

VMware vSphere Bitfusion Offers the Best ROI for Machine Learning Dev-Test Workl...
source link: https://blogs.vmware.com/performance/2020/09/bitfusion-best-roi-ml-dev-test-workloads.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

By Hari Sivaraman, Uday Kurkure, and Lan Vu
VMware offers multiple software solutions to run machine learning (ML) on vSphere using an NVIDIA graphics processing unit (GPU). Each of these solutions has its strengths and weaknesses, and you should choose the solution that best matches the type of workload you’ll run. This ensures you obtain the best return on investment (ROI) for your hardware.
One of the solutions available on vSphere is Bitfusion, and in this blog we present data to demonstrate this solution offers the best ROI for dev-test types of workloads.
Types of ML Workloads
We considered three different ML workloads, which have the following characteristics:
- ML-Training: Training model for production deployment and hyper-parameter tuning
- Long runtimes (measured in hours)
- Needs more than 1 GPU, usually
- ML-Inference: Inferencing as a service
- Runtime in milliseconds, throughput oriented.
- Dev-Test: Analyzing data, cleaning data, data engineering, and building/tweaking models
- Episodic code execution with idle time between code execution; the idle time is referred to as think-time in benchmarking
- Variable runtime (from seconds to minutes)
- Need high consolidation ratio (large number of VMs per vSphere host) for good device utilization and high ROI
The Dev-Test ML Workload
The use case we tested represents a dev-test environment. In this environment, we have one or more data scientists or ML-model developers (users), who from time to time run code kernels that must execute using a GPU. The code kernels might be issued from an IDE like Jupyter or from a command-line. The users need the GPU for at least two reasons:
- To speed up the data analysis/data engineering kernel
- To verify the kernel will run correctly while using a GPU
In the second scenario, while testing the correctness of the kernel, execution speed isn’t important; verifying correctness is what’s important. In the dev-test environment, developers and data scientists rarely work with the full dataset that will be used to train an ML-model for deployment in a production environment; instead, they use a subset of the full dataset to tweak the model, clean the data, engineer features, and so on.
To capture the features of the dev-test use case, we created a workload with the following four items:
- A convolutional neural network (CNN) – 2 convolutional layers with RELU and max pooling followed by three fully connected layers
- A fully connected neural network – four fully connected layers with cross-entropy loss and an Adam optimizer
- Matrix multiplication
- Vector-matrix multiplication
All four items had code fragments/sequences that ran on the CPU, and CUDA kernels that executed on the GPU. In the CNN, the CUDA kernel had a loop inside in which data was transferred to the GPU memory from the host. In all other items, the required data was transferred to the GPU memory before it had accessed the CUDA kernel. The matrix multiplication and vector-matrix multiplication used matrices of size 5000×5000 and vectors of size 5000×1. These items require 2GB of GPU memory to run. While we do not expect the conclusions presented in this blog to change with the amount of memory used by the test, we plan, in a future blog, to report on the results obtained with tests that use a smaller or larger amount of GPU memory.
Dev-Test ML Benchmark
We used this workload to create a dev-test benchmark with the following characteristics:
- The benchmark consisted of running tests, one after the other, for three hours.
- Each test consisted of think-time followed by one of the four items in the workload, selected at random using a uniform distribution.
- Think-times were drawn from a beta (beta (2,8)) distribution.
- The benchmark was run with 1, 2, 4, 8, 12, 16, 20, 24, 32, 40, 44, 48 clients. Each client represents a data scientist or an ML engineer.
- Each client was a Docker container within the benchmark. Each container ran in its own Ubuntu 18.04 VM.
In this benchmark, the computational load on the GPU was defined by two parameters:
- Think-time
- Number of clients
Varying the value of these two parameters allowed us to apply different levels of load on the system. As we reduced the think-time, the number of operations per minute increased (in this case, an operation is the number of items from the list of four items that made up the benchmark). As we increased the number of clients, the number of operations issued per minute increased. Each client had only one operation outstanding at any one time.
The pseudocode for the benchmark and the metrics we report is shown in figure 1.
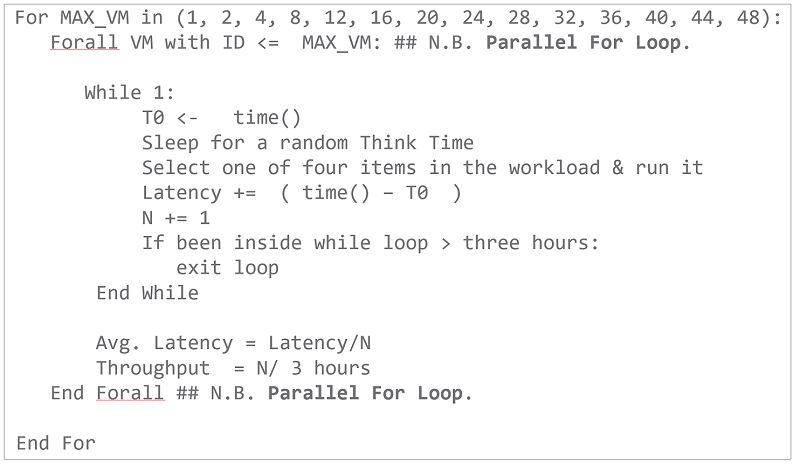
We ran this benchmark on a DELL R740xd with two sockets and Intel Xeon Gold 6140 processors with 18 cores per socket, 768GB RAM, 5.2TB SSD storage, and one 16GB V100 NVIDIA GPU. The server ran ESXi 6.7.0. We ran the benchmark with 1, 2, 4, 8, 12, 16, 20, 24, 32, 40, 44, 48 clients using three different configurations:
- CPU only: The benchmark ran without any GPU
- vGPU: We ran the benchmark using NVIDIA vGPU (driver version 440.43) on V100
- Bitfusion: We set up the Bitfusion server using DirectPath I/O (NVIDIA driver 440.33) on the server and connected to it using client VMs on the same server.
Latency vs. Throughput
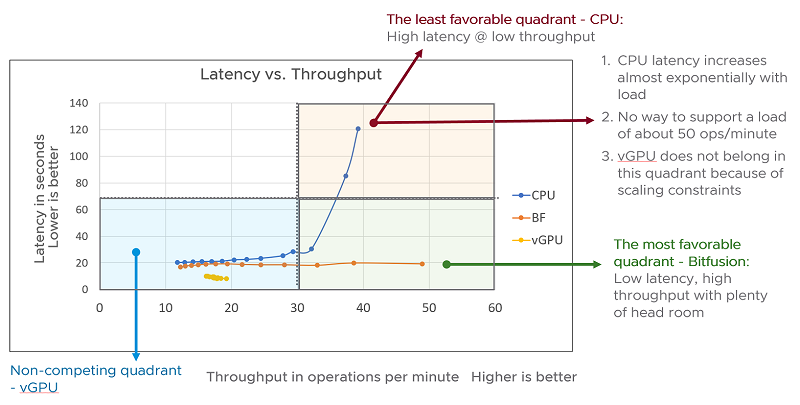
CPU Solution
Figure 2 shows the latency vs. throughput as we increased the computational load. From the figure, we can see that at low levels of computational load, the latency experienced using only the CPU compared to using Bitfusion is fairly close but, as we increase the load, the runs using only the CPU show gradually increasing latency and, after about 35 operations per minute, the latency starts to climb sharply. The CPU-only mode is incapable of supporting a computational load exceeding about 40 operations per minute. This severely limits the extent of consolidation or sharing of resources possible using a CPU-only solution.
vGPU Solution
However, when we look at the latencies obtained in runs that use the vGPU, we see that the measured latencies are always noticeably lower than those with Bitfusion. However, since each client requires 2GB of GPU DRAM to run, and the GPU we used in our tests has 16 GB of RAM, the vGPU solution can only support a maximum of eight (i.e. 16GB/2 = 8) clients. Had we used a GPU with 32GB memory we could have supported up to 16 (32GB/2 = 16) clients using the vGPU solution. Alternately, if we had used tests that use less than 1 GB GPU memory, we could have supported up to 16 clients on this 16GB GPU. The vGPU solution uses static sharing of memory resources, so there’s a hard limit on the number of concurrent clients it can support. This hard limit is defined by the amount of memory on the GPU and the memory required by a single client.
Bitfusion Solution
The Bitfusion solution shows slightly higher latencies than the vGPU solution, but as we increased the load, the latency remained relatively constant. The Bitfusion solution achieves low latencies at high throughput. This allows us to support multiple clients (up to 48 in this test) on a single NVIDIA V100 GPU, at low latencies.
This is not possible using any other solution:
- The CPU-only solution starts to climb the vertical wall of the hockey-stick curve, making it undesirable at high consolidation ratios.
- The vGPU solution, which shares memory statically, is limited to supporting at most eight clients.
Only the Bitfusion solution allows us to share the GPU among 48 clients with low latency for this workload. So, for workloads that resemble the dev-test type usage scenario, a Bitfusion solution offers the highest consolidation at low latencies. It provides the best ROI for this type of workload.
Greatest Number of Users That Each Solution Can Run
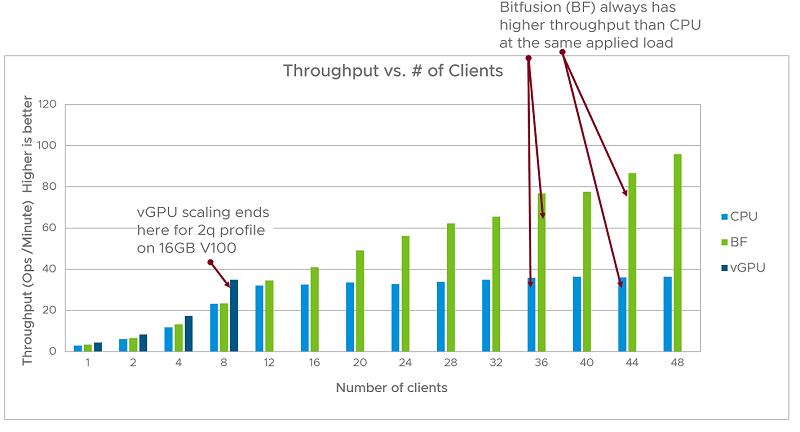
The superior scaling achieved by Bitfusion compared to that obtained using a CPU-only solution is shown in figure 3. To measure this scaling, we ran the benchmark with 1,2, …, 48 clients running concurrently with a mean think-time of five seconds. As we increased the number of clients (which increased the number of operations issued per minute) the throughput achieved using a CPU-only solution reached a peak value close to 38 operations per minute and remained fixed at that value (this is consistent with the data shown in the latency vs. throughput graph in figure 2). In contrast, the Bitfusion solution showed steadily increasing throughput as the number of clients were increased. So, from the data in figure 3, we can see that by using the Bitfusion solution, it is possible to consolidate far more clients on a single server than would be possible using a CPU-only or vGPU solution for the dev-test type of workload. The vGPU solution stops scaling with 8 clients because we used a 16GB GPU in our tests, and each test requires 2GB memory, which means the GPU can support a maximum of 8 (16GB /2 =8) clients in this test.
Conclusion and Future Work
VMware vSphere supports multiple solutions to run ML. Every solution has its strengths and weaknesses. In this blog, we demonstrated that the Bitfusion solution shows superior scaling and low latency at high throughput for the dev-test type of ML workloads. The data presented in this blog shows that the Bitfusion configuration supports more than 16 data scientists engaged in dev-test on a single NVIDIA V100 GPU.
In a future blog, we plan to present data from tests run using an Intel CPU with VNNI capability. We also plan to run and report results using tests with different amounts of memory requirements other than 2GB.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK