

Scaling Netflix's API via GraphQL Federation (#2) | Netflix TechBlog
source link: https://netflixtechblog.com/how-netflix-scales-its-api-with-graphql-federation-part-2-bbe71aaec44a
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

How Netflix Scales its API with GraphQL Federation (Part 2)
In our previous post and QConPlus talk, we discussed GraphQL Federation as a solution for distributing our GraphQL schema and implementation. In this post, we shift our attention to what is needed to run a federated GraphQL platform successfully — from our journey implementing it to lessons learned.


Our Journey so Far
Over the past year, we’ve implemented the core infrastructure pieces necessary for a federated GraphQL architecture as described in our previous post:

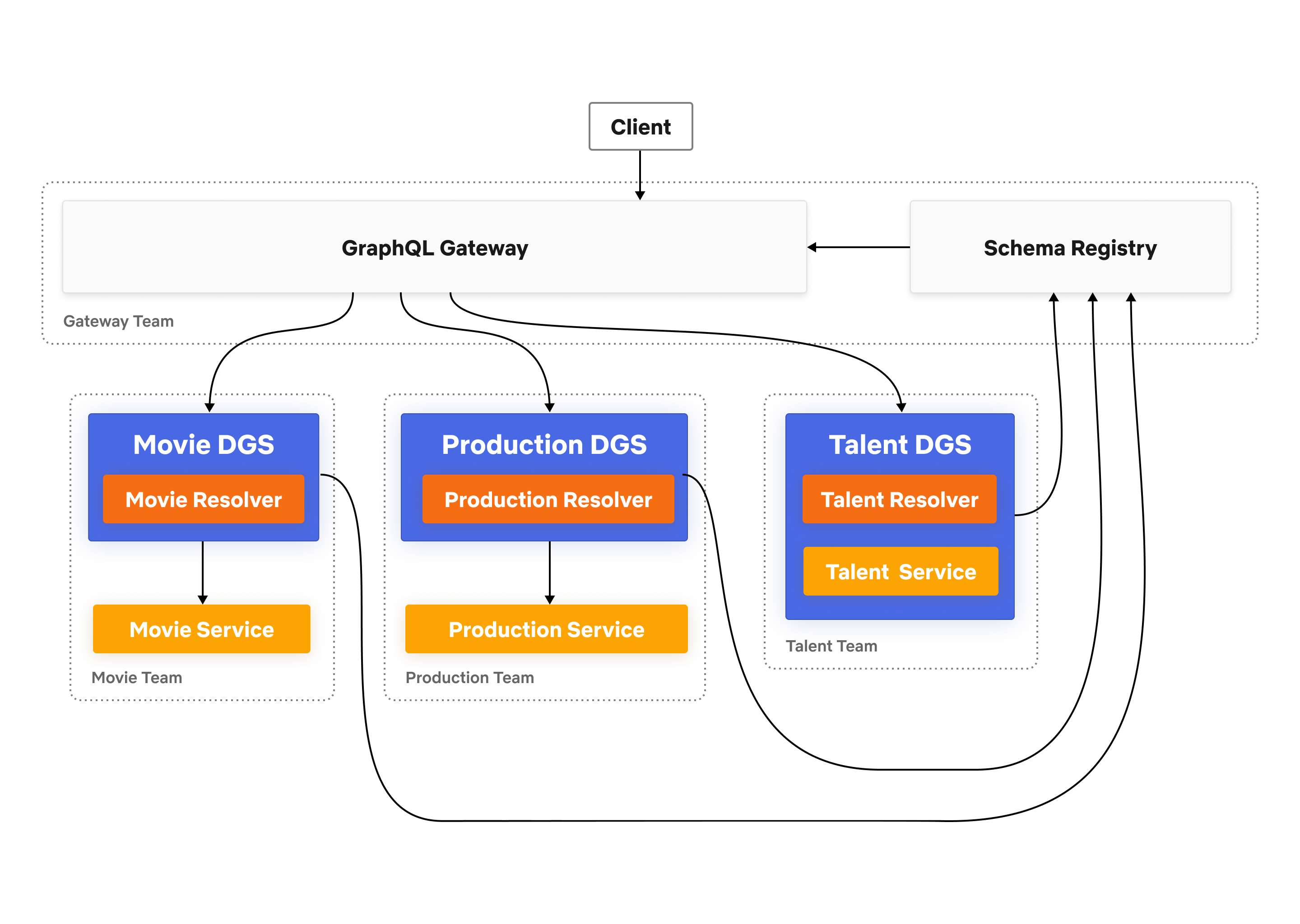
The first Domain Graph Service (DGS) on the platform was the former GraphQL monolith that we discussed in our first post (Studio API). Next, we worked with a few other application teams to make DGSs that would expose their APIs alongside the former monolith. We had our first Studio applications consuming the federated graph, without any performance degradation, by the end of the 2019. Once we knew that the architecture was feasible, we focused on readying it for broader usage. Our goal was to open up the Studio Edge platform for self-service in April 2020.
April 2020 was a turbulent time with the pandemic and overnight transition to working remotely. Nevertheless, teams started to jump into the graph in droves. Soon we had hundreds of engineers contributing directly to the API on a daily basis. And what about that Studio API monolith that used to be a bottleneck? We migrated the fields exposed by Studio API to individually owned DGSs without breaking the API for consumers. The original monolith is slated to be completely deprecated by the end of 2020.
This journey hasn’t been without its challenges. The biggest challenge was aligning on this strategy across the organization. Initially, there was a lot of skepticism and dissent; the concept was fairly new and would require high alignment across the organization to be successful. Our team spent a lot of time addressing dissenting points and making adjustments to the architecture based on feedback from developers. Through our prototype development and proactive partnership with some key critical voices, we were able to instill confidence and close crucial gaps.
Once we achieved broad alignment on the idea, we needed to ensure that adoption was seamless. This required building robust core infrastructure, ensuring a great developer experience, and solving for key cross-cutting concerns.
Core Infrastructure
Our GraphQL Gateway is based on Apollo’s reference implementation and is written in Kotlin. This gives us access to Netflix’s Java ecosystem, while also giving us the robust language features such as coroutines for efficient parallel fetches, and an expressive type system with null safety.
The schema registry is developed in-house, also in Kotlin. For storing schema changes, we use an internal library that implements the event sourcing pattern on top of the Cassandra database. Using event sourcing allows us to implement new developer experience features such as the Schema History view. The schema registry also integrates with our CI/CD systems like Spinnaker to automatically setup cloud networking for DGSs.
Developer Education & Experience
In the previous architecture, only the monolith Studio API team needed to learn GraphQL. In Studio Edge, every DGS team needs to build expertise in GraphQL. GraphQL has its own learning curve and can get especially tricky for complex cases like batching & lookahead. Also, as discussed in the previous post, understanding GraphQL Federation and implementing entity resolvers is not trivial either.
We partnered with Netflix’s Developer Experience (DevEx) team to build out documentation, training materials, and tutorials for developers. For general GraphQL questions, we lean on the open source community plus cultivate an internal GraphQL community to discuss hot topics like pagination, error handling, nullability, and naming conventions.
DGS Framework & Developer Tools
To make it easy for backend engineers to build a GraphQL DGS, the DevEx team built a “DGS Framework” on top of GraphQL Java and Spring Boot. The framework takes care of all the cross-cutting concerns of running a GraphQL service in production while also making it easier for developers to write GraphQL resolvers. In addition, DevEx built robust tooling for pushing schemas to the Schema Registry and a Self Service UI for browsing the various DGS’s schemas. Check out their conference talk and expect a future blog post from our colleagues. The DGS framework is planned to be open-sourced in early 2021.
Schema Governance
Netflix’s studio data is extremely rich and complex. Early on, we anticipated that active schema management would be crucial for schema evolution and overall health. We had a Studio Data Architect already in the org who was focused on data modeling and alignment across Studio. We engaged with them to determine graph schema best practices to best suit the needs of Studio Engineering.
Our goal was to design a GraphQL schema that was reflective of the domain itself, not the database model. UI developers should not have to build Backends For Frontends (BFF) to massage the data for their needs, rather, they should help shape the schema so that it satisfies their needs. Embracing a collaborative schema design approach was essential to achieving this goal.

The collaborative design process involves feedback and reviews across team boundaries. To streamline schema design and review, we formed a schema working group and a managed technical program for on-boarding to the federated architecture. While reviews add overhead to the product development process, we believe that prioritizing the quality of the graph model will reduce the amount of future changes and reworking needed. The level of review varies based on the entities affected; for the core federated types, more rigor is required (though tooling helps streamline that flow).
We have a deprecation workflow in place for evolving the schema. We’ve leveraged GraphQL’s deprecation feature and also track usage stats for every field in the schema. Once the stats show that a deprecated field is no longer used, we can make a backward incompatible change to remove the field from the schema.

We embraced a schema-first approach instead of generating our schema from existing models such as the Protobuf objects in our gRPC APIs. While Protobufs and gRPC are excellent solutions for building service APIs, we prefer decoupling our GraphQL schema from those layers to enable cleaner graph design and independent evolvability. In some scenarios, we implement generic mapping code from GraphQL resolvers to gRPC calls, but the extra boilerplate is worth the long-term flexibility of the GraphQL API.
Underlying our approach is a foundation of “context over control”, which is a key tenet of Netflix’s culture. Instead of trying to hold tight control of the entire graph, we give guidance and context to product teams so that they can apply their domain knowledge to make a flexible API for their domain. As this architecture matures, we will continue to monitor schema health and develop new tooling, processes, and best practices where needed.
Observability
In our previous architecture, observability was achieved through manual analysis and routing via the API team, which scaled poorly. For our federated architecture, we prioritized solving observability needs in a more scalable manner. We prioritized three areas:
- Alerting — report when something goes awry
- Discovery — easily determine what isn’t working
- Diagnosis — debug why something isn’t working
Our guiding metrics in this space are mean time to resolution (MTTR) and service level objectives and indicators (SLO/SLI).
We teamed up with experts from Netflix’s Telemetry team. We integrated the Gateway and DGS architectural components with Zipkin, the internal distributed tracing tool Edgar, and application monitoring tool TellTale. In GraphQL, almost every response is a 200 with custom errors in the error block. We introspect these custom error codes from the response and emit them to our metrics server, Atlas. These integrations created a great foundation of rich visibility and insights for the consumers and developers of the GraphQL API.
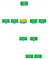
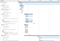
Distributed Log Correlation helps with debugging more complex server issues. By surfacing the application level logging details for all systems involved in processing a request, we gain deeper insights into what happened across the stack. Developers can easily see what was happening around the same time as a given request, to inspect surrounding factors that might have impacted an interaction.
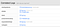
To solve the “who do I ask about…” routing problem, we integrated deep linking from GraphQL types and fields to their owning team’s support channels. Finding support is now as simple as clicking a link from a trace, which helps shorten MTTR and reduce the number of times the gateway team needs to get involved.
Securing the Federated Graph
Our goal is to enable robust and consistent security practices across the federated architecture. To achieve this, we partnered with the security experts at Netflix to build security into the graph. Let’s look at two essential parts of our security solution: AuthN and AuthZ.
Authentication
All of our product experiences in the Studio space require an authenticated account, so we restrict the GraphQL Gateway access to only trusted authenticated callers. Additionally, Graph Introspection is restricted to Netflix internal developers.
Authorization
Before Studio Edge, authorization logic was fragmented across teams. Some teams implemented authorization in their BFFs, some in microservices, and others did both for good measure. The result was often a different authorization story for a given piece of data depending on which UI a user was accessing it through. UI teams also found themselves needing to implement (and re-implement) authorization checks with each new frontend.
In Studio Edge, we delegated the authorization responsibility to DGS owners. This resulted in consistent authorization for the same user across different applications. Plus, Product Managers, Engineers and the Security team can easily get a bird’s eye view of who has access to each data type and how.
We have multiple authorization offerings within Netflix: from a simple system that grants access based on user identity to a more granular system that brings in the concept of roles and capabilities. DGS developers can choose a solution based on their needs. Then they simply annotate their resolvers with @Secured annotation and configure that to use one of the available systems. If needed, more complex authorization can be implemented in the resolver or in downstream systems.
Future of Authorization
We are currently prototyping a GraphQL-aware authorization solution. The Schema Registry automatically generates Access Control Groups (ACGs) for each field and its corresponding type when its schema is registered. Product managers & DGS Engineers decide membership and rules for these generated ACGs. Since the ACGs map to a field in GraphQL, the DGS framework then automatically applies the rules associated with the ACG during execution.
Architecting for Failure
The GraphQL Gateway is the single entry point for all requests; a failure on the gateway can cause significant disruptions. Following Netflix engineering best practices, we assume failures will happen and design ways to mitigate the impact of those failures. These are our design principles for ensuring the gateway layer is resilient:
- Single purpose
- Stateless service
- Demand controlled
- Multi-region
- Sharded by functionality
First, we focus the responsibilities of the gateway layer on a single purpose: parse client queries, then build and execute query plans. By reducing the scope, we limit the range of problems that can occur. We aim to perform any additional resource-intensive operations off-box with the exception of logging and metrics. Taking on additional unrelated logic in the gateway layer could increase surface area for failures in this critical tier.
Second, we run multiple stateless instances of the gateway service. Any gateway instance is able to generate and execute a query plan for any request. When we do code changes to the gateway layer, we rigorously test them before rolling out to production.
Third, we seek to balance the resources each request consumes through applying demand control. We rate-limit callers to avoid overloading the underlying databases that are the source of most of our domain elements. We also run a static query cost calculation on all incoming queries and reject expensive queries to avoid gridlock in gateway and DGS resources. Our partners understand these tradeoffs and work with us to meet these requirements, reworking expensive queries and reducing high volume callers.
Fourth, we deploy our gateway layer to multiple AWS regions around the world. This allows us to limit the blast radius for problems that inevitably arise. When problems happen, we can fail over to another region to ensure our clients are minimally impacted.
Last, we deploy multiple functional shards of our gateway layer. The code is the same in each shard and incoming requests are routed based on category. For example, GraphQL subscriptions generally result in long-lived connections while Queries & Mutations are short-lived. We use a separate fleet of instances for Subscriptions so “running out of connections” does not affect the availability of Queries and Mutations.
There is more we can do to improve resilience. We have plans to do canary deployments and analysis for gateway deployments and, eventually, schema changes. Today, our gateway dynamically updates its schema by polling the schema registry. We are in the process of decoupling these by storing the federation config in a versioned S3 bucket, making the gateway resilient to schema registry failures.
Closing Thoughts
GraphQL and Federation have been a productivity multiplier for Studio applications. Motivated by this, we’ve recently prototyped using GraphQL Federation for the Netflix consumer app search page on iOS & Android. To do this, we created three DGSs to provide the data for a minimal portion of the consumer graph. We are sending a small subset of users to this alternative stack and measuring high-level metrics. We are excited to see the results and explore further applicability in the Netflix consumer space.
Despite our positive experience, GraphQL Federation is early in its maturity lifecycle and may not be the best fit for every team or organization. Learning GraphQL and DGS development, running a federation layer, and doing a migration requires high commitment from partner teams and seamless cross-functional collaboration. If you’re considering going in this direction, we recommend checking out Apollo’s SaaS offering for Federation and the many online resources for learning GraphQL. For ecosystems like ours with a large swath of microservices that need to be aggregated together, the development velocity and improved operability has made the transition worth it.
In closing, we want to hear from you! If you have already implemented federation or tried to solve this problem with another approach, we would love to learn more. Sharing knowledge is one of the ways our industry learns and improves rapidly. Finally, if you’d like to be a part of solving complex and interesting problems like this at Netflix scale, check out our jobs page or reach out to us directly.
By Tejas Shikhare, Edited by Philip Fisher-Ogden
Additional Credits: Stephen Spalding, Jennifer Shin, Robert Reta, Antoine Boyer, Bruce Wang, David Simmer
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK