

Claude tops GPT 4 in blind comparisons
source link: https://birchtree.me/blog/claude-tops-gpt-4-in-blind-comparisons/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Claude tops GPT 4 in blind comparisonsMastodon
Benj Edwards writing for ArsTechnica: “The King Is Dead”—Claude 3 Surpasses GPT-4 on Chatbot Arena for the First Time
On Tuesday, Anthropic's Claude 3 Opus large language model (LLM) surpassed OpenAI's GPT-4 (which powers ChatGPT) for the first time on Chatbot Arena, a popular crowdsourced leaderboard used by AI researchers to gauge the relative capabilities of AI language models.
There are all sorts of chatbot leaderboards on the web, and I don’t take many of them very seriously. I guess it’s academically interesting how well each model does in standardized tests, but I don’t personally find that a super compelling data point that helps me figure out which model is going to be most useful for the sorts of things I do with them.
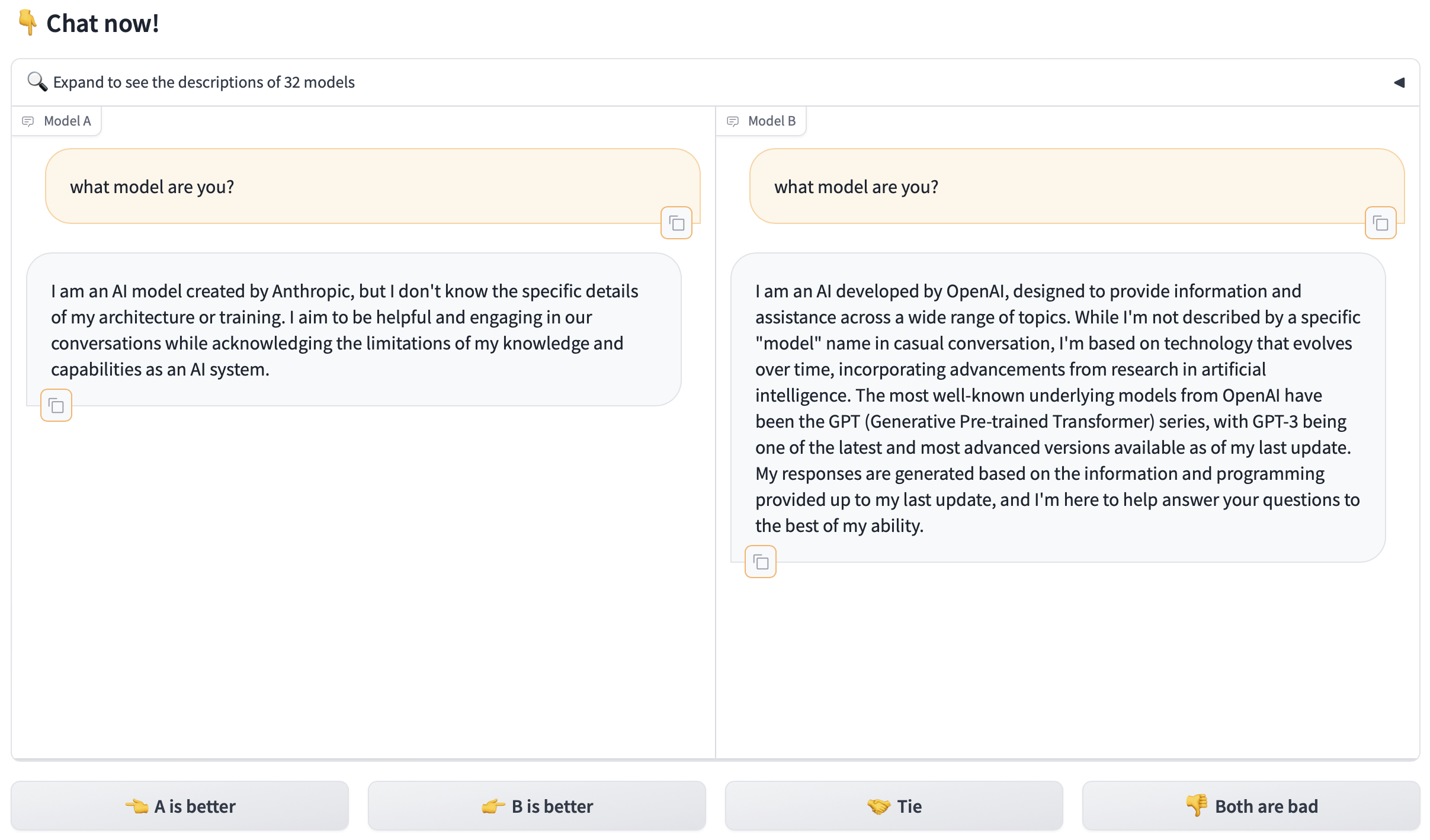
But Hugging Face’s leaderboard is more interesting and you can contribute to the votes yourself by using their testing page to ask your own questions and compare the results from two unnamed models. I played with this for a bit today and my big takeaways were:
- I also preferred Claude’s responses almost every single time it was in the comparison.
- There’s something called “command-r” that lost in every single comparison it appeared in. Woof.
Oh, and you can cheat if you really want to ?
</article
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK