

Spark-Radiant: Spark Performance, Cost Optimizer - DZone Big Data
source link: https://dzone.com/articles/spark-radiant-apache-spark-performance-and-cost-op
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Spark-Radiant: Apache Spark Performance and Cost Optimizer
In this article, learn how to boost performance, reduce cost and increase observability for Spark Application using Spark-Radiant.
Spark-Radiant is the Apache Spark Performance and Cost Optimizer. Spark-Radiant will help optimize performance and cost considering catalyst optimizer rules, enhance auto-scaling in Spark, collect important metrics related to a Spark job, Bloom filter index in Spark, etc.
Spark-Radiant is now available and ready to use. The dependency for Spark-Radiant 1.0.4 is available in Maven central. In this blog, I will discuss the availability of Spark-Radiant 1.0.4, and its features to boost performance, reduce cost, and the increase observability of the Spark Application. Please refer to the release notes docs for Spark-Radiant 1.0.4.
How To Use Spark-Radiant-1.0.4 With Spark Jobs
For Maven projects, use the below dependency in the pom.xml.
- spark-radiant-sql:
<dependency>
<groupId>io.github.saurabhchawla100</groupId>
<artifactId>spark-radiant-sql</artifactId>
<version>1.0.4</version>
</dependency><dependency>
<groupId>io.github.saurabhchawla100</groupId>
<artifactId>spark-radiant-core</artifactId>
<version>1.0.4</version>
</dependency>Prerequisites
- Spark-Radiant is supported with Spark-3.0.x and a newer version of Spark.
- Supported Scala version 2.12.x
- Scala, Pyspark, Java, and spark-sql support is available with Spark-Radiant-1.0.4.
Running Spark Job With Spark-Radiant
Use the published spark-radiant-sql-1.0.4.jar and spark-radiant-core-1.0.4.jar from Maven central at runtime while running the spark jobs.
./bin/spark-shell --packages "io.github.saurabhchawla100:spark-radiant-sql:1.0.4,io.github.saurabhchawla100:spark-radiant-core:1.0.4" ./bin/spark-submit --packages "io.github.saurabhchawla100:spark-radiant-sql:1.0.4,io.github.saurabhchawla100:spark-radiant-core:1.0.4" --class com.test.spark.examples.SparkTestDF /spark/examples/target/scala-2.12/jars/spark-test_2.12-3.2.0.jar
How To Use Performance Features of Spark-Radiant
Below are some of the features and improvements that are available with Spark-Radiant which will help to boost the performance, reduce the cost, and increase observability for the Spark Application.
Using Dynamic Filtering in Spark
Spark-Radiant Dynamic Filter works well for the join, which is a type of star schema where one table consists of a large number of records as compared to other tables. Dynamic Filtering works on runtime by using the predicates from the smaller table, filtering out the join columns, using those predicates' results on the bigger table, and filtering out the bigger table. This reduces the number of records on the bigger side of the join, resulting in a less expensive join, and also improved the performance of the Spark SQL queries. This works with inner, right outer, left semi, left outer, and left anti joins.
Performance Improvement Factors
- Improved Network Utilization: Dynamic filter reduces the number of records involved in the join operation and this helps in reducing the shuffle data generated and minimizes network I/O.
- Improved Resource Utilization: The number of records involved in the join is reduced as a result of using the Dynamic Filtering in Spark. This reduces the system resource requirements since the number of tasks spawned for the Join operation is reduced. This results in the completion of jobs with a lower number of resources.
- Improved Disk I/0: Push down the dynamic filter to the FileSourceScan/Datasource to read only the filter records. This will reduce the pressure on the Disk I/O.
./bin/spark-shell --packages "io.github.saurabhchawla100:spark-radiant-sql:1.0.4,io.github.saurabhchawla100:spark-radiant-core:1.0.4" --conf spark.sql.extensions=com.spark.radiant.sql.api.SparkRadiantSqlExtension
or
./bin/spark-submit --packages "io.github.saurabhchawla100:spark-radiant-sql:1.0.4,io.github.saurabhchawla100:spark-radiant-core:1.0.4" --class com.test.spark.examples.SparkTestDF /spark/examples/target/scala-2.12/jars/spark-test_2.12-3.1.1.jar
--conf spark.sql.extensions=com.spark.radiant.sql.api.SparkRadiantSqlExtension
Example
val df = spark.sql("select * from table, table1, table2 where table._1=table1._1 and table._1=table2._1
and table1._3 <= 'value019' and table2._3 = 'value015'")
df.show()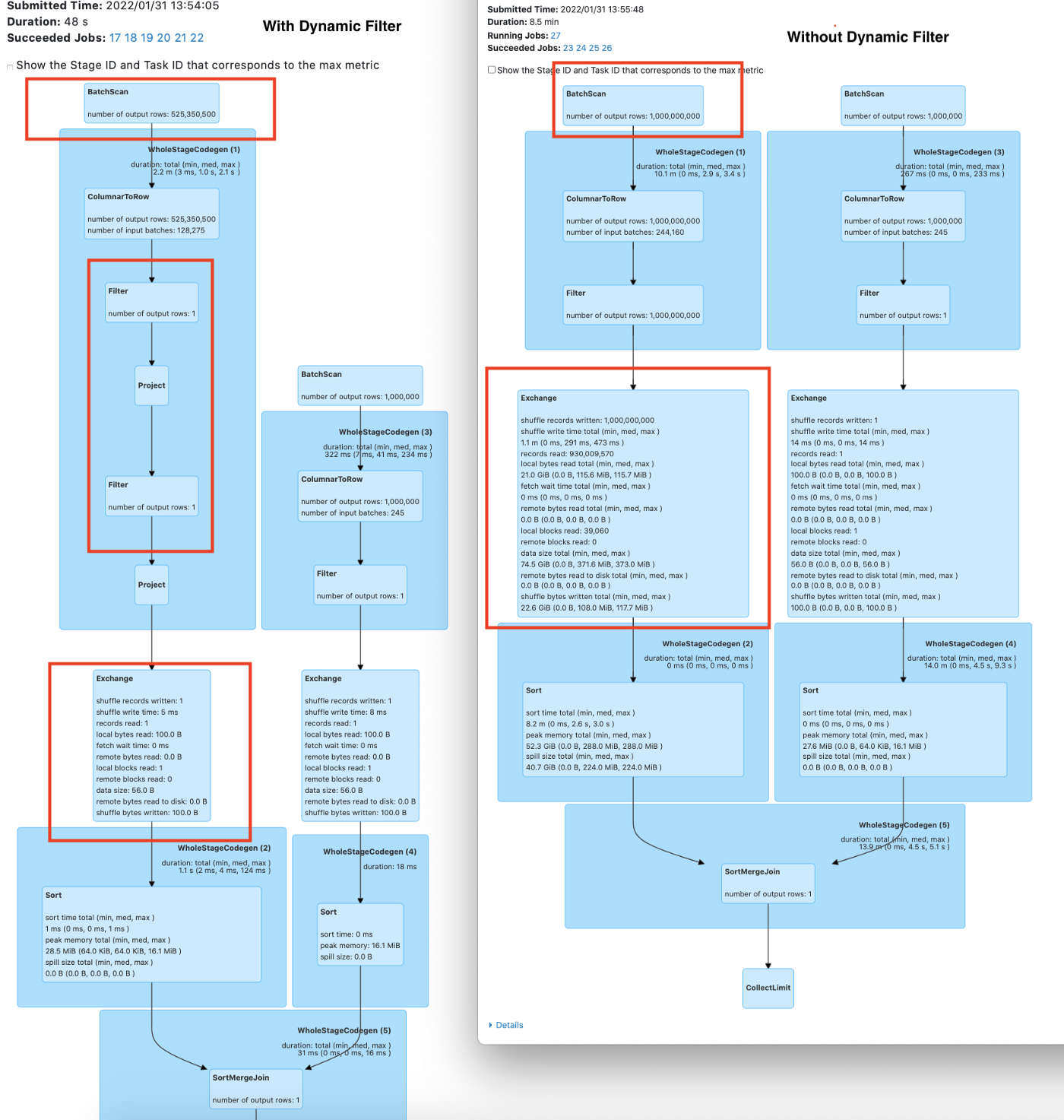
Dynamic Filtering in Spark SQL
It was found that using the Dynamic Filter on Spark join improved the performance 8X as compared to the query run with regular Spark join.
For more information, refer to the documentation.
Using Size-Based Join Reordering in Spark
Spark-Radiant size-based join reordering works well for the join. Spark by default performs join left to right (whether it's BHJ before the SMJ, or vice versa). This optimizer rule allows the smaller table to join first before the bigger table (BHJ first before the SMJ).
Size-based join reordering support is available in Scala, PySpark, Spark SQL, Java, and R using conf:
--conf spark.sql.extensions=com.spark.radiant.sql.api.SparkRadiantSqlExtension --conf spark.sql.support.sizebased.join.reorder=truePerformance Improvement Factors
- Improved Network Utilization: Size-based join reordering performs BHJ before SMJ, and hence, reduces the number of records involved in the join operation. This helps in reducing the shuffle data generated and minimizes Network I/O.
- Improved Resource Utilization: The number of records involved in the join is reduced as the result of using size-based join reordering in Spark. This reduces the system resource requirements since the number of tasks spawned for the join operation is reduced. This results in the completion of jobs with a lower number of resources.
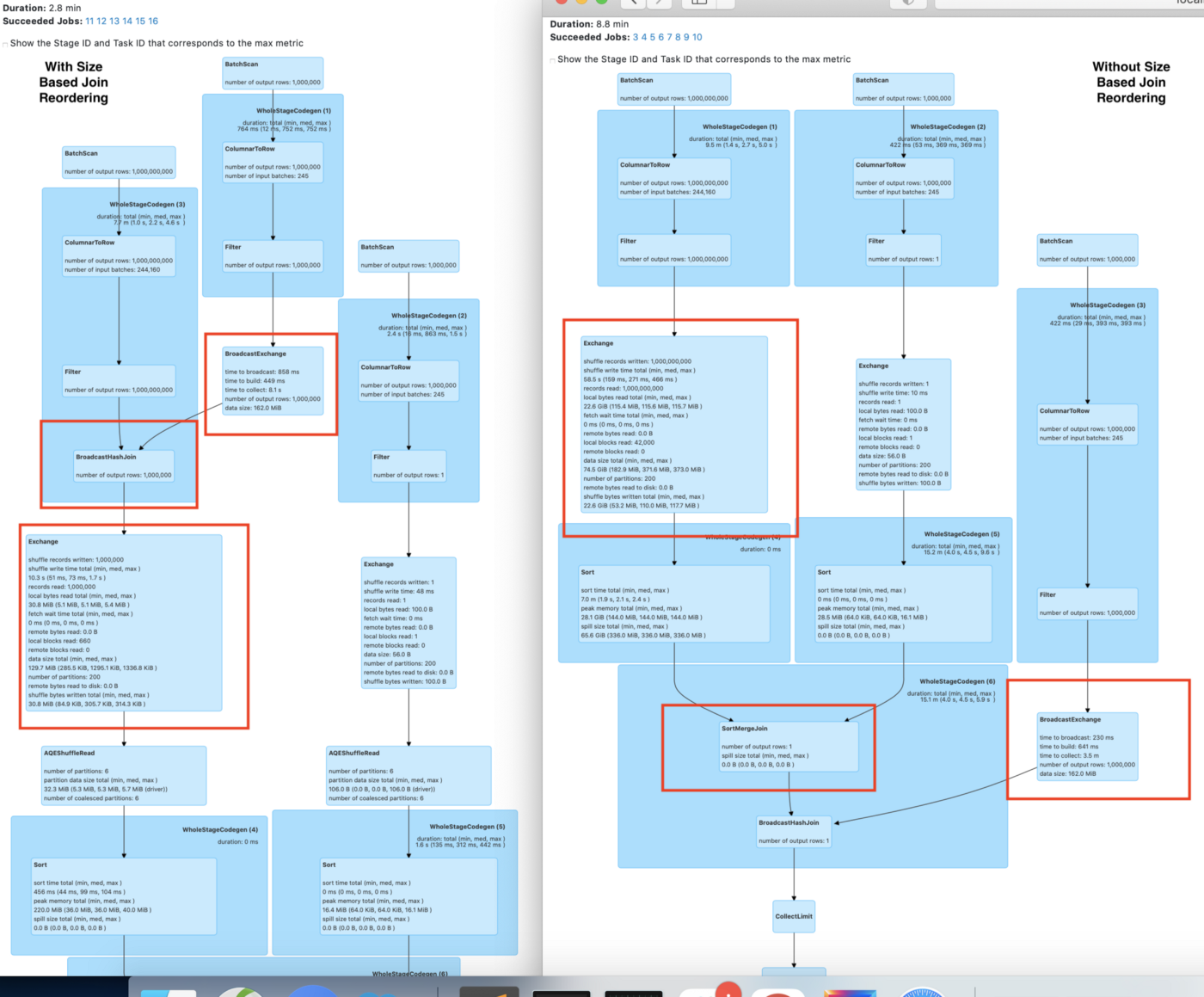
Size-based join reordering in Spark
SizeBasedJoinReOrdering join works 4X faster than the regular Spark Join for this query.
For more information refer to the spark-radiant Size based Join ReOrdering documentation.
UnionReuseExchangeOptimizeRule
This rule works for scenarios when a union is present with aggregation having the same grouping columns. The union is between the same table/data source. In this scenario, instead of scanning twice the table/data source, there will be one scan of the table/data source, and the other child of the union will reuse this scan. This feature is enabled using:
- conf spark.sql.optimize.union.reuse.exchange.rule=true
val df = spark.sql("select test11, count(*) as count from testDf1" +
" group by test11 union select test11, sum(test11) as count" +
" from testDf1 group by test11")
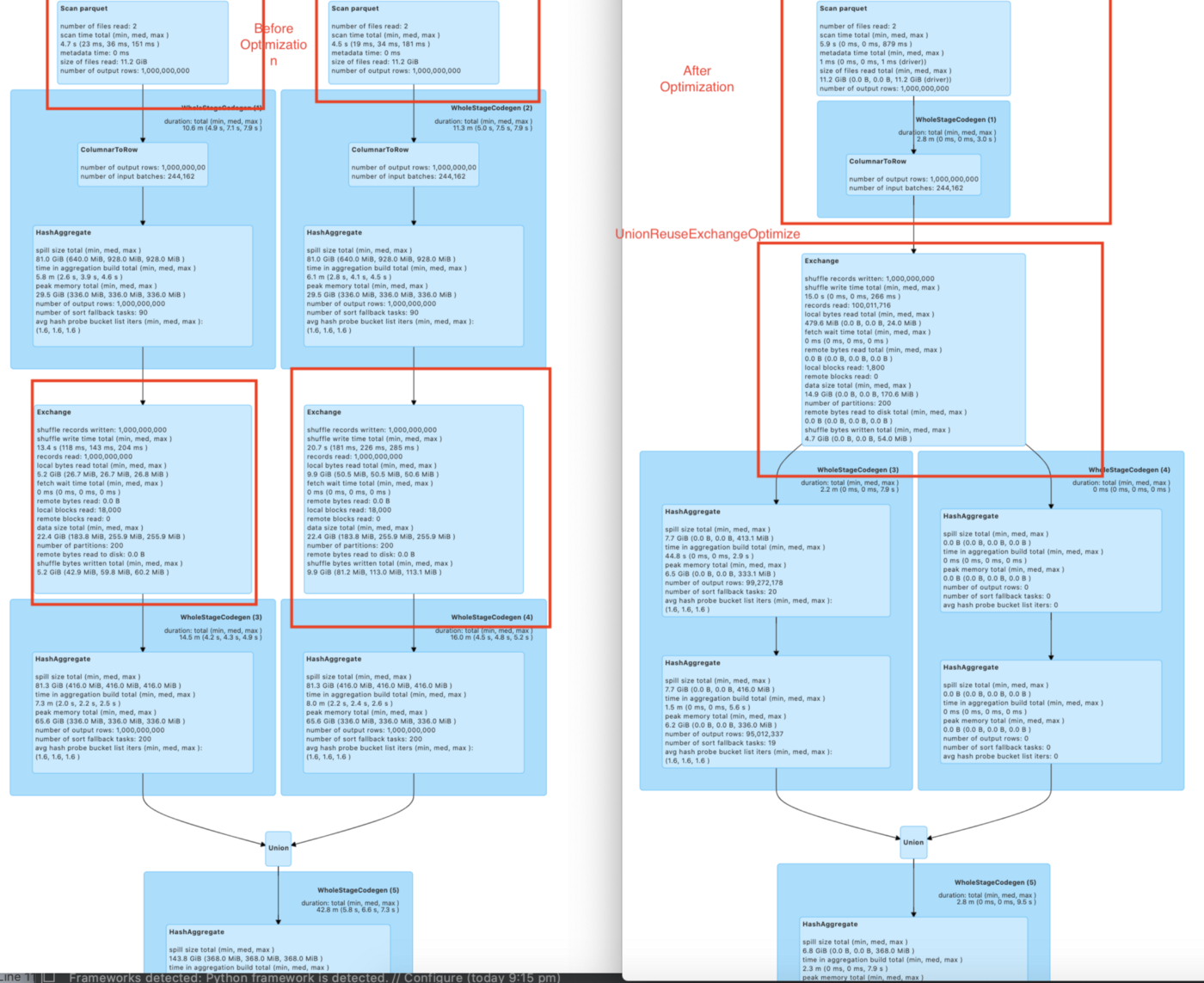
UnionReuseExchangeOptimizeRule in Spark-Radiant
Metrics Collector
This Metrics Collector is newly added as part of the spark-radiant-core module. This helps in getting the overall information about how the Spark Application performed in the various stages and tasks. This in turn helps in figuring out SLA/RCA in case of any performance degradation and failure in the Spark Application.
SparkJobMetricsCollector is used for collecting the important metrics to Spark Job metrics, Stage metrics, and Task Metrics(Task Failure info, Task skewness info). This is enabled by using the configuration --conf spark.extraListeners=com.spark.radiant.core.SparkJobMetricsCollector and providing the jars in the classpath using the following.
Steps To Run
./bin/spark-shell --conf spark.extraListeners=com.spark.radiant.core.SparkJobMetricsCollector --packages "io.github.saurabhchawla100:spark-radiant-sql:1.0.4,io.github.saurabhchawla100:spark-radiant-core:1.0.4"
Response of the Metrics Collector
Spark-Radiant Metrics Collector
Total Time taken by Application:: 895 sec
*****Driver Metrics*****
Time spend in the Driver: 307 sec
Percentage of time spend in the Driver: 34. Try adding more parallelism to the Spark job for Optimal Performance
*****Stage Info Metrics*****
***** Stage Info Metrics Stage Id:0 *****
{
"Stage Id": 0,
"Final Stage Status": succeeded,
"Number of Task": 10,
"Total Executors ran to complete all Task": 2,
"Stage Completion Time": 858 ms,
"Average Task Completion Time": 139 ms
"Number of Task Failed in this Stage": 0
"Few Skew task info in Stage": Skew task in not present in this stage
"Few Failed task info in Stage": Failed task in not present in this stage
}
***** Stage Info Metrics Stage Id:1 *****
{
"Stage Id": 1,
"Final Stage Status": succeeded,
"Number of Task": 10,
"Total Executors ran to complete all Task": 2,
"Stage Completion Time": 53 ms,
"Average Task Completion Time": 9 ms
"Number of Task Failed in this Stage": 0
"Few Skew task info in Stage": Skew task in not present in this stage
"Few Failed task info in Stage": Failed task in not present in this stage
}
Skew Task Info in the Metrics Collector
In this case, skewed tasks are present in this stage. The metrics collector will show the skew task info.
***** Stage Info Metrics Stage Id:2 *****
{
"Stage Id": 2,
"Final Stage Status": succeeded,
"Number of Task": 100,
"Total Executors ran to complete all Task": 4,
"Stage Completion Time": 11206 ms,
"Average Task Completion Time": 221 ms
"Number of Task Failed in this Stage": 0
"Few Skew task info in Stage": List({
"Task Id": 0,
"Executor Id": 3,
"Number of records read": 11887,
"Number of shuffle read Record": 11887,
"Number of records write": 0,
"Number of shuffle write Record": 0,
"Task Completion Time": 10656 ms
"Final Status of task": SUCCESS
"Failure Reason for task": NA
}, {
"Task Id": 4,
"Executor Id": 1,
"Number of records read": 11847,
"Number of shuffle read Record": 11847,
"Number of records write": 0,
"Number of shuffle write Record": 0,
"Task Completion Time": 10013 ms
"Final Status of task": SUCCESS
"Failure Reason for task": NA
})
"Few Failed task info in Stage": Failed task in not present in this stage
}
Failed Task Info in the Metrics Collector
In case the failed task is present in this stage, the metrics collector will show the failed task info.
***** Stage Info Metrics Stage Id:3 *****
{
"Stage Id": 3,
"Final Stage Status": failed,
"Number of Task": 10,
"Total Executors ran to complete all Task": 2,
"Stage Completion Time": 53 ms,
"Average Task Completion Time": 9 ms
"Number of Task Failed in this Stage": 1
"Few Skew task info in Stage": Skew task in not present in this stage
"Few Failed task info in Stage": List({
"Task Id": 12,
"Executor Id": 1,
"Number of records read in task": 0,
"Number of shuffle read Record in task": 0,
"Number of records write in task": 0,
"Number of shuffle write Record in task": 0,
"Final Status of task": FAILED,
"Task Completion Time": 7 ms,
"Failure Reason for task": java.lang.Exception: Retry Task
at $line14.$read$$iw$$iw$$iw$$iw$$iw$$iw$$iw$$iw.$anonfun$res0$1(<console>:33)
at scala.runtime.java8.JFunction1$mcII$sp.apply(JFunction1$mcII$sp.java:23)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:461)
at scala.collection.Iterator$$anon$10.next(Iterator.scala:461)
})
}
Support for Struct Type Column in the DropDuplicate:
From now on, in using the struct col in the DropDuplicate, we will get the below exception.
case class StructDropDup(c1: Int, c2: Int)
val df = Seq(("d1", StructDropDup(1, 2)),
("d1", StructDropDup(1, 2))).toDF("a", "b")
df.dropDuplicates("a", "b.c1")
org.apache.spark.sql.AnalysisException: Cannot resolve column name "b.c1" among (a, b) at org.apache.spark.sql.Dataset.$anonfun$dropDuplicates$1(Dataset.scala:2576) at scala.collection.TraversableLike.$anonfun$flatMap$1(TraversableLike.scala:245) at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
Add the support to use the struct col in the DropDuplicate:
import com.spark.radiant.sql.api.SparkRadiantSqlApi
case class StructDropDup(c1: Int, c2: Int)
val df = Seq(("d1", StructDropDup(1, 2)),
("d1", StructDropDup(1, 2))).toDF("a", "b")
val sparkRadiantSqlApi = new SparkRadiantSqlApi()
val updatedDF = sparkRadiantSqlApi.dropDuplicateOfSpark(df, spark, Seq("a", "b.c1"))
updatedDF.show
+---+------+
| a| b|
+---+------+
| d1|{1, 2}|
+---+------+
The same support is added in this PR in Apache Spark [SPARK-37596][Spark-SQL]. Add the support for struct type column in the DropDuplicate.
This works well for the map type column in the dropDuplicate.
val df = spark.createDataFrame(Seq(("d1", Map(1 -> 2)), ("d1", Map(1 -> 2))))val updatedDF = sparkRadiantSqlApi.dropDuplicateOfSpark(df, spark, Seq("_2.1"))updatedDF.show
+---+--------+
| _1| _2|
+---+--------+
| d1|{1 -> 2}|
+---+--------+
Conclusion
In this blog, I discussed how to use Spark-Radiant. The new features added to the Spark-Radiant such as Metrics Collector, Drop duplicate for struct Type, Dynamic filter SizeBasedJoinReOrdering, and UnionReUseExchange will provide benefits related to performance and cost optimization.
In the near future, we will come up with new related blogs. Keep watching this space for more!
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK