

Porting x86 vector bitmask optimizations to Arm NEON - Infrastructure Solutions...
source link: https://community.arm.com/arm-community-blogs/b/infrastructure-solutions-blog/posts/porting-x86-vector-bitmask-optimizations-to-arm-neon
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Bit twiddling with Arm Neon: beating SSE movemasks, counting bits and more

Danila Kutenin is a Senior Software Engineer at Google Cloud in the Data Processing Efficiency team.
With the rise of Arm hardware in major cloud providers like Google (see our release), Amazon and Microsoft, and new client devices, better-optimized applications are looking to support Arm NEON and SVE. This post showcases some optimization techniques we used when porting from x86 to Arm.
When moving to Arm, the application code needs to be recompiled. While this is often straightforward, one challenge can be porting hand-written x86 intrinsics code to make the best use of the Arm architecture. There are a few SSE to Neon porting blogs that can make it easy to get something running, but they focus on portability and can sometimes be further optimized for best performance.
At Google, we found that some workloads were up to 2x slower if we used portable libraries or directly replaced x86 intrinsics with equivalent Arm instruction sequences. We would like to share our experience to highlight some under-appreciated Arm optimizations and showcase how they can benefit widely used libraries like hashtables, ZSTD, strlen, memchr, memcmp, variable integer, and more.
When comparing Arm NEON with the SSE instruction set, most instructions are present in both. E.g. 16-byte memory loads (_mm_loadu_si128 and vld1q_u8), vector comparisons (_mm_cmpgt_epi8 and vcgtq_s8) or byte shuffles (_mm_shuffle_epi8 and vqtbl1q_s8). However, developers often encounter problems with Arm NEON instructions being expensive to move to scalar code and back. This is especially true for the Move Byte Mask (PMOVMSKB) instruction.
Move Byte Mask (PMOVMSKB) is an x86 SSE2 instruction that creates a mask from the most significant bit of each 8-bit lane in a 128-bit register and writes the result to a general-purpose register. It is often used in tandem with vector comparison instructions, like PCMPEQB, to quickly scan a buffer for some byte value,16 characters at a time.
For example, suppose we want to index occurrences of the space character (0x20) in the string, “Call me Ishmael.” Using SSE2 instructions, we could do the following:

Then it becomes straightforward to know if a vector has some matching character (just comparing this mask to zero) or finding the first matching character, all you need to do is to compute the number of trailing zeros through bsf (Bit Scan Forward) or tzcnt instructions. Such an approach is also used together with bit iteration in modern libraries like Google SwissMap and ZSTD compression:
ZSTD_VecMask ZSTD_row_getSSEMask(int nbChunks, const BYTE* const src,
const BYTE tag, const U32 head) {
// …
const __m128i chunk = _mm_loadu_si128((const __m128i*)(src + 16*i));
const __m128i equalMask = _mm_cmpeq_epi8(chunk, comparisonMask);
matches[i] = _mm_movemask_epi8(equalMask);
// …
}
MEM_STATIC U32 ZSTD_VecMask_next(ZSTD_VecMask val) {
return ZSTD_countTrailingZeros64(val);
}
for (; (matches > 0) && (nbAttempts > 0); --nbAttempts, matches &= (matches - 1)) {
U32 const matchPos = (head + ZSTD_VecMask_next(matches)) & rowMask;
// …
}matches &= (matches - 1) sets the lowest bit of 1 to zero and is sometimes referred to as Kernighan's algorithm.
Such techniques are used in string comparisons, byte searches, and more. For example, in strlen, the algorithm should find the first zero byte, in memcmp the first non-matching byte, in memchr the first matching character. Arm NEON does not have a PMOVMSKB equivalent which prevents it from benefiting from the same approach. Direct translation from x86 would require a redesign of programs or emulating x86 intrinsics which would be suboptimal. Let us look at some examples using SSE2NEON and SIMDe:
int _mm_movemask_epi8(__m128i a) {
uint8x16_t input = vreinterpretq_u8_m128i(a);
uint16x8_t high_bits = vreinterpretq_u16_u8(vshrq_n_u8(input, 7));
uint32x4_t paired16 = vreinterpretq_u32_u16(vsraq_n_u16(high_bits, high_bits, 7));
uint64x2_t paired32 = vreinterpretq_u64_u32(vsraq_n_u32(paired16, paired16, 14));
uint8x16_t paired64 = vreinterpretq_u8_u64(vsraq_n_u64(paired32, paired32, 28));
return vgetq_lane_u8(paired64, 0) | ((int) vgetq_lane_u8(paired64, 8) << 8);
}int32_t
simde_mm_movemask_epi8 (simde__m128i a) {
int32_t r = 0;
simde__m128i_private a_ = simde__m128i_to_private(a);
static const uint8_t md[16] = {
1 << 0, 1 << 1, 1 << 2, 1 << 3,
1 << 4, 1 << 5, 1 << 6, 1 << 7,
1 << 0, 1 << 1, 1 << 2, 1 << 3,
1 << 4, 1 << 5, 1 << 6, 1 << 7,
};
uint8x16_t extended = vreinterpretq_u8_s8(vshrq_n_s8(a_.neon_i8, 7));
uint8x16_t masked = vandq_u8(vld1q_u8(md), extended);
uint8x8x2_t tmp = vzip_u8(vget_low_u8(masked), vget_high_u8(masked));
uint16x8_t x = vreinterpretq_u16_u8(vcombine_u8(tmp.val[0], tmp.val[1]));
r = vaddvq_u16(x);
return r;
}We are not going to get into the details of any of the implementations above. They are good default options while porting. However, they are not best for performance as they both require at least 4 instructions each with at least 2 cycles latency whereas movemask takes a single cycle on most modern x86 platforms.
One instruction that has not been given sufficient consideration by most libraries including glibc is shrn reg.8b reg.8h, #imm. It has the following semantics: let us consider a vector of 128-bits as eight 16-bit integers, shift them right by #imm and “narrow” (in other words, truncate) to 8-bits. In the end, we are going to have a 64-bit integer from such a truncation. When we shift with imm = 4 it has the effect of producing a bitmap where each output byte contains the lower four bits of the upper input byte combined with the upper four bits of the lower input byte.
This video shows shrn in operation.
Here is an example of getting a mask for comparing 128-bit chunks by finding a byte tag:
const uint16x8_t equalMask = vreinterpretq_u16_u8(vceqq_u8(chunk, vdupq_n_u8(tag))); const uint8x8_t res = vshrn_n_u16(equalMask, 4); const uint64_t matches = vget_lane_u64(vreinterpret_u64_u8(res), 0); return matches; // return & 0x8888888888888888ull; // Get 1 bit in every group. This AND is optional, see below.
In other words, it produces 4-bit out of each byte, alternating between the high 4-bits and low 4-bits of the 16-byte vector. Given that the comparison operators give a 16-byte result of 0x00 or 0xff, the result is close to being a PMOVMSKB, the only difference is that every matching bit is repeated 4 times and is a 64-bit integer. However, now you can do almost all the same operations as you were doing with PMOVMSKB. Consider the result in both cases as the result of PMOVMSKB or shrn:

We use a combination of rbit and clz as the arm instruction set does not have ctz (Count Trailing Zeros) instruction. For iteration use the first version, if the matching set is not big as the second one needs to preload 0xf000000000000000ull in a separate register. For example, for probing open-addressed hashtables, we suggest the first version, but for matching strings with a small alphabet, we suggest the second version. When in doubt, use the first one or measure performance for both.
Case study: ZSTD
ZSTD from version 1.5.0 introduced SIMD-based matching for levels 5-12. We optimized levels 5-9 by 3.5-4.5 percent and level 10 by 1 percent.
|
Before |
After |
||
|
|
Case study: memchr and strlen
The memory and string functions in the C standard library are fundamental functions to work with strings and byte searching. The memchr function searches for one particular byte and the strlenfunction searches for the first zero. Prior to our work, the implementation in glibc (the most popular implementation of the C standard library) tried to get a similar 64-bit mask with the help of another approach.
For each 16-byte chunk, a 64-bit nibble mask value was calculated with four bits per byte. For even bytes, bits 0-3 are set if the relevant byte matched but bits 4-7 must be zero. Likewise for odd bytes, adjacent bytes can be merged through addp instruction which adds bytes in pairs (1st and 2nd, 3rd and 4th, etc.) as shown in the diagram below:
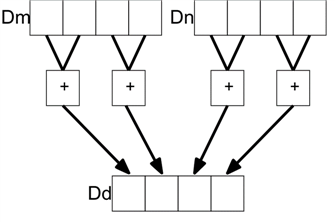
Getting the 64-bit mask where every matching byte of a 16-byte vector corresponds to 4 bits in the final value:
mov wtmp, 0xf00f dup vrepmask.8h, wtmp and vhas_chr.16b, vhas_chr.16b, vrepmask.16b addp vend.16b, vhas_chr.16b, vhas_chr.16b /* 128->64 */
We replaced this with:
shrn vend.8b, vhas_chr.8h, 4 /* 128->64 */
And obtained 10-15 percent improvements on a strlen distribution extracted from the SPEC CPU 2017 benchmark. For reference, check the patch in Arm Optimized Routines and glibc.
We would like to note that the main loop in memchr still looks for the maximum value out of four 32-bit integers through umaxp instruction: when comparing, it checks that the max byte is not zero. If it is not, it uses shrn to get the mask. Experiments showed this is faster for strings (>128 characters) as on cores like Neoverse N1, it uses 2 pipelines V0/V1 whereas shrn uses only one pipeline V1, but both have the same latency. Such an approach showed better results overall and is suitable for more workloads. So, if you are checking for existence in a loop, consider using umaxp instruction followed by shrn: it might have a threshold where it is faster than only using shrn.
Case study: Vectorscan
Vectorscan is a portable fork of a famous regex engine Hyperscan which was highly optimized for x86 platforms with intrinsics all over the place. A part of the reason to create such a fork was to provide better performance for Arm. We applied the same optimization and got some benefits on real-life workloads by optimizing pattern matching.
You can check the code in pull request, or for more details see this video from Arm DevSummit 2021.
Case study: Google SwissMap
At Google, we use the implementation of abseil hashmaps, which we refer to as 'Swiss Map'. In our design doc, we store the last 7 bits of hash in a separate metadata table and do a lookup of the last 7 hash bits in the vector to probe the position:
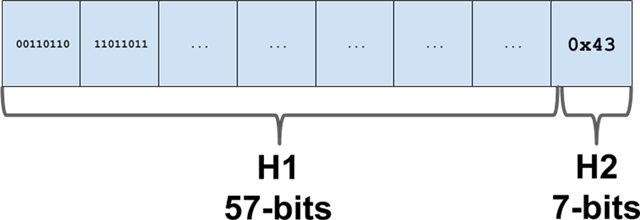

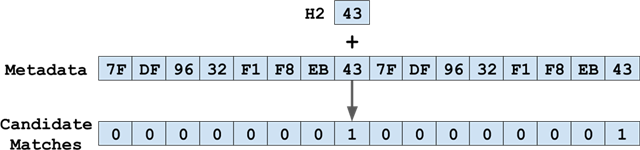
For x86, we use movemasks to implement this:
Mask Match(h2_t hash) const {
auto match = _mm_set1_epi8(hash);
return Mask(_mm_movemask_epi8(_mm_cmpeq_epi8(match, metadata)));
}
For Arm NEON, we used 64-bit NEON which gave us 8-byte masks of 0x00 or 0xff and then we used similar ideas for iteration but with a different constant which marked only one bit in every byte. Other options like using shrn instruction was not as optimal.
Mask Match(h2_t hash) const {
uint8x8_t dup = vdup_n_u8(hash);
auto mask = vceq_u8(ctrl, dup);
constexpr uint64_t msbs = 0x8080808080808080ULL;
// Get the 8x8 vector as a uint64_t.
return Mask(vget_lane_u64(vreinterpret_u64_u8(mask), 0) & msbs);
}In the end, we optimized all operations of hashtables by 3-8 percent. The commit and exact details can be found here.
Fascinating instruction: cls
One instruction that is rarely used but might be useful is cls – Count Leading Sign bits. It counts how many consecutive bits starting after the sign bit are equal to it. For example, for 64-bit integers we have:

We found it useful to be in cases when you know the first match happens:
while (FirstMatch(p)) {
// Get16ByteMatch can be vceqq_u8(vld1q_u8(p), vdupq_u8(value)); or anything that produces a mask
uint64_t matches = vshrn_n_u16(Get16ByteMatch(p));
// Skip all matching. rbit is bit reversal to count trailing matches on little endian.
p += (__clsll(__rbitll(matches)) + 1) >> 2; // +1 to count the sign bit itself.
}
This was useful for hashtable iteration to skip empty or deleted elements. Even though we ended up using another version, cls trick was useful to discover.
Another useful application of cls instruction was discovered to understand the final bit length of a variable integer where the first bit of each byte represents if there is a continuation of the value in the follow-up byte. To find the length, one can mark all bits from 1 to 7 for every byte as ones and do __clsll(__rbitll(value)): if the leading bit is 0, the result will be zero, if non-zero, it will be length * 8 - 1.
uint64_t varint = …; varint |= 0x7f7f7f7f7f7f7f7full; uint64_t num_leading_bits = __clsll(__rbitll(varint)); // +1 is not needed because num_leading_bits is off by 1. // Translates to "sub reg, reg, lsr 3". Returns 0 for 0, 7 for 1, 14 for 2, etc. uint64_t final_number_bits = num_leading_bits - (num_leading_bits >> 3);
32 and 64-bit movemasks
Arm NEON supports working mostly with 64-bit or 128-bit vectors. There are some exceptions - interleaved load. Instructions ld2`, `ld3` and `ld4` load 32, 48 and 64 bytes but in an interleaved way.
For example, intrinsic vld2q_u8 will load 32 bytes (enumerated from 0 to 31) into 2 vectors in the following way so that the even-indexed bytes end up in one vector and the odd-indexed bytes in the other:

But vld2q_u16 will do it with the 2-byte chunks as 16-bit shorts, where the even-indexed shorts end up in one vector and the odd indexed shorts end up in the other:

These instructions allow more flexibility when it comes to movemasks, as there are instructions called sri and sli which shift every byte and insert bits from another vector to the shifted bits. In the end, we can construct several versions of the 32-byte movemasks:
LD2 u8 interleaved: shift right and insert by 2 comparisons vectors, then duplicate to the upper 4 bits and get the 64-bit integer where the matching bit is duplicated 2 times.
const uint8x16x2_t chunk = vld2q_u8(src); const uint8x16_t dup = vdupq_n_u8(tag); const uint8x16_t cmp0 = vceqq_u8(chunk.val[0], dup); const uint8x16_t cmp1 = vceqq_u8(chunk.val[1], dup); const uint8x16_t t0 = vsriq_n_u8(cmp1, cmp0, 2); const uint8x16_t t1 = vsriq_n_u8(t0, t0, 4); const uint8x8_t t2 = vshrn_n_u16(vreinterpretq_u16_u8(t1), 4); return vget_lane_u64(vreinterpret_u64_u8(t2), 0); // Optional AND with 0xaaaaaaaaaaaaaaaa for iterations
LD2 u16 interleaved: shrn by 6 two vectors and combine them through sli:
const uint16x8x2_t chunk = vld2q_u16((const uint16_t*)(const void*)src); const uint8x16_t chunk0 = vreinterpretq_u8_u16(chunk.val[0]); const uint8x16_t chunk1 = vreinterpretq_u8_u16(chunk.val[1]); const uint8x16_t dup = vdupq_n_u8(tag); const uint8x16_t cmp0 = vceqq_u8(chunk0, dup); const uint8x16_t cmp1 = vceqq_u8(chunk1, dup); const uint8x8_t t0 = vshrn_n_u16(vreinterpretq_u16_u8(cmp0), 6); const uint8x8_t t1 = vshrn_n_u16(vreinterpretq_u16_u8(cmp1), 6); const uint8x8_t res = vsli_n_u8(t0, t1, 4); return vget_lane_u64(vreinterpret_u64_u8(res), 0); // Optional AND with 0xaaaaaaaaaaaaaaaa for iterations
For completeness, let’s add a pairwise version as previously discussed adding 2 more pairwise:
const uint8x16_t bitmask = { 0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80,
0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80};
const uint8x16_t dup = vdupq_n_u8(tag);
const uint8x16_t p0 = vceqq_u8(vld1q_u8(src), dup);
const uint8x16_t p1 = vceqq_u8(vld1q_u8(src + 16), dup);
uint8x16_t t0 = vandq_u8(p0, bitmask);
uint8x16_t t1 = vandq_u8(p1, bitmask);
uint8x16_t sum0 = vpaddq_u8(t0, t1);
sum0 = vpaddq_u8(sum0, sum0);
sum0 = vpaddq_u8(sum0, sum0);
return vgetq_lane_u32(vreinterpretq_u32_u8(sum0), 0);
On Neoverse N1, we got the following benchmark results:
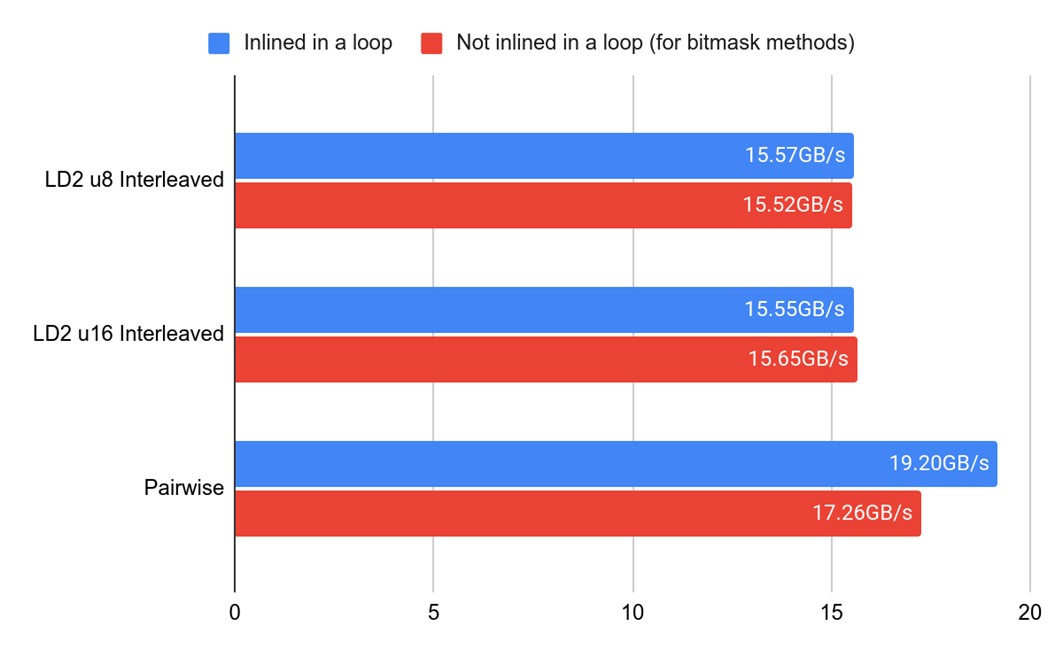
The blue line refers to throughput, and the red line to the inverse of latency as in a pairwise approach constant vector is loaded once before the loop.
It does not necessarily mean that the pairwise version is always faster because it requires some additional tables and more registers to achieve this throughput. However, we saw that one of two versions helped to achieve the best throughput: ZSTD uses LD2 u16 interleaved and the pairwise approach has not shown any improvements.
64-bit movemasks have similar versions but let’s have the implementations below for reference.
64-byte movemask: LD4 u8 interleaved:
const uint8x16x4_t chunk = vld4q_u8(src); const uint8x16_t dup = vdupq_n_u8(tag); const uint8x16_t cmp0 = vceqq_u8(chunk.val[0], dup); const uint8x16_t cmp1 = vceqq_u8(chunk.val[1], dup); const uint8x16_t cmp2 = vceqq_u8(chunk.val[2], dup); const uint8x16_t cmp3 = vceqq_u8(chunk.val[3], dup); const uint8x16_t t0 = vsriq_n_u8(cmp1, cmp0, 1); const uint8x16_t t1 = vsriq_n_u8(cmp3, cmp2, 1); const uint8x16_t t2 = vsriq_n_u8(t1, t0, 2); const uint8x16_t t3 = vsriq_n_u8(t2, t2, 4); const uint8x8_t t4 = vshrn_n_u16(vreinterpretq_u16_u8(t3), 4); return vget_lane_u64(vreinterpret_u64_u8(t4), 0);
64 byte movemask Pairwise:
const uint8x16_t bitmask = { 0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80,
0x01, 0x02, 0x4, 0x8, 0x10, 0x20, 0x40, 0x80};
const uint8x16_t dup = vdupq_n_u8(tag);
const uint8x16_t p0 = vceqq_u8(vld1q_u8(src), dup);
const uint8x16_t p1 = vceqq_u8(vld1q_u8(src + 16), dup);
const uint8x16_t p2 = vceqq_u8(vld1q_u8(src + 32), dup);
const uint8x16_t p3 = vceqq_u8(vld1q_u8(src + 48), dup);
uint8x16_t t0 = vandq_u8(p0, bitmask);
uint8x16_t t1 = vandq_u8(p1, bitmask);
uint8x16_t t2 = vandq_u8(p2, bitmask);
uint8x16_t t3 = vandq_u8(p3, bitmask);
uint8x16_t sum0 = vpaddq_u8(t0, t1);
uint8x16_t sum1 = vpaddq_u8(t2, t3);
sum0 = vpaddq_u8(sum0, sum1);
sum0 = vpaddq_u8(sum0, sum0);
return vgetq_lane_u64(vreinterpretq_u64_u8(sum0), 0);Same here: ZSTD uses “LD4 u8 interleaved” but SIMDJSON uses the “Pairwise” approach whereas there was no consistent winner across a set of benchmarks.
Conclusion
Arm NEON is different from x86 SSE in many ways and this article sheds light on how to translate popular x86 vector bitmask optimizations to Arm while retaining high performance. In the end, they resulted in significant savings across various major libraries.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK