

BOLT Optimization Technology Could Bring Obvious Performance Uplift On Arm Serve...
source link: https://community.arm.com/arm-community-blogs/b/infrastructure-solutions-blog/posts/bolt-optimization-technology
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
BOLT optimization technology could bring obvious performance uplift on arm server

BOLT is a post-link optimization technology which builds on LLVM framework, which leverages perf tool to collection sampling data and convert the executable into an optimized version. After evaluating BOLT on several workloads such as MySQL, Redis, memcached and nginx on arm server, we could see obvious performance uplift.
This blog post illustrates the methods used to enable BOLT and performance results of the workloads mentioned previously, please refer to llvm-bolt github project for more details.
Test environment
To collect branch sampling data, CoreSight is needed to be enabled. All of the workloads are run on N1SDP as we could only enable CoreSight on N1SDP currently, the clients are running on a Ampere Altra 2P.

Test Environment for BOLT
Steps to enable BOLT
To enable BOLT, we will need to build llvm-bolt firstly:
git clone https://github.com/llvm/llvm-project.git mkdir build cd build cmake -G Ninja ../llvm-project/llvm -DLLVM_TARGETS_TO_BUILD="X86;AArch64" -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=ON -DLLVM_ENABLE_PROJECTS="bolt" ninja bolt
Also, CoreSight functionality needs to be enabled on N1SDP, this is done by building and installing a customized kernel:
git clone https://git.gitlab.arm.com/arm-reference-solutions/linux.git git reset --hard d2e55d92eefd99ede330270b00c01b734a6b61c0
To capture the etm perf data, we'll need to build perf with opencsd supported:
git clone https://github.com/Linaro/OpenCSD.git my-opencsd cd my-opencsd/decoder/build/linux/ make LINUX64=1 DEBUG=1 make install cp /usr/local/lib64/libtraceevent.* /usr/local/lib/ cp -a /usr/local/lib64/traceevent/ /usr/local/lib/ export C_INCLUDE_PATH=/usr/include/python3.6m/ make -C tools/perf CORESIGHT=1 VF=1 ARCH=arm64 NO_JEVENTS=1
Once the system is properly configured with coresight and perf tool ready, we can following the steps to enable BOLT for various workloads:
- Rebuild workload with compile option "-fno-reorder-blocks-and-partition" and link option "--emit-relocs".
- Run workload
-
Collect perf data with:
Fullscreenperf record -e cs_etm//u -a -o perf.data -- sleep 180perf record -e cs_etm//u -a -o perf.data -- sleep 180
-
Convert workload executable into BOLT optimized version:
Fullscreen$ perf2bolt -p perf.data -o perf.fdata --itrace=l64i1us [executable]$ llvm-bolt [executable] -o [executable].bolt -data perf.fdata -reorder-blocks=ext-tsp -reorder-functions=hfsort -split-functions -split-all-cold -split-eh -dyno-stat$ perf2bolt -p perf.data -o perf.fdata --itrace=l64i1us [executable] $ llvm-bolt [executable] -o [executable].bolt -data perf.fdata -reorder-blocks=ext-tsp -reorder-functions=hfsort -split-functions -split-all-cold -split-eh -dyno-stat
- Run executable and <executable>.bolt and then compare performance between them.
Benchmark results
By testing workloads such as MySQL, Redis, Memcached and nginx, we could see obvious performance uplift after enabling BOLT (three round of tests are done for every workloads and the minimum uplift number was selected for comparison), shown in the following graph:
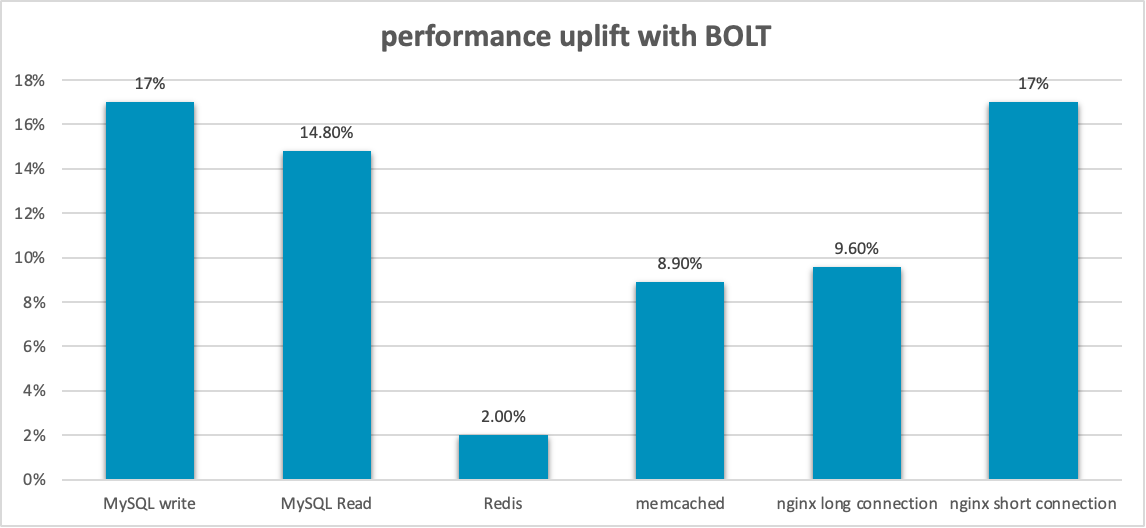
Performance test report of BOLT
By checking perf data of running MySQL write, it indicates there are noticeable miss drops for those 3 metrics:
- l1 icache miss decreases from 4.46% to 3.3%
- branch miss decreases from 5.79% to 3.19%
- iTLB load miss decreases from 0.95% to 0.63%
This is an evidence shows how BOLT improves performance.
Summary
From the tests we run, we could learn that BOLT is a powerful method to optimize workload performance which we could see obvious performance uplift for several typical workloads.
Please note it requires CoreSight to be enabled to capture branch profiling data as we didn't see performance improvement if without capturing branch profiling data, also a rebuild for workload is necessary to allow the executable to be relocated.
However, thing would become simpler once the BRBE feature is supported in future arm architecture.
In a word, this is a performance optimization technology we would highly recommend to use.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK