

Get to Know Apache Flume from Scratch!
source link: https://www.analyticsvidhya.com/blog/2022/05/get-to-know-apache-flume-from-scratch/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
This article was published as a part of the Data Science Blogathon.
Introduction
Apache Flume, a part of the Hadoop ecosystem, was developed by Cloudera. Initially, it was designed to handle log data solely, but later, it was developed to process event data.
The Apache Flume tool is designed mainly for ingesting a high volume of event-based data, especially unstructured data, into Hadoop. Flume moves these files to the Hadoop Distributed File System (HDFS) for further processing and is flexible to write to other storage solutions like HBase or Solr. Therefore, Apache Flume is an excellent data ingestion tool fit for aggregating, storing, and analyzing the data with Hadoop. This article expects you to have some basic knowledge of the Hadoop ecosystem and its components.
What is Apache Flume?
Apache Hadoop has become a default for big data for established businesses. Nowadays, applications generate big data that eventually gets written to HDFS. Apache Flume was developed to be a reliable and scalable system to write data to Apache Hadoop and HBase. Due to this, Flume has rich features that allow writing the data in several formats supported by the Hadoop and HBase systems. Also, it is possible to perform this in a MapReduce/Hive/Impala/Pig–friendly way. Thus, Apache Flume is an open-source tool for collecting, aggregating, and pushing log data from a massive number of sources into different storage systems in the Hadoop ecosystem, like HDFS and HBase. It is a highly available, distributed, and reliable service that is fault-tolerant and resilient.
Apache Flume collects vast data logs from a source and writes them to storage while retaining all the events. These data feeds could be streaming logs; Twitter feeds, network traffic, etc. However, we need to note that Apache Flume works on a push model and cannot process the data. The data ingested by Apache Flume can either be stored in HDFS or reused later/moved further through Spark Streaming for analytics purposes, or it could even be integrated with a Kafka pipeline for messaging requirements. There are several ways to store and process the ingested data, but this relies on the way of data processing by the organization. Following is a simple representation of the Apache Flume system.
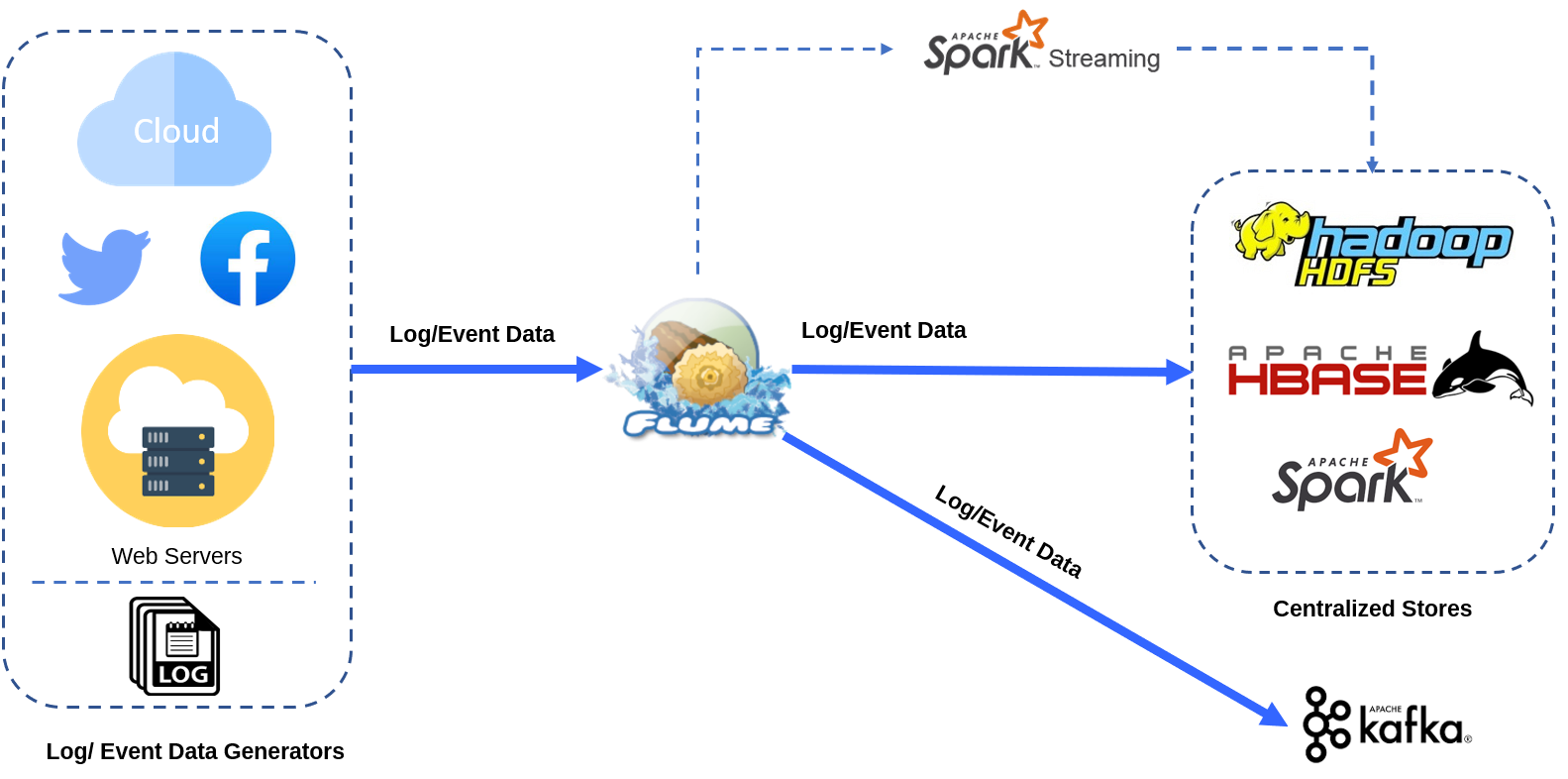
Now that we know about what Flume is, it is possible to wonder why a system like a Flume is needed? If we can simply write data directly to HDFS from every application server that produces data, why not do so? Let us explore this in the next section.
Why do we Need Flume?
There are a few clear reasons why a system like Apache Flume is needed. These can be summarized as –
1. Reducing load and latency issues: When big data needs to be handled on a Hadoop cluster, it is usually produced by a large number of servers, i.e., hundreds or possibly thousands of servers. Thus, multiple servers trying to write data to an HDFS/HBase cluster can cause significant problems. Since HDFS requires that only one client writes to a file, it means there could be a large number of files being written to HDFS parallelly, resulting in multiple complex sets of operations co-occurring on the name node. This increases the load on the machine. Similarly, when thousands of machines are writing a vast amount of data to fewer machines, the connecting network might get overloaded and cause severe latency issues. To address this issue, a Flume system is required.
2. Resolving problems related to Production systems: Most production applications experience regular patterns of production traffic, i.e., a few hours of peak traffic each day and substantially less traffic for the rest of the day. To ensure that there is no data loss or a requirement for a large buffer, the HDFS/HBase cluster must be designed to handle peak demand with minimal latency. This indicates the need to isolate production apps from HDFS/HBase and ensure that production applications send data to these systems in a controlled and ordered manner. This problem can be resolved using a Flume system.
3. Add flexibility and scalability to the entire system: Due to the flexible structure of Flume agents, it is possible to have control over the data flows with different configurations using multiple sources/channels/sinks (explained later in the article). So, to add flexibility and scalability, a Flume system might be needed.
Features of Apache Flume
Next, let us understand the important features of Apache Flume.
1. Scalability: It is horizontally scalable as it is possible to have multiple sources & channels and multiple Flume agents to transport data to multiple sinks depending on the data processing needs.
2. Performance: It is a robust, fault-tolerant, and highly available service.
3. Latency: It provides high throughput with lower latency.
4. Reliable message delivery: Since Apache Flume performs channel-based transactions, two transactions per message (one for the sender and the other for the receiver) ensure reliable message delivery.
5. Fault-tolerant: Flume is an extensible, reliable, highly available distributed system that provides tunable reliability mechanisms for fail-over and recovery.
6. Data Flow: It supports complex data flows such as multi-hop flows, fan-in flows, fan-out flows, contextual routing, etc.
7. Ease of use: With Flume, we can ingest the stream data from multiple web servers and store them in any of the centralized stores such as HBase, Hadoop HDFS, etc.
8. Imported Data Size: It can efficiently ingest log data into a centralized repository from various servers. It allows importing large volumes of data generated by social networking sites and e-commerce sites into HDFS.
9. Support for varieties of Sources and Sinks: It supports a wide range of sources and sinks.
10. Streaming: Using Flume, we can collect data from online streaming data from different sources (email messages, network traffic, log files, social media, etc.) in real-time as well as in batch mode and transport it to HDFS.
11. Economical: Being an open-source tool, Apache Flume is an inexpensive system that is less costly to install, operate and maintain.
Apache Flume Architecture
Apache Flume’s architecture is simple and versatile. The following diagram depicts Apache Flume architecture.
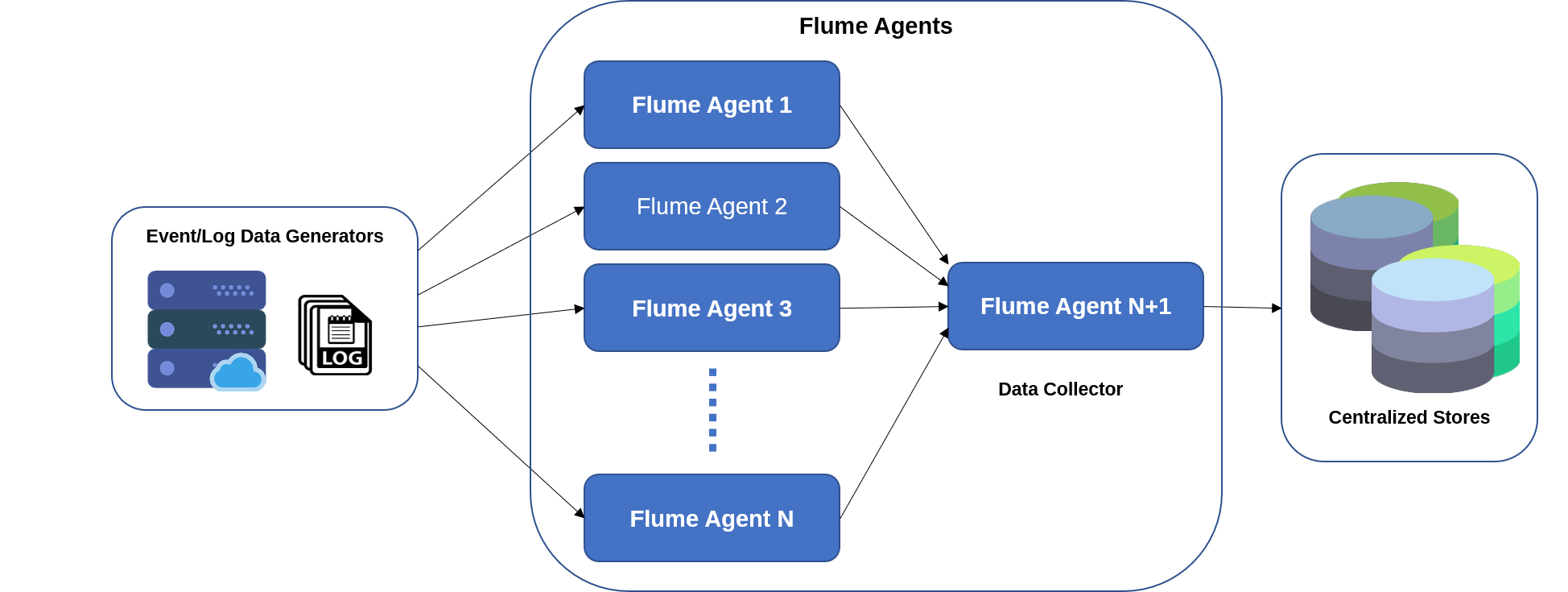
As seen in the figure above, the event/log data generators create massive amounts of data collected by individual agents (Flume agents) that run on them. As explained in the previous section, these data generators could be Facebook, Twitter, e-commerce sites, and various other external sources. A data collector is also a Flume agent which gathers data from all the agents, aggregates it, and then pushes it to a centralized repository like HBase or HDFS.
Now, we will understand what the entities in the Flume architecture are.
1. Flume Event: A Flume event can be termed as the fundamental data unit that must be moved from source to destination (sink).
2. Flume Agent: In Apache Flume, the Flume agent is an independent JVM (Java Virtual Machine) process. A Flume agent is the most basic unit of Flume deployment. One Flume agent can be linked to one or more additional agents. An agent can also receive data from one or more other agents. A data flow is produced by linking many Flume agents to one another. Each Flume Agent consists of three main components – source, channel, and sink.

Flume Agent
3. Source: A source receives data sent by the data generators. It pushes the received data in the form of events to one or more channels. Apache Flume supports various sources like Exec source, Thrift source, Avro source, etc.
4. Channel: A channel acts as a transient store as it accepts data or events from a source and then buffers this data until the sinks consume it. Apache Flume supports several channel types like memory, file system, JDBC, etc.
5. Sink: A sink is a component that consumes data from the channel and stores it in the destination. It can be a centralized store for the data or other flume agents. An example of a sink could be HDFS.
Additional Components of a Flume Agent
Other than the ones mentioned above, a few more components are involved in transferring the events. They are-
Interceptors: They are used to modify or examine flume events between the flume source and channel.
Channel Selectors: When numerous channels are available for data transport, channel selectors decide which channel to use. There are two kinds of channel selectors: default and multiplexing.
Sink Processors: The Sink Processors call a specific sink from a set of sinks.
Data Flow in Apache Flume
Apache Flume helps in moving the log data into HDFS and supports complex data flow. Three main types of data flow in Apache Flume are –
1. Multi-hop Flow: In a Multi-hop Flow, there can be multiple Flume agents. Before reaching the final destination, the flume event moves through more than one flume agent.

2. Fan-out Flow: In a Fan-out Flow, the data moves from one flume source to multiple channels and is held in multiple sinks. This type of flow is of two types − replicating and multiplexing.
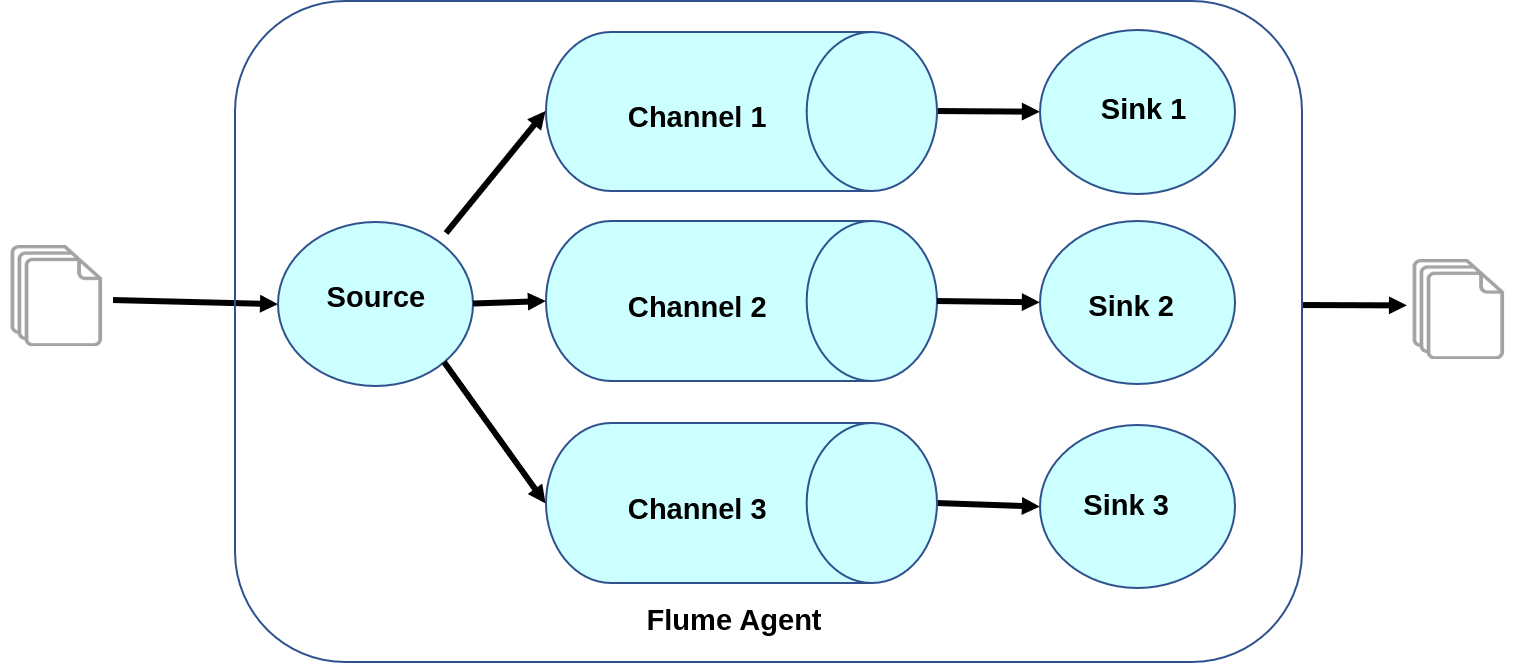
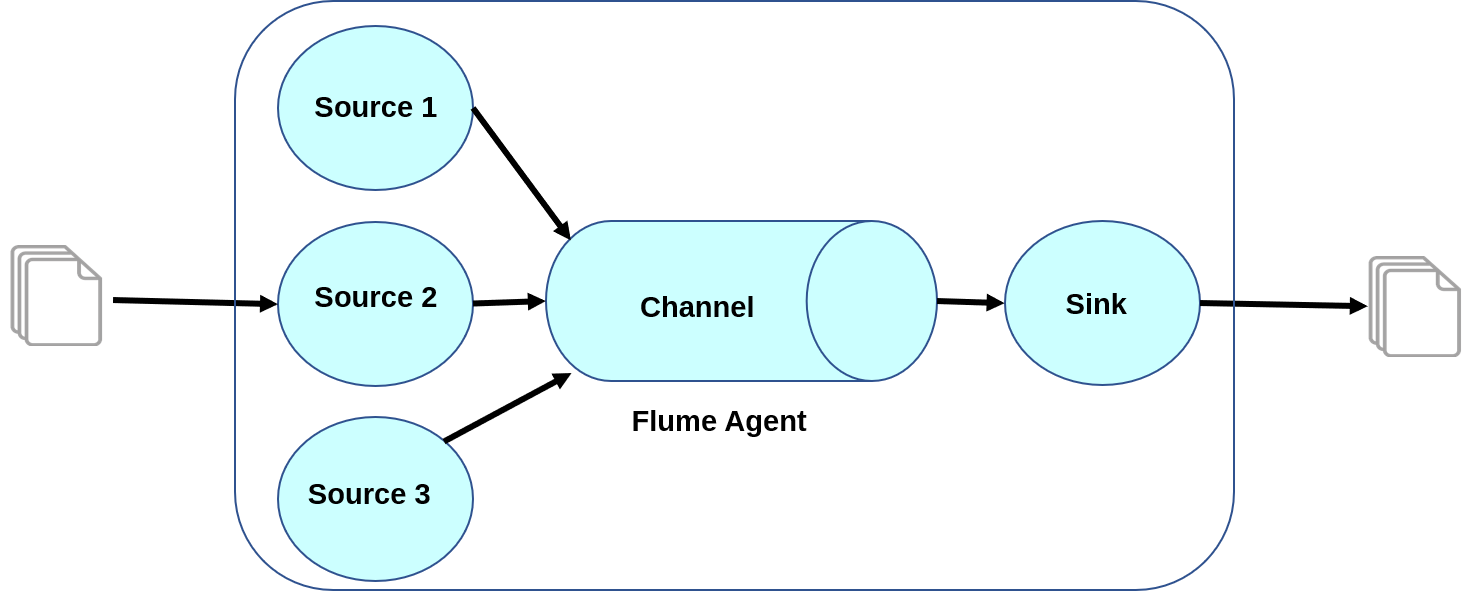
3. Fan-in Flow: The data flow occurs from more than one source to a single channel in a fan-in flow.
Pros of Apache Flume
Apache Flume offers several advantages like-
- It enables us to store streaming data into any of the centralized repositories (HBase/HDFS).
- It provides steady data flow between producer and consumer during reading2/write operations.
- It supports the feature of contextual routing.
- It guarantees reliable message delivery.
- It is reliable, scalable, extensible, fault-tolerant, manageable, and customizable.
Cons of Apache Flume
Though Apache Flume offers several benefits, it still has some drawbacks like-
- It offers weaker ordering guarantees for queuing messages quickly with cheaper fault tolerance.
- It does not guarantee that the messages reaching are 100% unique, as sometimes duplicate messages may appear.
- It has a complicated structure, and reconfiguring it is difficult.
- Although it is reliable and scalable, sometimes Apache Flume might suffer from scalability and reliability issues.
When should you go for Apache Flume?
The Apache Flume tool is a good fit for the following requirements –
- collecting data from varieties of sources, i.e., from a large number of production servers
- pushing this collected data to storage solutions like HDFS, HBase, etc., or processed further through Spark streaming or Kafka pipelines.
- the data being pushed is unstructured
- The events, i.e., the data captured, are events in real-time where the stream of data is continuous and the volume is reasonably large.
In cases where Flume is not suitable for an application, there are alternatives like Web HDFS or the HBase HTTP API that can be used to write data. Sometimes, there are only a few production servers, and the data is not required to be written in real-time, then Apache Flume is also not a good option. In such cases, it might be better to simply move the data to HDFS via Web HDFS or NFS. Similarly, if the data is relatively small ( a few files of a few GB every few hours), it can be moved to HDFS directly as planning, configuring, and deploying Flume would require more effort.
Let us now look at some important Apache Flume applications.
Apache Flume Applications
Apache Flume can move large amounts of data generated by application servers into HDFS at a higher speed. In addition, here are some specific use cases of Apache Flume –
- It is used in e-commerce to analyze customer behaviour based on locations.
- It is used for banking and financial domains for fraud detection.
- It can be applied for streaming real-time sensor data from IoT devices for IoT applications.
- It can be used to aggregate data generated by machines and sensors for analytics applications.
- It is applicable in monitoring and alerting potential vulnerabilities, i.e., enterprise security solutions (SIEM).
Conclusion
In this article, we learned what Apache Flume is and why we need it? Further, we explored the features, the architecture, the pros and cons of this tool, and real-world applications. Before closing the article, let us revise the essential points related to Apache Flume.
Below are some key takeaways from this article:
- Apache Flume is a part of the Hadoop ecosystem and is mainly used for real-time data ingestion from different web applications into storage like HDFS, HBase, etc.
- Apache Flume reliably collects, aggregates, and transports big data generated from external sources to the central store. These data streams could be log files, Twitter data, network traffic, etc.
- Apache Flume is a highly available and scalable tool. However, it cannot manipulate the data.
- Apache Flume has a variety of applications in different domains like e-commerce, banking, finance, IoT applications, etc.
That’s it! I hope you found this article interesting and informative. You can explore Apache Flume in detail through the official documentation here.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK