

A parser in Rust to convert your Medium Blogs to Markdown
source link: https://medium.com/@harshiljani2002/a-parser-in-rust-to-convert-your-medium-blogs-to-markdown-84173a6c1300
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
A parser in Rust to convert your Medium Blogs to Markdown

Recently, I have been writing some medium blogs for tutorials. Medium is pretty good to host your blogs quickly and present it to the larger audience. But, It’s still a centralized hosting solution. Someday, If medium goes down then the hardwork of blog writers is at risk.
Personally, I maintain a copy of all my medium blogs on my personal blog site built out of prose.sh and it uses markdown.
Converting a medium blog into markdown ends up taking lots of my time and thus one day I went on to search for any converter that can help me do just that. I found one written in javascript but was merely a simple HTML to Markdown converted and was not scrapping only the main content but had also scraped medium footer and title. And it lacks images too.
So, It was the time I thought to build one parser in Rust. It’s an interesting program to write since it helps you understand the Tree Data Structure very cleverly in some real world application. The reason we will explore Tree is because we fetch the HTML from the medium link and we tinker around with DOM (Document Object Model) which is kind of our AST (Abstract Syntax Tree) for the parser.
I will also be wrapping the parser around CLI so that people can just convert this using simple commands without worrying about the parser logic. This would be beneficial for users who quickly want the markdown and are reading this post to do just that.
Before I get into coding of the parser, Let me explain the people who just want to use the parser and not code it up.
Usage
The command-line interface (CLI) accepts a Medium blog post URL and a filename as input and generates the Markdown content.
medium-to-markdown <URL> <file_name>
Replace <URL> with the URL of the Medium blog post you want to convert, and <file_name> with the desired filename for the Markdown output.
medium-to-markdown
https://medium.com/@harshiljani2002/building-stock-market-engine-from-scratch-in-rust-i-9be7c110e137
blog_post.md
Github Link : https://github.com/Harshil-Jani/medium-to-markdown
Crate Link : https://crates.io/crates/medium-to-markdown
Setting up Project
$ cargo new medium-to-markdown
$ cd medium-to-markdown
$ cd src
$ touch dom.rs
$ touch parser.rs
Now we will use basic crates for this project and they are : tokio : async runtime I/O networking operations.reqwest : for fetching the HTML of the medium blog.html_parser : Convert HTML into DOM and identify tags.
$ cargo add tokio reqwest html_parser
Important Note : Use “rt-multi-thread”, “macros” features for the tokio and to do that update your Cargo.toml for the tokio to look like below. I am pasting my full cargo file to also let you know the versions I am using for the mentioned packages. Time is inevitable and things may tend to break if you look this blog after years. Even medium may change the way it embeds in HTML and this may need continuous maintainance for the project.
I am writing this blog just to make my kids kid aware that grandpa made the parser work by this logic. Scrapping may change but core logic that grandpa leaves behind will work just fine hopefully.
[package]
name = "medium-to-markdown"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
reqwest = "0.12.3"
tokio = { version = "1.37.0", features = ["rt-multi-thread", "macros"] }
html_parser = "0.7.0"
Fetching the DOM and Understand AST
Go to dom.rs file and now let’s get things rolling. We will write a method which will take the URL of the blog as input and return the DOM Object of the HTML Document as Output.
use html_parser::Dom;
use reqwest::get;
#[tokio::main]
pub async fn dom(url: &str) -> Result<Dom, Box<dyn std::error::Error>> {
let html = get(url).await?.text().await?;
let dom = Dom::parse(&html)?;
Ok(dom)
}
The reason , I was mentioning earlier that you’d get a good chance to learn the Tree Data Structure is because the DOM for the HTML is itself a Tree.
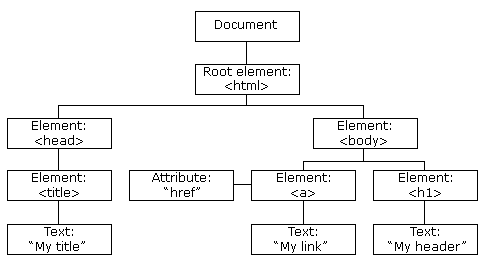
Think of traversing the DOM Tree to get the document in correct order. You got four traversal options. Pre-Order, Post-Order, In-Order or Level-Order Traversal. I leave that as an exercise to spend some time and how would you get the elements in correct order if you were to convert the above sample HTML DOM into Markdown.
To reveal the answer : Pre-Order traversal is the one in which you will get the perfect order of contents to be parsed in any other format.
For writing any parser, we need an AST. Just in case you don’t know, AST is Abstract Syntax Tree which is a tree-like data structure which summarizes the code’s structure. Here for our medium-to-markdown parser HTML DOM is going to be the AST.
DOM is set of nodes here. Node is of three types Element, Textand Comment. For the scope of this project we are not interested in Comments at all. Elements will have the HTML tags. Text contains the required content to be formatted from HTML to Markdown. We will extract text while iterating each element node.
Writing the Parser
Open the parser.rs file. Before we start writing the parser, It’s important to list down the features which we are going to work behind in the parser. As per the current state of medium it supports the following features :
- Headings (H1)
- SubHeadings (H2)
- Paragraphs (p)
- Inline Tags
this(code) - Code Blocks : Ctrl + Alt+6 The ones where you read code (pre)
- Images (source)
- Line Breaks (br)
- Bold (b,strong), Italics (i)
So this is an overview of what we will be parsing and getting it on the markdown style. Here it is important to understand that we would encounter two types of tags. Block and Inline. Basically, Inline are the ones used in the same line and appear in between the block tags.
Eg : <p> This is a very beautiful <b>Bold</b> Text</p>
Create a Template for the parser as showin below.
use html_parser::{Dom, Node};
pub fn parse_medium_post(dom: Dom) -> Result<String, Box<dyn std::error::Error>>{
let mut parsed_post = String::new();
for node in &dom.children {
// Iterate thorough nodes in Dom
if let Some(content) = parse_dom(node) {
parsed_post.push_str(&content);
}
}
Ok(parsed_post)
}
fn parse_dom(node: &Node) -> Option<String>{
match node.element() {
Some(element) => {
match element.name.as_str() {
"h1" => {
// Parse Heading
}
"h2" => {
// Parse Subheading
}
"p" => {
// Parse Paragraph
}
"pre" => {
// Parse Code Block
}
"source" => {
// Parse Image
}
_ => {}
}
}
None => {}
};
Some("".to_owned())
}
fn extract_inline(node: &Node) -> Option<String> {
match node {
Node::Text(text) => Some(text.to_owned()),
Node::Element(element) => {
match element.name.as_str() {
"b" | "strong" => {
// Parse Bold
Some("".to_owned())
}
"i" | "em" => {
// Parse Italic
Some("".to_owned())
}
"br" => {
// Parse Line Break
Some("".to_owned())
}
"code" => {
// Parse `tag` Code
Some("".to_owned())
}
_ => {
// Check for nested elements
// Eg : <p> <b>Hello <i>World</i></b> </p>
// In order to check for nested elements, We need to recursively call extract_inline
// and iterate over the childrens of the inline elements.
Some("".to_owned())
}
}
}
_ => None,
}
}Perfect. This is the parser architecture. We will iterate through each node and inline node elements and keep extracting the text from it. One-by-One we will define the functions using which we can print elements as they show up in markdown format.
Let’s start by the most basic <br> tag, The most simple thing is that for each <br> tag we need to show a new line character. Also here we are assured that there is not going to be any other inline characters since <br> tags are single tags.
"br" => {
// Parse Line Break
Some("\n".to_owned())
}Now, Think about the <b> bold text. In markdown the bold text is marked with **text**. One thing to think about is that the <b> tag may contain inner childrens.
Eg : <b>Bold and <i>Italics</i></b>
So we may recursively look after the following tags from the child nodes and then extract the text from it. Similarly we need to parse the text from italics (with *text* ) and the tags (with `tags`).
fn extract_inline(node: &Node) -> Option<String> {
match node {
Node::Text(text) => Some(text.to_owned()),
Node::Element(element) => {
match element.name.as_str() {
"b" | "strong" => {
// Parse Bold
let text = parse_formatting_text(element);
Some(format!("**{}** ", text.trim()))
}
"i" | "em"=> {
// Parse Italic
let text = parse_formatting_text(element);
Some(format!("*{}* ", text.trim()))
}
"br" => {
// Parse Line Break
Some("\n".to_owned())
}
"code" => {
// Parse `tag` Code
let text = parse_formatting_text(element);
Some(format!("`{}` ", text.trim()))
}
_ => {
// Check for nested elements
// Eg : <p> <b>Hello <i>World</i></b> </p>
// In order to check for nested elements, We need to recursively call extract_inline
// and iterate over the childrens of the inline elements.
// If the text is not formatted then return as a simple text.
let text = parse_formatting_text(element);
Some(text)
}
}
}
_ => None,
}
}
fn parse_formatting_text(element : &Element) -> String{
let mut result = String::new();
for child in &element.children {
if let Some(text) = extract_inline(child) {
result.push_str(&text);
}
}
result
}If we did not found any formatting then we just return the simple text in _ in match statement.
Now let us parse the main building blocks of the HTML page which are our block tags.
Headings : For the Heading (H1) and Subheading(H2) it’s Straight forward that we just need to use # H1 and ## H2 .
Paragraph : The paragraph of the contents which we write are written inside of pw-post-body-paragraph class. Hence for the paragraphs we need to look into this particular class name. If we find this then it will asure us that our content is wrapped inside of these p tags. Other p tags are part of header and footer text of medium.
Code Snippets : Parsing code snippets needs to be wrapped in ``` code ```` and for pretty formatting, medium convert each line into <br> tag. So basically our inline parsing takes care of code formatting and we just need to wrap it in triple backticks.
Images : Extracting images is a smart work. Medium uploads the images from our blog on their public servers. I found the links to images on the server and in markdown which supports the images with url is written with  So we format the link as shown.
Now the question is how do we get the link. The source tag contains the list of links of images in different dimension sizes on medium and for two formats webp and the original extension. Thus for a single image there are about 12–14 links.
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/0*Iu8XBXGnOCYLkxsD.jpeg 640w,
https://miro.medium.com/v2/resize:fit:720/format:webp/0*Iu8XBXGnOCYLkxsD.jpeg 720w,
https://miro.medium.com/v2/resize:fit:750/format:webp/0*Iu8XBXGnOCYLkxsD.jpeg 750w,
https://miro.medium.com/v2/resize:fit:786/format:webp/0*Iu8XBXGnOCYLkxsD.jpeg 786w,
https://miro.medium.com/v2/resize:fit:828/format:webp/0*Iu8XBXGnOCYLkxsD.jpeg 828w,
https://miro.medium.com/v2/resize:fit:1100/format:webp/0*Iu8XBXGnOCYLkxsD.jpeg 1100w,
https://miro.medium.com/v2/resize:fit:1400/format:webp/0*Iu8XBXGnOCYLkxsD.jpeg 1400w"
sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px"
type="image/webp"
/>
<source data-testid="og"
srcset="https://miro.medium.com/v2/resize:fit:640/0*Iu8XBXGnOCYLkxsD.jpeg 640w,
https://miro.medium.com/v2/resize:fit:720/0*Iu8XBXGnOCYLkxsD.jpeg 720w,
https://miro.medium.com/v2/resize:fit:750/0*Iu8XBXGnOCYLkxsD.jpeg 750w,
https://miro.medium.com/v2/resize:fit:786/0*Iu8XBXGnOCYLkxsD.jpeg 786w,
https://miro.medium.com/v2/resize:fit:828/0*Iu8XBXGnOCYLkxsD.jpeg 828w,
https://miro.medium.com/v2/resize:fit:1100/0*Iu8XBXGnOCYLkxsD.jpeg 1100w,
https://miro.medium.com/v2/resize:fit:1400/0*Iu8XBXGnOCYLkxsD.jpeg 1400w"
sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px" />
<img alt="" class="bg ls pt c" width="700" height="826" loading="eager"
role="presentation" />
</picture>
Here the links are in source tag and for each image we might find two source tags. When I was coding up the parser, I stumbled upon this because it was printing the image twice and then I realized how medium stores images with webp and actual extension with different sizes to make it look consistent across the screens.
I will fetch the webp format and only the smallest possible screen size into this parser.
fn parse_dom(node: &Node) -> Option<String> {
let mut parsed_content = String::new();
match node.element() {
Some(element) => match element.name.as_str() {
"h1" => {
if let Some(text) = extract_inline(node) {
parsed_content.push_str(&format!("\n# {}\n", text));
}
}
"h2" => {
if let Some(text) = extract_inline(node) {
parsed_content.push_str(&format!("\n## {}\n", text));
}
}
"p" => {
if !element.classes.is_empty() && element.classes[0] == "pw-post-body-paragraph" {
if let Some(text) = extract_inline(node) {
parsed_content.push_str(&format!("\n{}\n", text.trim()));
}
}
}
"pre" => {
if let Some(text) = extract_inline(node) {
parsed_content.push_str(&format!("```\n{}\n```\n", text));
}
}
"source" => {
if let Some(links_str) = element.attributes.get("srcSet") {
match links_str {
Some(links_str) => {
let links = links_str.split(" ").collect::<Vec<&str>>();
if let Some(link) = links.first().filter(|link| link.contains("webp")) {
parsed_content
.push_str(&format!("\n", link.trim()));
}
}
None => {}
}
}
}
_ => {
for child in &element.children {
if let Some(child_content) = parse_dom(child) {
parsed_content.push_str(&child_content);
}
}
}
},
None => {}
};
if parsed_content.is_empty() {
None
} else {
Some(parsed_content)
}
}This is pretty much it for the parser. Now, In order to test the functionality , let’s write some unit tests.
Unit Testing Parser
#[cfg(test)]
mod test {
use crate::parser::*;
use html_parser::Dom;
#[test]
fn test_heading() {
let html = "<html><head></head><body><h1>Hii</h1></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(markdown, "\n# Hii\n".to_string());
}
let html = "<html><head></head><body><h2>Hii</h2></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(markdown, "\n## Hii\n".to_string());
}
}
#[test]
fn test_paragraph() {
let html = "<html><head></head><body><p>Hii</p></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(markdown, "".to_string());
}
let html =
"<html><head></head><body><p class='pw-post-body-paragraph'>Hii</p></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(markdown, "\nHii\n".to_string());
}
}
#[test]
fn test_code_snippets() {
let html = "<html><head></head><body><pre>fn main() { println!(\"Hello, World!\"); }</pre></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(
markdown,
"```\nfn main() { println!(\"Hello, World!\"); }\n```\n".to_string()
);
}
}
#[test]
fn test_image() {
let html = "<html><head></head><body><source srcSet='https://example.com/image.webp'></source></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(
markdown,
"\n".to_string()
);
}
}
#[test]
fn test_nested_elements() {
let html = "<html><head></head><body><h1>Heading</h1><p class='pw-post-body-paragraph'>Paragraph</p></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(markdown, "\n# Heading\n\nParagraph\n".to_string());
}
}
#[test]
fn test_text_formatting() {
let html = "<html><head></head><body><h1>Heading</h1><p class='pw-post-body-paragraph'>Paragraph <strong>bold</strong> <em>italic</em></p></body></html>";
if let Ok(dom) = Dom::parse(&html) {
let markdown = parse_medium_post(dom).unwrap();
assert_eq!(
markdown,
"\n# Heading\n\nParagraph **bold** *italic*\n".to_string()
);
}
}
}
Just to note that in order to make this work you’d need to do mod test in your main.rs file. This is how your main.rs should look like.
mod dom;
mod parser;
mod test;
fn main() {}
Writing a CLI client for ease of users
The input arguments that the user needs to provide should be a URL and a filename where they want to dump their markdown content. Let’s build a CLI using our rust standard crates and functionalities.
use std::env;
use std::fs;
use std::io::Write;
mod dom;
mod parser;
mod test;
fn main() {
let args: Vec<String> = env::args().collect();
if args.len() != 3 {
eprintln!("Usage: {} <URL> <file_name>", args[0]);
return;
}
let url = &args[1];
let file_name = &args[2];
match dom::dom(url) {
Ok(dom) => {
if let Ok(markdown) = parser::parse_medium_post(dom) {
if let Err(err) = write_to_file(file_name, &markdown) {
eprintln!("Error writing to file: {}", err);
}
} else {
eprintln!("Error parsing Medium post");
}
}
Err(e) => eprintln!("{}", e),
};
}
fn write_to_file(file_name: &str, content: &str) -> std::io::Result<()> {
let mut file = fs::File::create(file_name)?;
file.write_all(content.as_bytes())?;
Ok(())
}
Wrap Up
Finally, You have got the ready made version of the medium to markdown parser and this is important in order to preserve your blogs or content independently of the centralized platforms to safeguard in case something goes wrong.
Personally, This is one of my most involved project learning wise because hardly I write some code to build a tool or utility by realizing the Tree data structure. Apart from it , I have also learned about the system design aspect of how medium manages the scalable images for all screen sizes and stores them in two different formats for optimizing. Another important thing was parser AST knowledge.
I am already releasing the version of this parser as a crate to the official rust crate.io so that it could be a tool useful for community around. Finally, Don’t hesitate to visit Github if something looks missing or even just to appreciate the efforts maybe leave a star ⭐ .
Github Link : https://github.com/Harshil-Jani/medium-to-markdown
Crate Link : https://crates.io/crates/medium-to-markdown
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK