

Java 虚拟机原理 (六) ZGC 垃圾收集器
source link: https://blog.duval.top/2021/04/08/Java-%E8%99%9A%E6%8B%9F%E6%9C%BA%E5%8E%9F%E7%90%86-6-ZGC-%E5%9E%83%E5%9C%BE%E6%94%B6%E9%9B%86%E5%99%A8/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Java 虚拟机原理 (六) ZGC 垃圾收集器
ZGC 是 JVM 生态最新最先进的一款垃圾收集器,具有可扩展低延迟高吞吐量等特性,其设计目标包括:
- 亚毫秒级停顿时间( <= 10ms);
- 停顿时间长短与堆大小、存活对象数量、根节点数量无关;
- 支持堆大小从8MB到16TB不等;
ZGC 主要特点包括:
- 尽可能的并发;
- 基于 Region 的堆空间划分;
- 空间整理;
- 支持 NUMA-aware;
- 使用染色指针(colored pointers)
- 使用读屏障;
ZGC 之所以能实现10ms以内的低延迟,最核心原因是实现了并发的对象转移。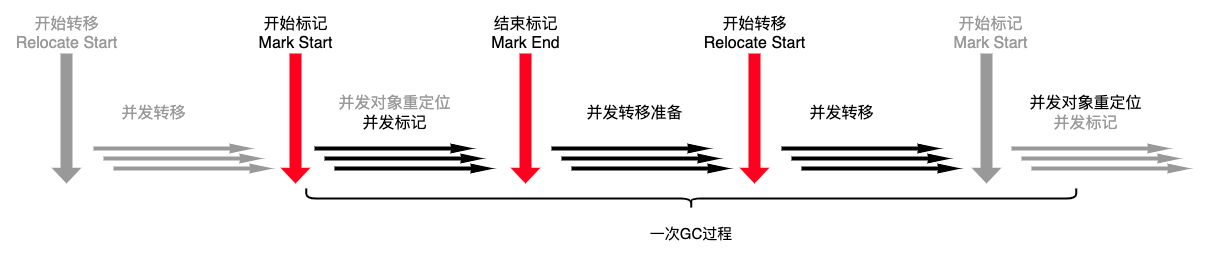
ZGC 只有三个停顿阶段:开始标记(Mark Start)、结束标记(Mark End)、开始转移(Relocate Start)。这仨阶段的最大停顿时间不超过10ms,而开始标记和开始转移两个节点只是扫描 GC Root,与堆内活跃对象数量多少没有关系。而结束标记阶段(也称重新标记阶段)的停顿时间一般小于1ms,如果超过1ms会重新进入并发标记阶段。
此外,在每一个 GC 周期的并发标记阶段都会顺便进行上一个阶段的并发对象重定位。
Region

ZGC 也是采用 Region 来划分堆空间,这点与 G1 类似,但有略有不同:
- ZGC 不采用分代划分;
- ZGC 包含三种大小类型的 Region:Small(2MB)、Medium(32MB)、Large(N * 2MB);
- ZGC 中的 Region 也称为 ZPage,空闲的 ZPage 会被记录在 ZPageCache;而空闲的 ZPage 有可能会被归还给操作系统;

ZGC 只支持64位地址系统,其中,[0~4TB) 对应Java堆,[4TB ~ 8TB) 称为M0地址空间,[8TB ~ 12TB) 称为M1地址空间,[12TB ~ 16TB) 预留未使用,[16TB ~ 20TB) 称为 Remapped 空间。
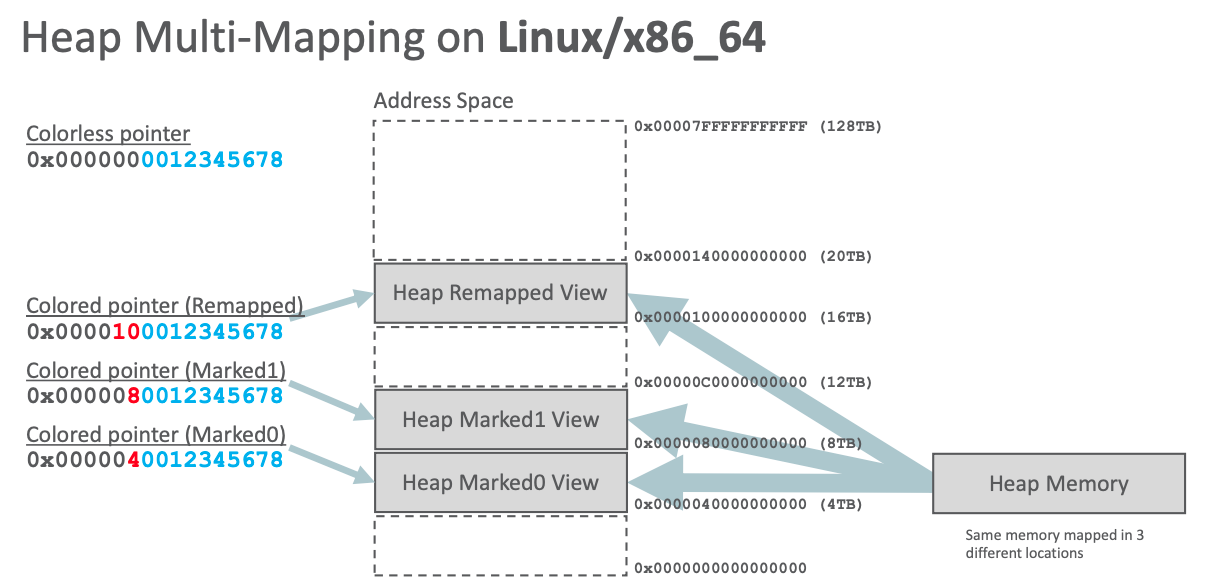
Heap Multi-Mapping on Linux:x86_64.png
因此,同一个时间点下,堆空间的某一个位置会同时有三个虚拟地址与之对应。ZGC 用这三个地址来标识该对象所处的状态,在对象转移和重定位过程中会用到这三个虚拟地址。
ZGC 在并发转移的时候会转移对象,并变更对象指针为 Remapped 空间指针。但此时应用程序中的指针还是 M0 或者 M1 空间指针,该指针也称为坏指针(bad pointer)。
如果应用线程或者GC线程访问到该坏指针并尝试从堆中读取指针背后的对象,则会尝试在读取之后通过读屏障进行指针修复,类似伪代码如下:
Object o = obj.fieldA; // Loading an object reference from heap
<load barrier needed here>
Object p = o; // No barrier, not a load from heap
o.doSomething(); // No barrier, not a load from heap
int i = obj.fieldB; // No barrier, not an object reference如上,假定 fieldA 对象已经被转移,需要被重定向。那么,第一行代码其后会被插入一段读屏障代码,代码里所做的事情就是修正当前指针为 M0 或者 M1 指针:
Object o = obj.fieldA; // Loading an object reference from heap
if (!(o & good_bit_mask)) {
if (o != null) {
slow_path(register_for(o), address_of(obj.fieldA));
}
}这个修改过程大概有4%的执行开销。
ZGC 回收过程详解
初始标记/Pause Mark Start
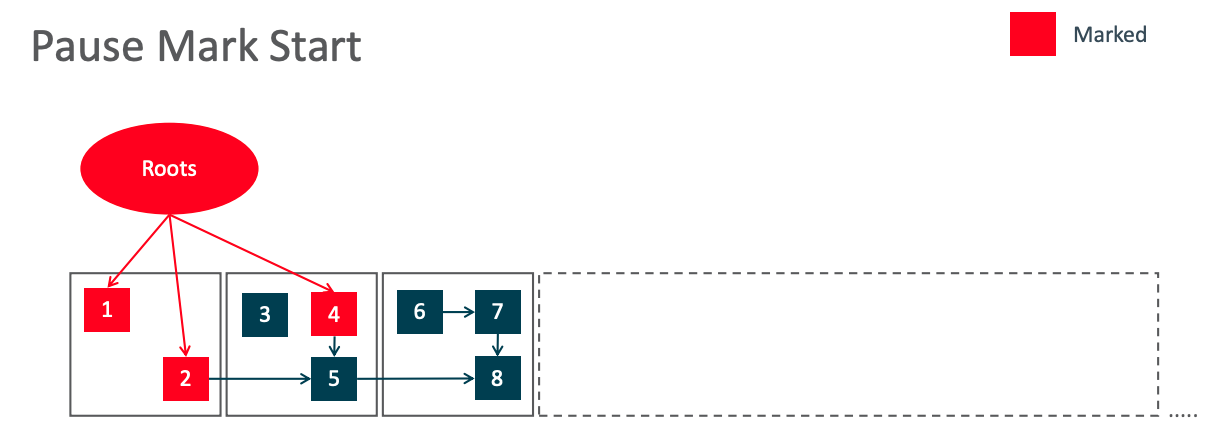
从 GC Roots 出发快速标记并其引用的对象。由于根节点集合很小,这个阶段时间会很短。
假如当前 GC 周期使用 M0 地址空间,那么被标记存活的对象1、2、4会被更新为 M0 指针。
并发标记以及并发重定位/ Concurrent Mark && Remapped
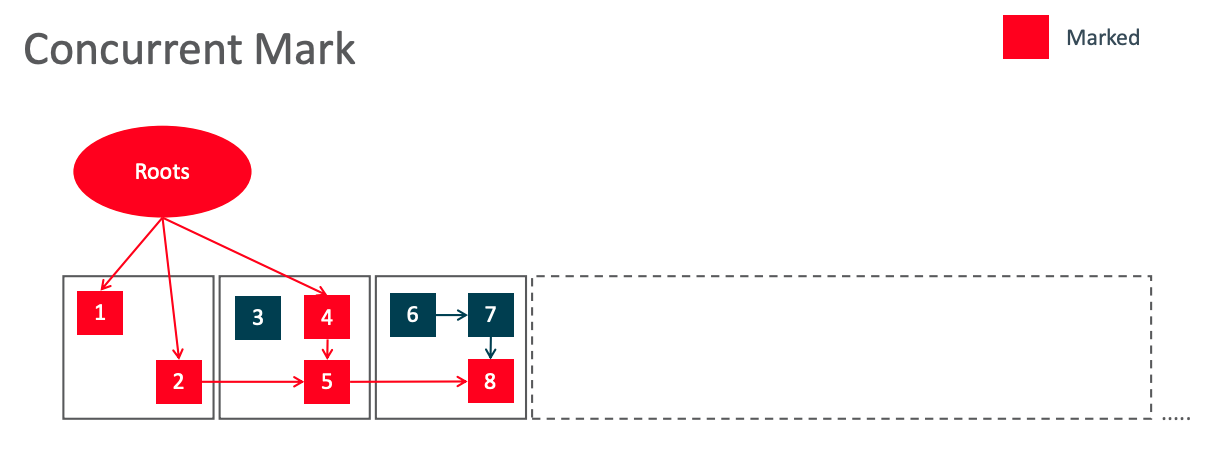
并发阶段会遍历整个堆,所有活跃对象都将得到标记。
假如当前 GC 周期使用 M0 地址空间,则对象1、2、4、5、8会被更新为 M0 地址空间。而3、6、7可能还处于上一个阶段,也就是 M1 指针。另外,坏指针也会被修复为 M0 指针。
重新标记/Pause Mark End
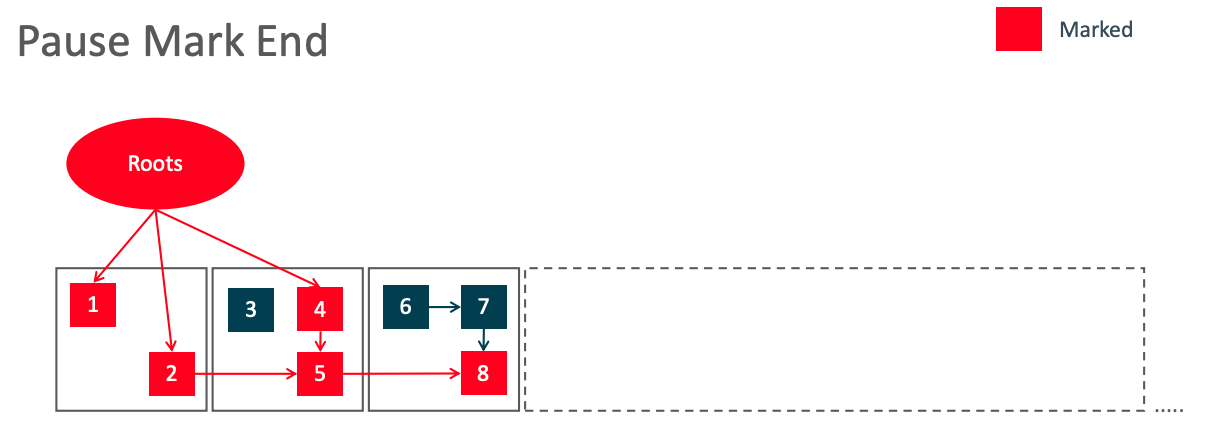
重新阶段会 STW,并做一些收尾工作。这个阶段会控制在1ms以内,超过1ms会重新回到并发标记阶段。
并发迁移准备/Concurrent Prepare for Reloc
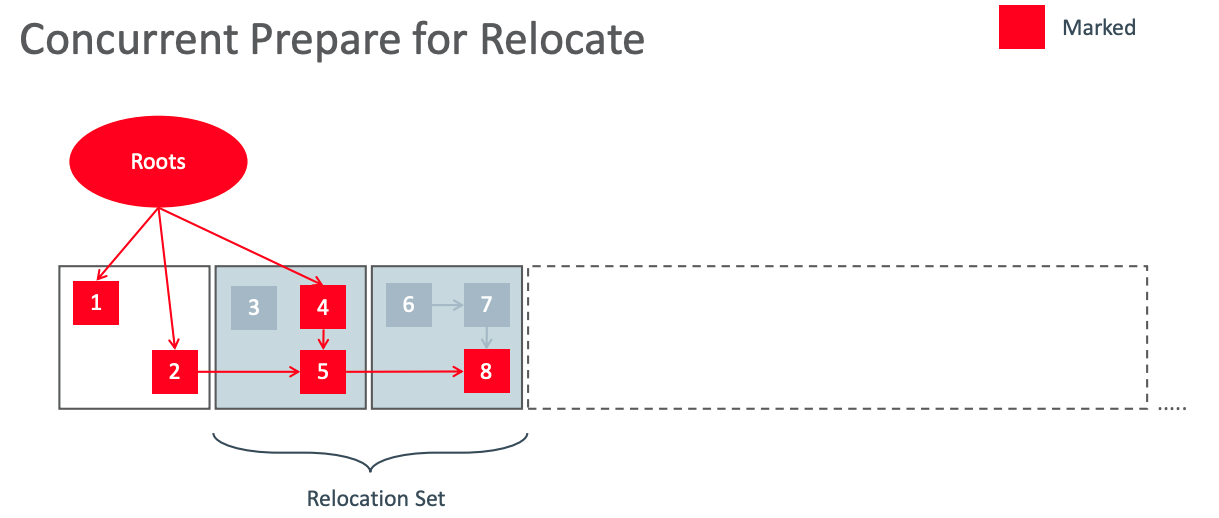
Concurrent Prepare for Relocate.png
经过之前的标记工作,已经掌握了整个堆中的存活对象。那么在并发迁移准备过程中,会计算迁移集合。
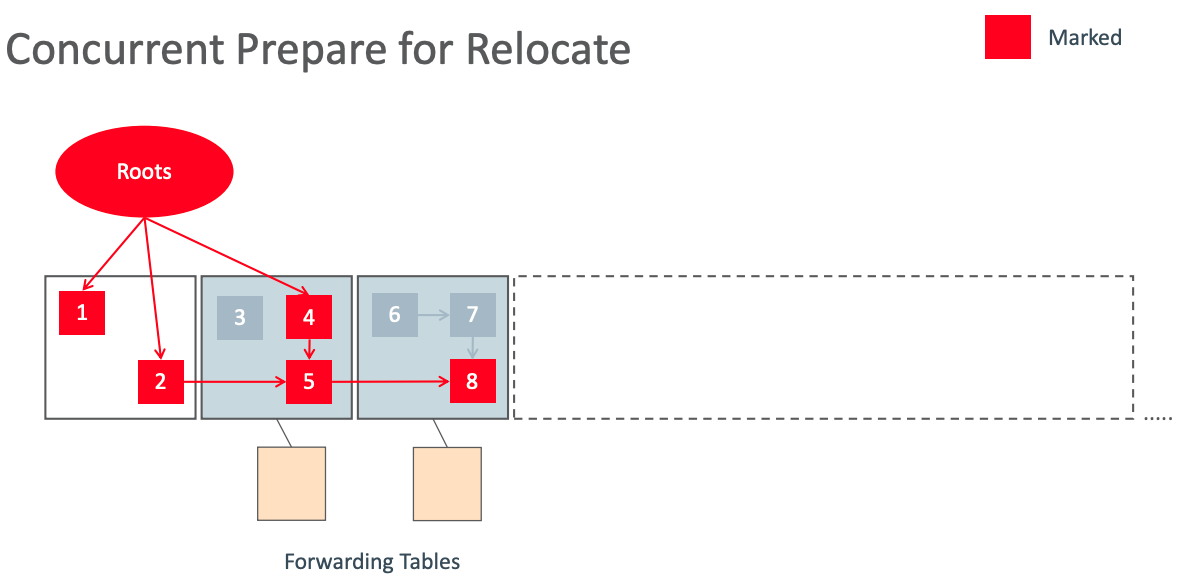
Concurrent Prepare for Relocate 2.png
同时会初始化一个空的 forwarding tables,用于保存迁移前后的映射关系。
初始迁移/Pause Relacate Start
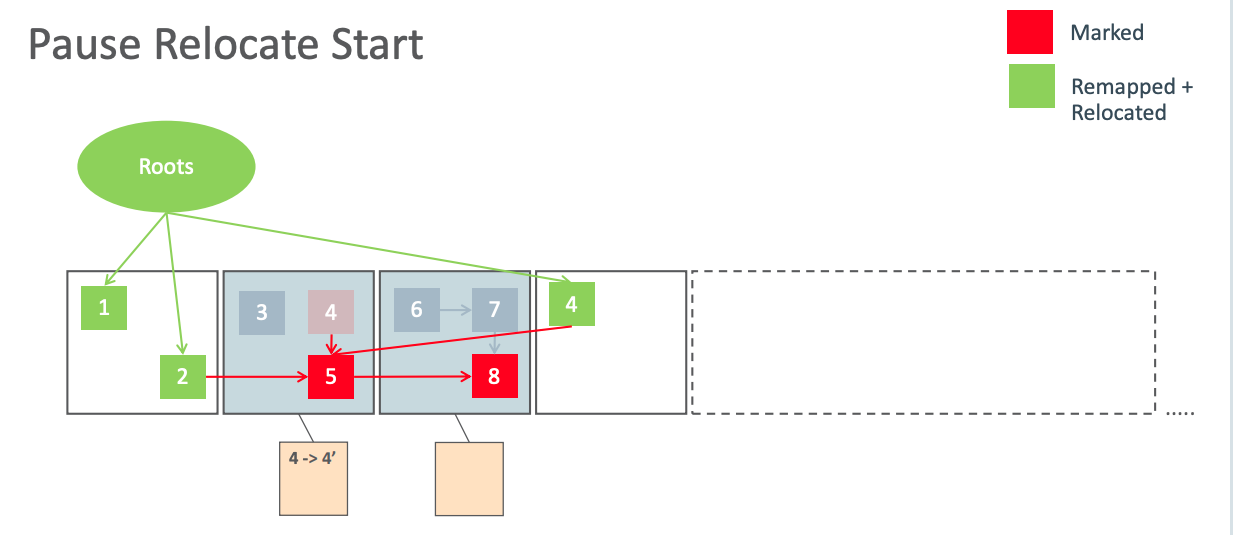
初始迁移阶段只是扫描与根节点直接关联的对象,并进行迁移,被迁移对象会被变更为 Remapped 指针,并把映射映射关系保存到 forwarding tables。该阶段只扫描少量对象,速度非常快。
并发迁移/Concurrent Relocate
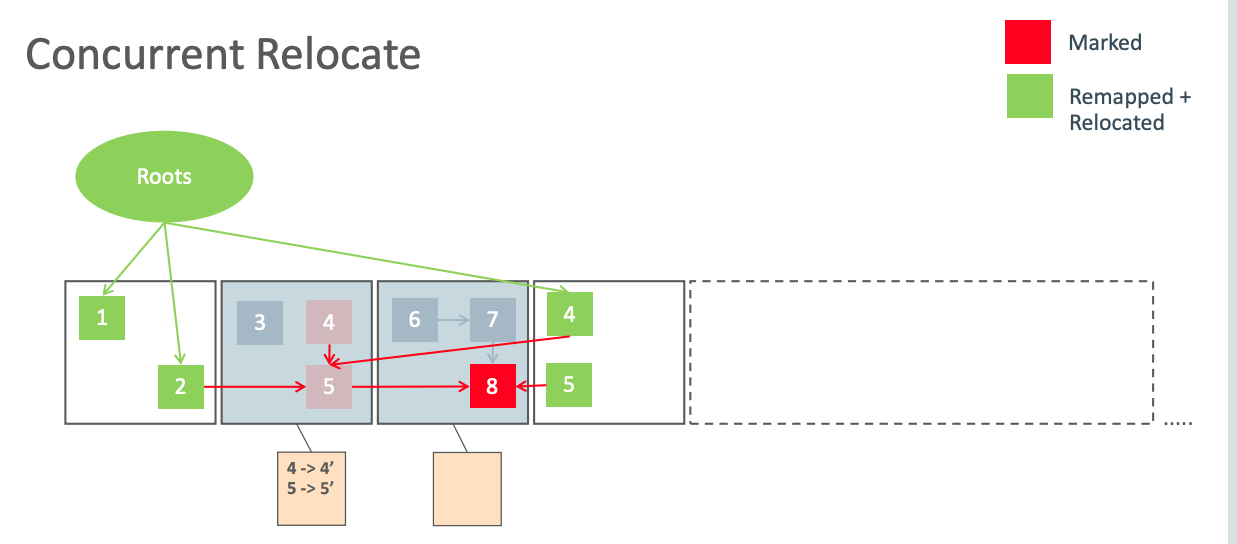
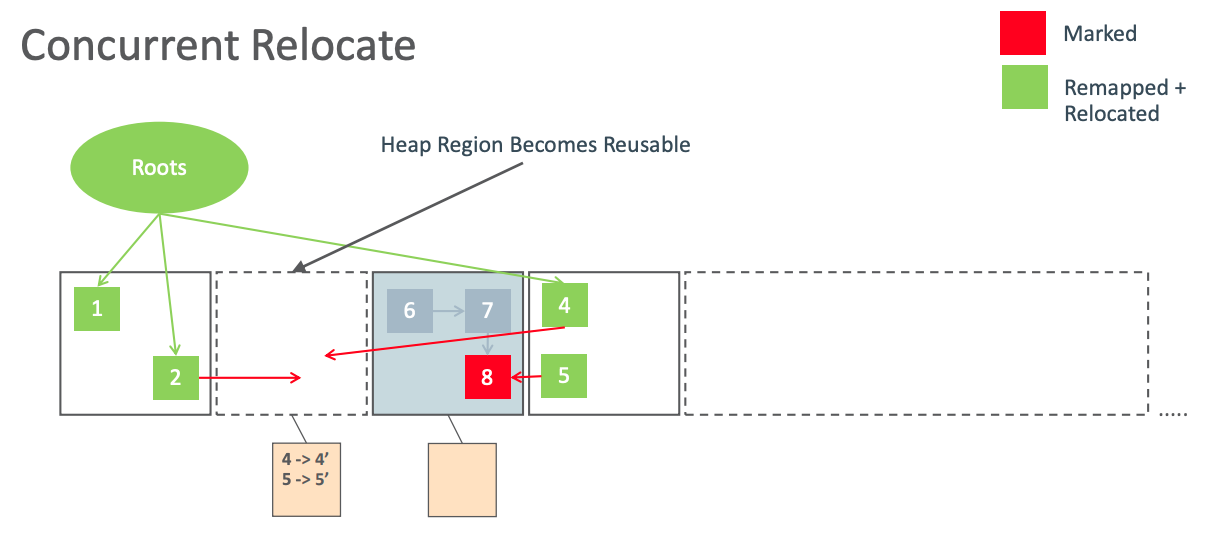
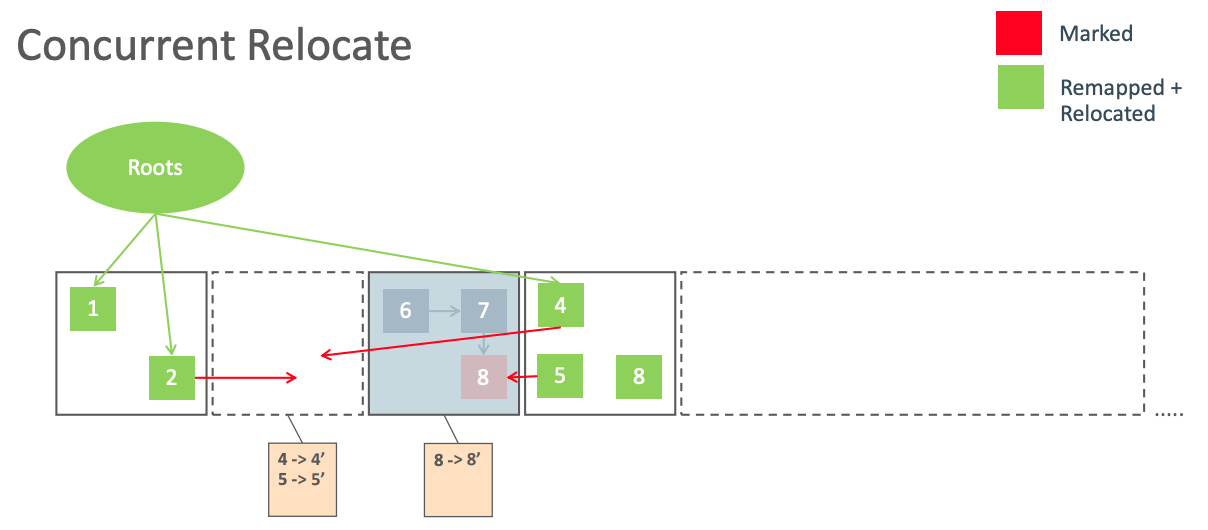
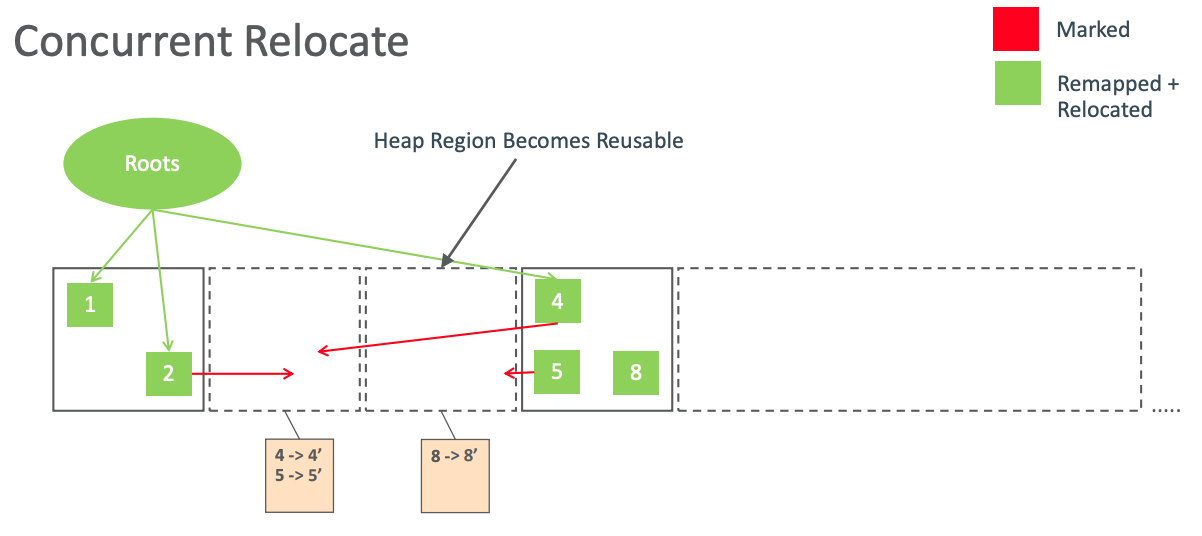
并发转移阶段会遍历所有的迁移集合,进行存活对象迁移,并回收空区块。被迁移的对象指针都会被变更为 Remapped 指针,并把映射映射关系保存到 forwarding tables。
假如当前 GC 周期使用 M0 地址空间,那么对象4、5、6都发生了迁移,此时其指针处于 Remapped 地址空间。而对象2、4、5所引用的指针都是处于 M2 指针。这些指针都已经失效,也就是坏指针,后续对象重定向阶段会修复它们。
对象重定位
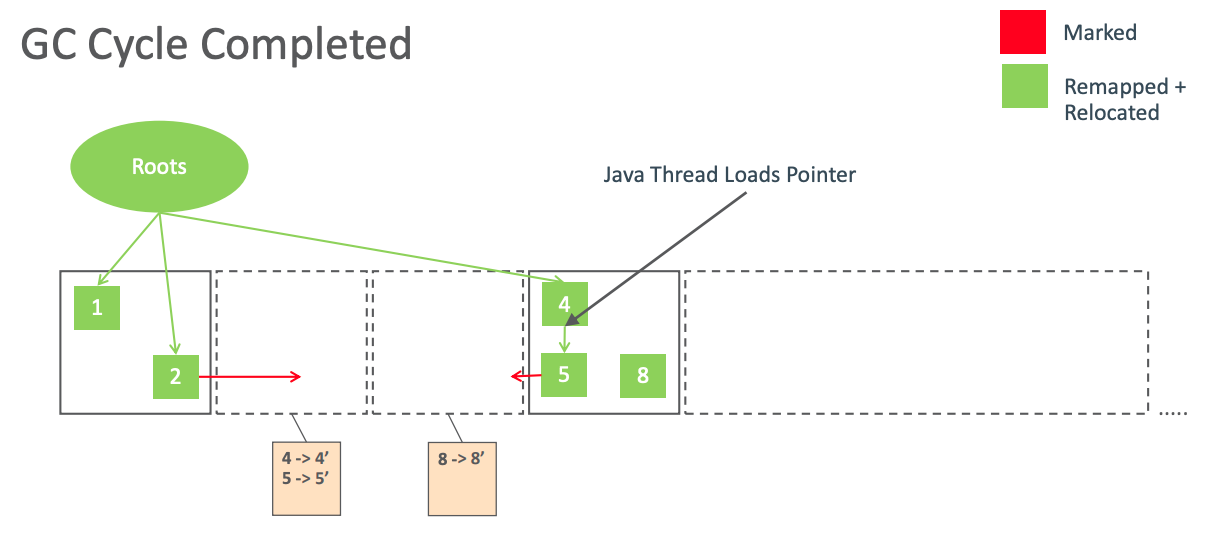
上一个 GC 周期结束后,JVM 内部还有很多坏指针,如果应用线程线程加载了这些指针,则会在读屏障阶段修复这些指针。剩下的未修复指针将延迟到第二个 GC 周期来进行修复。
假如上一个 GC 周期使用的是 M0 地址空间,那么新的 GC 周期就会使用 M1 地址空间进行活跃对象标记。
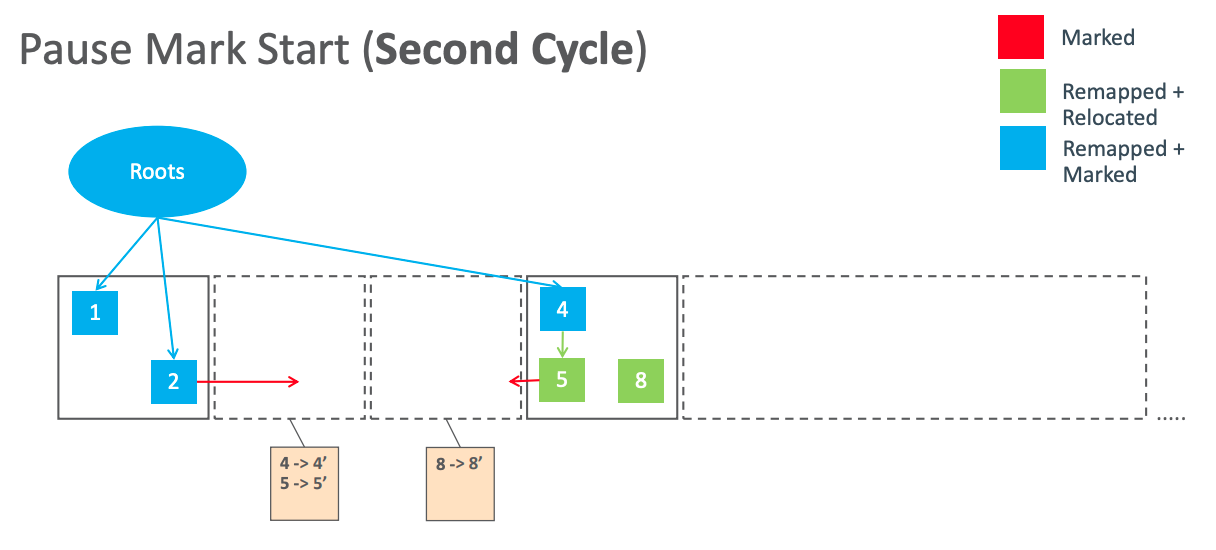
Pause Mark Start(Second Cycle).png
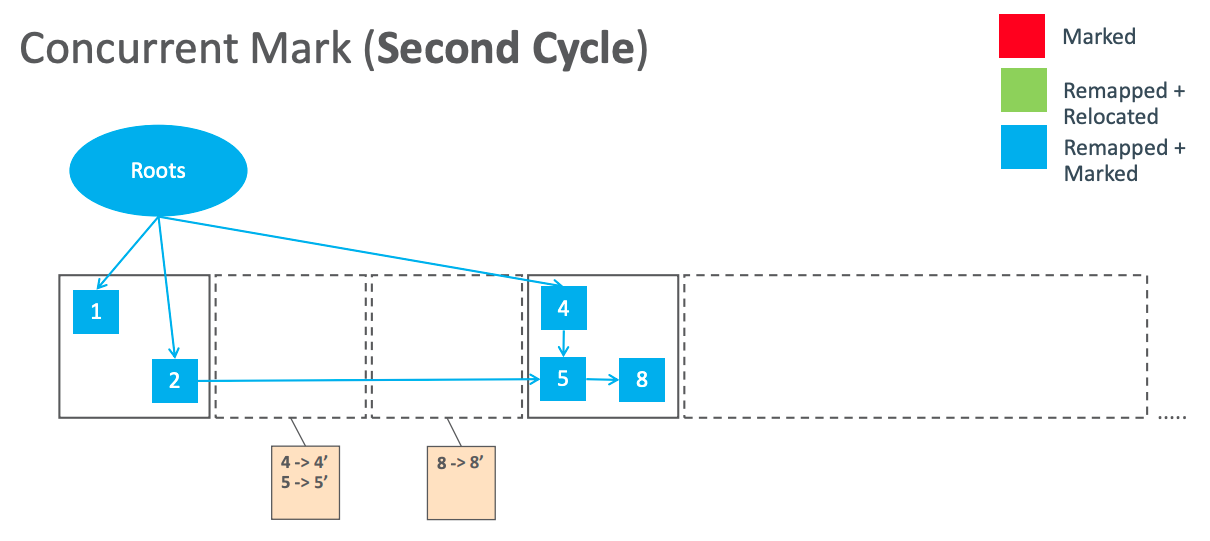
Concurrent Mark(Second Cycle).png
下一个周期的初始标记和并发标记会顺带把上一个周期的坏指针修复。
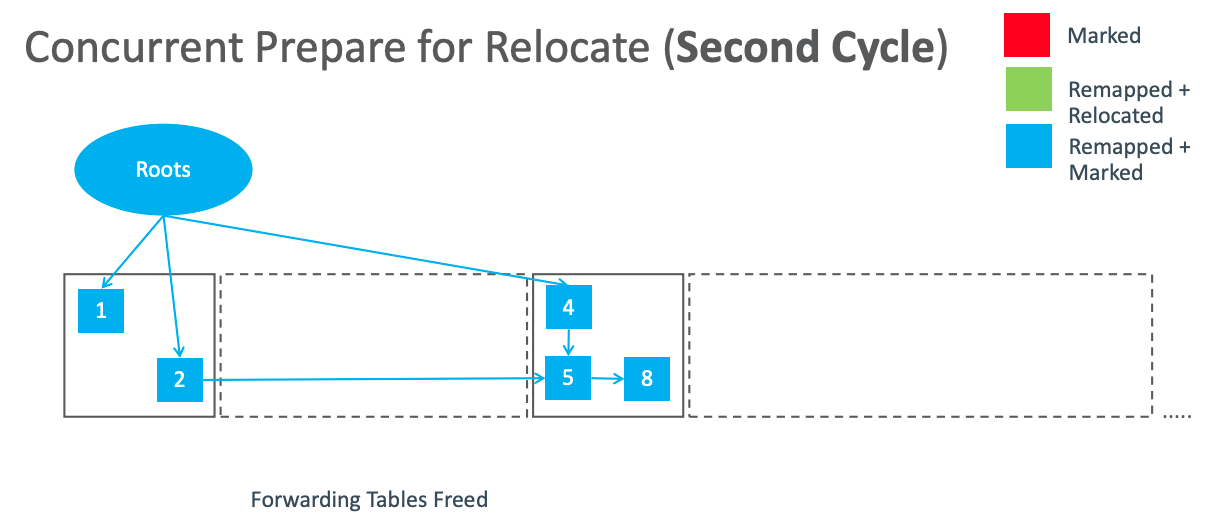
Concurrent Prepare for Relocate(Second Cycle).png
然后清空上一个阶段的 forwarding table。
ZGC 触发条件
CMS 调优中一般会调整 CMSInitiatingOccupancyFraction 参数,然后在老年代占用达到一定比例的时候,触发一次 GC;
G1 中也有类似的参数 InitiatingHeapOccupancyPercent,在老年代占用达到堆空间的一定比例的时候,触发一次混合 GC;此外,G1 还会评估当前收集时间是否超过阈值 MaxGCPauseMillis ,如果超过阈值也会触发一次 GC;
无论是 CMS 或者是 G1 的触发方式都存在一些不足。因此,ZGC 使用了更复杂的一套机制:
元空间分配触发:元空间分配不足的时候触发。使用 G1 的时候一般建议配置,因为默认会占满所有剩余内存。但在 ZGC 中不存在这个问题,所以一般不用关心元空间分配。
[2021-04-07T03:17:58.763-0400][14855][gc ] GC(0) Garbage Collection (Metadata GC Threshold) 196M(0%)->196M(0%) [2021-04-07T03:18:00.052-0400][14855][gc ] GC(1) Garbage Collection (Metadata GC Threshold) 444M(0%)->202M(0%) [2021-04-07T03:18:04.429-0400][14855][gc ] GC(2) Garbage Collection (Metadata GC Threshold) 1038M(1%)->206M(0%)固定时间间隔触发:通过 -XX:ZCollectionInterval=<seconds> 来控制。如果服务压力不大的话,这是最主要的 GC 方式。这种方式是为了在流量平稳的情况下定时触发 GC,避免流量突增的时候才触发 GC,从而导致线程阻塞。如果 G1 用得比较多话,就会发现 G1 就存在这个比较严重的问题。
[2021-04-07T10:00:24.610-0400][14855][gc ] GC(203) Garbage Collection (Timer) 48674M(32%)->336M(0%) [2021-04-07T10:02:24.709-0400][14855][gc ] GC(204) Garbage Collection (Timer) 54888M(36%)->360M(0%) [2021-04-07T10:04:24.804-0400][14855][gc ] GC(205) Garbage Collection (Timer) 50482M(33%)->362M(0%) [2021-04-07T10:06:24.904-0400][14855][gc ] GC(206) Garbage Collection (Timer) 46962M(31%)->370M(0%) [2021-04-07T10:08:25.006-0400][14855][gc ] GC(207) Garbage Collection (Timer) 49444M(32%)->340M(0%)基于分配速率的自适应算法触发:ZGC 根据对象分配速率和 GC 时间来计算内存占用达到什么阈值的时候才触发 GC。通过ZAllocationSpikeTolerance参数控制阈值大小,该参数默认2,数值越大,越早的触发GC。
[2021-04-07T09:30:41.600-0400][22575][gc ] GC(166) Garbage Collection (Allocation Rate) 7854M(96%)->340M(4%) [2021-04-07T09:31:16.474-0400][22575][gc ] GC(167) Garbage Collection (Allocation Rate) 7798M(95%)->330M(4%) [2021-04-07T09:31:54.769-0400][22575][gc ] GC(168) Garbage Collection (Allocation Rate) 7812M(95%)->312M(4%) [2021-04-07T09:32:34.672-0400][22575][gc ] GC(169) Garbage Collection (Allocation Rate) 7894M(96%)->330M(4%) [2021-04-07T09:33:09.872-0400][22575][gc ] GC(170) Garbage Collection (Allocation Rate) 7886M(96%)->314M(4%)阻塞内存触发分配:当垃圾来不及回收并堆满整个堆的情况下,会触发这种 GC。调优良好情况下,应该尽量避免这种 GC:
[2021-04-07T10:08:14.458-0400][23755][gc ] Allocation Stall (nioEventLoopGroup-12-1) 0.749ms [2021-04-07T10:08:14.458-0400][23783][gc ] Allocation Stall (nioEventLoopGroup-16-1) 1.019ms [2021-04-07T11:13:08.556-0400][23764][gc ] Allocation Stall (nioEventLoopGroup-13-1) 0.115ms主动触发规则:类似于固定间隔规则,但时间间隔不固定,是ZGC自行算出来的时机,我们的服务因为已经加了基于固定时间间隔的触发机制,所以通过-ZProactive参数将该功能关闭,以免GC频繁,影响服务可用性。 日志中关键字是”Proactive”
预热规则:服务刚启动时出现,一般不需要关注。日志中关键字是”Warmup”
外部触发:代码中显式调用System.gc()触发。 日志中关键字是”System.gc()”
后边三种较少见,没在生产服务里找到案例,所以直接复制了美团的技术文章里的片段。
ZGC 与 G1 案例对比
简单做了下测试对比下 ZGC 和 G1,无论是大堆或者小堆,ZGC 在收集停顿上都控制得非常好,基本不会超过10ms,这点远胜于 G1;但是可能 ZGC 的触发策略保守了,总的停顿时间要比 G1 多。
但总体来说,ZGC 是一款低延迟高吞吐量的收集器,是 G1 的良好替代!
大堆(150G)
-Xmx150g -Xms150g -XX:ReservedCodeCacheSize=256m -XX:InitialCodeCacheSize=256m
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC -XX:ConcGCThreads=80 -XX:ParallelGCThreads=80
-XX:ZCollectionInterval=120 -XX:ZAllocationSpikeTolerance=5 -XX:+UnlockDiagnosticVMOptions
-XX:-ZProactive -Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=gc.log:time,tid,tags:filecount=5,filesize=500m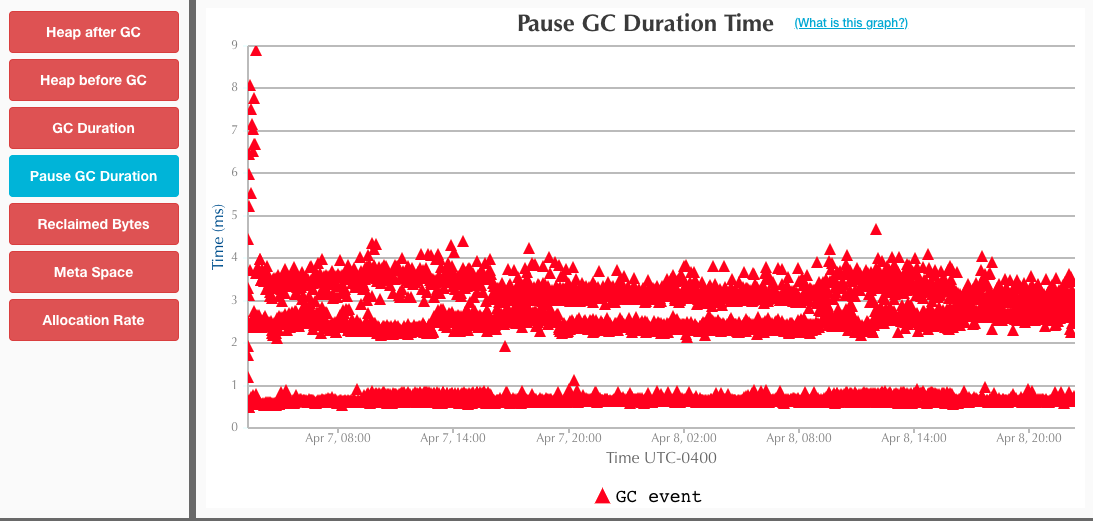
-Xmx150g -Xms150g -XX:+UseG1GC -XX:MaxGCPauseMillis=500 -XX:MetaspaceSize=150m -XX:MaxMetaspaceSize=150M -XX:+UnlockExperimentalVMOptions -Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=gc.log:time,tid,tags:filecount=5,filesize=500m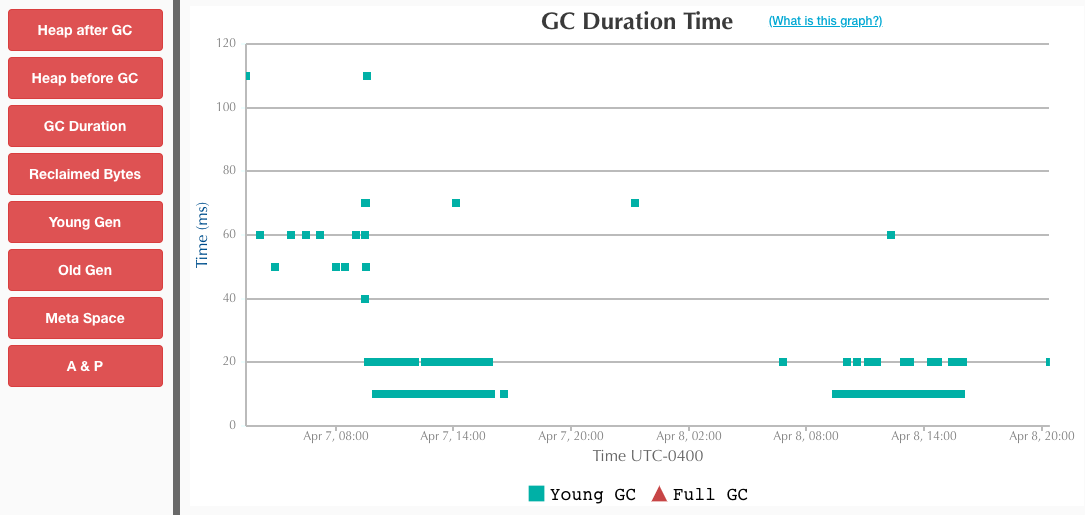
小堆(8G)
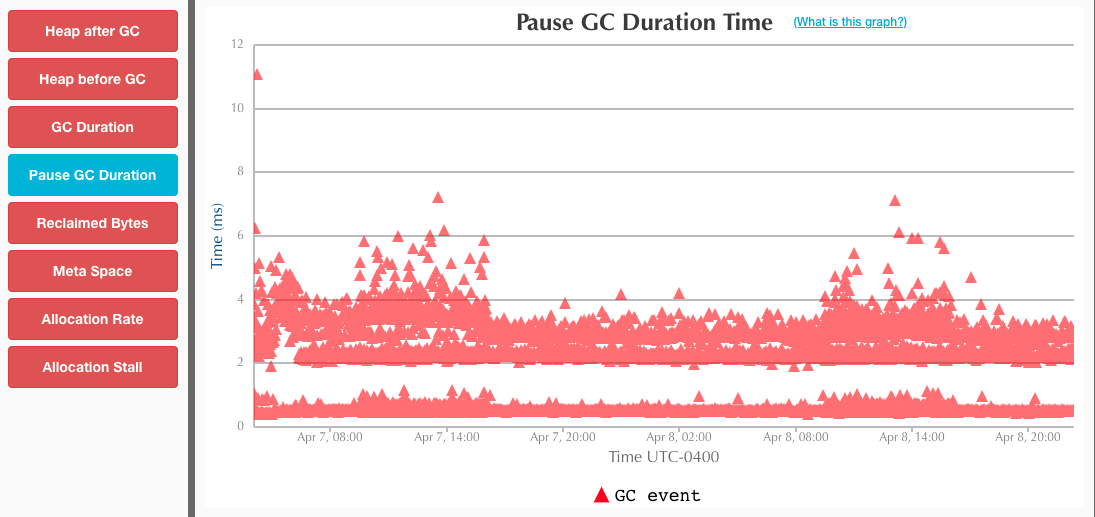
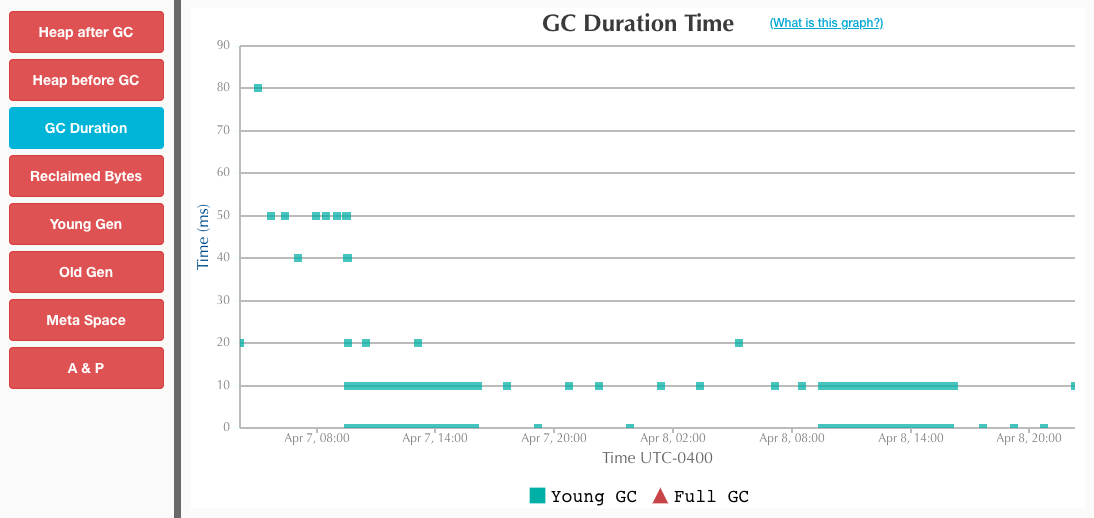
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK