

G1调优-复杂业务治理小记
source link: https://xiaoyue26.github.io/2022/03/25/2022-03/G1%E8%B0%83%E4%BC%98-%E5%A4%8D%E6%9D%82%E4%B8%9A%E5%8A%A1%E6%B2%BB%E7%90%86%E5%B0%8F%E8%AE%B0/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
G1调优-复杂业务治理小记
- Region size;
- Profile出不合理的内存分配代码,优化或者迁移;
- 确实有比较高内存消耗的场景,提早收集;
一般来说8~64GB的堆用G1垃圾收集器还是比较省心,只需要配置regionSize和停顿时间基本就不用管了。
相关参数: -XX:G1HeapRegionSize=16M, -XX:MaxGCPauseMillis=200
不一般的情况也偶有发生,
工作中我们的一个老服务就遇到了停顿时间太长的问题。
这个老服务首先jdk版本较低只有8,
其次服务里有非常多不同类型的业务接口,承担了极为复杂的业务功能。
复杂度正比于 ~ 公司所有其他对外业务的功能*公司内大量对内业务的功能。
线上服务gc停顿时间达到3~5s,偶尔甚至达到10s.
1。 收集信息
1。 通过arthas的dashboard或jstat -gcutils观察内存消耗特别快,gc日志里能看到时不时就to-space耗尽了。
2。 但是经过gc能够回收,说明没有太长时间的内存泄露,用jmap就很难找到对应的内容或者相关代码了。
// 同时jmap会卡住线上服务进入safepoint,停顿时间分钟级,然后上传、加载估计半小时起步,风险和成本太高,收益较难达到。
3。 预发环境没有问题,只有线上有,说明是用户请求触发的。
4。 gc日志里source: concurrent humongous allocation较多。
2。 profile
如果jdk16的话,可以长期开着Profile(sample事件),但是这个老服务是jdk8,因此需要重新监控一下内存分配的事件:
./async-profiler-2.7-linux-x64/profiler.sh -d 300 -f 5min.jfr -e alloc --alloc 10m <pid>
首先记录下线上服务进程的jfr黑匣子,然后再输出一下ObjectAllocationOutsideTLAB事件并统计:
# 分配大对象次数最多: :
jfr print --events jdk.ObjectAllocationOutsideTLAB 5min.jfr | grep allocationSize | awk -F'=' '{print $2}' | sort | uniq -c | sort -n
# 每次分配内存对象最大:
jfr print --events jdk.ObjectAllocationOutsideTLAB 5min.jfr | grep allocationSize | awk -F'=' '{print $2}' | sort | uniq | sort -n
找到对应的allocationSize以后,再grep出对应的堆栈:
jfr print --events jdk.ObjectAllocationOutsideTLAB --stack-depth 16 5min.jfr | grep 19538928 -A 16 -B 3
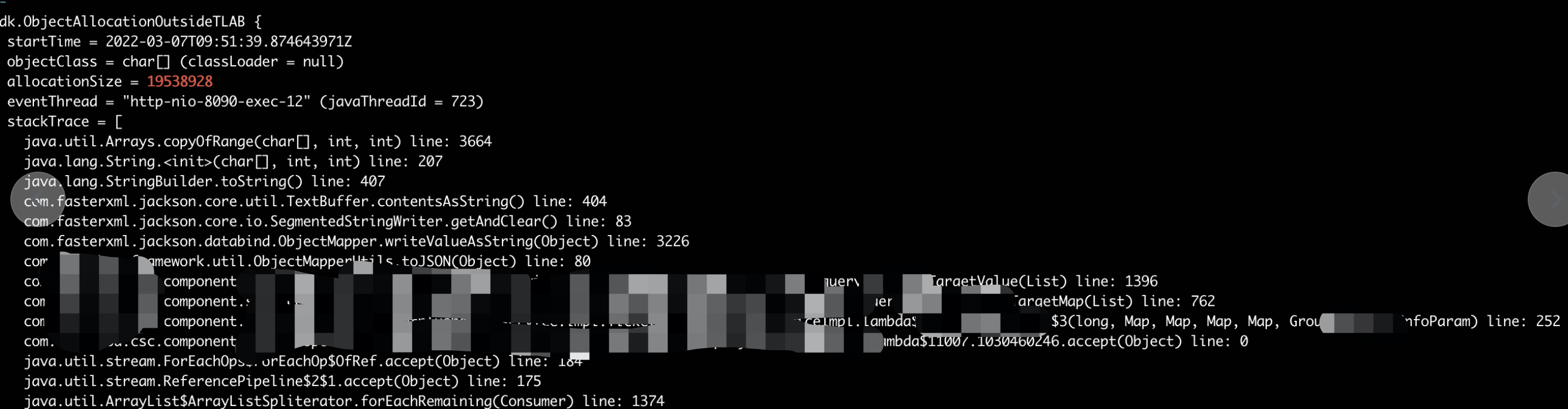
至此就抓到疯狂分配内存的元凶代码了。
3。改代码
这里因为是18MB * 上百次/每秒的内存申请,由于我们的regionSize是16MB,18MB是大对象(即使我们设置成最大32MB也还是会判定成大对象)
,而且内存碎片特别多(18MB要两个region才能放得下,也就是浪费16*2-18=14MB)。所以调gc参数的方式处理的话比较困难。
另一个方向是改代码,这里同事是在logger.debug的时候写了一个toJSON方法,虽然不会打印,但toJSON还是执行了。
将超大的对象数组toJSON,因此内存消耗巨大。
所以我们简单把日志改成sl4j的fluentApi,用suplier做toJSON就解决了问题。
重新上线,gc停顿时间消失。
logger.atDebug().log(() -> toJSON(args));
回顾:WHY
java创建对象的内存分配从好到坏有4种:
1.栈上分配: 如果是线程封闭的、足够小的对象,可以优化到栈上;
2.TLAB分配;
3.outside TLAB+eden分配;
4.H region分配;
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK