

ELK+Redis 最佳实践
source link: https://changkun.de/blog/posts/elk-redis-best-practice/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
ELK+Redis 最佳实践
Published at:
2016-07-17
|
Reading: 3362 words ~7min
|
PV/UV: 11/11
上个月老板让我搭一个日志分析系统,选用了 ELK 作为技术栈,网上的文章较为混乱,前期刚接触的时候查资料踩了很多坑,所以根据我总共一个星期的接触(包括安装和后期运维),大致总结一下我个人的最佳实践。
本文主要内容为:
这张图相信足以证明 ELK Stack 的强大之处了:
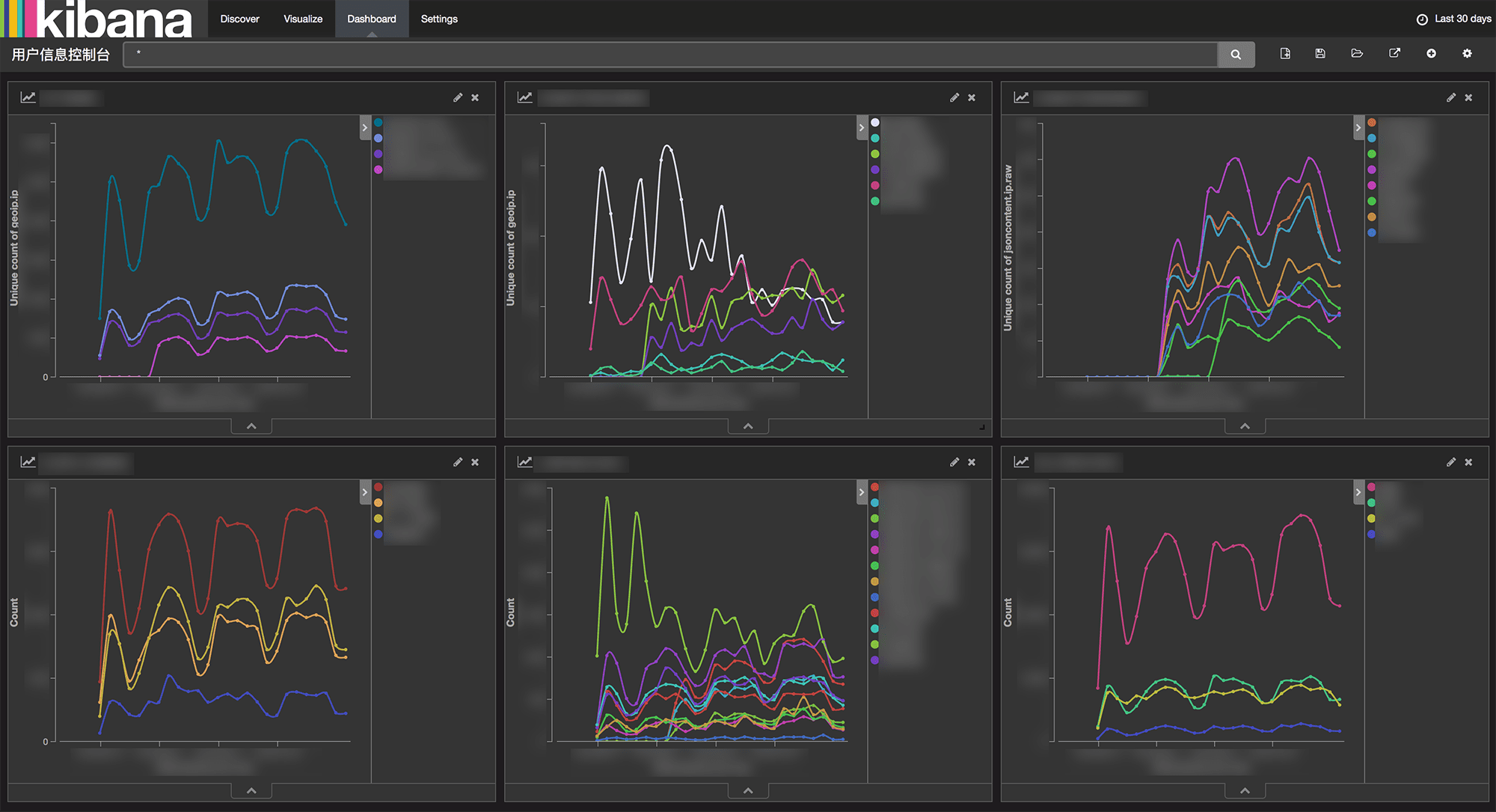
E(lasticsearch) L(ogstash) K(ibana) 本身这里并不做过多介绍。
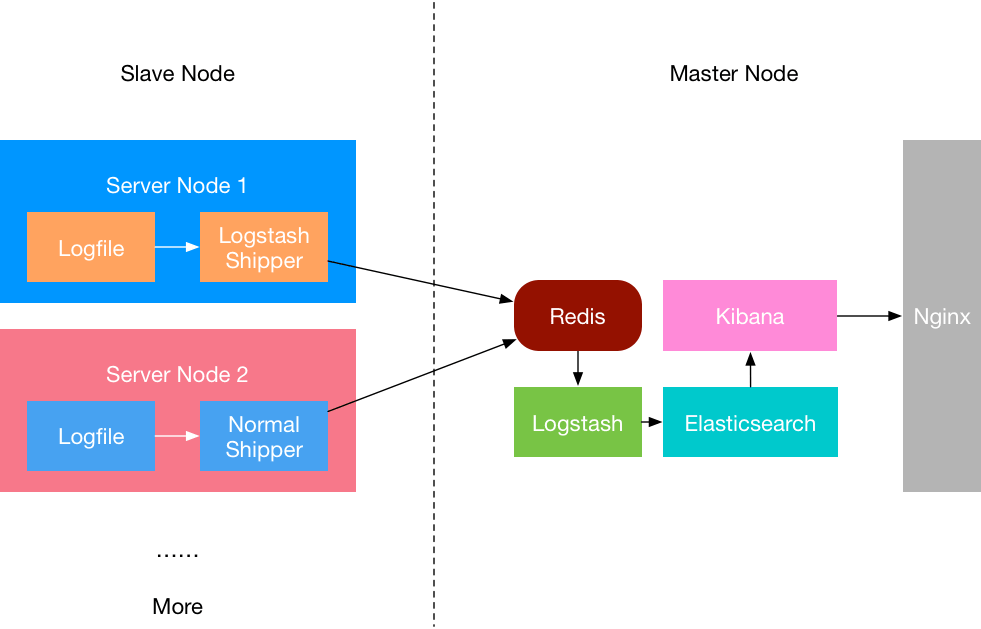
值得一提的是,为了让整个系统更好的分层,是非常建议引入 Redis 的。Redis 作为一个缓存,能够帮助我们在主节点上屏蔽掉多个从节点之间不同日志文件的差异,负责管理日志端(从节点)的人可以专注于向 Redis 里生产数据,而负责数据分析聚合端的人则可以专注于从 Redis 内消费数据。
同时,Kibana 本身并不具备访问限制,这不是我们期望的,因此可以用考虑用 Nginx 做一层反向代理,并做身份验证。
综上所述,整个 ELK 的架构应该是下图所示的样子:
安装可以有很多方式,在 elastic 官网 里也提供了下载安装的功能,但事实上 ELK 更应该作为一种服务被运行在机器上,所以使用包管理是必不可少的。
本文以
Ubuntu 14.04为例,其他平台雷同
一般情况下,纯净的 Ubuntu 14.04 环境是不具备诸如
Java/Redis/Nginx/Git等一系列基础环境的。
-
安装 ELK 之前要先检查当前系统环境,使用
uname -a查看基本的系统信息。 -
ELK 依赖 Java 环境,使用
sudo apt-get install default-jre安装。 -
我们要引入 Redis 和 Nginx,所以使用
sudo apt-get install redis-server nginx安装。 -
安装好后不要着急启动服务。
安装 ELK 本体
-
- 加 Key:
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
-
- 在
/etc/apt/source.list.d/下创建elk.list,添加最新的安装源:
- 在
deb https://packages.elastic.co/elasticsearch/2.x/debian stable main
deb https://packages.elastic.co/logstash/2.3/debian stable main
deb http://packages.elastic.co/kibana/4.5/debian stable main
注意,这里的源提供了为 ELK 提供的版本是目前(2016.07)最新的版本,分别为:2.x, 2.3, 4.5。
sudo apt-get update && sudo apt-get install elasticsearch logstash kibana
-
- 现在可以使用
sudo service来管理全部服务了,这一共包括elasticsearch, logstash, kibana, redis, nginx。
- 现在可以使用
sudo service elasticsearch status
sudo service logstash status
sudo service kibana status
sudo service redis status
sudo service nginx status
-
- 同样,不要着急启动这些服务。
目录树和权限配置
ELK 整个技术栈作为一套完整服务,建议将所有的相关内容都放置到一个目录下进行管理。这里以 /elk 为例,将所有的内容都按下面的目录树进行整理:
elk
├── elastic
│ ├── data
│ └── logs
├── kibana
│ ├── data
│ └── logs
├── logstash
│ ├── data
│ └── logs
├── nginx
│ ├── data
│ └── logs
└── redis
├── data
└── logs
这么进行分类的好处是方便进行权限管理,例如整个 elastic 目录下的用户和组都可以使用 chown 递归设置为 elasticsearch:
chown -hR elasticsearch:elasticsearch elastic
chown -hR logstash:logstash logstash
chown -hR kibana:kibana kibana
chown -hR redis:redis elastic
chown -hR root:root nginx
Redis 配置
Redis 作为 Logstash Shipper 和 Logstash Master 之间的缓存服务,只要启动它,就能够保证在维护 Elasticsearch 主节点的时候即便停止 Logstash 和 Elasticsearch,也能够保证日志数据的连续性。
注意,停用 Logstash 和 Elasticsearch 服务时,应该先停用 Logstash,再停用 Elasticsearch。这是因为当 Elasticsearch 被先停用时,Logstash 依然会从 Redis 中消耗数据,但发送给 Elasticsearch 之后由于 Elasticsearch 服务已经停止而导致本应本 Elasticsearch 持久化的日志应发送失败而消失。
Redis 的配置文件位置为 /etc/redis/redis.conf 。
一般情况下,不建议修改服务的默认端口号,这里只讨论和 ELK 栈相关的配置服务,其他配置不进行讨论。主要修改的几个配置为:
- bind 不应该开放给外网,所以:
bind <内网 IP> <127.0.0.1> - logfile 存储到
/elk/redis/logs,所以logfile /elk/redis/logs/redis-server.log dump.rdb落地文件存储到/elk/redis/data所以dir /elk/redis/data- 创建好日志文件
touch /elk/redis/logs/redis-server.log
确认好这些配置后,可以启动 redis 服务了:
sudo service redis-server start
sudo service redis-server status
# 检查启动是否成功,若失败,主要检查配置文件是否正确配置以及相关的目录权限是否正确
Elasticsearch 配置
Elasticsearch 本身在搭建之初并不需要做过多配置,但是有几个比较关键性概念和配置会影响到后期的查询结果,这里做一些罗列。
-
结果不准确
在 Kibana 里直接搜索结果的时候有时候会发现搜索 “Hello " 比搜索 “Hello World” 的结果还要少,这是有悖常理的,这里面涉及到 Elasticsearch 的一个概念叫做『Mapping』,具体参考这里,大致意思就是 Elasticsearch 会对对象类型进行推断,若推断为不准确的类型就会影响查询的结果,由于 Elasticsearch 在索引建好后是不能够修改 Mapping 的,因此在 Elasticsearch 创建索引之前就应该配置好各字段的 Mapping 关系,建好后,可以
curl -XGET 'localhost:9200/_mapping?pretty'进行查看。 -
查询精度偏差太大
整个平台搭建完后,本身并没有什么问题,老板问我,为什么有时候 Kibana 显示的统计结果会明显高于站点里的诸如百度统计 CNZZ 这类的统计服务?日活偏差高达四五千。
这其实是 Elasticsearch 的一个『坑』。Elasticsearch 给出的是统计的估计值,这是由 Elasticsearch 内置的 HyperLogLog+ 查询算法决定的,具体可以参考这里。总而言之就是,查询精度越高,搜索性能越差。Elasticsearch 的精度阈值最大值可以为 40000,正常情况下将精度设置为 10000就足够了,也就是说:
{"precision_threshold":10000}。
Logstash 配置
Logstash 作为日志数据到 Elasticsearch 的关键节点,它的配置非常重要。主要分为三个部分:
input{}
filter{}
output{}
客户端配置
客户端应该只负责将日志发送到 Redis 缓存中,所以这部分的配置至少应该是:
input {
stdin { }
file {
type => "nginx"
path => "/nginx/日志/路径.log"
start_position => beginning
codec => multiline {
'negate' => true
'pattern' => '^\d'
'what' => 'previous'
}
}
file {
type => "web-client"
path => "新路径"
}
}
output {
stdout { codec => rubydebug }
if [type] == "nginx" {
redis {
host => "服务端地址"
data_type => "list"
key => "logstash-service_name"
}
}
if [type] == "web-client" {
redis {
host => "服务端地址"
data_type => "list"
key => "logstash-service_name"
}
}
}
同样,有了 Redis 做缓存,有时候客户端数据可以直接按照对应的 JSON 格式向 Redis 中写入,这样服务端的 Logstash 并不会察觉到来源有何异样,从而直接消费 Redis 缓存数据。
服务端配置
由于数据处理是需要消耗服务器性能的,所以一切数据都应该交给服务端而不是客户端来处理(这也是为什么没有在客户端配置 filter{} 相关配置的原因)。因此服务端的配置会较为复杂,Logstash 有很多插件,input{}部分的解析和客户端并没有太大差别,如果涉及到多个源的情况,可以给不同源加上 type,然后在 filter{} 和 output{} 里针对不同源进行分批处理。
对于 filter{} 而言,grok{} 是一个解析日志数据的好插件,mutate{} 可以用于处理数据类型相关的转换,geoip{} 可以根据日志中的 IP 数据直接解析出更加详细直观的位置数据,date{} 用于将日期解析为 @timestamp,而 useragent 可以更佳的获得用户浏览器的属性。
input {
redis {
host => "localhost"
type => "nginx"
data_type => "list"
key => "nginx_key"
db => "1"
}
redis {
host => "localhost"
type => "json"
data_type => "list"
key => "json_key"
db => "1"
}
}
filter{
if [type] == "nginx" {
grok {
match => [ "message" , "%{COMBINEDAPACHELOG}+%{GREEDYDATA:extra_fields}"]
overwrite => [ "message" ]
}
mutate {
convert => ["response", "integer"]
convert => ["bytes", "integer"]
convert => ["responsetime", "float"]
}
geoip {
source => "clientip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
remove_field => [ "timestamp" ]
}
useragent {
source => "agent"
}
}
if [type] == "json" {
json {
source => "message"
target => "jsoncontent"
}
}
}
output {
elasticsearch { hosts => ["localhost:9200"] index => "logstash-%{+YYYY.MM.dd}"}
stdout { codec => rubydebug }
}
在最后的 output{} 部分,可以人为的将每天的日志进行存储分割,以便删除过于古老的数据。此外,Logstash 的配置统一保存在 /etc/logstash/conf.d/ 下,当 Logstash 启动后,会自动加载这个目录下的所有以 .conf 结尾的文件。
Kibana 配置
Kibana 只是一个 Web 前端,本身并没有什么高深的数据分析功能,它的出现完全得益于 Elasticsearch 提供的是 JSON 的接口,这就造就了 Kibana。
正是由于 Kibana 本身只是一个 Web 前端,所以无法直接控制对这个页面的访问。Kibana 服务运行后,会默认跑在 localhost:5601 上,这样如果服务器一旦向外界暴露,那么外界就能够直接通过5601 访问到这个页面,这是不能接受的,因为我们自然不会希望将日志数据向大众开放。
因此,我们要让整个服务跑在内网中,所以在 /opt/kibana/config/kibana.yml 中:
server.host: "内网 IP"
logging.dest: /elk/kibana/logs/kibana-std.log # 日志同一存放到 /elk 下
Nginx
配置好Kibana 在内网中访问并没有结束,因为如果整个 Web 跑在了内网,是没办法从外界访问到的。这时候 Nginx 要做的,就是做一层反向代理:
server {
listen 80;
server_name kibana_server;
access_log /elk-core/log/kibana/kibana_access.log;
error_log /elk-core/log/kibana/kibana_error.log;
location / {
# 反向代理
proxy_set_header Host $proxy_host;
proxy_pass http://内网IP:5601$request_uri;
# 访问控制
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/.htpasswd;
}
}
这里面使用了 auth_basic 和 auth_basic_user_file 进行配置,这个配置文件是由:htpasswd -c ~/passwd.db <用户名>进行设置的。
Docker 方案
Docker 已经是这两年来最热门的技术之一了,如果使用 Docker 几乎不会出现各种安装上的困难,同时还能方便管理。
这里推荐一个还算不错的 Docker镜像,具体的实践,就留给另一篇文章了。
一些有用的链接和资料
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK