

图解 Kafka 生产者初始化核心流程-51CTO.COM
source link: https://developer.51cto.com/article/708525.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
从今天开始我将以「 Kafka 2.7」 版本为主,通过「场景驱动」的方式带大家一点点的对 Kafka 源码进行深度剖析,正式开启 「Kafka的源码之旅」,跟我一起来掌握 Kafka 源码核心架构设计思想吧。
今天这篇我们先来聊聊 Kafka 生产者初始化时用到的核心组件以及发送的核心流程,带你梳理生产者初始化整体的源码分析脉络。
认真读完这篇文章,我相信你会对 Kafka 生产初始化源码有更加深刻的理解。
这篇文章干货很多,希望你可以耐心读完。
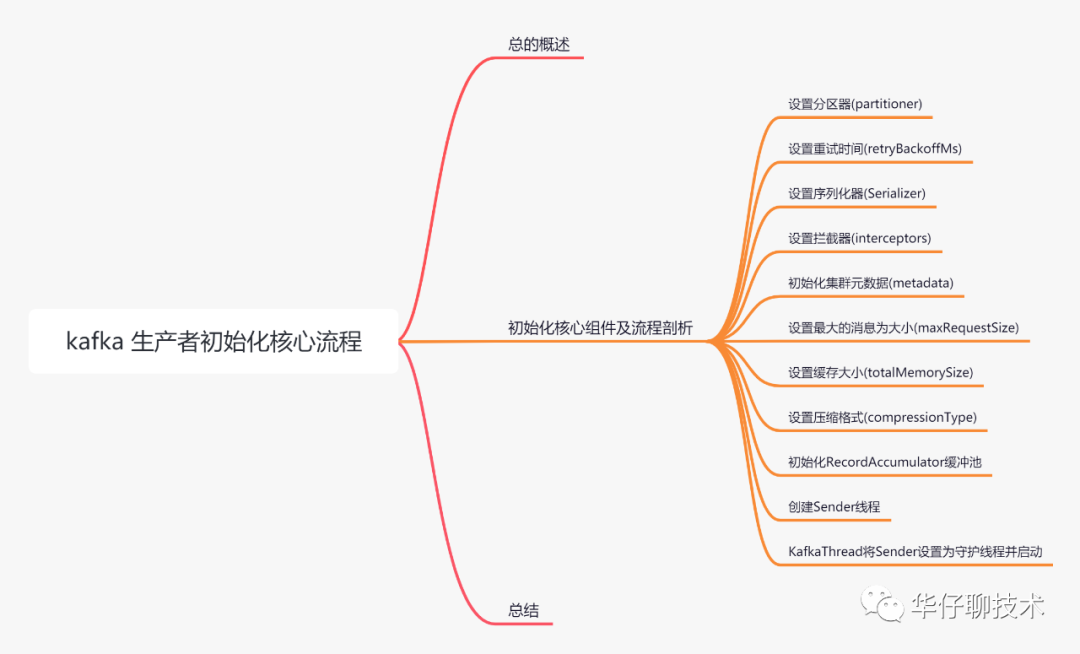
1 总体概述
我们都知道在 Kafka 中,我们把产生消息的一方称为生产者即 Producer,它是 Kafka 核心组件之一,也是消息的来源所在。那么这些生产者产生的消息是如何传到 Kafka 服务端的呢?初始化过程是怎么样的呢?接下来会逐一讲解说明。
2 生产者初始化核心组件及流程剖析
我们先从生产者客户端构造 KafkaProducer开始讲起:
Properties properties = new Properties();
//构造 KafkaProducer
KafkaProducer producer = new KafkaProducer(properties);
//调用send异步回调发送
producer.send(record,new DemoCallBack(record.topic(), record.key(), record.value()));上面代码主要做了2件事情:
1)初始化 KafkaProducer 实例。
2)调用 send 接口发送数据,支持同步和异步回调方式。
待构造完 KafkaProducer 就正式进入生产者源码的入口了,如下图所示:
接下来我们分析一下 KafkaProducer 的源码, 先看下该类里面的「重要字段」:
public class KafkaProducer<K, V> implements Producer<K, V> {
private final Logger log;
private static final String JMX_PREFIX = "kafka.producer";
public static final String NETWORK_THREAD_PREFIX = "kafka-producer-network-thread";
public static final String PRODUCER_METRIC_GROUP_NAME = "producer-metrics";
// 生产者客户端Id
private final String clientId;
// 消息分区器
private final Partitioner partitioner;
// 消息的最大的长度,默认1M,生产环境可以提高到10M
private final int maxRequestSize;
// 发送消息的缓冲区的大小,默认32M
private final long totalMemorySize;
// 集群元数据
private final ProducerMetadata metadata;
// 消息累加器
private final RecordAccumulator accumulator;
// 执行发送消息的类
private final Sender sender;
// 执行发送消息的线程
private final Thread ioThread;
// 消息压缩类型
private final CompressionType compressionType;
// key的序列化器
private final Serializer<K> keySerializer;
// value的序列化器
private final Serializer<V> valueSerializer;
// 生产者客户端参数配置
private final ProducerConfig producerConfig;
// 等待元数据更新的最大时间,默认1分钟
private final long maxBlockTimeMs;
// 生产者拦截器
private final ProducerInterceptors<K, V> interceptors;
// api版本
private final ApiVersions apiVersions;
// 事务管理器
private final TransactionManager transactionManager;
........
}
重要且核心字段含义如下:
1)clientId:生产者客户端的ID。
2)partitioner:消息的分区器,即通过某些算法将消息分配到某一个分区中。
3)maxRequestSize:消息的最大的长度,默认1M,生产环境可以提高到10M。
4)totalMemorySize:发送消息的缓冲区的大小,默认32M。
5)metadata:集群的元数据。
6)accumulator:消息累加器,主要负责缓冲消息。
7)sender:执行发送消息的类,主要负责发送消息。
8)ioThread:执行发送消息的线程,主要负责封装Sender类。
9)compressionType:消息压缩的类型。
10)keySerializer:key的序列化器。
11)valueSerializer:value的序列化器。
12)producerConfig:生产者客户端的配置参数。
13)maxBlockTimeMs:等待元数据更新和缓冲区分配的最长时间,默认1分钟。
14)interceptors:生产者拦截器。主要负责在消息发送前后对消息进行拦截和处理。
接下来我们看下 KafkaProducer 的构造方法,来剖析生产者发送消息的过程中涉及到的「核心组件」。
源码位置:
kafka\clients\src\main\java\org\apache\kafka\clients\producer\KafkaProducer.java 323行
如果有不会安装源码环境的话,可以参考之前的 Kafka源码之旅入门篇。
public class KafkaProducer<K, V> implements Producer<K, V> {
......
KafkaProducer(Map<String, Object> configs,
Serializer<K> keySerializer,
Serializer<V> valueSerializer,
ProducerMetadata metadata,
KafkaClient kafkaClient,
ProducerInterceptors<K, V> interceptors,
Time time) {
// 1.生产者配置初始化
ProducerConfig config = new ProducerConfig(ProducerConfig.appendSerializerToConfig(configs, keySerializer,
valueSerializer));
try {
// 2.获取客户端配置参数
Map<String, Object> userProvidedConfigs = config.originals();
this.producerConfig = config;
this.time = time;
// 3.用于事务传递的TransactionalId,保证会话的可靠性,如果配置表示启用幂等+事务
String transactionalId = (String) userProvidedConfigs.get(ProducerConfig.TRANSACTIONAL_ID_CONFIG);
// 4.设置生产者客户端id
this.clientId = config.getString(ProducerConfig.CLIENT_ID_CONFIG);
LogContext logContext;
// 根据事务id是否配置来记录不同日志
if (transactionalId == null)
logContext = new LogContext(String.format("[Producer clientId=%s] ", clientId));
else
logContext = new LogContext(String.format("[Producer clientId=%s, transactionalId=%s] ", clientId, transactionalId));
log = logContext.logger(KafkaProducer.class);
log.trace("Starting the Kafka producer");
........省略Metrics
// 5.设置对应的分区器
this.partitioner = config.getConfiguredInstance(ProducerConfig.PARTITIONER_CLASS_CONFIG, Partitioner.class);
// 6.失败重试的退避时间,配置参数:retry.backoff.ms 默认100ms
long retryBackoffMs = config.getLong(ProducerConfig.RETRY_BACKOFF_MS_CONFIG);
// 7.定义key、value对应的序列化器
if (keySerializer == null) {
this.keySerializer = config.getConfiguredInstance(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
this.keySerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), true);
} else {
config.ignore(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG);
this.keySerializer = keySerializer;
}
if (valueSerializer == null) {
this.valueSerializer = config.getConfiguredInstance(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
this.valueSerializer.configure(config.originals(Collections.singletonMap(ProducerConfig.CLIENT_ID_CONFIG, clientId)), false);
} else {
config.ignore(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG);
this.valueSerializer = valueSerializer;
}
// load interceptors and make sure they get clientId
userProvidedConfigs.put(ProducerConfig.CLIENT_ID_CONFIG, clientId);
ProducerConfig configWithClientId = new ProducerConfig(userProvidedConfigs, false);
// 8.定义生产者拦截器列表
List<ProducerInterceptor<K, V>> interceptorList = (List) configWithClientId.getConfiguredInstances(
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, ProducerInterceptor.class);
if (interceptors != null)
this.interceptors = interceptors;
else
this.interceptors = new ProducerInterceptors<>(interceptorList);
ClusterResourceListeners clusterResourceListeners = configureClusterResourceListeners(keySerializer,
valueSerializer, interceptorList, reporters);
// 9.设置消息的最大的长度,默认1M,生产环境可以提高到10M
this.maxRequestSize = config.getInt(ProducerConfig.MAX_REQUEST_SIZE_CONFIG);
// 10.设置发送消息的缓冲区的大小,默认32M
this.totalMemorySize = config.getLong(ProducerConfig.BUFFER_MEMORY_CONFIG);
// 11.设置消息压缩类型
this.compressionType = CompressionType.forName(config.getString(ProducerConfig.COMPRESSION_TYPE_CONFIG));
// 12.设置等待元数据更新的最大时间,默认1分钟
this.maxBlockTimeMs = config.getLong(ProducerConfig.MAX_BLOCK_MS_CONFIG);
// 13.设置消息投递的超时时间
int deliveryTimeoutMs = configureDeliveryTimeout(config, log);
this.apiVersions = new ApiVersions();
// 事务管理器
this.transactionManager = configureTransactionState(config, logContext);
....省略,看下面各小节源码
config.logUnused();
AppInfoParser.registerAppInfo(JMX_PREFIX, clientId, metrics, time.milliseconds());
log.debug("Kafka producer started");
} catch (Throwable t) {
// call close methods if internal objects are already constructed this is to prevent resource leak. see KAFKA-2121
close(Duration.ofMillis(0), true);
// now propagate the exception
throw new KafkaException("Failed to construct kafka producer", t);
}
}
}
下面通过一张图来描述 KafkaProducer 的初始化源码过程:
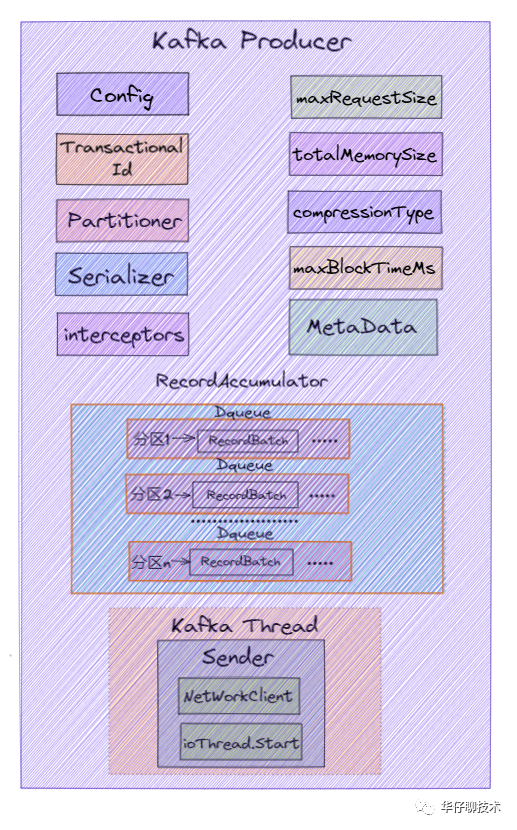
Kafka Producer 初始化核心组件如下:
1)初始化生产者配置(ProducerConfig)。
2)设置客户端配置文件的配置信息(userProvidedConfigs)。
3)设置事务ID(transactionaID)。
4)设置生产者客户端ID(clientId)。
5)设置对应的分区器(partitioner),支持自定义,用来将消息分配给某个主题的某个分区的。
6)设置失败重试的退避时间(retryBackoffMs)。在客户端请求服务端时,可能因为网络或服务端异常造成请求超时。这时请求失败会重试,但是如果重试的频率过高又可能造成服务端网络拥堵。因此必须等一段时间再请求,默认100ms。
7)初始化key的序列化器(keySerializer)和value的序列化器(valueSerializer)。key和value的序列化器是用户在初始化 KafkaProducer 的时候自定义的。
8)设置生产者拦截器(ProducerInterceptor),拦截器的主要作用是按照一定的规则统一对消息进行处理。
9)设置消息的最大的长度(maxRequestSize)。默认是1M,超了会报异常。在生产环境中建议设置为10M。
10)设置发送消息的缓冲区的大小(totalMemorySize),默认是32M。
11)设置消息压缩的类型(compressionType)。默认是none表示不压缩。在消息发送的过程中,为了提升发送消息的吞吐量会把消息进行压缩再发送。
12)设置等待元数据更新和缓冲区分配的最长时间(maxBlockTimeMs),默认60S。
13)设置消息投递超时时间(deliveryTimeoutMs),默认120S。消息投递时间是从发送到收到响应的时间。
我们分析了 KafkaProducer 的核心组件,接下来我们分析下初始化过程中的核心流程。
(1)初始化消息累加器
// 初始化消息累加器---缓冲区
this.accumulator = new RecordAccumulator(logContext,
config.getInt(ProducerConfig.BATCH_SIZE_CONFIG),
this.compressionType,
lingerMs(config),
retryBackoffMs,
deliveryTimeoutMs,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
初始化消息累加器对象「accumulator」,部分重要参数如下:
1)batchSize :消息批次大小,默认16KB;
2)compressionType:消息压缩方式,主要包括none、gzip、snappy、lz4、zstd。默认是不进行压缩,如果你的 Topic 占用的磁盘空间比较多的话,可以考虑启用压缩,以节省资源。
3)lingerMs:消息 batch 延迟多久再发送的时间,这是吞吐量与延时之间的权衡。为了不频繁发送网络请求,设置延迟时间后 batch 会尽量积累更多的消息再发送出去。
4)retryBackoffMs:设置失败重试的退避时间。
5)deliveryTimeoutMs:设置消息投递超时时间。
6)apiVersion:客户端api版本。
7)transactionalManager:事务管理器。
8)BufferPool 分配:后续篇在进行深度剖析。
消息累加器---缓冲区的设计是 Kafka Producer 非常优秀和经典的设计,Kafka 中消息不是生产后立马就发送给服务端的,而是会先写入一个缓冲池中,然后直到多条消息组成了一个 Batch,达到一定条件才会一次网络通信把 Batch 发送过去,利用该设计来避免 JVM 频繁的 Full GC 的问题,后续会单独对其进行深度剖析。
(2)初始化集群元数据
元数据的获取涉及的组件比较多,主要分为:
1)KafkaProducer 主线程负责加载元数据。
2)Sender 子线程负责拉取元数据。
首先我们来看下 KafkaProducer 主线程是如何加载元数据。
元数据「metadata」的初始化的时候是在 KafkaProducer 主线程里面的,源代码如下:
// 初始化 Kafka 集群元数据,元数据会保存到客户端中,并与服务端元数据保持一致
if (metadata != null) {
this.metadata = metadata;
} else {
// 初始化集群元数据
this.metadata = new ProducerMetadata(retryBackoffMs,
// 元数据过期时间:默认5分钟
config.getLong(ProducerConfig.METADATA_MAX_AGE_CONFIG),
// topic最大空闲时间,如果在规定时间没有被访问,将从缓存删除,下次访问时强制获取元数据
config.getLong(ProducerConfig.METADATA_MAX_IDLE_CONFIG),
logContext,
clusterResourceListeners,
Time.SYSTEM);
// 启动metadata的引导程序
this.metadata.bootstrap(addresses);
}它会保存在客户端内存中,并与服务端保持准实时的数据一致性,元数据主要包含:
1)Kafka 集群节点信息。
2)Topic 信息。
3)Topic对应的分区信息
4)ISR列表信息以及分布情况
5)Leader Partition 所在节点
从上面源代码我们可以看出在 KafkaProducer 的构造方法中初始化了元数据类「metadata」,然后调用 「metadata.bootstrap()」来启动引导程序,这个时候 metaData 对象里并没有具体的元数据信息,因为客户端还没发送元数据更新的请求「获取是通过唤醒 Sender 线程进行发送的」。
而具体的发送和拉取,我们将在下一篇中进行剖析。
(3)初始化 Sender 线程
// 初始化 Sender 发送线程类,并同时初始化NetworkClient
this.sender = newSender(logContext, kafkaClient, this.metadata); 这里非常关键,初始化 「Sender」发送线程类,并同时初始化 「NetworkClient」,它为 sender 提供了网络IO的能力,后续我们会对其深度剖析。
(4)ioThread 启用 Sender 线程
String ioThreadName = NETWORK_THREAD_PREFIX + " | " + clientId;
// 用 ioThread 线程来封装 Sender 线程类,使用 demon 守护线程方式来启动 Sender 线程类
this.ioThread = new KafkaThread(ioThreadName, this.sender, true);
this.ioThread.start();
public KafkaThread(final String name, Runnable runnable, boolean daemon) {
super(runnable, name);
configureThread(name, daemon);
}
private void configureThread(final String name, boolean daemon) {
setDaemon(daemon);
setUncaughtExceptionHandler((t, e) -> log.error("Uncaught exception in thread '{}':", name, e));
}从上面源代码可以看出使用「ioThread」线程来封装 「Sender」 线程类,并使用 demon 守护线程方式来启动 Sender 线程类。
这里的设计模式非常值得我们去学习,就是在设计一些后台线程的时候,可以把「线程本身」和「线程执行」的逻辑分开,Sender 线程就是线程执行的具体逻辑,而 KafkaThread 其实代表了这个「线程本身」、「线程的名字」、「未捕获的异常处理」,「deamon 线程设置」。对 KafkaThread 的启动会自动执行 Sender 线程的 Run() 方法。
(5)doSend 发送
用户可以直接使用 「producer.send()」 进行数据的发送,先看一下 「Send()」接口的源码实现。
// 向 topic 异步发送数据,此时回调为空
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {
return send(record, null);
}
// 向 topic 异步地发送数据,当发送确认后唤起回调函数
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}生产环境我们一般会使用带回调函数的方式去发送,所以最终实现还是调用了 KafkaProducer 的 「doSend()」 接口。
该方法只是把消息发送到缓冲区后直接返回,真正的发送是需要等待 Sender 线程把消息从缓冲区将消息取出来后再进行发送。
源码比较长,这里只简单的分析下都做了哪些事情,后续再进行深度剖析,源码如下:
private Future<RecordMetadata> doSend(ProducerRecord<K, V> record, Callback callback) {
TopicPartition tp = null;
try {
....省略
// 1.等待元数据更新即确认数据要发送到的 topic 的 metadata 是可用的
clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), nowMs, maxBlockTimeMs);
....省略
// 2.序列化 record的key和value
byte[] serializedKey;
serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key());
byte[] serializedValue;
serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value());
// 3.获取record消息对应的分区
int partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
....省略
// 4.验证消息的大小
ensureValidRecordSize(serializedSize);
// 5.组装回调方法和拦截器为一个对象
Callback interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
....省略
// 6.向 accumulator 中追加数据
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, true, nowMs);
// 7.新的批次需要重新进行分区
if (result.abortForNewBatch) {
int prevPartition = partition;
partitioner.onNewBatch(record.topic(), cluster, prevPartition);
partition = partition(record, serializedKey, serializedValue, cluster);
tp = new TopicPartition(record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
interceptCallback = new InterceptorCallback<>(callback, this.interceptors, tp);
result = accumulator.append(tp, timestamp, serializedKey,
serializedValue, headers, interceptCallback, remainingWaitMs, false, nowMs);
}
// 8.如果 batch 已经满了, 则唤醒 sender 线程发送数据
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
} catch (ApiException e) {
....省略
return new FutureFailure(e);
} catch (InterruptedException e) {
....省略
throw new InterruptException(e);
} catch (KafkaException e) {
....省略
throw e;
} catch (Exception e) {
....省略
throw e;
}
}(6)整体发送流程
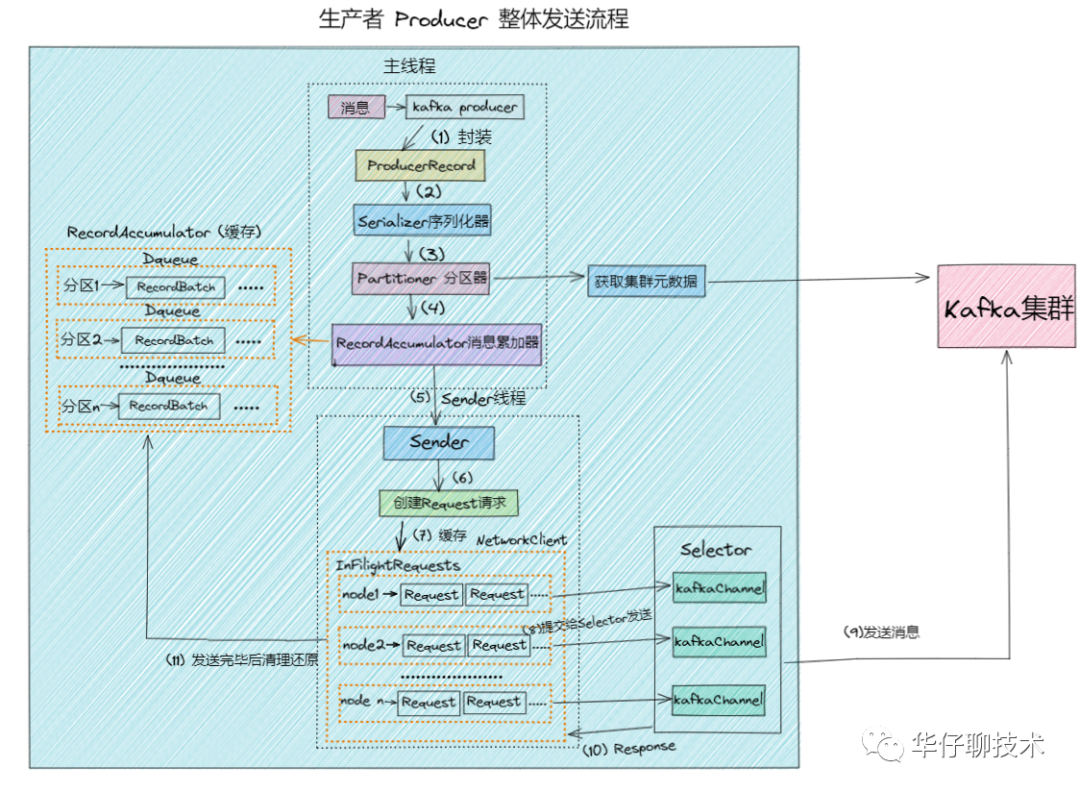
03 总结
这里,我们一起来总结一下这篇文章的重点。
1、通过「场景驱动」的方式从生产者调用出发,抛出初始化和发送的过程是怎样的?
2、带你梳理了「Kafka Producer 初始化源码全貌」,包含主线程的核心组件模块以及消息累加器的初始化、元数据初始化、 Sender 线程初始化流程。
3、最后通过一张整体发送流程图来勾勒出生产者发送消息的全貌。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK