

前缀树算法模板秒杀五道算法题
source link: https://labuladong.github.io/algo/2/21/58/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
前缀树算法模板秒杀五道算法题

通知: 持续更新中, 开始报名, 开始预约。
读完本文,你不仅学会了算法套路,还可以顺便解决如下题目:
| 牛客 | LeetCode | 力扣 | 难度 |
|---|---|---|---|
| - |
🔒 |
🔒 |
🟠 |
| - | 🟠 | ||
| - | 🟠 | ||
| - | 🟠 | ||
| - | 🟠 | ||
| - | - | 🟠 | |
| - | - | 🟠 | |
| - | - | 🟠 |
———–
Trie 树又叫字典树、前缀树、单词查找树,是一种二叉树衍生出来的高级数据结构,主要应用场景是处理字符串前缀相关的操作。
我是在《算法 4》第一次学到这种数据结构,不过书中的讲解不是特别通俗易懂,所以本文按照我的逻辑帮大家重新梳理一遍 Trie 树的原理,并基于《算法 4》的代码实现一套更通用易懂的代码模板,用于处理力扣上一系列字符串前缀问题。
阅读本文之前希望你读过我旧文讲过的
和
。
本文主要分三部分:
1、讲解 Trie 树的工作原理。
2、给出一套 TrieMap 和 TrieSet 的代码模板,实现几个常用 API。
3、实践环节,直接套代码模板秒杀 5 道算法题。本来可以秒杀七八道题,篇幅考虑,剩下的我集成到
中。
关于 Map 和 Set,是两个抽象数据结构(接口),Map 存储一个键值对集合,其中键不重复,Set 存储一个不重复的元素集合。
常见的 Map 和 Set 的底层实现原理有哈希表和二叉搜索树两种,比如 Java 的 HashMap/HashSet 和 C++ 的 unorderd_map/unordered_set 底层就是用哈希表实现,而 Java 的 TreeMap/TreeSet 和 C++ 的 map/set 底层使用红黑树这种自平衡 BST 实现的。
而本文实现的 TrieSet/TrieMap 底层则用 Trie 树这种结构来实现。
了解数据结构的读者应该知道,本质上 Set 可以视为一种特殊的 Map,Set 其实就是 Map 中的键。
所以本文先实现 TrieMap,然后在 TrieMap 的基础上封装出 TrieSet。
PS:为了模板通用性的考虑,后文会用到 Java 的泛型,也就是用尖括号
<>指定的类型变量。这些类型变量的作用是指定我们实现的容器中存储的数据类型,类比 Java 标准库的那些容器的用法应该不难理解。
前文
说过,各种乱七八糟的结构都是为了在「特定场景」下尽可能高效地进行增删查改。
你比如 HashMap<K, V> 的优势是能够在 O(1) 时间通过键查找对应的值,但要求键的类型 K 必须是「可哈希」的;而 TreeMap<K, V> 的特点是方便根据键的大小进行操作,但要求键的类型 K 必须是「可比较」的。
本文要实现的 TrieMap 也是类似的,由于 Trie 树原理,我们要求 TrieMap<V> 的键必须是字符串类型,值的类型 V 可以随意。
接下来我们了解一下 Trie 树的原理,看看为什么这种数据结构能够高效操作字符串。
Trie 树原理
Trie 树本质上就是一棵从二叉树衍生出来的多叉树。
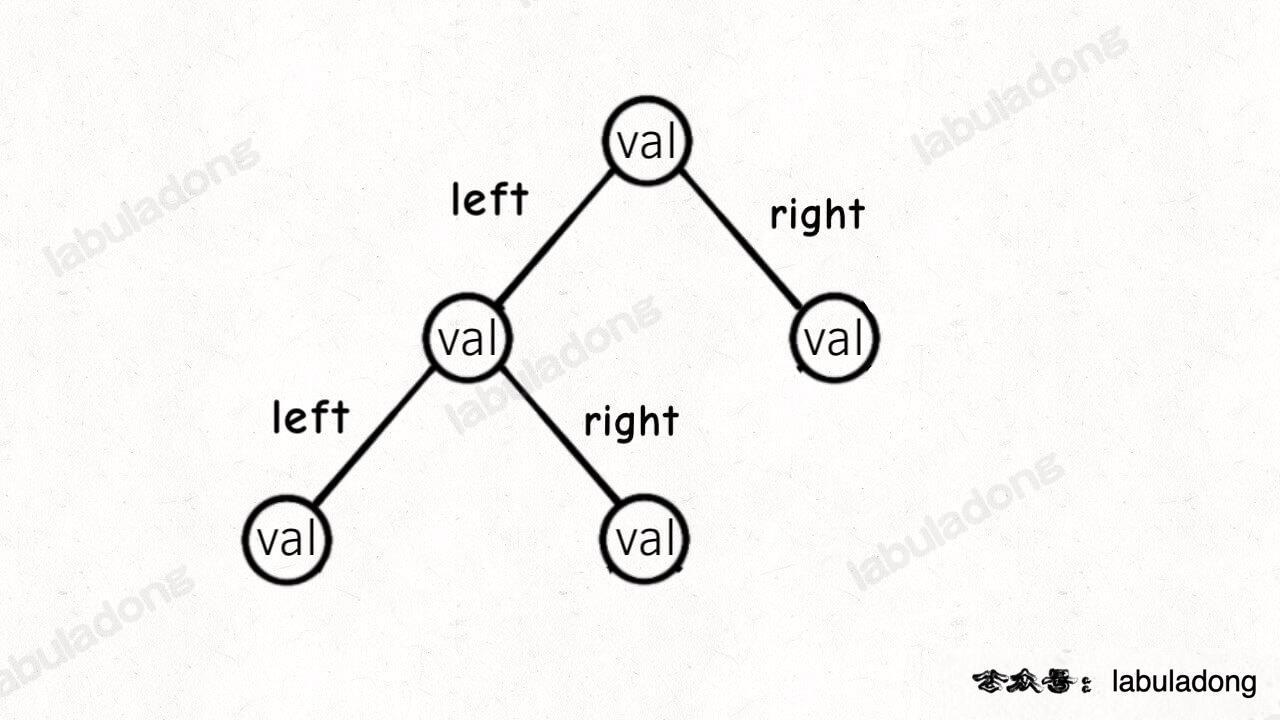
二叉树节点的代码实现是这样:
/* 基本的二叉树节点 */
class TreeNode {
int val;
TreeNode left, right;
}
其中 left, right 存储左右子节点的指针,所以二叉树的结构是这样:
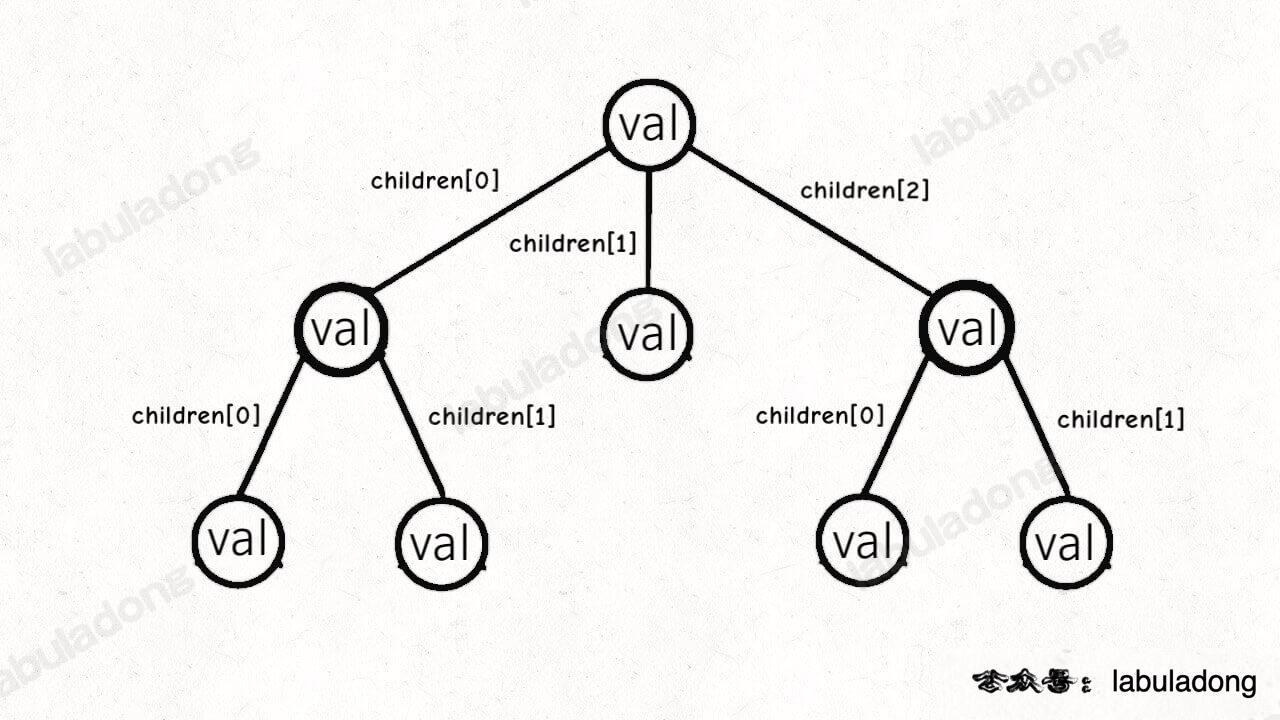
多叉树节点的代码实现是这样:
/* 基本的多叉树节点 */
class TreeNode {
int val;
TreeNode[] children;
}
其中 children 数组中存储指向孩子节点的指针,所以多叉树的结构是这样:
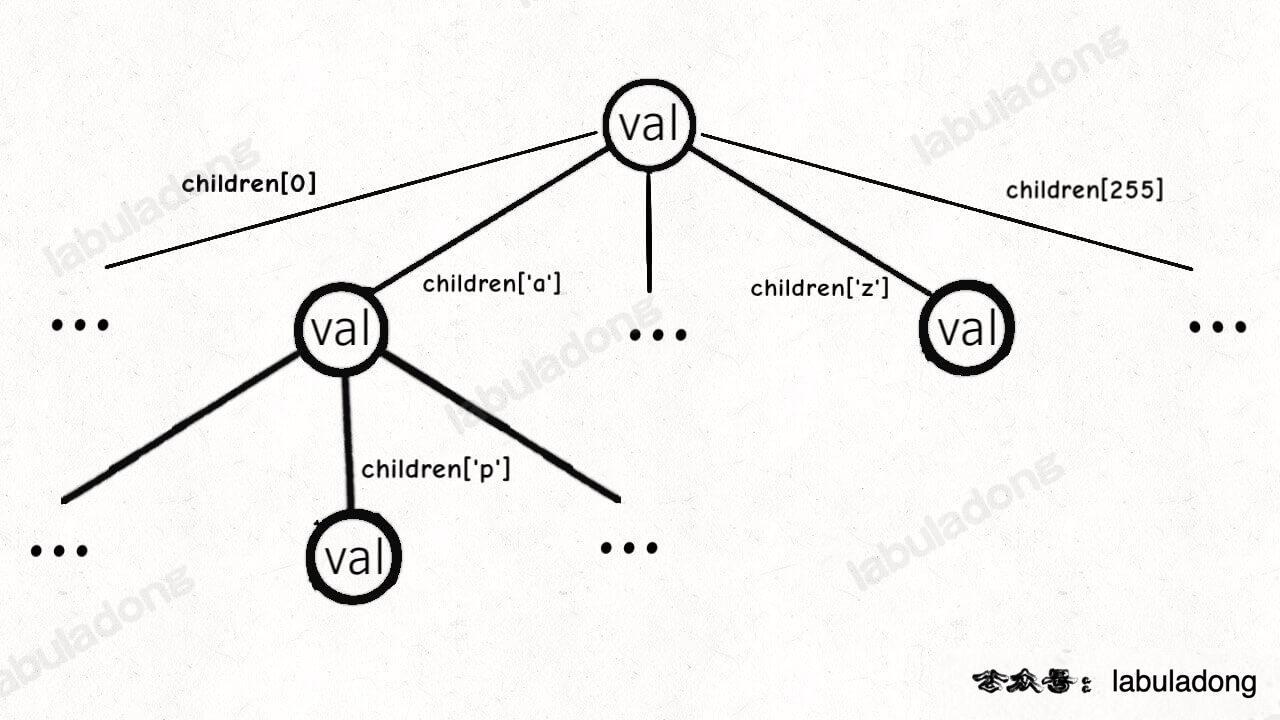
而 TrieMap 中的树节点 TrieNode 的代码实现是这样:
/* Trie 树节点实现 */
class TrieNode<V> {
V val = null;
TrieNode<V>[] children = new TrieNode[256];
}
这个 val 字段存储键对应的值,children 数组存储指向子节点的指针。
但是和之前的普通多叉树节点不同,TrieNode 中 children 数组的索引是有意义的,代表键中的一个字符。
比如说 children[97] 如果非空,说明这里存储了一个字符 'a',因为 'a' 的 ASCII 码为 97。
我们的模板只考虑处理 ASCII 字符,所以 children 数组的大小设置为 256。不过这个可以根据具体问题修改,比如改成更小的数组或者 HashMap<Character, TrieNode> 都是一样的效果。
有了以上铺垫,Trie 树的结构是这样的:
一个节点有 256 个子节点指针,但大多数时候都是空的,可以省略掉不画,所以一般你看到的 Trie 树长这样:
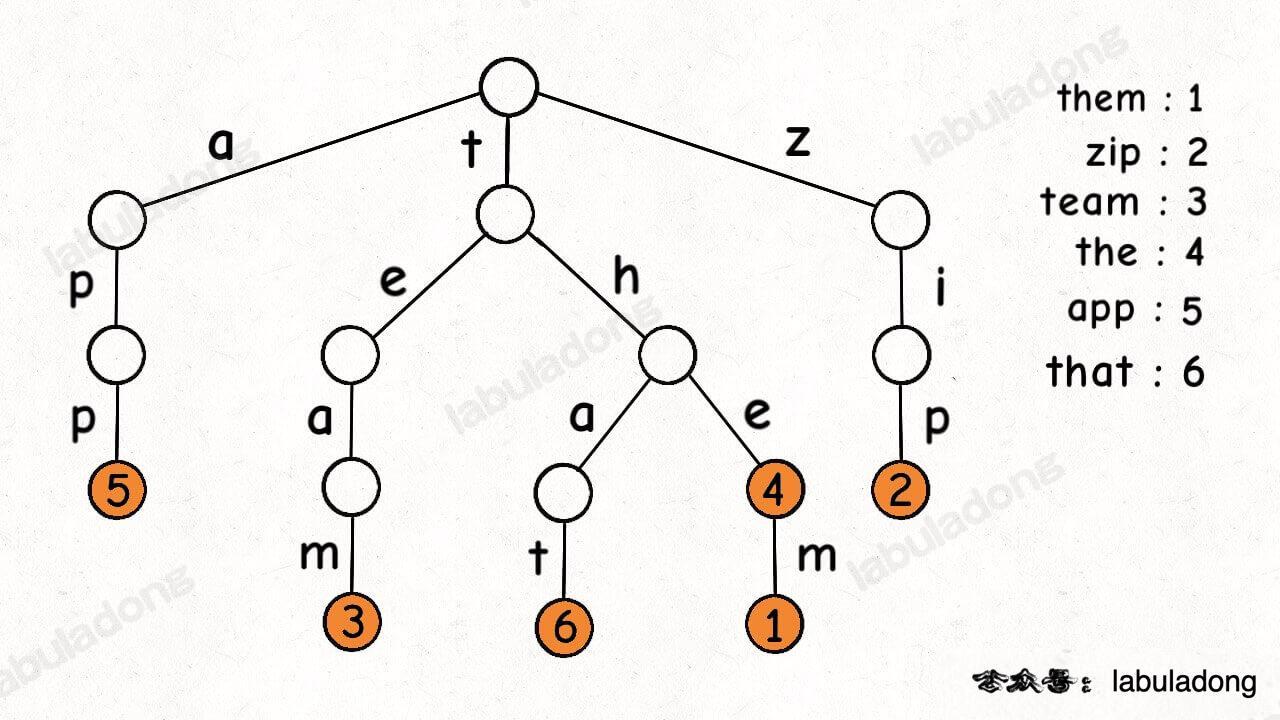
这是在 TrieMap<Integer> 中插入一些键值对后的样子,白色节点代表 val 字段为空,橙色节点代表 val 字段非空。
这里要特别注意,TrieNode 节点本身只存储 val 字段,并没有一个字段来存储字符,字符是通过子节点在父节点的 children 数组中的索引确定的。
形象理解就是,Trie 树用「树枝」存储字符串(键),用「节点」存储字符串(键)对应的数据(值)。所以我在图中把字符标在树枝,键对应的值 val 标在节点上:
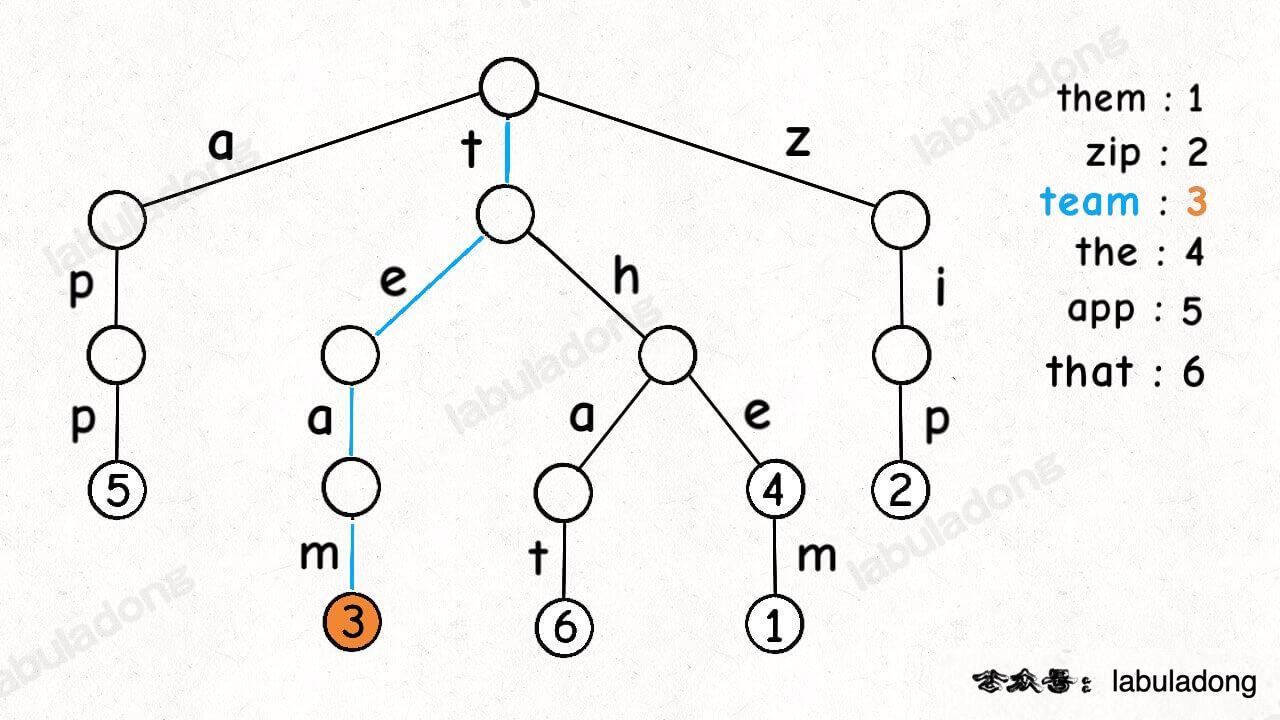
明白这一点很重要,有助于之后你理解代码实现。
PS:《算法 4》以及网上讲 Trie 树的文章中都是把字符标在节点上,我认为这样很容易让初学者产生误解,所以建议大家按照我的这种理解来记忆 Trie 树结构。
现在你应该知道为啥 Trie 树也叫前缀树了,因为其中的字符串共享前缀,相同前缀的字符串集中在 Trie 树中的一个子树上,给字符串的处理带来很大的便利。
TrieMap/TrieSet API 及实现
_____________
应合作方要求,本文不便在此发布,请扫码关注回复关键词「trie」或
查看:

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK