
5

降级利器-Hystrix
source link: https://fishermartyn.github.io/blog/hystrix/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

降级利器-Hystrix
![]() By fisherMartyn
2016-11-07
By fisherMartyn
2016-11-07
在分布式环境下,服务之间有大量的依赖,单个依赖故障时的容灾是个很重要的话题。
相似的话题包括:SOA柔性架构、分布式系统高可用、高可用系统故障处理。
个人理解主要解决三个方面的问题:
- 非核心依赖故障时,系统应该提供有损的服务。
- 核心依赖故障时,系统不应该被拖垮。
- 核心依赖问题恢复后,系统应该尽快恢复。
这里介绍下Hystrix,以介绍一些主要的思想、核心的设计思路为主,具体的使用请阅读文档5遍,深入的也可以分析代码。
99.99^30 = 99.7% uptime
如果一个服务依赖30个子服务,子服务都是4个9的可用性,那么该服务可用性为2个9.
0.3% of 1 billion requests = 3,000,000 failures
从请求数量上讲,一亿次请求中如果有0.3%的失败,失败次数是300万。
2+ hours downtime/month even if all dependencies have excellent uptime.
从时间上讲,上述服务相当于每个月有2个小时的不可用时间。
Hystrix的设计原则
- 不允许单个依赖占满Web容器线程池。
- 快速失败(而不是放到队列排队)。
- 提供fallback钩子机制。
- 使用隔离技术(例如熔断器模式)来防止对单个依赖的冲击。
- 实时问题发现,监控、上报、报警。
- 实时的故障恢复。
- 策略对整个client生效,而不仅仅针对网络问题。
- 使用
HystrixCommand或者HystrixObservableCommand封装所有外部系统的调用,并在单独的线程执行(命令模式)。 - 对于超过自定应响应时间阈值的请求,执行timeout。响应时间阈值一般需要设置为略高于该依赖99.5响应时间。
- 对于每个依赖维护一个小的线程池,如果线程池满了,响应会被立即拒绝掉。
- 记录成功、失败(client异常)、超时、线程拒绝等事件。
- 如果依赖错误率超过一定阈值,触发一个熔断器阻止所有请求一段时间。
- 请求失败、拒绝、超时、或者短路时,执行fallback钩子逻辑。
- 近乎实时的指标监控和配置修改。
请求执行流程
- 构建
HystrixCommand或者HystrixObservableCommand对象。前者是用来处理依赖返回单个结果的情况,后者是用来返回Observable。 - 执行处理动作。主要有四种方式:
execute()是阻塞的方式返回单个依赖处理的结果;queue(),返回依赖调用结果的Future对象;observe()和observe()返回多个(或者一个)响应结果的Observable。本质上所有请求都是Observable的实现,只不过execute是queue().get(),而queue()是toObservable().toBlocking().toFuture()。 - 判断请求是否缓存。如果请求缓存开启,命中请求缓存的会直接返回
Observable中的数据。 - 判断是否熔断。每个请求执行时,会判断熔断是否生效,如果熔断失效,则直接走到第8步,返回fallback,否则执行第5步。
- 判断是否资源(线程池、队列、信号量)满了。如果资源已经占满,则不会执行请求,直接走到第8步的fallback。
- 请求执行。执行真正封装的外部依赖指令,发生超时会执行fallback;如果未发生异常并成功返回结果,则进行相应日志和上报。
- 熔断计算。Hystrix维护的熔断计数器进行统计和更新。如果满足熔断条件会进行熔断一段时间,并进行健康检查。
- 执行fallback。综上所述,执行短路的条件包括:运行时异常、熔断开启和线程池资源被占满。
- 返回成功结果。基于不同的调用方式,返回结果。
如何配置熔断
如何部署Hystrix到生成环境并调优:
- 超时时间保留为默认的1s,除非明确知道需要更长时间。
- 线程池保留为默认的10个,除非明确知道需要更多线程。
- 部署到灰度机器、如果正常,全量运行24小时。
- 依赖标准的报警和监控来发现问题。
- 24小时后,根据统计的数据计算熔断所需的最低配置。
- 根据线上dashboard监控实时调整,直到合适。
- 通过监控报警和dashboard监控得知依赖状态修改、继续调整。
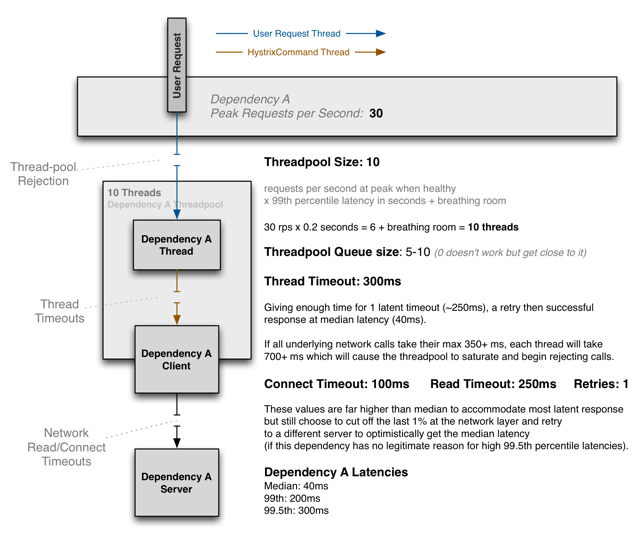
如上图所示:
假设应用平均响应时间40ms,99%响应时间200ms,99.5%响应时间300ms。峰值QPS 30。
- 线程池数量 = 最大QPS x 99响应时间 + 一定余量。这里是30*0.2 + 余量4 = 10。
- 线程池Queue大小:5-10
- 连接超时100ms,读超时250ms,重试一次。该设置远高于平均响应时间,但仍然丢掉了1%的网络抖动问题。给了一次平均响应时间去另外的机器重试。(前提要求是99.5%以上响应时间的请求没有逻辑上的原因)。
- 线程超时时间 = 客户端超时时间 + 一次重试的平均响应时间。这里是250 + 40 约等 300。如果网络调用超过了350ms,加上重试的一次共700ms,则会导致线程池占满、开始拒绝请求。
- Hystrix使用线程池来处理不同的请求、有利有弊,需要自己权衡。核心优点是隔离、核心缺点是会有性能损耗。
- Hystrix支持请求合并(Request Collapsing)和请求缓存(Request Caching)来优化请求。
- Hystrix支持同步调用、异步调用和响应式调用。根据不同的需求调用。
- https://github.com/Netflix/Hystrix/wiki
- http://www.infoq.com/cn/news/2013/01/netflix-hystrix-fault-tolerance
</div
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK