

深度学习与CV教程(8) | 常见深度学习框架介绍 - ShowMeAI
source link: https://www.cnblogs.com/showmeai/p/16339676.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.


本系列为 斯坦福CS231n 《深度学习与计算机视觉(Deep Learning for Computer Vision)》的全套学习笔记,对应的课程视频可以在 这里 查看。更多资料获取方式见文末。
大家在前序文章中学习了很多关于神经网络的原理知识和实战技巧,在本篇内容中ShowMeAI给大家展开介绍深度学习硬件知识,以及目前主流的深度学习框架TensorFlow和pytorch相关知识,借助于工具大家可以实际搭建与训练神经网络。
- 深度学习硬件
- CPU、GPU、TPU
- 深度学习框架
- PyTorch / TensorFlow
- 静态与动态计算图
1.深度学习硬件
GPU(Graphics Processing Unit)是图形处理单元(又称显卡),在物理尺寸上就比 CPU(Central Processing Unit)大得多,有自己的冷却系统。最初用于渲染计算机图形,尤其是游戏。在深度学习上选择 NVIDIA(英伟达)的显卡,如果使用AMD的显卡会遇到很多问题。TPU(Tensor Processing Units)是专用的深度学习硬件。
1.1 CPU / GPU / TPU
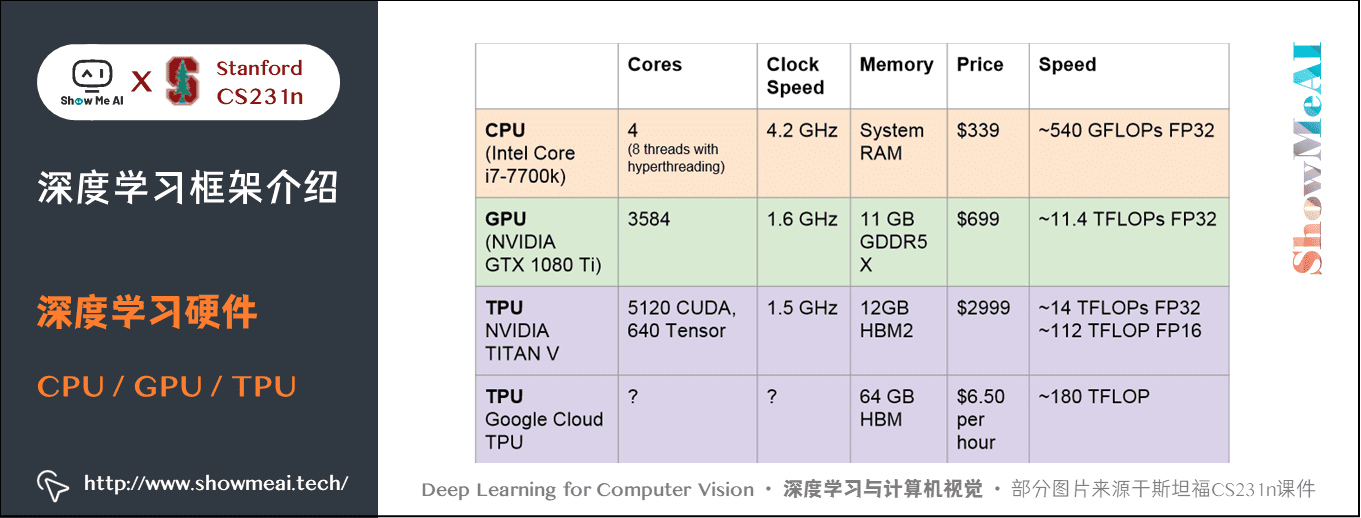
- CPU一般有多个核心,每个核心速度都很快都可以独立工作,可同时进行多个进程,内存与系统共享,完成序列任务时很有用。图上CPU的运行速度是每秒约 540 GFLOPs 浮点数运算,使用 32 位浮点数(注:一个 GFLOPS(gigaFLOPS)等于每秒十亿(=109=109)次的浮点运算)。
- GPU有上千个核心数,但每个核心运行速度很慢,也不能独立工作,适合大量的并行完成类似的工作。GPU一般自带内存,也有自己的缓存系统。图上GPU的运行速度是CPU的20多倍。
- TPU是专门的深度学习硬件,运行速度非常快。TITANV 在技术上并不是一个「TPU」,因为这是一个谷歌术语,但两者都有专门用于深度学习的硬件。运行速度非常快。
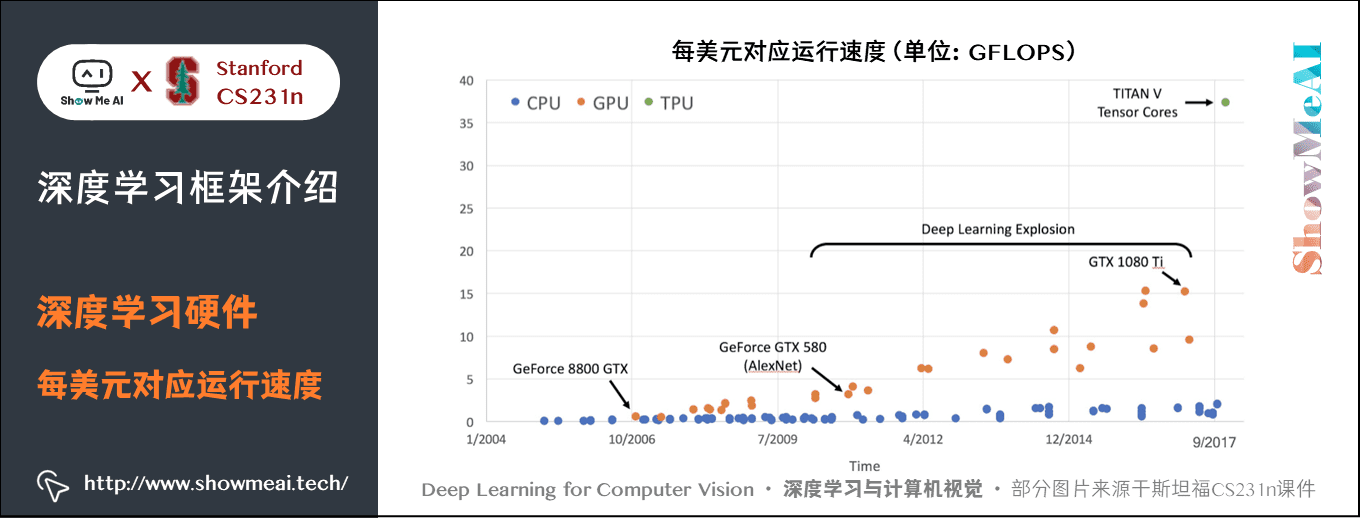
若是将这些运行速度除以对应的价格,可得到下图:
1.2 GPU的优势与应用
GPU 在大矩阵的乘法运算中有很明显的优势。
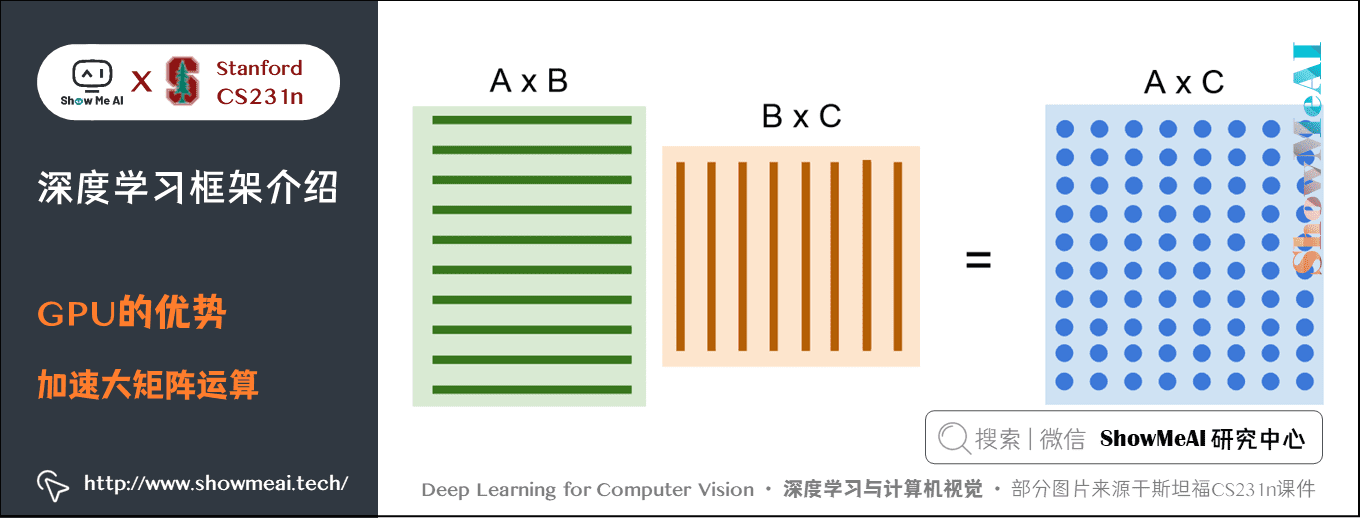
由于结果中的每一个元素都是相乘的两个矩阵的每一行和每一列的点积,所以并行的同时进行这些点积运算速度会非常快。卷积神经网络也类似,卷积核和图片的每个区域进行点积也是并行运算。
CPU 虽然也有多个核心,但是在大矩阵运算时只能串行运算,速度很慢。
可以写出在 GPU 上直接运行的代码,方法是使用NVIDIA自带的抽象代码 CUDA ,可以写出类似 C 的代码,并可以在 GPU 直接运行。
但是直接写 CUDA 代码是一件非常困难的事,好在可以直接使用 NVIDIA 已经高度优化并且开源的API,比如 cuBLAS 包含很多矩阵运算, cuDNN 包含 CNN 前向传播、反向传播、批量归一化等操作;还有一种语言是 OpenCL,可以在 CPU、AMD 上通用,但是没人做优化,速度很慢;HIP可以将CUDA 代码自动转换成可以在 AMD 上运行的语言。以后可能会有跨平台的标准,但是现在来看 CUDA 是最好的选择。
在实际应用中,同样的计算任务,GPU 比 CPU 要快得多,当然 CPU 还能进一步优化。使用 cuDNN 也比不使用要快接近三倍。
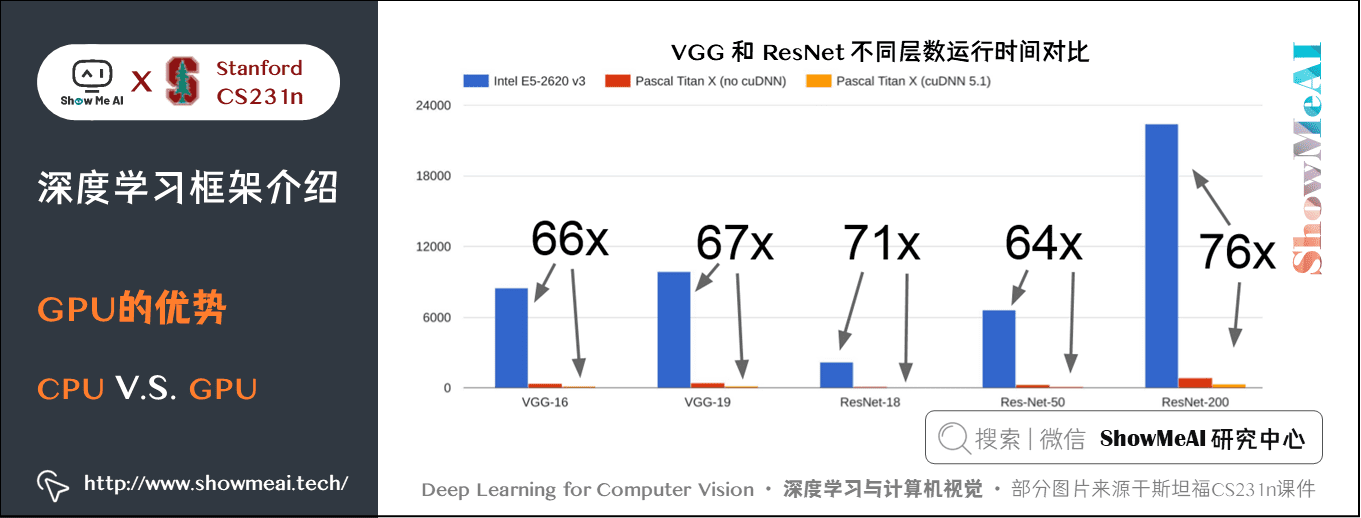
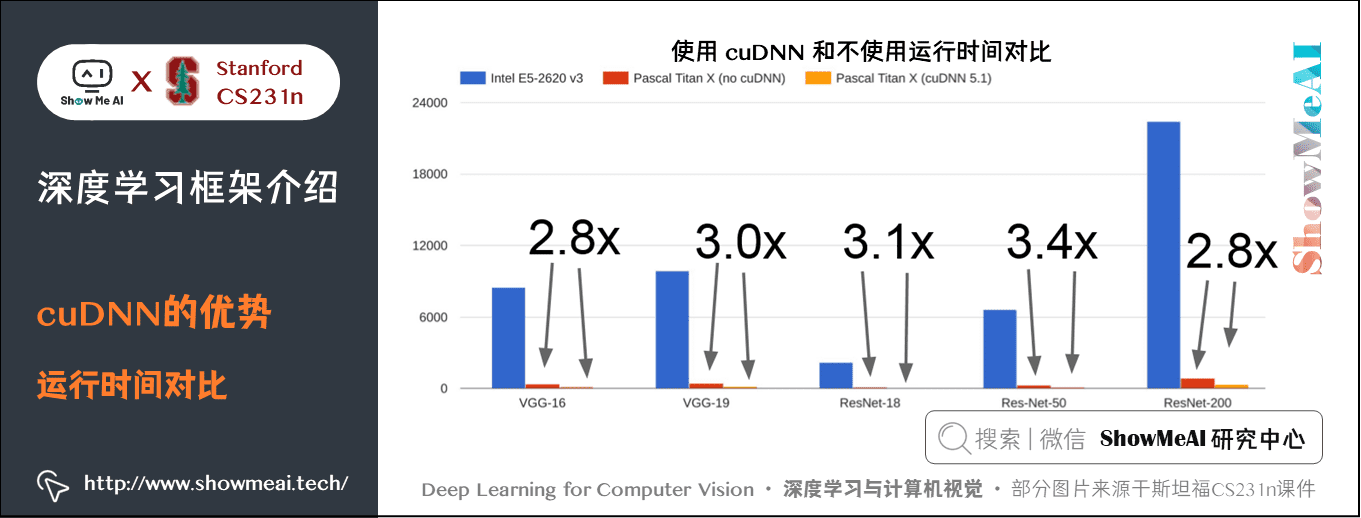
实际应用 GPU 还有一个问题是训练的模型一般存放在 GPU,而用于训练的数据存放在硬盘里,由于 GPU 运行快,而机械硬盘读取慢,就会拖累整个模型的训练速度。有多种解决方法:
- 如果训练数据数量较小,可以把所有数据放到 GPU 的 RAM 中;
- 用固态硬盘代替机械硬盘;
- 使用多个 CPU 线程预读取数据,放到缓存供 GPU 使用。
2.深度学习软件
2.1 DL软件概述
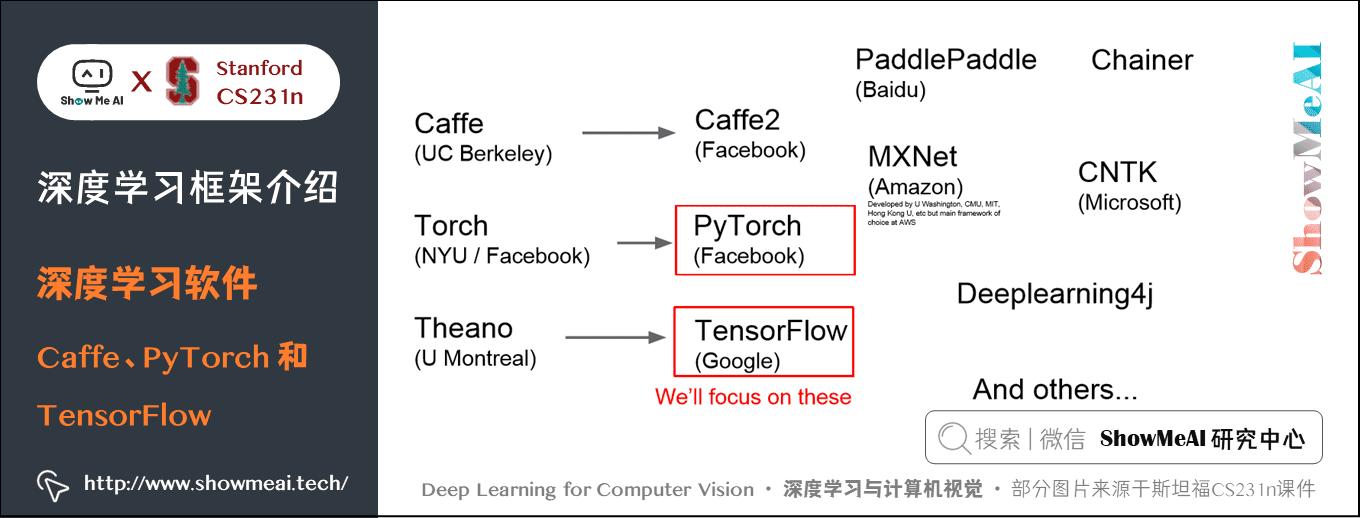
现在有很多种深度学习框架,目前最流行的是 TensorFlow。
第一代框架大多由学术界编写的,比如 Caffe 就是伯克利大学开发的。
第二代往往由工业界主导,比如 Caffe2 是由 Facebook 开发。这里主要讲解 PyTorch 和 TensorFlow。
回顾之前计算图的概念,一个线性分类器可以用计算图表示,网络越复杂,计算图也越复杂。之所以使用这些深度学习框架有三个原因:
- 构建大的计算图很容易,可以快速的开发和测试新想法;
- 这些框架都可以自动计算梯度只需写出前向传播的代码;
- 可以在 GPU 上高效的运行,已经扩展了 cuDNN 等包以及处理好数据如何在 CPU 和 GPU 中流动。
这样我们就不用从头开始完成这些工作了。
比如下面的一个计算图:
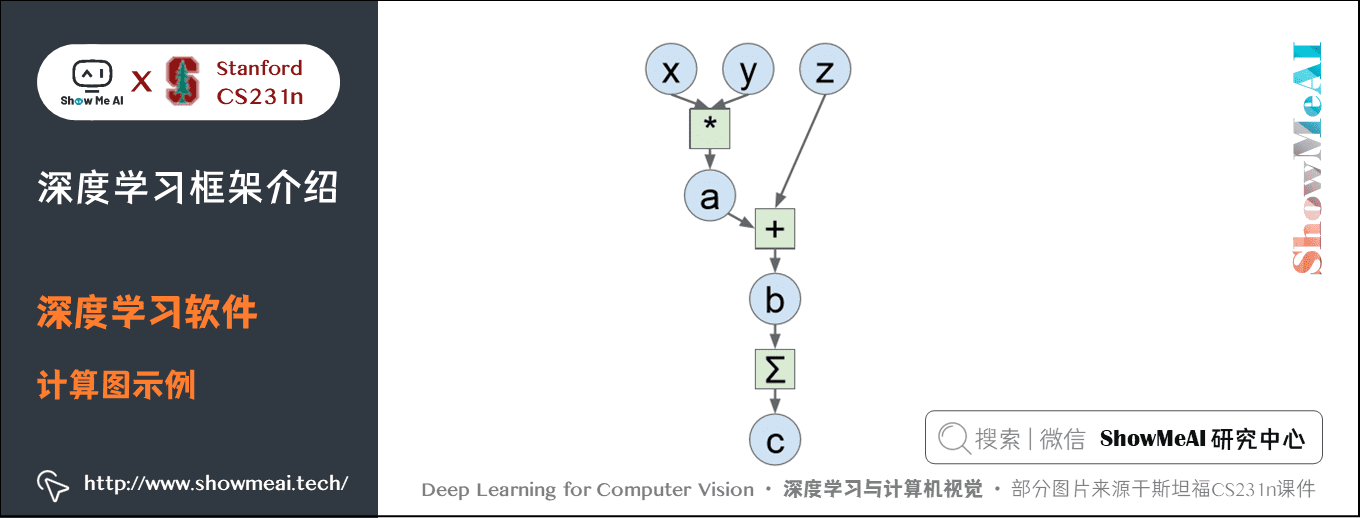
我们以前的做法是使用 Numpy 写出前向传播,然后计算梯度,代码如下:
import numpy as npnp.random.seed(0) # 保证每次的随机数一致 N, D = 3, 4 x = np.random.randn(N, D)y = np.random.randn(N, D)z = np.random.randn(N, D) a = x * yb = a + zc = np.sum(b) grad_c = 1.0grad_b = grad_c * np.ones((N, D))grad_a = grad_b.copy()grad_z = grad_b.copy()grad_x = grad_a * ygrad_y = grad_a * x
这种做法 API 干净,易于编写代码,但问题是没办法在 GPU 上运行,并且需要自己计算梯度。所以现在大部分深度学习框架的主要目标是自己写好前向传播代码,类似 Numpy,但能在 GPU 上运行且可以自动计算梯度。
TensorFlow 版本,前向传播构建计算图,梯度可以自动计算:
import numpy as npnp.random.seed(0)import tensorflow as tf N, D = 3, 4 # 创建前向计算图x = tf.placeholder(tf.float32)y = tf.placeholder(tf.float32)z = tf.placeholder(tf.float32) a = x * yb = a + zc = tf.reduce_sum(b) # 计算梯度grad_x, grad_y, grad_z = tf.gradients(c, [x, y, z]) with tf.Session() as sess: values = { x: np.random.randn(N, D), y: np.random.randn(N, D), z: np.random.randn(N, D), } out = sess.run([c, grad_x, grad_y, grad_z], feed_dict=values) c_val, grad_x_val, grad_y_val, grad_z_val = out print(c_val) print(grad_x_val)
PyTorch版本,前向传播与Numpy非常类似,但反向传播可以自动计算梯度,不用再去实现。
import torch device = 'cuda:0' # 在GPU上运行,即构建GPU版本的矩阵 # 前向传播与Numpy类似N, D = 3, 4x = torch.randn(N, D, requires_grad=True, device=device)# requires_grad要求自动计算梯度,默认为Truey = torch.randn(N, D, device=device)z = torch.randn(N, D, device=device) a = x * yb = a + zc = torch.sum(b) c.backward() # 反向传播可以自动计算梯度print(x.grad)print(y.grad)print(z.grad)
可见这些框架都能自动计算梯度并且可以自动在 GPU 上运行。
2.2 TensoFlow
关于TensorFlow的用法也可以阅读ShowMeAI的制作的 TensorFlow 速查表,对应文章AI 建模工具速查 | TensorFlow使用指南和AI建模工具速查 | Keras使用指南。
下面以一个两层的神经网络为例,非线性函数使用 ReLU 函数、损失函数使用 L2 范式(当然仅仅是一个学习示例)。
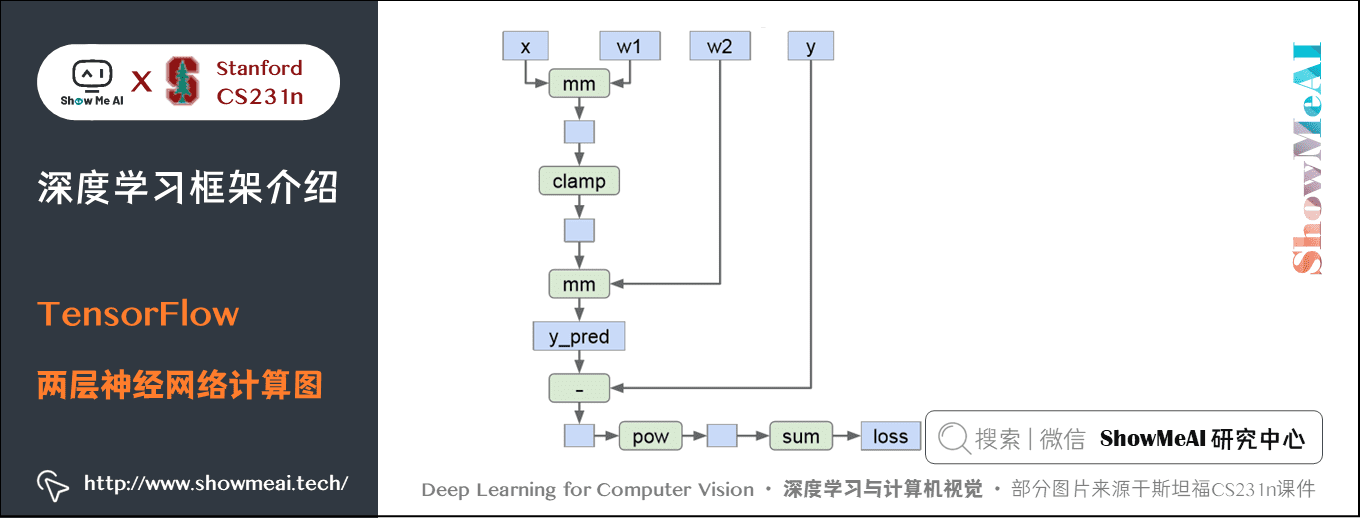
实现代码如下:
1) 神经网络
import numpy as npimport tensorflow as tf N, D , H = 64, 1000, 100 # 创建前向计算图x = tf.placeholder(tf.float32, shape=(N, D))y = tf.placeholder(tf.float32, shape=(N, D))w1 = tf.placeholder(tf.float32, shape=(D, H))w2 = tf.placeholder(tf.float32, shape=(H, D)) h = tf.maximum(tf.matmul(x, w1), 0) # 隐藏层使用折叶函数y_pred = tf.matmul(h, w2)diff = y_pred - y # 差值矩阵loss = tf.reduce_mean(tf.reduce_sum(diff ** 2, axis=1)) # 损失函数使用L2范数 # 计算梯度grad_w1, grad_w2 = tf.gradients(loss, [w1, w2]) # 多次运行计算图with tf.Session() as sess: values = { x: np.random.randn(N, D), y: np.random.randn(N, D), w1: np.random.randn(D, H), w2: np.random.randn(H, D), } out = sess.run([loss, grad_w1, grad_w2], feed_dict=values) loss_val, grad_w1_val, grad_w2_val = out
整个过程可以分成两部分,with 之前部分定义计算图,with 部分多次运行计算图。这种模式在TensorFlow 中很常见。
- 首先,我们创建了
x,y,w1,w2四个tf.placeholder对象,这四个变量作为「输入槽」,下面再输入数据。 - 然后使用这四个变量创建计算图,使用矩阵乘法
tf.matmul和折叶函数tf.maximum计算y_pred,使用 L2 距离计算 s 损失。但是目前并没有实际的计算,因为只是构建了计算图并没有输入任何数据。 - 然后通过一行神奇的代码计算损失值关于
w1和w2的梯度。此时仍然没有实际的运算,只是构建计算图,找到 loss 关于w1和w2的路径,在原先的计算图上增加额外的关于梯度的计算。 - 完成计算图后,创建一个会话 Session 来运行计算图和输入数据。进入到 Session 后,需要提供 Numpy 数组给上面创建的「输入槽」。
- 最后两行代码才是真正的运行,执行
sess.run需要提供 Numpy 数组字典feed_dict和需要输出的计算值 loss ,grad_w1,grad_w2` ,最后通过解包获取 Numpy 数组。
上面的代码只是运行了一次,我们需要迭代多次,并设置超参数、参数更新方式等:
with tf.Session() as sess: values = { x: np.random.randn(N, D), y: np.random.randn(N, D), w1: np.random.randn(D, H), w2: np.random.randn(H, D), } learning_rate = 1e-5 for t in range(50): out = sess.run([loss, grad_w1, grad_w2], feed_dict=values) loss_val, grad_w1_val, grad_w2_val = out values[w1] -= learning_rate * grad_w1_val values[w2] -= learning_rate * grad_w2_val
这种迭代方式有一个问题是每一步需要将Numpy和数组提供给GPU,GPU计算完成后再解包成Numpy数组,但由于CPU与GPU之间的传输瓶颈,非常不方便。
解决方法是将 w1 和 w2 作为变量而不再是「输入槽」,变量可以一直存在于计算图上。
由于现在 w1 和 w2 变成了变量,所以就不能从外部输入 Numpy 数组来初始化,需要由 TensorFlow 来初始化,需要指明初始化方式。此时仍然没有具体的计算。
w1 = tf.Variable(tf.random_normal((D, H)))w2 = tf.Variable(tf.random_normal((H, D)))
现在需要将参数更新操作也添加到计算图中,使用赋值操作 assign 更新 w1 和 w2,并保存在计算图中(位于计算梯度后面):
learning_rate = 1e-5new_w1 = w1.assign(w1 - learning_rate * grad_w1)new_w2 = w2.assign(w2 - learning_rate * grad_w2)
现在运行这个网络,需要先运行一步参数的初始化 tf.global_variables_initializer(),然后运行多次代码计算损失值:
with tf.Session() as sess: sess.run(tf.global_variables_initializer()) values = { x: np.random.randn(N, D), y: np.random.randn(N, D), } for t in range(50): loss_val, = sess.run([loss], feed_dict=values)
2) 优化器
上面的代码,实际训练过程中损失值不会变。
原因是我们执行的 sess.run([loss], feed_dict=values) 语句只会计算 loss,TensorFlow 非常高效,与损失值无关的计算一律不会进行,所以参数就无法更新。
一个解决办法是在执行 run 时加入计算两个参数,这样就会强制执行参数更新,但是又会产生CPU 与 GPU 的通信问题。
一个技巧是在计算图中加入两个参数的依赖,在执行时需要计算这个依赖,这样就会让参数更新。这个技巧是 group 操作,执行完参数赋值操作后,执行 updates = tf.group(new_w1, new_w2),这个操作会在计算图上创建一个节点;然后执行的代码修改为 loss_val, _ = sess.run([loss, updates], feed_dict=values),在实际运算时,updates 返回值为空。
这种方式仍然不够方便,好在 TensorFlow 提供了更便捷的操作,使用自带的优化器。优化器需要提供学习率参数,然后进行参数更新。有很多优化器可供选择,比如梯度下降、Adam等。
optimizer = tf.train.GradientDescentOptimizer(1e-5) # 使用优化器updates = optimizer.minimize(loss) # 更新方式是使loss下降,内部其实使用了group
执行的代码也是:loss_val, _ = sess.run([loss, updates], feed_dict=values)
计算损失的代码也可以使用 TensorFlow 自带的函数:
loss = tf.losses.mean_squared_error(y_pred, y) # 损失函数使用L2范数
目前仍有一个很大的问题是 x,y,w1,w2 的形状需要我们自己去定义,还要保证它们能正确连接在一起,此外还有偏差。如果使用卷积层、批量归一化等层后,这些定义会更加麻烦。
TensorFlow可以解决这些麻烦:
N, D , H = 64, 1000, 100x = tf.placeholder(tf.float32, shape=(N, D))y = tf.placeholder(tf.float32, shape=(N, D)) init = tf.variance_scaling_initializer(2.0) # 权重初始化使用He初始化h = tf.layers.dense(inputs=x, units=H, activation=tf.nn.relu, kernel_initializer=init)# 隐藏层使用折叶函数y_pred = tf.layers.dense(inputs=h, units=D, kernel_initializer=init) loss = tf.losses.mean_squared_error(y_pred, y) # 损失函数使用L2范数 optimizer = tf.train.GradientDescentOptimizer(1e-5)updates = optimizer.minimize(loss) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) values = { x: np.random.randn(N, D), y: np.random.randn(N, D), } for t in range(50): loss_val, _ = sess.run([loss, updates], feed_dict=values)
上面的代码,x,y 的初始化没有变化,但是参数 w1,w2 隐藏起来了,初始化使用 He初始化。
前向传播的计算使用了全连接层 tf.layers.dense,该函数需要提供输入数据 inputs、该层的神经元数目 units、激活函数 activation、卷积核(权重)初始化方式 kernel_initializer 等参数,可以自动设置权重和偏差。
5) High level API:tensorflow.keras
Keras 是基于 TensorFlow 的更高层次的封装,会让整个过程变得简单,曾经是第三方库,现在已经被内置到了 TensorFlow。
使用 Keras 的部分代码如下,其他与上文一致:
N, D , H = 64, 1000, 100x = tf.placeholder(tf.float32, shape=(N, D))y = tf.placeholder(tf.float32, shape=(N, D)) model = tf.keras.Sequential() # 使用一系列层的组合方式# 添加一系列的层model.add(tf.keras.layers.Dense(units=H, input_shape=(D,), activation=tf.nn.relu))model.add(tf.keras.layers.Dense(D))# 调用模型获取结果y_pred = model(x)loss = tf.losses.mean_squared_error(y_pred, y)
这种模型已经简化了很多工作,最终版本代码如下:
import numpy as npimport tensorflow as tf N, D , H = 64, 1000, 100 # 创建模型,添加层model = tf.keras.Sequential()model.add(tf.keras.layers.Dense(units=H, input_shape=(D,), activation=tf.nn.relu))model.add(tf.keras.layers.Dense(D)) # 配置模型:损失函数、参数更新方式model.compile(optimizer=tf.keras.optimizers.SGD(lr=1e-5), loss=tf.keras.losses.mean_squared_error) x = np.random.randn(N, D)y = np.random.randn(N, D) # 训练history = model.fit(x, y, epochs=50, batch_size=N)
代码非常简洁:
- 定义模型:
tf.keras.Sequential()表明模型是一系列的层,然后添加两个全连接层,并设置激活函数、每层的神经元数目等; - 配置模型:用
model.compile方法配置模型的优化器、损失函数等; - 基于数据训练模型:使用
model.fit,需要设置迭代周期次数、批量数等,可以直接用原始数据训练模型。
6) 其他知识
① 常见的拓展包
② 预训练模型
TensorFlow已经有一些预训练好的模型可以直接拿来用,利用迁移学习,微调参数。
③ Tensorboard
- 增加日志记录损失值和状态
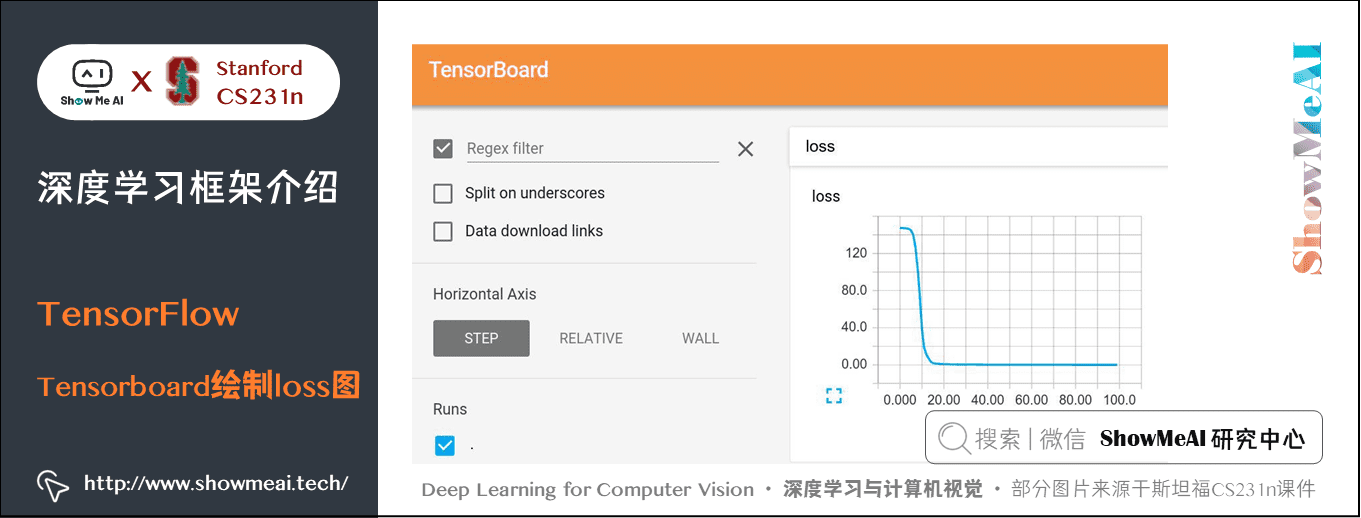
④ 分布式操作
可以在多台机器上运行,谷歌比较擅长。
⑤ TPU(Tensor Processing Units)
TPU是专用的深度学习硬件,运行速度非常快。Google Cloud TPU 算力为180 TFLOPs ,NVIDIA Tesla V100算力为125 TFLOPs。

⑥Theano
TensorFlow的前身,二者许多地方都很相似。
2.3 PyTorch
关于PyTorch的用法也可以阅读ShowMeAI的制作的PyTorch速查表,对应文章AI 建模工具速查 | Pytorch使用指南
1) 基本概念
- Tensor:与Numpy数组很相似,只是可以在GPU上运行;
- Autograd:使用Tensors构建计算图并自动计算梯度的包;
- Module:神经网络的层,可以存储状态和可学习的权重。
下面的代码使用的是v0.4版本。
2) Tensors
下面使用Tensors训练一个两层的神经网络,激活函数使用ReLU、损失使用L2损失。
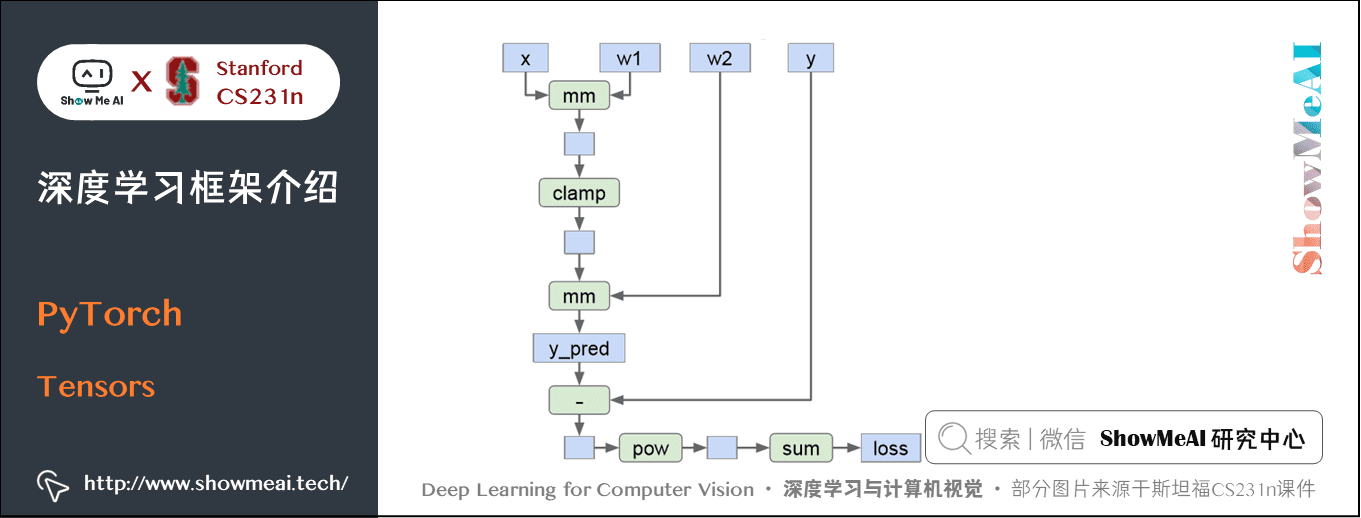
代码如下:
import torch # cpu版本device = torch.device('cpu')#device = torch.device('cuda:0') # 使用gpu # 为数据和参数创建随机的TensorsN, D_in, H, D_out = 64, 1000, 100, 10x = torch.randn(N, D_in, device=device)y = torch.randn(N, D_out, device=device)w1 = torch.randn(D_in, H, device=device)w2 = torch.randn(H, D_out, device=device) learning_rate = 1e-6for t in range(500): # 前向传播,计算预测值和损失 h = x.mm(w1) h_relu = h.clamp(min=0) y_pred = h_relu.mm(w2) loss = (y_pred - y).pow(2).sum() # 反向传播手动计算梯度 grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.t().mm(grad_y_pred) grad_h_relu = grad_y_pred.mm(w2.t()) grad_h = grad_h_relu.clone() grad_h[h < 0] = 0 grad_w1 = x.t().mm(grad_h) # 梯度下降,参数更新 w1 -= learning_rate * grad_w1 w2 -= learning_rate * grad_w2
- 首先创建
x,y,w1,w2的随机 tensor,与 Numpy 数组的形式一致 - 然后前向传播计算损失值和预测值
- 然后手动计算梯度
- 最后更新参数
上述代码很简单,和 Numpy 版本的写法很接近。但是需要手动计算梯度。
3) Autograd自动梯度计算
PyTorch 可以自动计算梯度:
import torch # 创建随机tensorsN, D_in, H, D_out = 64, 1000, 100, 10x = torch.randn(N, D_in)y = torch.randn(N, D_out)w1 = torch.randn(D_in, H, requires_grad=True)w2 = torch.randn(H, D_out, requires_grad=True) learning_rate = 1e-6for t in range(500): # 前向传播 y_pred = x.mm(w1).clamp(min=0).mm(w2) loss = (y_pred - y).pow(2).sum() # 反向传播 loss.backward() # 参数更新 with torch.no_grad(): w1 -= learning_rate * w1.grad w2 -= learning_rate * w2.grad w1.grad.zero_() w2.grad.zero_()
与上一版代码的主要区别是:
- 创建
w1,w2时要求requires_grad=True,这样会自动计算梯度,并创建计算图。x1,x2不需要计算梯度。 - 前向传播与之前的类似,但现在不用保存节点,PyTorch 可以帮助我们跟踪计算图。
- 使用
loss.backward()自动计算要求的梯度。 - 按步对权重进行更新,然后将梯度归零。
Torch.no_grad的意思是「不要为这部分构建计算图」。以下划线结尾的 PyTorch 方法是就地修改 Tensor,不返回新的 Tensor。
TensorFlow 与 PyTorch 的区别是 TensorFlow 需要先显式的构造一个计算图,然后重复运行;PyTorch 每次做前向传播时都要构建一个新的图,使程序看起来更加简洁。
PyTorch 支持定义自己的自动计算梯度函数,需要编写 forward,backward 函数。与作业中很相似。可以直接用到计算图上,但是实际上自己定义的时候并不多。
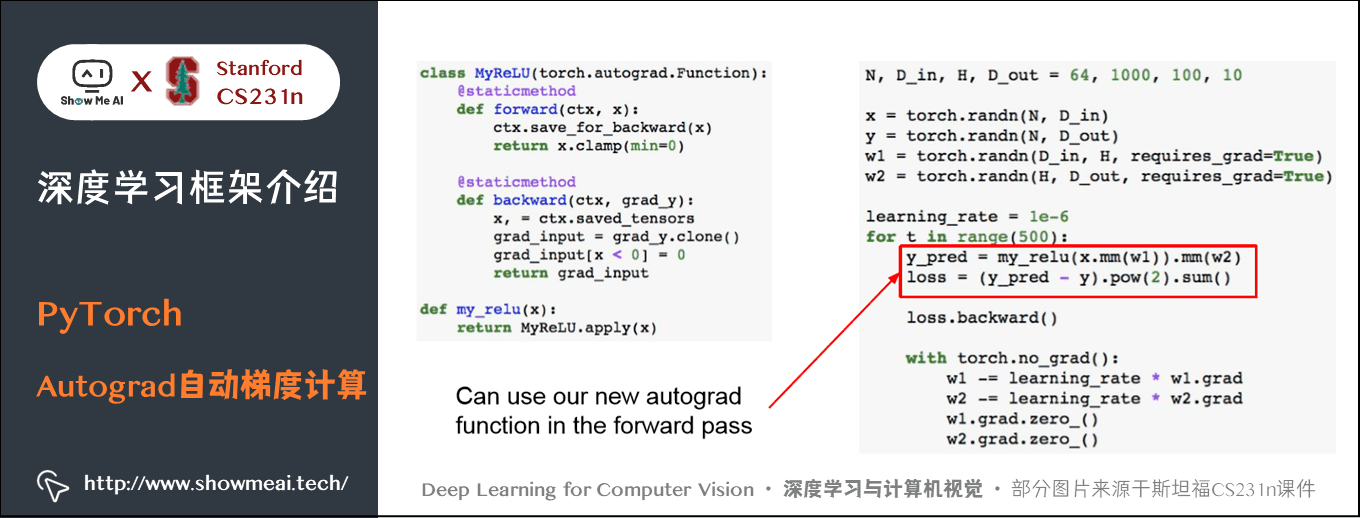
与 Keras 类似的高层次封装,会使整个代码变得简单。
import torch N, D_in, H, D_out = 64, 1000, 100, 10x = torch.randn(N, D_in)y = torch.randn(N, D_out) # 定义模型model = torch.nn.Sequential(torch.nn.Linear(D_in, H), torch.nn.ReLu(), torch.nn.Linear(H, D_out)) learning_rate = 1e-2for t in range(500): # 前向传播 y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred, y) # 计算梯度 loss.backward() with torch.no_grad(): for param in model.parameters(): param -= learning_rate * param.grad model.zero_grad()
- 定义模型是一系列的层组合,在模型中定义了层对象比如全连接层、折叶层等,里面包含可学习的权重;
- 前向传播将数据给模型就可以直接计算预测值,进而计算损失;
torch.nn.functional含有很多有用的函数,比如损失函数; - 反向传播会计算模型中所有权重的梯度;
- 最后每一步都更新模型的参数。
5) Optimizer
PyTorch 同样有自己的优化器:
import torch N, D_in, H, D_out = 64, 1000, 100, 10x = torch.randn(N, D_in)y = torch.randn(N, D_out) # 定义模型model = torch.nn.Sequential(torch.nn.Linear(D_in, H), torch.nn.ReLu(), torch.nn.Linear(H, D_out))# 定义优化器learning_rate = 1e-4optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)# 迭代for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred, y) loss.backward() # 更新参数 optimizer.step() optimizer.zero_grad()
- 使用不同规则的优化器,这里使用Adam;
- 计算完梯度后,使用优化器更新参数,再置零梯度。
6) 定义新的模块
PyTorch 中一个模块就是一个神经网络层,输入和输出都是 tensors。模块中可以包含权重和其他模块,可以使用 Autograd 定义自己的模块。
比如可以把上面代码中的两层神经网络改成一个模块:
import torch# 定义上文的整个模块为单个模块class TwoLayerNet(torch.nn.Module): # 初始化两个子模块,都是线性层 def __init__(self, D_in, H, D_out): super(TwoLayerNet, self).__init__() self.linear1 = torch.nn.Linear(D_in, H) self.linear2 = torch.nn.Linear(H, D_out) # 使用子模块定义前向传播,不需要定义反向传播,autograd会自动处理 def forward(self, x): h_relu = self.linear1(x).clamp(min=0) y_pred = self.linear2(h_relu) return y_pred N, D_in, H, D_out = 64, 1000, 100, 10x = torch.randn(N, D_in)y = torch.randn(N, D_out)# 构建模型与训练和之前类似model = TwoLayerNet(D_in, H, D_out)optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)for t in range(500): y_pred = model(x) loss = torch.nn.functional.mse_loss(y_pred, y) loss.backward() optimizer.step() optimizer.zero_grad()
这种混合自定义模块非常常见,定义一个模块子类,然后作为作为整个模型的一部分添加到模块序列中。
比如用定义一个下面这样的模块,输入数据先经过两个并列的全连接层得到的结果相乘后经过 ReLU:
class ParallelBlock(torch.nn.Module): def __init__(self, D_in, D_out): super(ParallelBlock, self).__init__() self.linear1 = torch.nn.Linear(D_in, D_out) self.linear2 = torch.nn.Linear(D_in, D_out) def forward(self, x): h1 = self.linear1(x) h2 = self.linear2(x) return (h1 * h2).clamp(min=0)
然后在整个模型中应用:
model = torch.nn.Sequential(ParallelBlock(D_in, H), ParallelBlock(H, H), torch.nn.Linear(H, D_out))
使用 ParallelBlock 的新模型计算图如下:
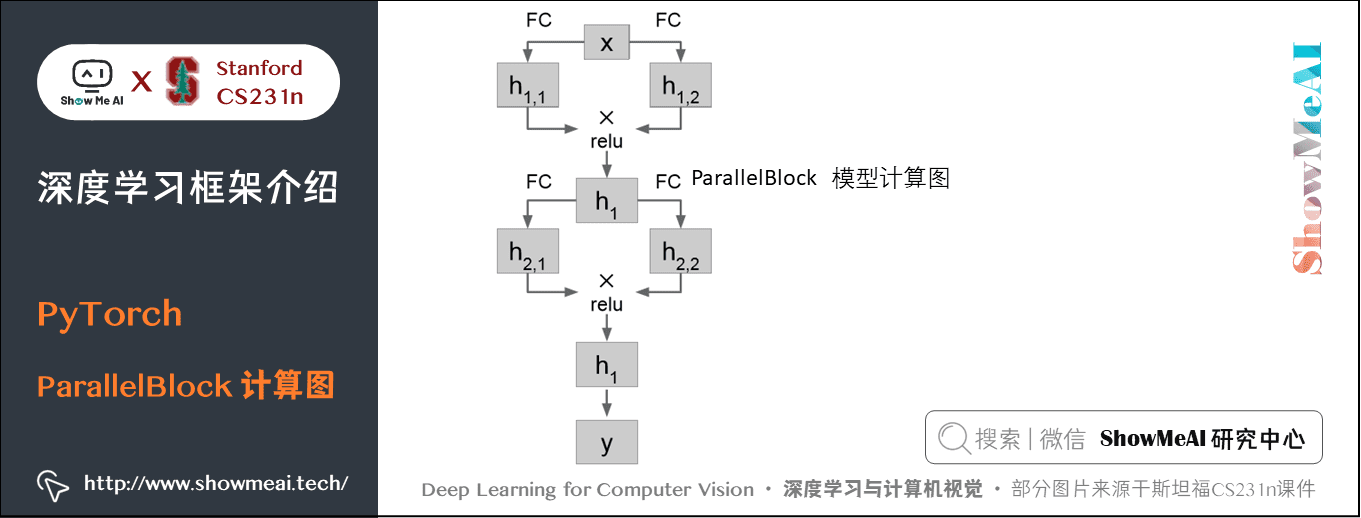
7) DataLoader
DataLoader 包装数据集并提供获取小批量数据,重新排列,多线程读取等,当需要加载自定义数据时,只需编写自己的数据集类:
import torchfrom torch.utils.data import TensorDataset, DataLoader N, D_in, H, D_out = 64, 1000, 100, 10x = torch.randn(N, D_in)y = torch.randn(N, D_out) loader = DataLoader(TensorDataset(x, y), batch_size=8)model = TwoLayerNet(D_in, H, D_out)optimizer = torch.optim.Adam(model.parameters(), lr=1e-2) for epoch in range(20): for x_batch, y_batch in loader: y_pred = model(x_batch) loss = torch.nn.functional.mse_loss(y_pred, y_batch) loss.backward() optimizer.step() optimizer.zero_grad()
上面的代码仍然是两层神经完网络,使用了自定义的模块。这次使用了 DataLoader 来处理数据。最后更新的时候在小批量上更新,一个周期会迭代所有的小批量数据。一般的 PyTorch 模型基本都长成这个样子。
8) 预训练模型
使用预训练模型非常简单:https://github.com/pytorch/vision
import torchimport torchvisionalexnet = torchvision.models.alexnet(pretrained=True)vgg16 = torchvision.models.vggl6(pretrained=-True)resnet101 = torchvision.models.resnet101(pretrained=True)
9) Visdom
可视化的包,类似 TensorBoard,但是不能像 TensorBoard 一样可视化计算图。
10) Torch
PyTorch 的前身,不能使用 Python,没有 Autograd,但比较稳定,不推荐使用。
3.静态与动态图(Static vs Dynamic Graphs )
TensorFlow使用的是静态图(Static Graphs):
- 构建计算图描述计算,包括找到反向传播的路径;
- 每次迭代执行计算,都使用同一张计算图。
与静态图相对应的是PyTorch使用的动态图(Dynamic Graphs),构建计算图与计算同时进行:
- 创建tensor对象;
- 每一次迭代构建计算图数据结构、寻找参数梯度路径、执行计算;
- 每一次迭代抛出计算图,然后再重建。之后重复上一步。
3.1 静态图的优势
使用静态图形,由于一张图需要反复运行很多次,这样框架就有机会在计算图上做优化。
- 比如下面的自己写的计算图可能经过多次运行后优化成右侧,提高运行效率。
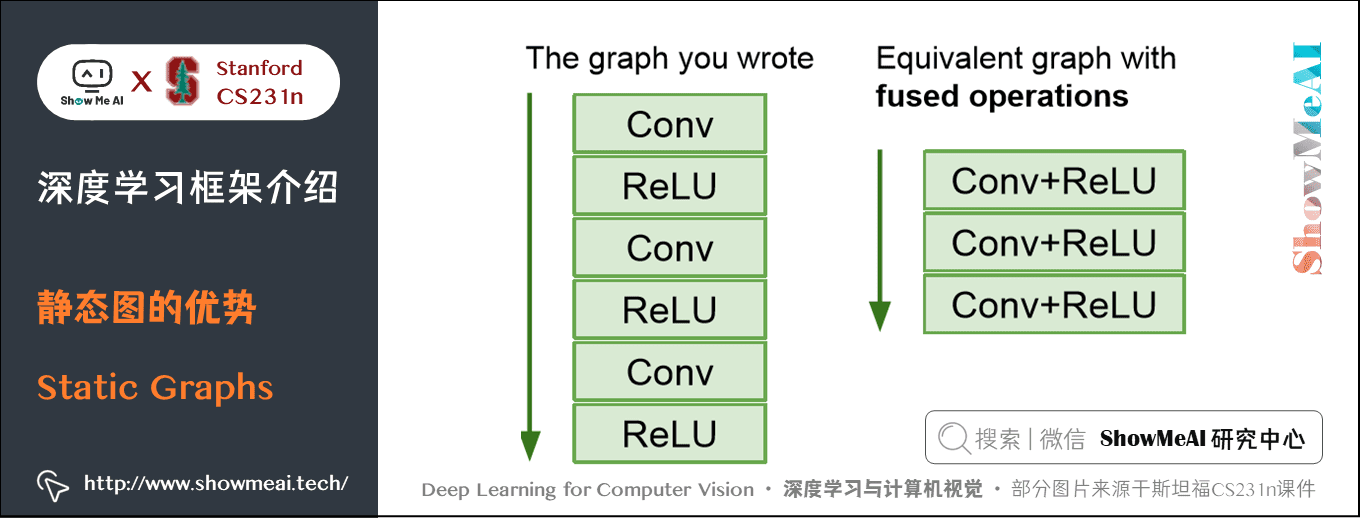
静态图只需要构建一次计算图,所以一旦构建好了即使源代码使用 Python 写的,也可以部署在C++上,不用依赖源代码;而动态图每次迭代都要使用源代码,构件图和运行是交织在一起的。
3.2 动态图的优势
动态图的代码比较简洁,很像 Python 操作。
在条件判断逻辑中,由于 PyTorch 可以动态构建图,所以可以使用正常的 Python 流操作;而TensorFlow 只能一次性构建一个计算图,所以需要考虑到所有情况,只能使用 TensorFlow 流操作,这里使用的是和条件有关的。

在循环结构中,也是如此。
- PyTorch 只需按照 Python 的逻辑去写,每次会更新计算图而不用管最终的序列有多长;
- TensorFlow 由于使用静态图必须把这个循环结构显示的作为节点添加到计算图中,所以需要用到 TensorFlow 的循环流
tf.foldl。并且大多数情况下,为了保证只构建一次循环图, TensorFlow 只能使用自己的控制流,比如循环流、条件流等,而不能使用 Python 语法,所以用起来需要学习 TensorFlow 特有的控制命令。

3.3 动态图的应用
1) 循环网络(Recurrent Networks)
例如图像描述,需要使用循环网络在一个不同长度序列上运行,我们要生成的用于描述图像的语句是一个序列,依赖于输入数据的序列,即动态的取决于输入句子的长短。
2) 递归网络(Recursive Networks)
用于自然语言处理,递归训练整个语法解析树,所以不仅仅是层次结构,而是一种图或树结构,在每个不同的数据点都有不同的结构,使用TensorFlow很难实现。在 PyTorch 中可以使用 Python 控制流,很容易实现。
3) Modular Networks
一种用于询问图片上的内容的网络,问题不一样生成的动态图也就不一样。
3.4 TensorFlow与PyTorch的相互靠拢
TensorFlow 与 PyTorch 的界限越来越模糊,PyTorch 正在添加静态功能,而 TensorFlow 正在添加动态功能。
- TensorFlow Fold 可以把静态图的代码自动转化成静态图
- TensorFlow 1.7增加了Eager Execution,允许使用动态图
import tensorflow as tfimport tensorflow.contrib.eager as tfetf.enable eager _execution() N, D = 3, 4x = tfe.Variable(tf.random_normal((N, D)))y = tfe.Variable(tf.random_normal((N, D)))z = tfe.Variable(tf.random_normal((N, D))) with tfe.GradientTape() as tape: a=x * 2 b=a + z c = tf.reduce_sum(b) grad_x, grad_y, grad_z = tape.gradient(c, [x, y, 2])print(grad_x)
- 在程序开始时使用
tf.enable_eager_execution模式:它是一个全局开关 tf.random_normal会产生具体的值,无需 placeholders / sessions,如果想要为它们计算梯度,要用tfe.Variable进行包装- 在
GradientTape下操作将构建一个动态图,类似于 PyTorch - 使用
tape计算梯度,类似 PyTorch 中的backward。并且可以直接打印出来 - 静态的 PyTorch 有 [Caffe2](https://caffe2.ai/)、[ONNX Support](https://caffe2.ai/)
4.拓展学习
可以点击 B站 查看视频的【双语字幕】版本
5.要点总结
- 深度学习硬件最好使用 GPU,然后需要解决 CPU 与 GPU 的通信问题。TPU 是专门用于深度学习的硬件,速度非常快。
- PyTorch 与 TensorFlow 都是非常好的深度学习框架,都有可以在 GPU 上直接运行的数组,都可以自动计算梯度,都有很多已经写好的函数、层等可以直接使用。前者使用动态图,后者使用静态图,不过二者都在向对方发展。取舍取决于项目。
斯坦福 CS231n 全套解读
ShowMeAI 系列教程推荐

Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK