

调优-cpu毛刺问题通用优化思路
source link: http://xiaoyue26.github.io/2022/11/21/2022-11/cpu%E6%AF%9B%E5%88%BA%E9%97%AE%E9%A2%98%E9%80%9A%E7%94%A8%E4%BC%98%E5%8C%96%E6%80%9D%E8%B7%AF/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
工作中可能会遇到这么一种现象:
服务的cpu平均值不高,但是偶尔会有毛刺,也就是峰值高、均值低。
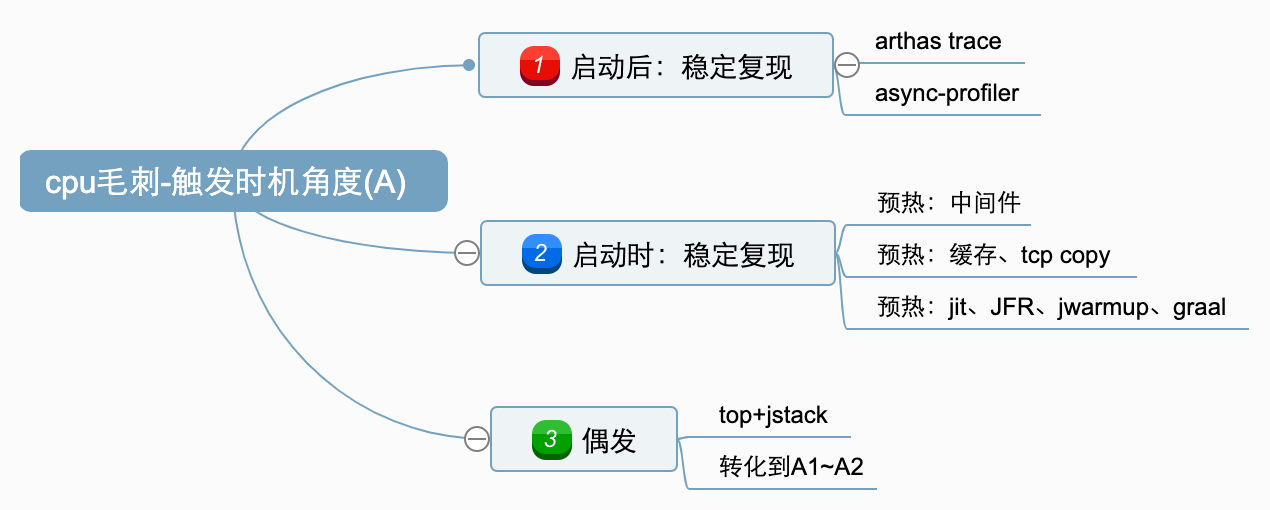
这里需要分类讨论,从触发时机角度可以分3类:
A1。启动后可稳定复现;(或者大概率)
A2。启动时稳定复现;(或者大概率)
A3。无法稳定复现;
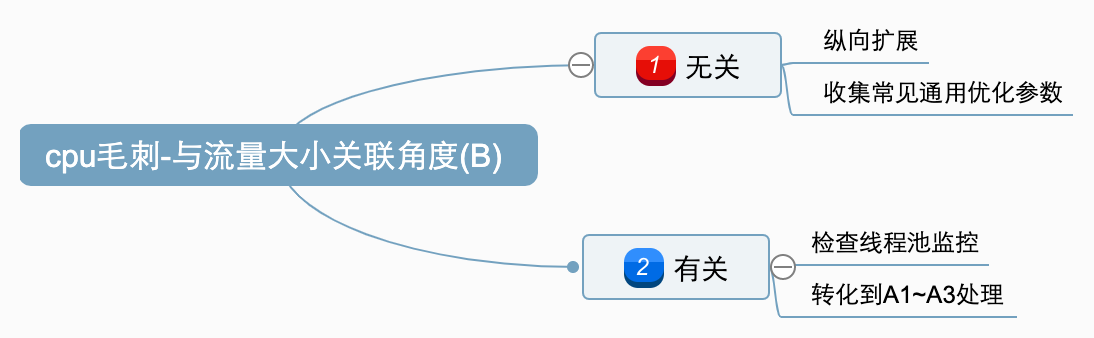
从cpu峰值和流量大小的关系,则可以分2类:
B1: 峰值与流量大小无关;
B2: 峰值与流量大小有关;
对于上一节中的几种分类现象,其实大致是从易到难排列的,解决方案依次有:
A1,启动后稳定复现
也就是提供服务期间,某些特定请求会触发,例如之前遇到过的情况:
http://xiaoyue26.github.io/2022/09/25/2022-09/%E8%B0%83%E4%BC%98-%E8%A7%A3%E5%86%B3%E7%BA%BF%E7%A8%8B%E6%B1%A0%E9%80%A0%E6%88%90%E7%9A%84%E8%BF%9B%E7%A8%8B%E5%8D%A1%E9%A1%BF%E3%80%81cpu%E6%AF%9B%E5%88%BA%E9%97%AE%E9%A2%98/
这个时候可以使用arthas的trace命令,找出耗时长的代码链路:
options unsafe true
trace -E java.util.concurrent.CompletableFuture|java.lang.Thread supplyAsync|asyncSupplyStage|start -n 1 --skipJDKMethod false '#cost > 200'
还可以使用async-profiler工具,打印火焰图,查看cpu使用率较高的调用栈,参考:
http://xiaoyue26.github.io/2020/12/20/2020-12/%E7%BA%BF%E4%B8%8A%E6%80%A7%E8%83%BD%E4%BC%98%E5%8C%96-%E6%9F%A5%E7%9C%8B%E6%96%B9%E6%B3%95%E7%BA%A7%E8%80%97%E6%97%B6/
A2.启动时稳定复现
首先,A2类可以转化为A1类问题中的async-profiler解法来查看原因。
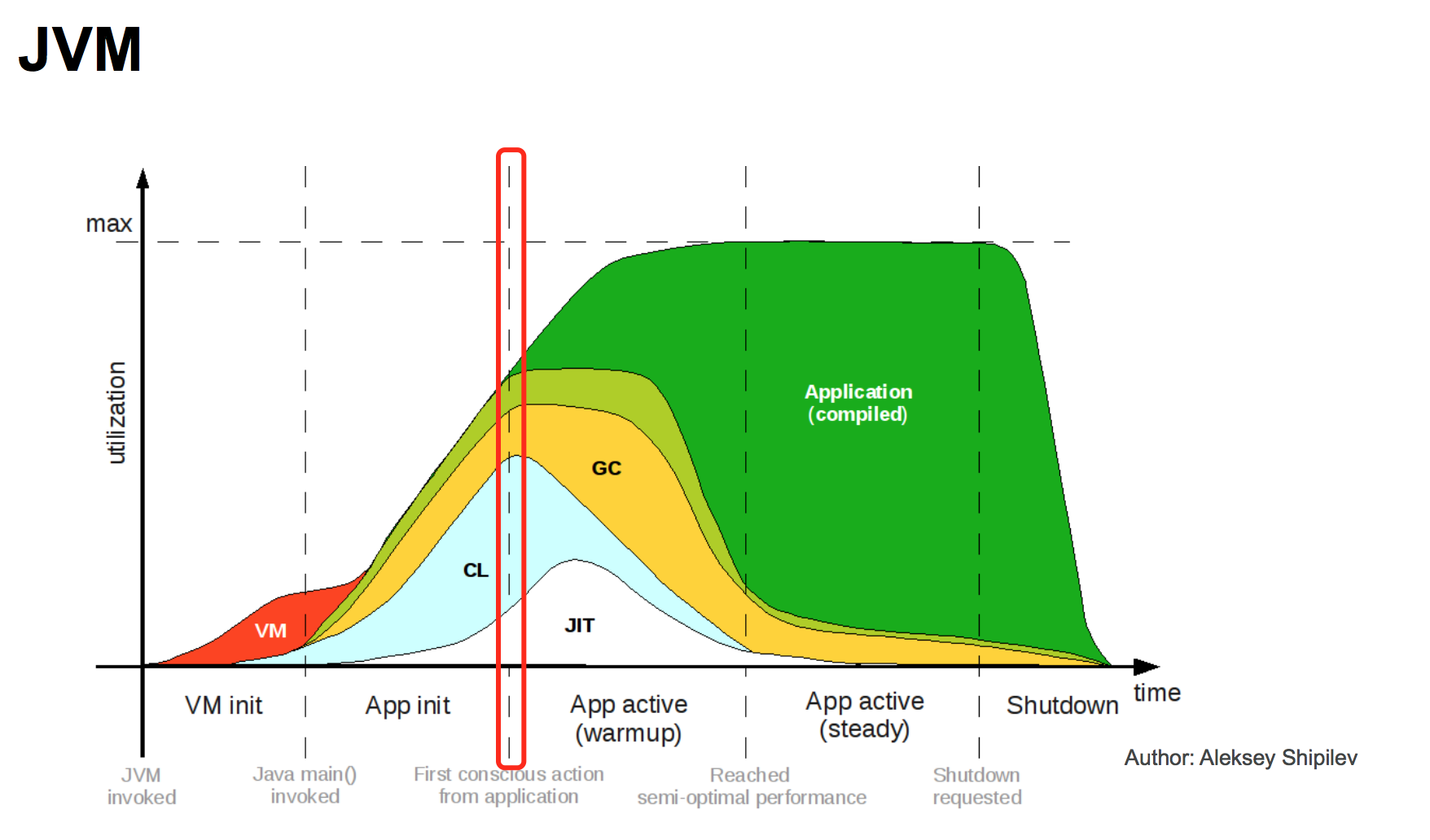
然后这类问题一般会发现是有些资源没有预热导致的,大致包括:
1。中间件类:mysql等框架组件;
2。缓存:如redis\内存缓存;
3。jit热点代码;(可以观察内存的codeHeap部分大小变化)
解决方案主要是对外提供服务前,先预热好上述资源,大致方法包括:
1。启动时手动用代码调用相应接口,触发各种资源的加载;
2。对外提供服务前,先用tcpcopy之类的工具复制流量预热;
或者分阶段承接流量,先10%,再50%,再100%。
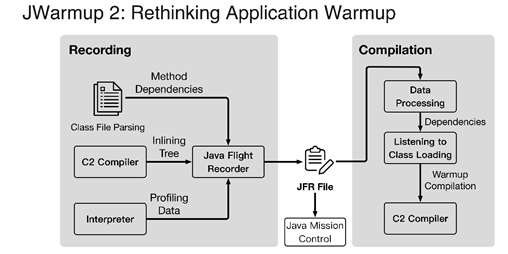
3。用阿里的jwarmup功能,用第一个实例的jfr文件,提供给其他实例触发编译,参考:
https://developer.aliyun.com/ask/321147
- 升级jit编译器,改用
graal。
或者如果是-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompilercodeHeap满的问题,可以关掉flushing,增加size:-XX:-UseCodeCacheFlushing -XX:ReservedCodeCacheSize=320M
A3.无法稳定复现
对于偶发的cpu毛刺,确实比较麻烦,上次遇到了每1~3天只发生1次、时间无规律、也不一定出现在哪个容器上的情况,真是比较头疼。
这种情况比较难处理,只能进一步简化为每次发生的时候持续时间>1s的情况。
基本解决思路是,启动一个后台进程,不断检查cpu占用情况,然后一旦发现cpu超限,就打印调用栈。
因为没搜到现成的工具,我手写了一个简单的python脚本:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import re
import subprocess
import time
pid = "136" # jps find it
print("start")
while True:
top_info = subprocess.Popen(["top", "-H", "-p", pid, "-n", "1", "-b"], stdout=subprocess.PIPE)
out, err = top_info.communicate()
out_info = out.decode('unicode-escape')
line_list = out_info.split('\n')
top_line = line_list[7]
# print(line_list[6])
# print(top_line)
top_line = top_line.strip()
arr = re.split('\s+', top_line)
# print(arr)
cpu = float(arr[8])
# print(cpu)
thread_id = arr[0]
nid = hex(int(thread_id))
# print(nid)
nid_str = "nid=" + str(nid)
# print(nid_str)
if cpu > 50:
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())))
print(cpu)
print(nid)
print(line_list[6])
print(line_list[7])
print(line_list[8])
# jstack -l <pid> | grep 'nid=0xd6b' -A 14
top_info = subprocess.Popen(["jstack", "-l", pid], stdout=subprocess.PIPE)
out, err = top_info.communicate()
out_info = out.decode('unicode-escape')
out_arr = out_info.split('\n')
total = len(out_arr)
for i in range(total):
line = out_arr[i]
if nid_str in line:
for j in range(14):
print(out_arr[i + j])
break
time.sleep(10)
启动命令:
nohup python -u debug.py > jvm-debug.log 2>&1 &
echo $! > nohup.pid
tail -fn 100 jvm-debug.log
放到容器里,跟踪个几天,才能跟踪到异常时的栈。
graal编译器
有时候遇到一种情况就是抓出来发现是C2编译cpu高:
"C2 CompilerThread0" #6 daemon prio=9 os_prio=0 cpu=778138.42ms elapsed=64477.22s tid=0x00007fce3a2ba600 nid=0xa4 runnable [0x0000000000000000]
java.lang.Thread.State: RUNNABLE
Compiling: 90064 ! 4 java.net.URLClassLoader::findClass (47 bytes)
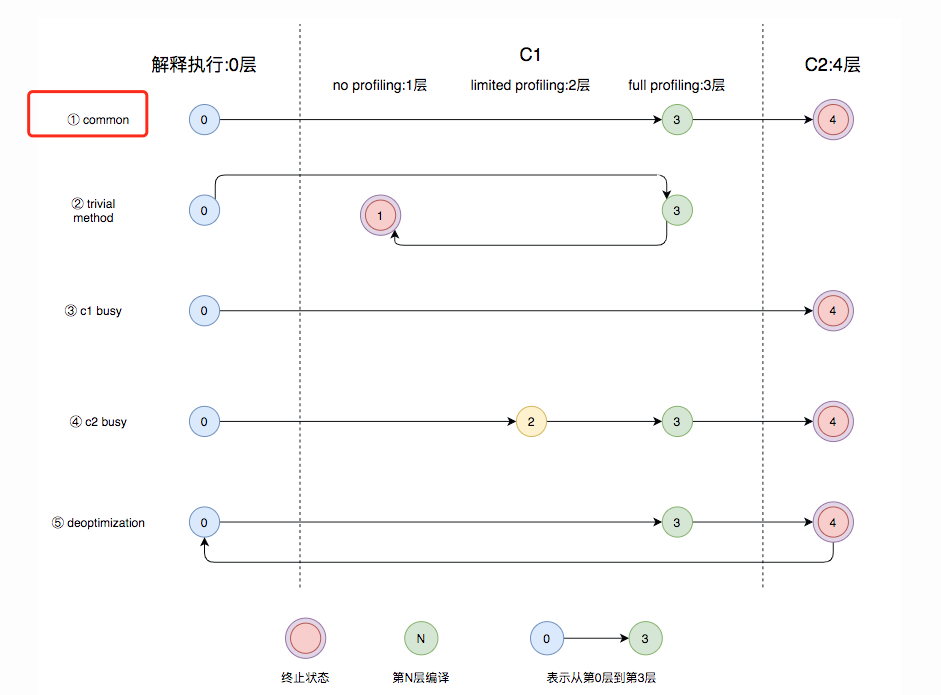
这种时候如果jdk版本>=8,可以考虑换成graal编译器。
当然大方向上有几个思路:
1.C2 cpu占用高,那可以减少c2的线程数(-XX:CICompilerCount);
(如果已经是2,c1和c2各占1个线程,那就无法再低了,也可以参考B1调整)
2.直接把C2关了,只用C1: -XX:TieredStopAtLevel=3;
这个非常激进,影响很大,启动会很慢,平时性能也会下降;不到万不得已不用。
3.提前录制JFR,启动时编译(jwarmup);
4.升级到graal编译器。
对于第四点,为什么有用呢,有以下几个原因:
定性得看,c2编译器从jdk8以后就不维护升级了,因为它是C++写的,作者表示不维护也不会升级了,其他人改它的可能性微乎其微。
而graal是新一代编译器,java写的,还在活跃,C2里有的优化会往graal搬,反之则不会。所以定性地看graal天然就有优势。
定量的看,graal有几个场景下的新优化:
1.使用了lambda表达式、虚函数、java以外的语言(scala,groovy,kotlin)的场景:
C2对于没法直接知道调用点地址的,没有进一步做内联;
而graal会去比较类代码地址,然后内联,所以对于上述场景也会内联,会更优化;
2.部分逃逸场景:
C2只处理完全不逃逸,graal则对于部分逃逸情况的对象也进行优化,进行栈上分配。
(栈上分配,实际实现是标量替换,直接把这个对象的所有字段展开、在栈上创建)。
比如一个对象如果仅在单个方法内(栈封闭),其实就是这个对象不会逃逸出这个线程的使用,不会并发,可以直接栈上分配,不用去堆。
而部分逃逸就是可能99%的情况是不逃逸的,只有1%的情况逃逸;graal可以推迟对象的创建,这样99%的情况可以栈上分配。
3.支持SIMD的CPU:
C2主要考虑循环展开,而graal会倾向于用向量化指令来优化,因此如果是支持SIMD的cpu,graal可能会有优势。
graal当然不只上述几个优化点(锁消除、数据流分析等),仅列举了几个比较好理解的,有兴趣可以搜素或者看参考资料中的链接。
如果要探究究竟编译了什么代码,可以打开jit日志,然后用jitwatch查看日志(或者直接自己肉眼parse看):
-XX:+UnlockDiagnosticVMOptions -XX:+PrintCompilation -XX:+PrintInlining -XX:+PrintCodeCache -XX:+PrintCodeCacheOnCompilation -XX:+TraceClassLoading -XX:+LogCompilation -XX:LogFile=jit.log
B1 cpu峰值与流量大小无关
前面A1到A3都涉及到先定位原因,再解决问题。
如果时间紧迫,情况又是B1这种简单情况,其实可以考虑先简单改下基础配置来先临时顶一下。后续再慢慢考虑A1到A3优化。
比如如果我们cpu均值使用是20%、峰值是120%,根据监控,峰值(毛刺)部分出现的时机和流量大小无关;
并不是流量大的时候才会出现,这种时候,我们可以把容器的基础配置改改,升核数、降实例数:
before: 4核8GB x 16个
after: 8核16GB x 8个
修改后,cpu均值使用40%,峰值60%,就都处于安全区间了。
当然,如果cpu均值是25%,峰值是320%,差距过于大,调完变成均值100%、峰值100%(max(80%,100%))了,这种方法就无法使用了。
也可以考虑一些通用的优化,比如:
-XX:-PreserveFramePointer 关闭打调用栈用的存储来优化性能
-XX:+UseLargePages
-XX:+UseTransparentHugePages
-XX:-PreserveFramePointer类似于GCC的 -fomit-frame-pointer 选项,PreserveFramePointer选项会将函数调用的frame pointer保存至寄存器,给perf等基于backtrace获取完整调用堆栈的场景提供支持,但同时也额外多执行了一些指令,引入一定开销。
JVM自身提供的jvmti接口,可以在不依赖PreserveFramePointer的情况下,获取Java堆栈,构建在其之上的jstack、async-profiler(AsyncGetCallTrace) 等工具也都不依赖PreserveFramePointer.
鉴于 「使用native工具获取Java堆栈 」这种场景出现的频率低,而常用JVM诊断工具均不依赖此参数,可以考虑仅在有限环境下开启PreserveFramePointer
B2 cpu峰值与流量大小有关
这种情况可能是高并发情况下触发了什么缺陷。
可以看看线程池的使用率,看看是哪个线程池飙升了,针对性进行优化业务代码。
或者可以通过压测或者分解成A1到A3的情况进行处理。
https://heapdump.cn/topic/UseLargePages
https://www.modb.pro/db/37684
https://zhuanlan.zhihu.com/p/459695978
https://martijndwars.nl/2020/02/24/graal-vs-c2.html
https://mp.weixin.qq.com/s/7PH8o1tbjLsM4-nOnjbwLw
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK