

Inside JavaScript Engines, Part 1: Parsing
source link: https://medium.com/@yanguly/inside-javascript-engines-part-1-parsing-c519d75833d7
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Inside JavaScript Engines, Part 1: Parsing
JavaScript is getting very popular now. “Write once, run everywhere” — it’s about JavaScript (not only Java)! But what is behind this “Run everywhere”? V8, SpiderMonkey, JavaScript core, and more and more engines. A good example of “Run everywhere” was Nashorn and Rhino, but have you ever heard about these engines, based on Java Virtual Machine?
Let’s take a closer look at JavaScript engines and how they work.
Part 1: Parsing

There are 3 major JavaScript engines left after long and exhausting browser wars.
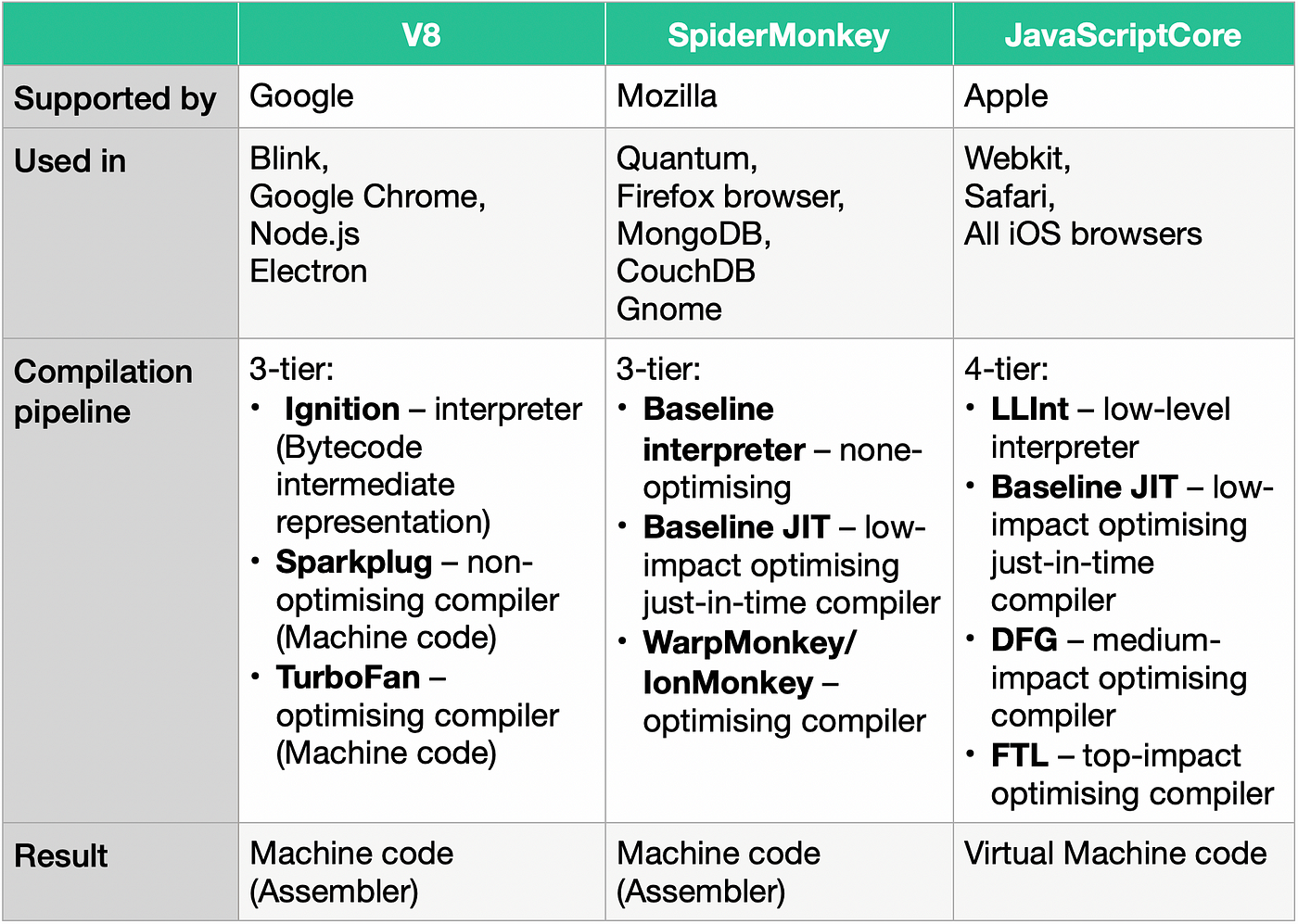
One of them is V8, backed by Google. It is used in Chrome and the Node.js environment. It supports modern EcmaScript, has a quite new baseline compiler for faster JavaScript start (Sparkplug), does garbage collection, supports WebAssembly, and does a wide range of code optimizations. The compilation pipeline of V8 has 3 compilers (later there will be one more low-impact TurboProp): Ignition (V8’s interpreter, from the parser to bytecode), Sparkplug (non-optimizing compiler from bytecode to machine code), and TurboFan (optimizing compiler from bytecode to machine code, that does deoptimizations directly to Sparkplug now).
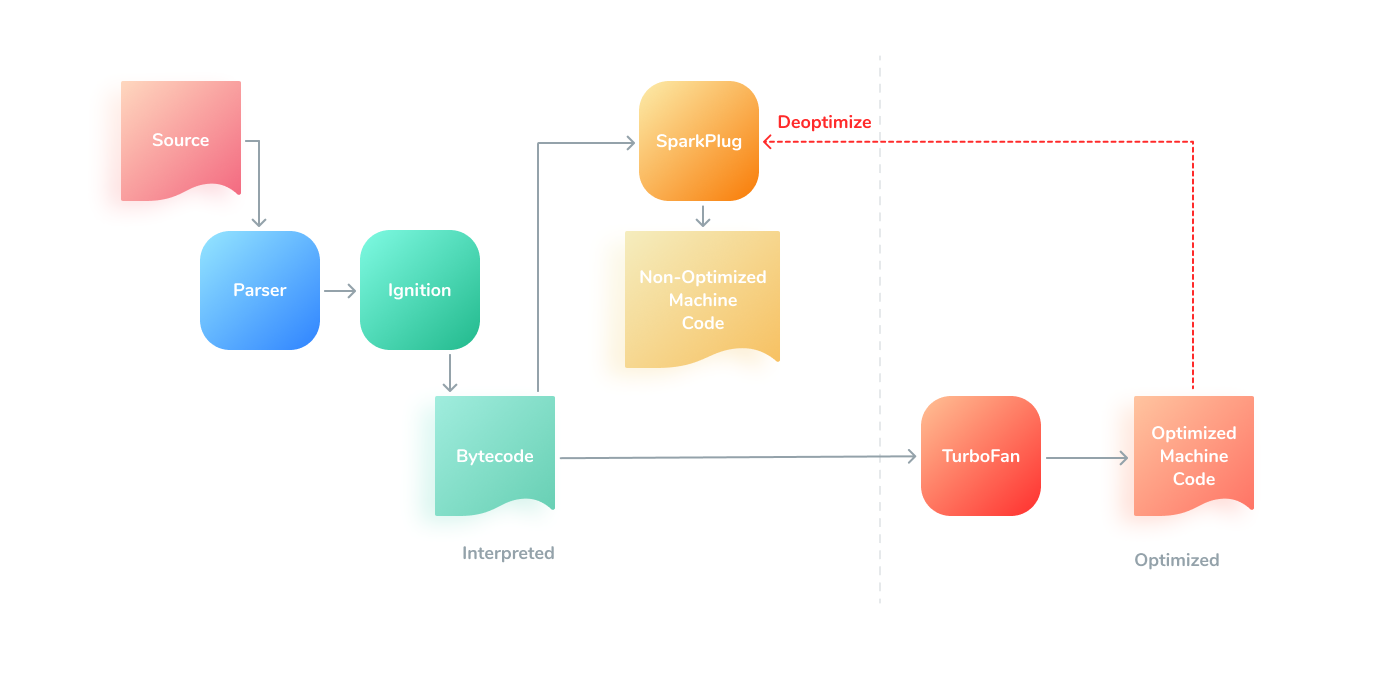
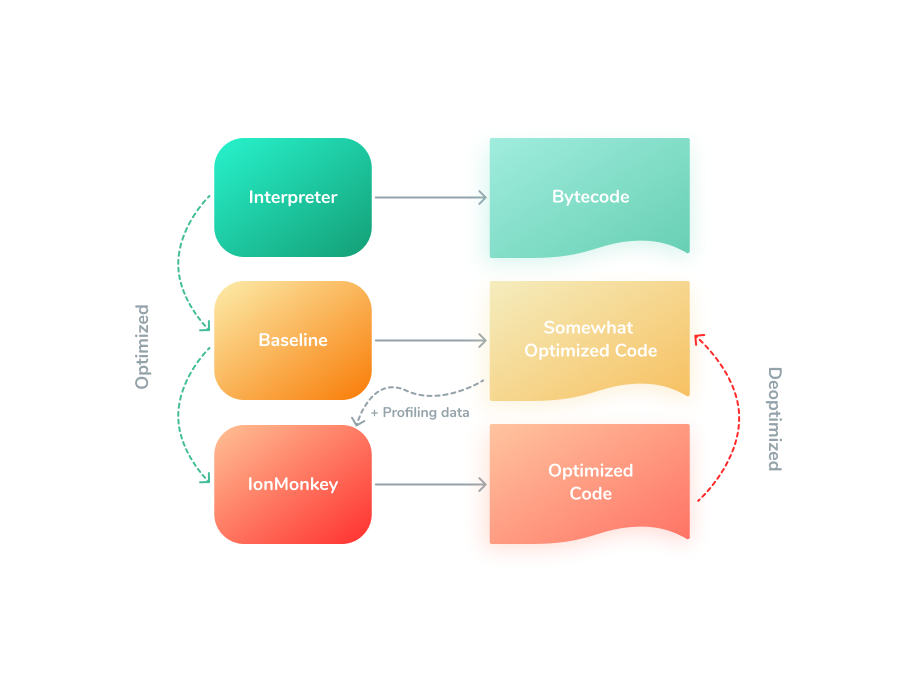
The second one is SpiderMonkey, backed by Firefox. It is used in Mozilla Firefox, MongoDB, CouchDB, and Gnome (yes, that was even before V8 existence). This JavaScript engine has a nice pipeline, that allows this engine to start JavaScript fastly. It has a fast Baseline interpreter with a compilator, that can produce non-optimized code, and, while it is running, the optimizing compiler can do its own job optimizing hot spots. Also, it has a garbage collector and can work with WebAssembly.
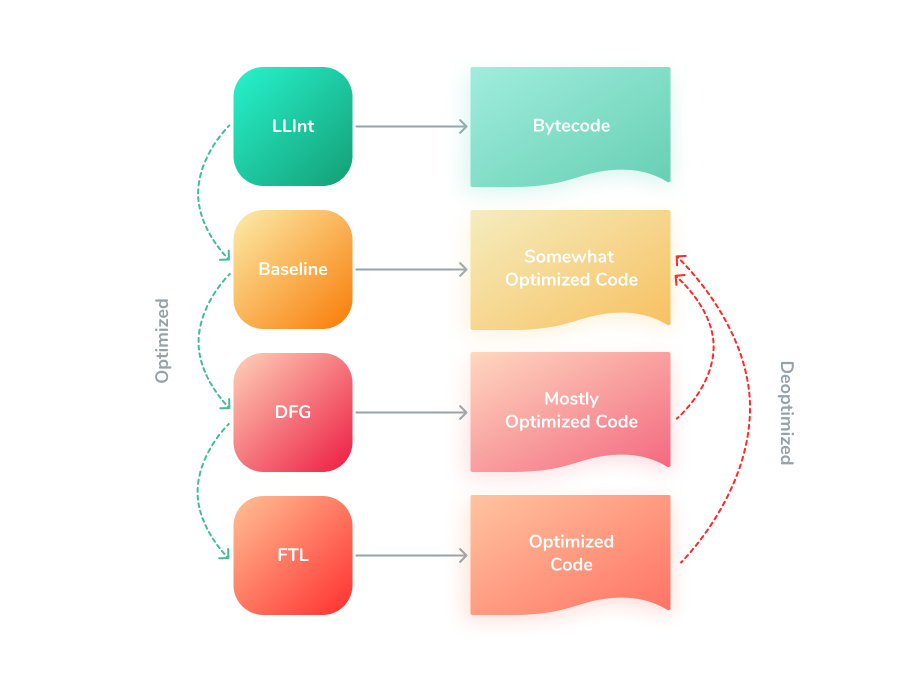
The third one is JavaScriptCore (JSC), the built-in JavaScript engine for Webkit. As a good example, it is used in Safari and in all iOS browsers. Latest versions of JSC support EcmaScript 2021. It is an optimizing virtual machine, that has multiple building blocks: lexer, parser, start-up interpreter (LLInt), baseline JIT, a low-latency optimizing JIT (DFG), and a high-throughput optimizing JIT (FTL). So, it has a 4-tier compilation. Probably, V8 will have it later with the introduction of the TurboProp low-latency optimizing compiler. Also, it has garbage collection.
Honorable mentions:
Hermes engine, used in React Native. It is built for optimizing React Native features, low memory usage, provides ahead-of-time static optimization, and compact bytecode.
JerryScript engine, super lightweight, used for Internet of Things. It can work on devices with a low amount of RAM and it weighs less than 200 KB.
What is a compiler? What is an interpreter? Theoretical part
A compiler is a computer program that transforms the code from one programming language (like Python, Java, JavaScript, etc.) to another (e.g. low-level machine instructions, or VM code). There are several types of compilers. For example, transpiler, which transforms the code from a high-level language to another high-level language. TSC, TypeScript transpiler, is a good example of it. It compiles TypeScript code to JavaScript.
The main difference between compiler and interpreter is that the interpreter goes through the code line-by-line and executes it, whereas the compiler prepares code for execution at first.
There is one thing in between. It’s a Just-In-Time (JIT)compiler, which is extremely popular in engines of dynamic languages like JavaScript.
To be effective, the JIT compiler should get profiling information to know how aggressively it needs to optimize code.
“JIT Compilation”, Wikipedia:
In computing, just-in-time (JIT) compilation (also dynamic translation or run-time compilations) is a way of executing computer code that involves compilation during execution of a program (at run time) rather than before execution.
JIT compilation is a combination of the two traditional approaches to translation to machine code —ahead-of-time compilation (AOT), and interpretation — and combines some advantages and drawbacks of both. Roughly, JIT compilation combines the speed of compiled code with the flexibility of interpretation, with the overhead of an interpreter and the additional overhead of compiling and linking (not just interpreting). JIT compilation is a form of dynamic compilation, and allows adaptive optimization such as dynamic recompilation and microarchitecture-specific speedups.
The traditional compiler has 2 different steps:
- Analysis Step
- Synthesis Step
Let’s take a closer look at the Analysis step:
The intermediate representation is created after this step. In our case, it is the Abstract Syntax Tree.
And it has some phases:
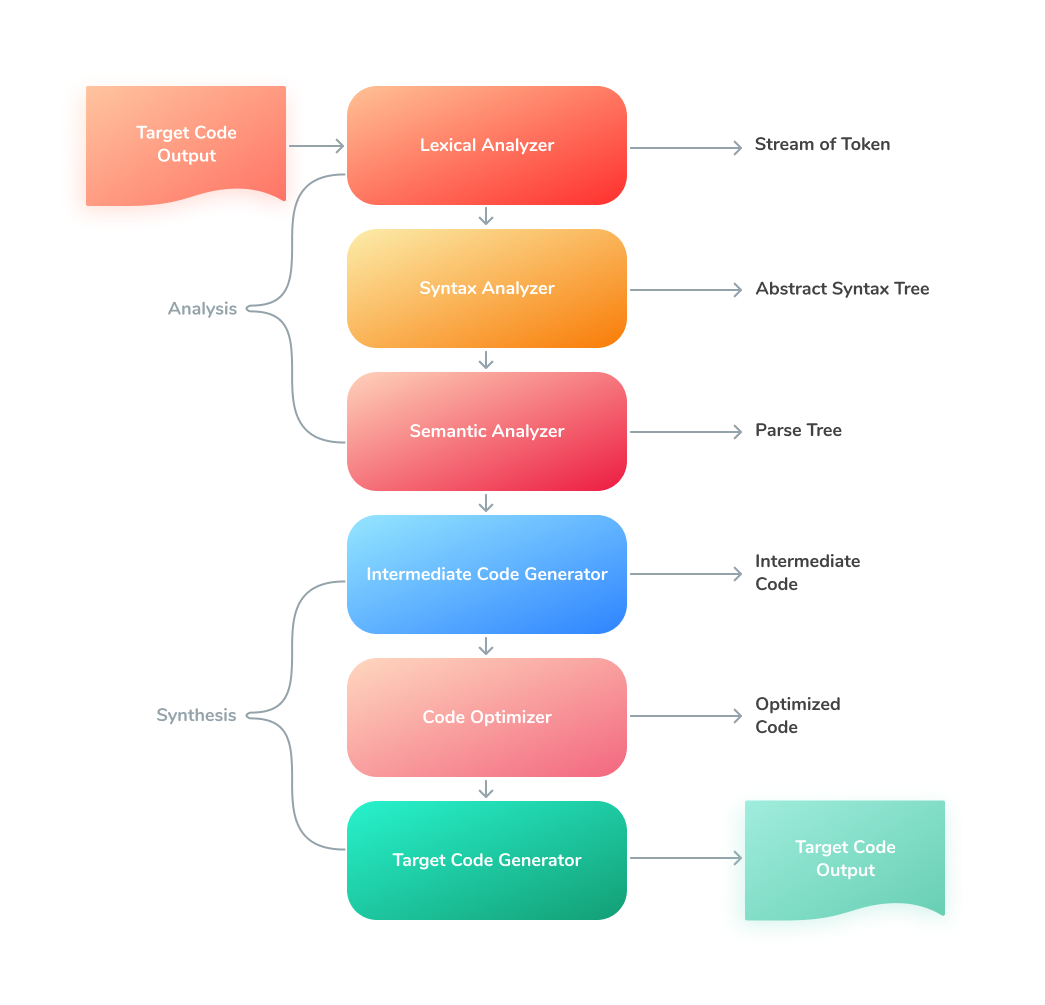
- Lexical Analyzer
Also called the scanner. It takes chars from the source code and groups them into lexemes, which correspond to tokens. It also removes comments and white spaces. Usually, it takes the output of the preprocessor (which performs file inclusion and macro expansion).
Nice Lexical Analyzer article. - Syntax Analyzer
Also called parser.It constructs the parse tree (or syntax tree). - Semantic Analyzer
It checks the parse tree, verifies it, and produces a verified parse tree. It also does different checks like type checking, control flow checking, and label checking.
The synthesis step usually ends with a result program. Something low-level, that can be run. And it has 3 parts:
- Intermediate code generator
Generates an intermediate code that can be translated into the machine code. Intermediate representation can be in various forms such as three-address code (3AC, TAC, language-independent) and byte code.
Three-address code — intermediate code, used by optimizing compilers.
It’s a high-level assembly where each operation has at most three operands. More here: Three-address code, Wikipedia.
Bytecode —intermediate representation for virtual machines or compilers. It’s a compact numeric code (usually human-unreadable), constants, and references. Bytecode is processed by the software, not hardware. More here: Bytecode, Wikipedia - Code optimizer
Makes potential target code faster, and more effective. - Code generator
Produces target code, that can be run on a specific machine.
A closer look at JavaScript Analysis step by the example of Chrome’s V8
What do we need to do to execute JavaScript?
“Blazingly fast parsing, part 1: optimizing the scanner, V8 blog”:
To run a JavaScript program, the source text needs to be processed so V8 can understand it. V8 starts out by parsing the source into an abstract syntax tree (AST), a set of objects that represent the program structure. That AST gets compiled to bytecode by Ignition.
Generally speaking, executing JavaScript requires the following steps:
- Parse the code to generate AST (Abstract Syntax Tree)
- Compile the parsed code (usually done by a baseline and an optimizing compiler)
The first step in executing JavaScript code is parsing the code, the parser generates data structures: AST, and Scope.
- Abstract Syntax Tree (AST) is a tree representation of the syntactic structure of the JavaScript code.
- The Scope is another data structure that maintains variable proxies which help manage the scope and reference of variables within functions. Parsing directly affects the JavaScript start-up performance.
As I mentioned before in my theoretical part about compilation, parsing involves two steps: lexical analysis and syntax analysis.
The lexical analysis involves reading a stream of characters from the code and combining them into tokens, it also involves the removal of white space characters, comments, etc. In the end, the entire string of code will be split into a list of tokens.
Syntax analyzer, also called parser, will take a plain list of tokens after lexical analysis and turn it into a tree representation, and also validates the language syntax.
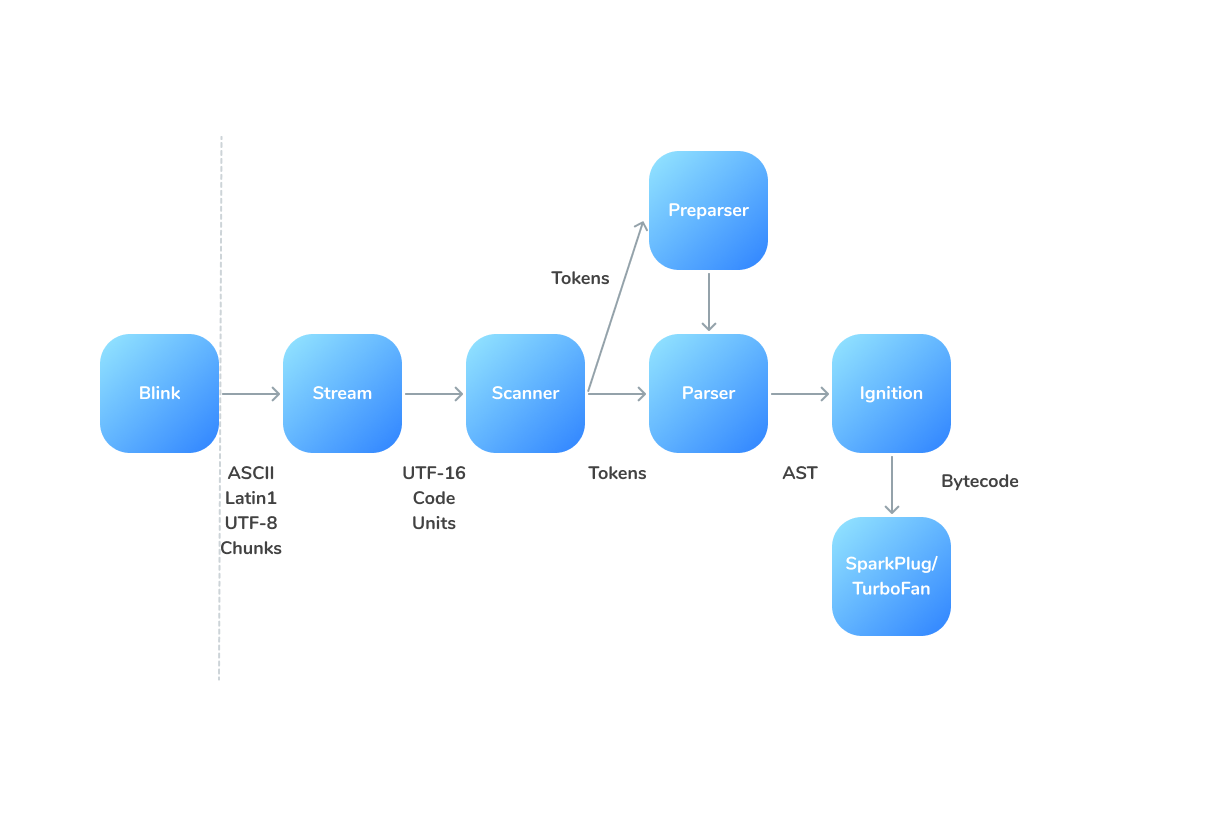
V8’s parser consumes tokens provided by the scanner. Tokens are blocks of one or more characters that have a single semantic meaning: a string, an identifier, an operator like ++. The scanner constructs these tokens by combining consecutive characters in an underlying character stream.
The Scanner consumes a stream of Unicode characters. These characters are always decoded from a stream of UTF-16 code characters. Only a single encoding is supported to avoid different versions of parser and scanner to work with multiple encodings.
“Blazingly fast parsing, part 1: optimizing the scanner, V8blog”:
Tokens can be separated by various types of whitespace, e.g., newline, space, tab, single-line comments, multiline comments, etc. One type of whitespace can be followed by other types of whitespace. Whitespace adds meaning if it causes a line break between two tokens: that possibly results in automatic semicolon insertion.
V8’s Scanner effectively works with whitespaces and adds semicolons. But don’t forget to minify your production code and always add semicolons if it’s needed!
The most complicated, but also most common token, is the identifier token, which is used for variable names in JavaScript.
Most JavaScript source code is written using ASCII. Only a-z, A-Z, $ and _ are ID_Start characters. ID_Continue additionally includes 0-9. It means that JavaScript variable name starts from a-z, A-Z, $ and _ , and it can have 0-9 symbols later.
const someVariable1 = 'example1';
const some_variable$ = 'example2';
Using shorter identifiers is beneficial for the parse performance of your application: the scanner is able to scan more tokens per second. But…
Since JavaScript code is often minified, V8 uses a simple lookup table for single ASCII character strings, so V8 is built for minified code! You can keep your long variable names, but be sure you minify your code.
Short Conclusion
The easiest way to improve the performance of the Scanning step is by minifying your source code, stripping out unnecessary whitespace, and avoiding non-ASCII identifiers where possible. Ideally, these steps are automated as part of a build process.
More information about Scanner: Blazingly fast parsing, part 1: optimizing the scanner
Parsing in V8
Parsing is the step where source code is turned into an intermediate representation to be consumed by a compiler (in V8, the bytecode compiler Ignition).
Parsing and compiling happen on the critical path of web page startup, and not all functions shipped to the browser are immediately needed during startup. Even though developers can delay such code with async and deferred scripts, that’s not always possible.
Additionally, many web pages ship code that’s only used by certain features which may not be accessed by a user at all during any individual run of the page.
So, it’s better to defer or lazy load JS modules, that are not needed for application startup. And don’t forget about the tree shaking of the code. It’s needed for better time-to-interact and for better lazy parsing.
Unwanted compilation of source code at one time may be too expensive:
- The availability of code, that is necessary for the app startup will be delayed.
- That’s taking memory, at least until bytecode flushing decides that the code isn’t needed and allows it to be garbage-collected.
- It will take up disk space for code caching.
To improve that, modern JS engines are doing lazy parsing.
The V8 engine has the Pre-parser: a copy of the parser that does the bare minimum needed to be able to otherwise skip over the function. // The PreParser checks that the syntax follows the grammar for JavaScript, and collects some information about the program along the way. The grammar check is only performed in order to understand the program sufficiently to deduce some information about it, which can be used to speed up later parsing.
Optimizing IIFEs
An IIFE (Immediately Invoked Function Expression) is a JavaScript function that runs as soon as it is defined.
IIFE exampleCode packers are wrapping modules to IIFEs, the danger of these IIFEs is that these functions are immediately needed at the very early stage of script execution, so it’s not ideal to prepare such functions.
V8 has two simple patterns it recognizes as possibly-invoked function expressions (PIFEs), upon which it immediately parses and compiles a function:
- If a function is a parenthesized function expression, i.e.
(function(){…}), V8 assumes it will be called. It makes this assumption as soon as it sees the start of this pattern, i.e.(function. - V8 also detects the pattern
!function(){…}(),function(){…}(),function(){…}()generated by UglifyJS.
Since V8 eagerly compiles PIFEs, they can be used as profile-directed feedback, informing the browser which functions are needed for startup.
Profile-directed feedback, also known as Profile-guided optimization, is a widely used compiler optimization technique, that uses profiling to improve performance.
Usually, it starts from static program analysis (without the running of source code, the opposite is dynamic analysis).
Analysis can even perform loop unrolling — loop transformation, which is performed to increase a program’s speed by reducing or eliminating instructions that control the loop, such as pointer arithmetic and “end of loop” tests on each iteration, reducing branch penalties; as well as hiding latencies, including the delay in reading data from memory.
Modern profile-guided optimizers can use both static and dynamic code analyses and recompile parts of code dynamically.
The example of Parsed code
Let’s take one simple piece of code:
Sum of arrayAnd the result, AST:
AST from JS codeQuite big! I used a local build of V8 with D8, V8’s developer shell:
d8 — print-ast reduce.js > reduce-ast.txt
Parsing usually takes up to 15–20% of the whole compilation time. And the non-minified AST is way bigger than the one from minified code. Use minifiers (e.g. UglifyJS), don’t try to minify your own code manually.
Also, Chrome can store compiled code locally to reduce compilation time in the next app runs.
More information about V8’s parser: Blazingly fast parsing, part 2: lazy parsing
A closer look at SpiderMonkey’s parser
Yes, SpiderMonkey has lazy (or syntax) parsing too. The parser creates AST, used by BytecodeEmitter. The resulting format uses Script Stencils. The key structures generated by parsing are instances of ScriptStencil.
The Stencil can then be instantiated into a series of Garbage Collector Cells that can be mutated and understood by the execution engines.
Stencils are the set of data structures capturing the result of parsing and bytecode emission. The Stencil format is a precursor format that is then used to allocate the corresponding scripts on the GC heap that will be used for execution. By decoupling from the GC and other runtime systems, robust caching and speculation systems can be built that are more thread-agnostic and flexible.
When a lazily compiled inner function is first executed, the engine recompiles just that function in a process called delazification. Lazy parsing avoids allocating the AST and bytecode which saves both CPU time and memory. In practice, many functions are never executed during a given load of a webpage so this delayed parsing can be quite beneficial.
JSC’s Lexer and Parser
Sure, JSC has both a lexical analyzer and parser.
Lexer does lexical analysis, i.e. breaking down the script source into a series of tokens. Main files: parser/Lexer.h and parser/Lexer.cpp.
The parser does the syntactic analysis, i.e. consuming the tokens from the lexer and building the corresponding syntax tree. JSC uses a hand-written recursive descent parser, the code is in parser/JSParser.h and parser/JSParser.cpp.
The next step is LLInt, the Low-Level interpreter. It can work with the code from Parser with zero start-up time.
You can read more about JSC parsing here and in this story, written by Assaf Sion.
Conclusion: Parsing step
We have reviewed the Parsing step of compilation and how is it done in different JavaScript engines.
You need to do these steps to make life easier for the parser:
- Defer loading of code modules, that you don’t need to the application startup.
- Check your node_modules, and remove all unnecessary dependencies.
- Use Devtools to find bottlenecks.
- Of course, minify your code. You don’t need tools like Optimize.js anymore. Check it here, in V8’s blog.
- Transpile less
Yes, you need to understand what your Babel or TSC (TypeScript compiler) doing and avoid too much null checking or syntax sugar. That can create some extra code. Check your generated code from time to time. And use the newest compilation target possible.
Even with IIFEs optimization, needlessly wrapping functions in parentheses should be avoided since it causes more code to be eagerly compiled, resulting in worse startup performance and increased memory usage.
Part 2 is going to be focused on Code Generation and Optimisations.
Big thanks to Diana Volodchenko for the illustrations for this story. If you need Web Designer and Graphic Designer support, feel free to contact her!
Also, I am looking for something new in my career. Just ping me on Twitter or LinkedIn.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK