如果我们在某层的输出处注入具有一定缩放因子的高斯噪声,那么随着噪声传播到更高层,这个噪声就会衰减(这里「顶部」方向是指网络的输出方向)。虽然他还没有在网络中以训练的方式出现,但它显然是和 Dropout 有关系。下图说明了在 VGG19(使用 CIFAR10 数据集)某一层注入的噪声是如何影响较高层的。 y 轴作为一层中被计算向量乘积的噪声的幅度( ℓ2ℓ2 范数),并展示了单个噪声向量在传播层时如何快速衰减。
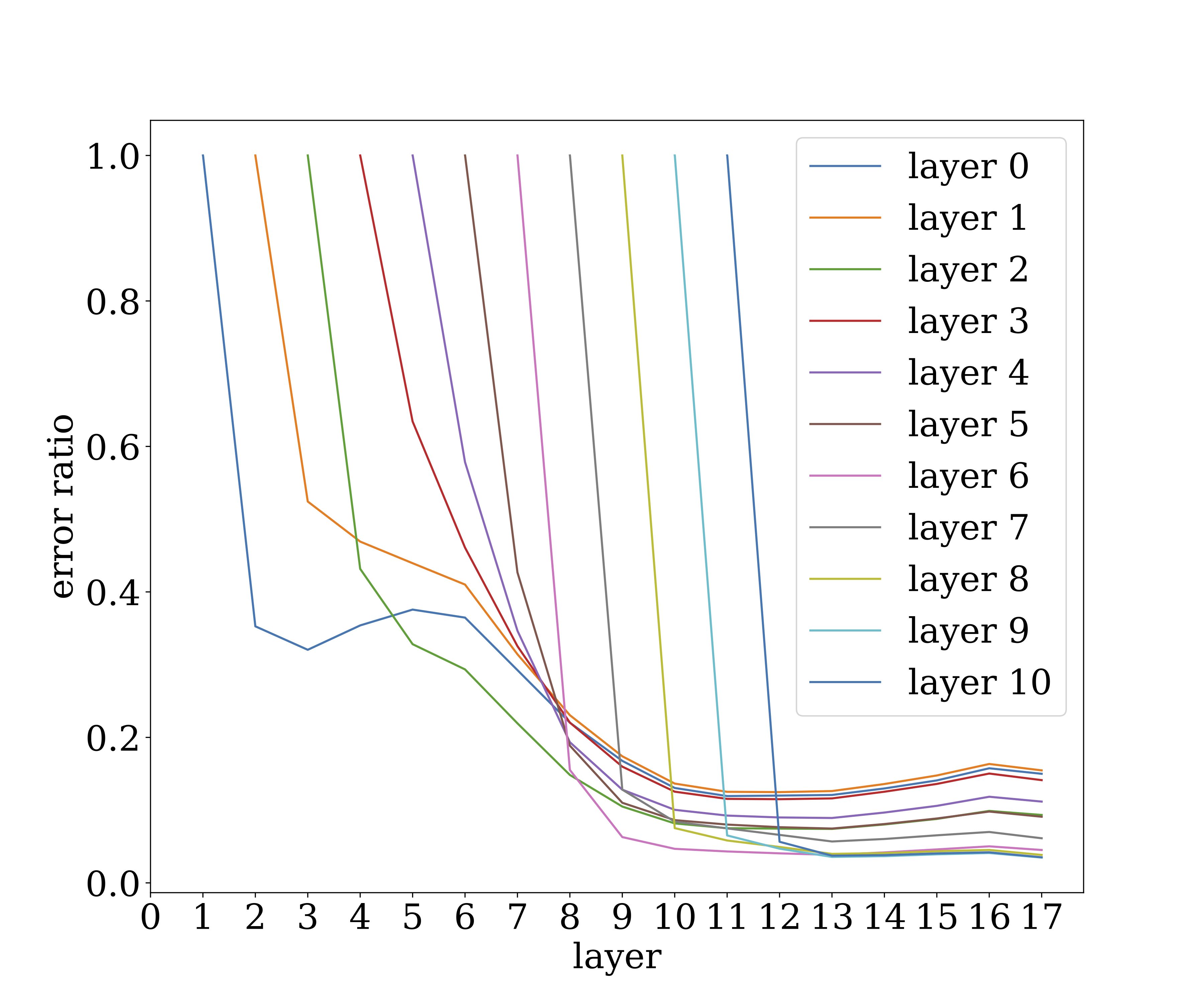
显然,训练网络的计算是具有很强的抗噪声能力的。这似乎在暗示生物圣经网络。注意,这里的训练并没有涉及明显的噪声(例如 dropout)。当然随机梯度下降会隐式的将噪声添加到梯度中去,如果噪声稳定性来自于此或别的什么地方,那么更加严格的研究是很有必要的。
噪声稳定性及单层网络的可压缩性
为了理解什么噪声稳定的网络是可压缩的,我们首先来理解一个神经网络的单层噪声稳定性,这里我们忽略了非线性变换的因素。因此,这一层仅仅只是一个线性变换,即矩阵 MM
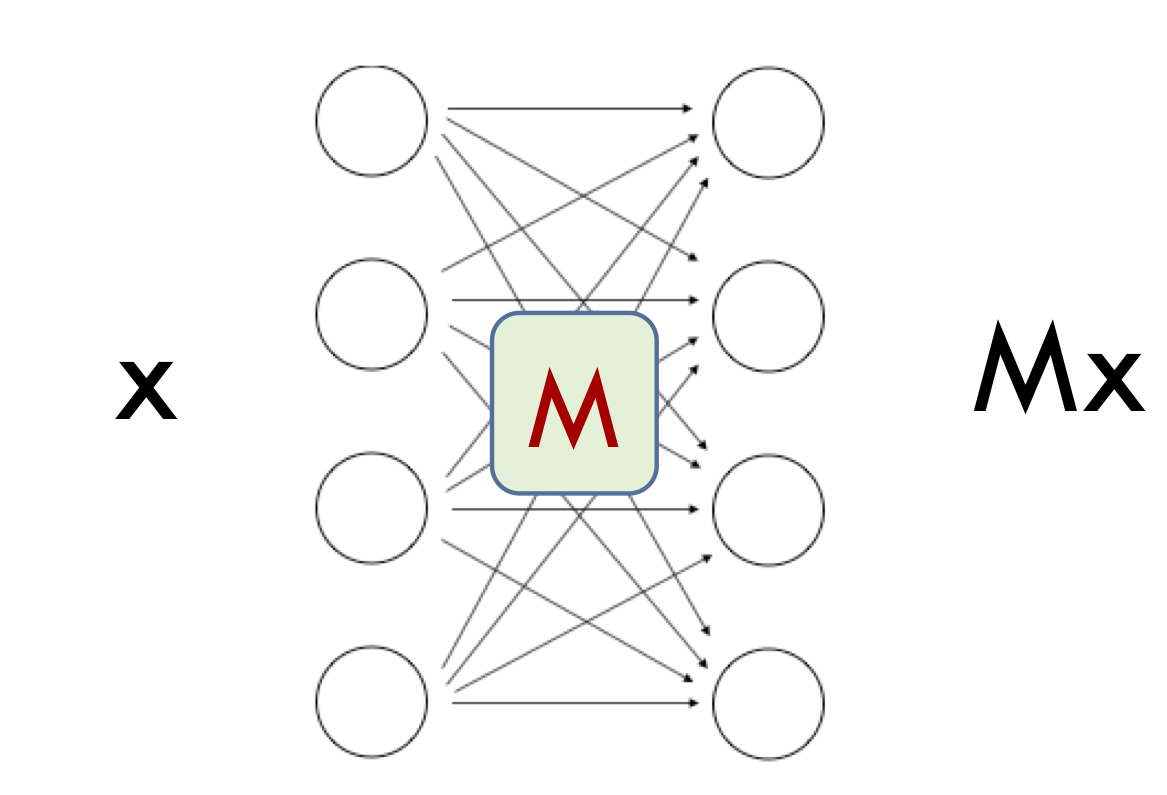
矩阵的输出对噪声稳定是什么意思呢?假设上一层的输出向量是一个单位向量 xx,那么 xx 可以被认为是当前层的「信号」。矩阵将 xx 变换为 MxMx。如果我们在注入单位范数的噪声向量 ηη,那么输出就会变成 M(x+η)M(x+η)。如果这样的噪声对输出的影响很小,我们就说 MM 对于输入 xx 是噪声稳定的。这表明 MxMx 的范数要远大于 MηMη 的范数。 前者不超过 σmaxMσmaxM,即矩阵 MM 的最大奇异值。后者约为 (∑iσi(M)2)1/2/h−−√(∑iσi(M)2)1/2/h,其中 σiMσiM 表示矩阵 MM 的第 ii 个奇异值,而 hh 是 MxMx 的维数。这是因为在于高斯噪声可以在每个方向上进行分解,且每个方向上的方差为 1h1h。于是,我们的结论是:
换句话说,矩阵 MM 具有奇异值不均匀分布的特点。不等式的左边和右边的比例称之为稳定秩,其最大值不超过其线性代数秩。此外,上述分析表明,「信号」xx 与奇异值更大的奇异方向有关,奇异值是噪声稳定性产生的根源。
我们在 VGG 和 GoogleNet 上进行了实验,实验结果表明深度神经网络的高层网络中(即大部分参数)确实表现出了及其不均匀的奇异值分布,并且信号与更大的奇异值方向一致。下图描述了使用 CIFAR10 训练 VGG19 的第十层的结果。
多层网络的压缩
上面关于噪声稳定性的分析不能保证跨多层的深度网络,这是因为非线性的因素的存在,从而缺少奇异值的符号表示。因此,噪声稳定性使用了雅克比矩阵进行形式化,这个矩阵描述了输出如何对输入的微小扰动作出反应。噪声的稳定性表明,这种非线性映射相比信噪比向量来说,能够传递来自前一层更强的信号。
我们的压缩算法对每一层的矩阵都使用了一个随机变换(注意随机性的使用,它适用于我们希望的「使用固定的字符串进行压缩」的框架),它依赖于每层低稳定秩的条件。这种压缩会适当的在每层引入误差,然而由于我们在压缩的过程中使用了随机的性质,从而使得此类误差类似于高斯误差。进而这个错误会被高层网络所压缩。
关于所有关于噪声稳定性质的形式化描述以及实验的细节可以在论文中找到。
现有泛化界的简单证明
在论文中,我们还是用了我们的压缩框架给出了过去一年间出现的泛化界的简单证明。例如 Neyshabur 等人的论文给出了这种形式的误差上界,其中 AiAi 是第 ii 层的矩阵:
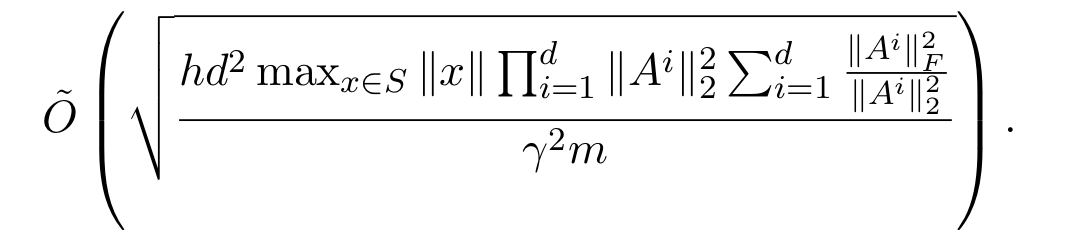
与上面提到的基本定理相比,我们意识到这个公式中的分子其实对应了有效参数的个数。表达式的第二项则表示了矩阵的稳定秩之和,这是一个很自然的复杂性度量。第一项则是层矩阵谱范数(即最大奇异值)的乘积,正好是整个网络 Lipschitz 常数的上界(映射 ff 的 Lipschitz 常数是指常数 LL 使得 f(x)≤Lc|˙x|f(x)≤Lc|˙x|)。
如果输入 xx 出现在网络的底层,那么每个连续的层可以将其范数乘至顶部的所有最大奇异值,而 ReLu 非线性只能降低矩阵的范数,它的唯一操作就是使某些数值归零,这也就是矩阵谱范数的乘积是 Lipschitz 常数的原因。
对上面的表达式进行分解后,可以很清楚的将其解释为网络(确定性)压缩的分析。通过(奇异值分解)将(小于某个阈值的)奇异值归零来压缩每一层,并期望它能变为低秩矩阵(回想一下,秩为 rr 的矩阵可以用 2nr2nr 个参数表示)。一个简单的计算表明,剩余的奇异值的数量最多为矩阵的稳定秩除以 t2t2。如何设定 tt 呢?截断会在网络曾的计算中引入误差,这个误差会向高层传播并最多由 Lipschitz 常数放大。我们想使这个传播的误差很小,则可以通过使其余 Lipschitz 常数成反比来完成。这最终导致了有效参数数量上的限制。
这个证明的概述还解释了我们是如何改进之前的这个工作:它们还能(隐式地)压缩深度网络,但是对压缩可能性的分析不够可靠,因为它们假设网络已通过 Lipschitz 常数来传递噪声。
推广至卷积网络
在早期的论文中还不能清晰的处理卷积网络。我必须承认,处理卷积会困扰我们一段时间。卷积网络中的一个图层将相同的过滤器应用于该图层中所有的修补程序。这种权重共享意味着整个矩阵已经具有相当紧凑的表示,并且将其压缩会有一定的挑战性。然而类似于 VGG 和 GoogleNet 这样的网络,在高层中使用较大的滤波器矩阵(即使用大量信道),并且我们可以期待压缩这种单独的滤波器矩阵。
现在来考虑两个天真的想法。首先是在不同的卷积核中压缩滤波器。可惜的是,这不是压缩,因为每个滤波器的拷贝都有自己的参数。第二个想法是对滤波器进行单个压缩,并在每个卷积核中使用压缩的拷贝。然而这会导致分析出错,因为根据不同拷贝中压缩引入的误差是彼此相关联的,然而分析过程要求他们应该服从高斯分布。
最终,我们的想法是使用 逐 kk 独立滤波器(想法来自哈希方法)进行压缩,其中 kk 大约为训练样本数量的对数。
尽管泛化理论在某些时候可能看起来仅仅是学术性问题,因为在实践中,测试数据确立了泛化能力。我希望你从上文中可以看出一些可以用来理解深度网络泛化能力的有趣见解。对已经训练好的深度网络的噪声稳定性的研究显然与生物神经网络的研究存在联系(请参考von Neumann关于噪声的适应计算的基本思想)。
与此同时,我觉得可压缩性只是泛化谜题的一小部分,我们仍然缺少一些重要的想法。我并没有从上面的想法中看到如何证明 VGG19 的有效参数量能够被降低至 50k。我怀疑完成这样的工作必须要求我们对数据的结构本身有足够多的认识(真实图像),而上面的分析并没有考虑这一点,我们只用到了深度网络与实际数据相配合比与噪声配合更加好这一唯一的与数据相关的性质。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK