

ProseMirror 编辑器指南中文翻译版
source link: https://keelii.com/2018/12/09/prosemirror-guide-cn/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
这个指南介绍了很多编辑器的设计理念,以及他们之间的关系。想完整的了解整个系统,建议按顺序阅读,或者至少阅读视图组件部分
简介 Introduction
ProseMirror 提供了一组工具和设计概念用来构建富文本编辑器,UI 的使用源于 WYSIWYG 的一些灵感,ProseMirror 试着屏蔽一些排版中的痛点
ProseMirror 的主要原则是:*你的代码对于文档及其事件变更有完整的控制权*。这个 文档 并不是原生的 HTML 文档,而是一个自定义的数据结构,这个数据结构包含了通过你明确允许应该被包含的元素,它们的关系也由你指定。所有的更新都会在一个你可以查看并做出响应的地方进行
核心的代码库并不是一个容易拿来就用的组合 — 我们会优先考虑 模块化 和 可自定义 化胜过简单化,希望将来有用户会基于 ProseMirror 分发一个拿来就用的版本。因此,ProseMirror 更像是乐高积木而不是火柴盒拼的成的玩具车
总共有四个核心模块,任何编辑行为都需要用到它们,还有很多核心团队维护的扩展模块,类似于三方模块 — 它们提供有用的功能,但是你可以删除或者替换成其它实现了相同功能的模块
核心模块分别是:
prosemirror-model定义了编辑器的文档模型,数据结构用来描述编辑器的内容prosemirror-state提供了整个编辑器状态的数据结构,包括选区和维护状态变化的事务系统prosemirror-view实现一个用户界面组件,用来在浏览器中把编辑器的状态展示成可编辑元素,并且与其进行交互prosemirror-transform包含了一种可以记录/重放文档修改历史的功能组件,这是state模块中事务的基础,而且这还使得编辑器的恢复历史和协作编辑功能成为可能
此外,还有一些诸如 基础的编辑命令、快捷键绑定、恢复历史、输入宏、协作编辑,简单的文档骨架 的模块。Github prosemirror 组织 代码库中还有更多
事实上 ProseMirror 并没有分发一个独立的浏览器可以加载的脚本,这表示你可能需要一些模块 bunder 来配合使用它。模块 Bunder 就是一个工具,用来自动化查找你的脚本依赖,然后合并到一个单独文件中,使你能很容易的在 web 面页中使用。你可以阅读更多关于 bundling 的东西,比如:这里
我的第一个编辑器 My first editor
就像拼乐高积木一样,下面的代码可以创建一个最小化的编辑器:
import {schema} from "prosemirror-schema-basic"
import {EditorState} from "prosemirror-state"
import {EditorView} from "prosemirror-view"
let state = EditorState.create({schema})
let view = new EditorView(document.body, {state})
ProseMirror 需要你为文档指定一个自己觉得合适的骨架(schema),所以上面的代码第一件事情就是引入一个基础骨架模块
接着这个骨架被用来创建一个状态,它将按骨架的定义生成一个空的文档,光标会在文档最开始的地方。最后创建了一个与状态关联的视图,并且插入到 document.body。这将会把状态的文档渲染成一个可编辑的 DOM 节点,并且一旦用户输入内容就会生成一个状态事务(transactions)
现在这个编辑器还没什么用处。比如说当你按下回车键时没有任何反应,因为核心库并不关心回车键应该用来做什么。我们马上就会谈到这一点
事务 Transactions
当用户输入或者与视图交互时,将会生成「状态事务」。这意味着它不仅仅是只修改文档并以这种方式隐式更新其状态。相反,每次更改都会触发一个事务的创建,该事务描述对状态所做的更改,而且它可以被应用于创建一个新状态,随后用这个新状态来更新视图
这些过程都会默认地在后台处理,但是你可以写一个插件来挂载进去,或者通过配置视图的参数。例如,下面的代码添加了一个 dispatchTransaction 属性(props),每当创建一个事务时都会调用它
// (省略了导入代码库)
let state = EditorState.create({schema})
let view = new EditorView(document.body, {
state,
dispatchTransaction(transaction) {
console.log("Document size went from", transaction.before.content.size,
"to", transaction.doc.content.size)
let newState = view.state.apply(transaction)
view.updateState(newState)
}
})
每次状态变化都会经过 updateState,而且每个普通的编辑更新都将通过调度一个事务来触发
插件 Plugins
插件用于以各种方式扩展编辑器和编辑器状态的状态,有的会非常简单,比如 快捷键 插件 — 为键盘输入绑定具体动作;有的会比较复杂,比如 编辑历史 插件 — 通过观察事务并逆序存储来实现撤销历史记录,以防用户想要撤消它们
让我们为编辑器添加这两个插件来获取撤消(undo)/重做(redo)的功能:
// (Omitted repeated imports)
import {undo, redo, history} from "prosemirror-history"
import {keymap} from "prosemirror-keymap"
let state = EditorState.create({
schema,
plugins: [
history(),
keymap({"Mod-z": undo, "Mod-y": redo})
]
})
let view = new EditorView(document.body, {state})
当创建一个状态的时候插件就会被注册(因为插件需要访问状态事务),当这个开启了编辑历史状态的视图被创建时,你将可以通过按 Ctrl-Z 或者 Cmd-Z 来撤消最近的一次变更
命令 Commands
上面示例代码中的 undo 和 redo 变量值是绑定到指定键位的一种叫做 *命令* 的特殊值。大多数编辑动作都是作为可绑定到键的命令编写的,它可以用来挂载到菜单栏,或者直接暴露给用户
prosemirror-commands 包提供了许多基本的编辑命令,其中一些是你可以需要用到的基本的快捷键,比如 回车,删除编辑器中指定的内容
// (Omitted repeated imports)
import {baseKeymap} from "prosemirror-commands"
let state = EditorState.create({
schema,
plugins: [
history(),
keymap({"Mod-z": undo, "Mod-y": redo}),
keymap(baseKeymap)
]
})
let view = new EditorView(document.body, {state})
现在,你已经有了一个算得上可以使用的编辑器了
添加菜单,额外的为特定骨架指定的快捷键绑定 等功能,可以通过查看 prosemirror-example-setup 包了解更多。这个模块提供给你一组插件用来创建一个基础的编辑器,但是就像它的名字一样,只是个例子,并不是生产环境级别的代码库。真正的开发中,你可能会需要替换成自定义的代码来精确实现你想要的功能
内容 Content
一个状态的文档被挂在它的 doc 属性上。这是一个只读的数据结构,用各种级别的节点来表示文档,就像是浏览器的 DOM。一个简单的文档可能会由一个包含了两个「段落」节点,每个「段落」节点又包含一个「文本」节点的「文档」节点构成
当初始化一个状态时,你可以给它一个初始文档。这种情况下,schema 就变成非必传项了,因为 schame 可以从文档中获取
下面我们通过传入一个 DOM 元素 (ID 为 content)做为 DOM parser 的参数初始化一个状态,它将利用 schema 中的信息来解析出对应的节点:
import {DOMParser} from "prosemirror-model"
import {EditorState} from "prosemirror-state"
import {schema} from "prosemirror-schema-basic"
let content = document.getElementById("content")
let state = EditorState.create({
doc: DOMParser.fromSchema(schema).parse(content)
})
文档 Documents
ProseMirror 定义了他自己的一种用来表示文档内容的数据结构。由于文档是构建所有编辑器的核心元素,了解它们的工作原理会对我们很有帮助
结构 Structure
一个 ProseMirror 文档就是一个节点,它包含一个片段,其中可以有一个或者多个子节点
这个和浏览器 DOM 非常相似,浏览器 DOM 是一个递归的树型结构。但是 ProseMirror 的不同点在于它存储内联元素的方式
在 HTML 中,一个段落的标记表示为一个树,就像这个:
<p>This is <strong>strong text with <em>emphasis</em></strong></p>

而在 ProseMirror 中,内联内容被建模为 扁平 的序列,标记作为元数据附加到节点
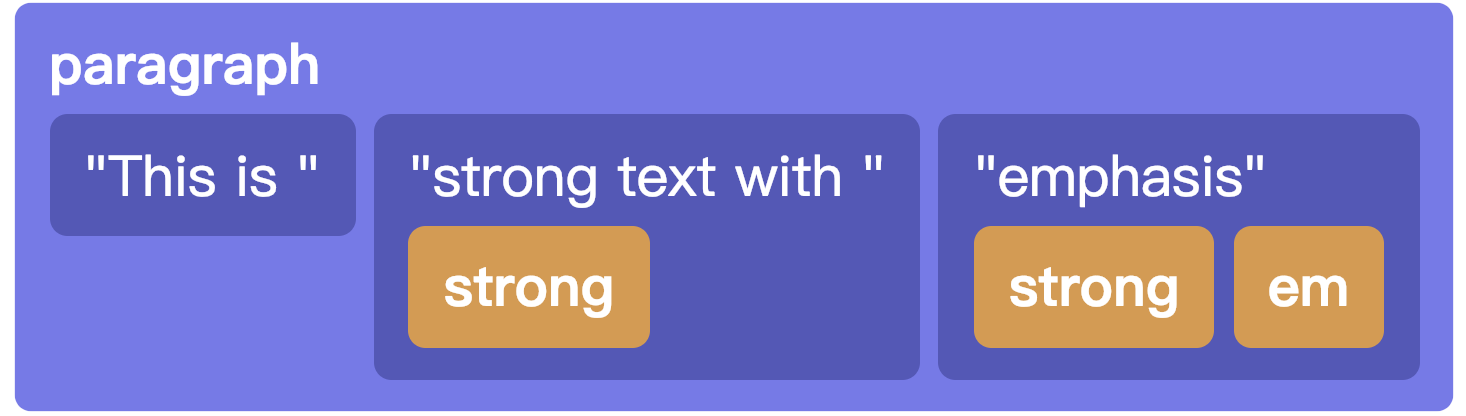
这更符合我们思考和使用此类文本的方式,这允许我们使用字符来表示位置而不是树的路径,这使得一些操作如分割、更改内容样式变得比维护树简单
这也意味着每个文档都只有一种合法的表现层。具有相同标记集的相邻文本节点总是组合在一起,并且不允许有空文本节点,标记出现的顺序由骨架指定
所以说一个 ProseMirror 文档就是一颗块级节点树,其中大多数叶子节点都是文本块,块级节点可以包含这些文本块儿。你也可以有一些空的叶子节点,比如水平分隔线或者视频元素
节点对象有很多属性,它们代表所处文档中的角色:
isBlock和 isInline 告诉你给定的节点是一个块级节点还是内联节点inlineContent表示一个节点希望它的内容是是内联元素isTextblock表示一个块级节点包含内联内容isLeaf告诉你节点不允许有任何内容
典型的「段落」节点是一个文本节点,而「引用块」可能是一个包含其它块级元素的元素。文本、硬换行(
)以及内联图片都是内联叶子节点,水平分隔线节点则是一种块级叶子节点
骨架允许你更准确地指定什么东西应该出现在什么位置,例如。即使一个节点允许块级内容,这并不表示他会允许所有的节点做为它的内容
标识与存储 Identity and persistence
另外一个 DOM 树和 ProseMirror 文档不同的地方是,对象表示节点的行为。在 DOM 中,节点是具有标识的可变的对象,这表示一个节点只能出现在一个父节点中,当节点更新的时候对象也会被修改
另外一方面,在 ProseMirror 中,节点仅仅是一些 *值*,和你想表示数字 3 一样,3 可以同时出现在很多数据结构中,它自己所处的部分与父元素没有连系,如果你给它加 1,你会得到一个新值 4,并且不用改变和原来 3 相关的任何东西
所以它是 ProseMirror 文档的一部分,它们不会更改,但是可以用作计算修改后的文档的起始值。它们也不知道自己处在什么数据结构当中,但可以是多个结构的一部分,甚至多次出现在一个结构中。它们是值,不是状态化的对象
这表示每当你更新文档,你将会获得一个新的文档值。文档值将共享所有子节点,并且不会修改原来的文档值,这使得它创建起来相对廉价
这有很多优点。它可以使两次更新之间的过程无效(严格控制更新的内容和过程),因为具有新文档的新状态可以瞬间转换。它还使得文档以某种数学方式推理变得更容易,相反的如果你的值不断的在后台发生变化这将会很难做到。这也使得协作编辑成为可能,并允许 ProseMirror 通过将最后一个绘制到屏幕的文档与当前文档进行比较来运行非常高效的 DOM 更新算法
由于此类节点使用了常规的 JavaScript 对象来表示,如果并且明确地冻结(freezing)其属性可能会影响到性能,实际上属性是 *可以* 改变的,但是并不建议你这么做,这将会导致程序中断,因为它们几乎总是在多个数据结构之间共享。所以要小心!请注意,这也适用于作为节点对象一部分的数组和普通对象,例如用于存储节点属性的对象或片段中子节点的数组(译注:意思是你最好不要更改类似的内部对象,给对象添加或者删除属性)
数据结构 Data structures
一个文档的对象看起来像这样:
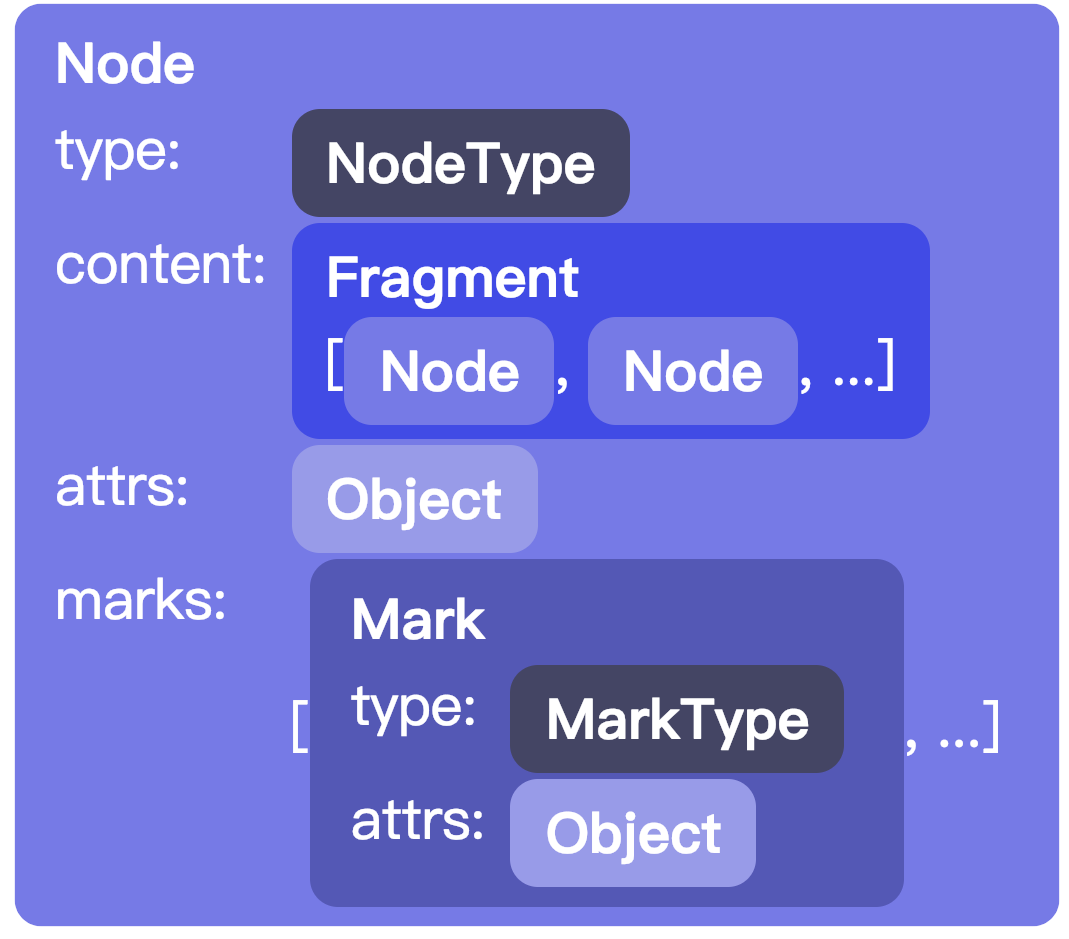
每个节点都是一个 Node 类的实例。都有一个 type 做为标签,通过 type 可以知道节点的名字,节点的属性字段也是有效的等等。节点的类型(和标识类型)每骨架会创建一次,他们知道自己属于骨架的哪个部分
节点的内容存储在 Fragment 的一个实例中,它掌握着节点序列。即使节点没有或者不允许有内容,这个字段也会有值(共享的空 fragment)
一些节点类型允许添加属性,它些值被存储到每个节点上。比如,图片节点一般会使用属性来存储 alt 文本和图片的 URL
此外,内联节点包含一组活动标记 — 例如强调(emphasis)或链接(link)— 活动标记就是一组 Mark 实例
整个文档就是一个节点。文档内容表现为一个顶级节点的子节点。通常,它将包含一系列块节点,其中一些块节点可能是包含内联内容的文本块。但顶级节点本身也可以是文本块,这样的话文档就只包含内联内容
什么样的节点可以被允许,是由文档的骨架决定的。用代码的方式创建节点(而不是直接用基础骨架库),你必须通过骨架来实现,比如使用 node 和 text 方法
import {schema} from "prosemirror-schema-basic"
// 如果需要的话可以把 null 参数替换成你想给节点添加的属性
let doc = schema.node("doc", null, [
schema.node("paragraph", null, [schema.text("One.")]),
schema.node("horizontal_rule"),
schema.node("paragraph", null, [schema.text("Two!")])
])
索引 Indexing
ProseMirror 节点支持两种索引 — 它们可以看做是树,使用单个节点的偏移量,或者它们可以被视为一个扁平的标识(tokens)序列
第一种 允许你执行类似于对 DOM 与单个节点进行操作的交互,使用 child 方法和 childCount 直接访问子节点,编写扫描文档的递归函数(如果你只想查看所有节点,请使用 descendants 或 nodesBetween)
第二种 当访问一个文档中指定的位置时更好用。它允许把文档任意位置表示为一个整数 — 即标记序列中的索引。这些标识并不做为对象在内存中 — 它们仅仅是用来计数的惯例 — 但是文档的树形状以及每个节点都知道它的大小,这使得按位置访问变的廉价(译注:类似于用下标访问扁平数组,而不是递归遍历嵌套结构的树)
- 在第一个内容之前,文档的开头是位置 0
- 进入或离开不是叶子节点的节点(即支持内容)计为一个标识索引位。因此,如果文档以段落开头,则该段落的开头计为位置 1
- 文本节点中的每个字符都算作一个标识索引位。因此,如果文档开头的段落包含单词「hi」,则位置 2 位于「h」之后,位置 3 位于「i」之后,位置 4 位于整个段落之后
- 不允许有内容(例如图像)的叶子节点也算作 单个 标识索引位
因此,如果你有一个文档,当表示为 HTML 时,将如下所示:
<p>One</p>
<blockquote><p>Two<img src="..."></p></blockquote>
标识序列以及位置下标,将会是这样:
0 1 2 3 4 5
<p> O n e </p>
5 6 7 8 9 10 11 12 13
<blockquote> <p> T w o <img> </p> </blockquote>
每个节点都有一个 nodeSize 属性,可以为告诉你整个节点的大小,你可以访问 .content.size 来获取节点 *内容* 的大小。注意,对于外部文档节点,打开和关闭标记不被视为文档的一部分(因为你无法将光标放在文档外面),因此文档的大小为 doc.content.size,而不是 doc.nodeSize
手动解释这样的位置会涉及相当多的计数操作。你可以调用 Node.resolve 来获取关于节点位置的更具有描述性的数据结构。这个数据结构将告诉你该位置的父节点是什么,它与父节点的偏移量是什么,父节点的祖先是什么,以及其他一些东西
注意区分子索引(每个 childCount),文档范围的位置和 node-local 偏移(有时在递归函数中用于表示当前正在处理的节点中的位置)
切片 Slices
为了处理一些诸如复制/粘贴和拖拽之类的操作,通过切片与文档进行通信是非常必要的,比如,两个位置之间的内容。这样的切片不同于整个节点或者片段,一些节点可能位于切片开始或者结束(译注:切片的开始位置可能在某个节点的中间)
例如,从一个段落的中间选择到下一个段落的中间,你所选择的切片中会有两个段落,那么切片的开始位置在第一个段落打开的地方,结束位置就在第二个段落打开的地方。然而如果你 node-select 一个段落,你就选择了一整个有关闭的节点。可能的情况是,如果将此类开放节点中的内容视为节点的完整内容,则会违反骨架约束(标签可能没关闭),因为某些所需节点落在切片之外
Slice 数据结构用于表示这样的切片。它存储一个 fragment 以及两侧的 节点打开深度(open depth)。你可以在节点上使用切片方法从文档外剪切切片
/*
0 1 2 3 4
<p> a b </p>
4 5 6 7 8
<p> a b </p>
*/
// doc holds two paragraphs, containing text "a" and "b"
let slice1 = doc.slice(0, 3) // The first paragraph
/*
0| 1 2 3 |4
<p> a b </p>
*/
console.log(slice1.openStart, slice1.openEnd) // → 0 0
let slice2 = doc.slice(1, 5) // From start of first paragraph
// to end of second
/*
0 1| 2 3 4
<p> a b </p>
4 5|6 7 8
<p> a b </p>
*/
console.log(slice2.openStart, slice2.openEnd) // → 1 1
更改 Changing
由于节点和片段是持久存储的,因此 永远 不要修改它们。如果你有文档(或节点或片段)的句柄,那这个句柄引用的对象将保持不变(译注:这意味着并不能通过拿到的引用直接修改节点,因为这个节点的引用是不可变的值,当你想改变的时候节点可能已经成为历史)
大多数情况下,你将使用转换(transformations)来更新文档,而不必直接接触节点。这些也会留下更改记录,当文档是编辑器状态的一部分时,这是必要的
如果你确实想要「手动」派发更新的文档,那么 Node 和 Fragment 类型上有一些辅助方法可用。要创建整个文档的更新版本,通常需要使用Node.replace,它用一个新的内容切片替换文档的给定范围。要少量地更新节点,可以使用 copy 方法,该方法使用新内容创建类似的节点。Fragments 还有各种更新方法,例如 replaceChild 或 append
骨架 Schemas
每个 ProseMirror 文档都有一个与之关联的骨架,骨架描述了文档中可能出现的节点类型以及它们嵌套的方式。例如,它可能会指定顶级节点可以包含一个或多个块,并且段落节点可以包含任意数量的内联节点,内联节点可以使用任何标记
有一个包含基础骨架的包,但 ProseMirror 的优点在于它允许你定义自己的骨架
节点类型 Node Types
文档中的每个节点都有一个类型,表示其语义和属性,正如其在编辑器中呈现的方式
定义骨架时,可以枚举其中可能出现的节点类型,并使用 spec 对象描述:
const trivialSchema = new Schema({
nodes: {
doc: {content: "paragraph+"},
paragraph: {content: "text*"},
text: {inline: true},
/* ... and so on */
}
})
这段代码定义了一个骨架,其中文档可能包含一个或多个段落,每个段落可以包含任意数量的文本
每个骨架必须至少定义顶级节点类型(默认为名称「doc」,但你可以设置),以及文本内容的(text)类型
注意内联的节点必须使用 inline 属性声明(但对于文本类型,根据定义是内联的,可以省略它)
内容表达式 Content Expressions
上面示例模式中的内容字段(paragraph+, text*)中的字符串称为内容表达式。它们控制子节点的哪些序列对此节点类型有效
例如 paragraph 表示「一个段落」, paragraph+ 表示「一个或者多个段落」。相似地,paragraph* 表示「零个或者更多个段落」, caption? 表示「零个或者一个说明文字」。你可以使用类正则的范围区间,比如 {2} 表示精确的两次,{1, 5} 表示 1~5 次,{2,} 表示 2~更多多次
可以组合这些表达式来创建序列,比如 heading paragraph+ 表示「首先是标题,然后是一个或多个段落」。你也可以使用管道运算符 | 表示两个表达式之间的选择,如 (paragraph|blockquote)+
某些元素类型组将在你的模式中出现多种类型 — 例如,你可能有一个「块」节点的概念,它可能出现在顶层但也嵌套在块引用内。你可以通过为节点规范提供 group 属性来创建节点组,然后在表达式中按名称引用该组
const groupSchema = new Schema({
nodes: {
doc: {content: "block+"},
paragraph: {group: "block", content: "text*"},
blockquote: {group: "block", content: "block+"},
text: {}
}
})
这里的 block+ 相当于 (paragraph | blockquote)+
建议在具有块内容的节点中始终需要至少一个子节点(例如上面示例中的 doc 和 blockquote),因为当节点为空时,浏览器将完全折叠节点,不方便编辑
节点在 or-表达式中的显示顺序非常重要。为非可选节点创建默认实例时,例如,为了确保在替换步骤后文档仍符合模式,将使用表达式中的第一个类型。如果这是一个组,则使用组中的第一个类型(由组成员在节点映射中显示的顺序确定)。如果我在示例骨架中切换 paragraph 和 blockquote 的位置,编辑器尝试创建一个块节点时,你会得到堆栈溢出 - 它会创建一个 blockquote 节点,其内容至少需要一个块,因此它会尝试创建另一个 blockquote 作为内容, 等等
库中的节点操作函数并非每个都会检查它是否正在处理有效的内容 - 高层次的概念,例如 转换(transforms)会,但原始节点创建方法通常不会,而是负责为其调用者提供合理的输入。完全可以使用例如 NodeType.create 来创建具有无效内容的节点。对于在切片边缘 打开 的节点,这甚至是合理的事情。有一个单独的 createChecked 方法,以及一个事后 check 方法,可用于断言给定节点的内容是有效的。
标记 Marks
标记用于向内联内容添加额外样式或其他信息。骨架必须声明允许的所有标记类型。标记类型 是与 节点类型 非常相似的对象,用于标记标记对象并提供其他信息
默认情况下,具有内联内容的节点允许将骨架中定义的所有标记应用于其子项。你可以使用节点规范上的 marks 属性对其进行配置
这有一个简单的骨架,支持段落中文本的 strong 和 emphasis 标记,但不支持标题:
const markSchema = new Schema({
nodes: {
doc: {content: "block+"},
paragraph: {group: "block", content: "text*", marks: "_"},
heading: {group: "block", content: "text*", marks: ""},
text: {inline: true}
},
marks: {
strong: {},
em: {}
}
})
标记集被解释为以空格分隔的标记名称或标记组字符串 — _ 充当通配符,空字符串对应于空集
属性 Attributes
文档骨架还定义了每个节点或标记具有的属性。如果你的节点类型需要存储额外的信息,例如标题节点的级别,那就最好使用属性
属性集可以认为就是普通对象,具有预定义(每个节点或标记)属性集,包含任何 JSON 可序列化值。要指定它允许的属性,请使用节点中的可选 attrs 字段或标记规范
heading: {
content: "text*",
attrs: {level: {default: 1}}
}
在上面的骨架中,标题节点的每个实例都将具有 level 属性。如果不指定,则默认为 1
如果不指定属性默认值,在尝试创建此类节点又不传属性时将引发错误。在满足模式约束条件下进行转换或调用 createAndFill 时,也无法使用库生成此类节点并填充
序列化与解析 Serialization and Parsing
为了能够在浏览器中编辑它们,必须能够在浏览器 DOM 中表示文档节点。最简单的方法是使用 node spec 中的 toDOM 字段包含有关骨架中每个节点的 DOM 表示的信息
该字段应包含一个函数,当以节点作为参数调用时,该函数返回该节点的DOM 结构的描述。这可以是直接 DOM 节点或描述它的数组,例如:
const schema = new Schema({
nodes: {
doc: {content: "paragraph+"},
paragraph: {
content: "text*",
toDOM(node) { return ["p", 0] }
},
text: {}
}
})
表达式 [“p”, 0] 声明了一个段落会被渲染成 HTML <p> 标签。零是一个「孔」用来表示内容被渲染的地方,你还可以在标记名称后面包含具有 HTML 属性的对象,例如:["div", {class: "c"}, 0]。叶节点在其 DOM 表示中不需要「洞」,因为它们没有内容
Mark specs 允许类似于 toDOM 方法,但它们需要渲染成直接包装内容的单个标记,因此内容始终直接在返回的节点中,并且不需要指定「孔」
你可能经常需要从 DOM 数据中 *解析* 文档,例如,当用户将某些内容粘贴或拖动到编辑器中时。模型(Model) 模块具有相应的功能,建议你使用 parseDOM 属性直接在骨架中包含解析信息
这可以列出一个解析规则数组,它描述映射到给定节点或标记的 DOM 结构。例如,基础骨架具有以下表示 emphasis 标记:
parseDOM: [
{tag: "em"}, // Match <em> nodes
{tag: "i"}, // and <i> nodes
{style: "font-style=italic"} // and inline 'font-style: italic'
]
解析规则中标记的值可以是 CSS 选择器,因此你也可以使用 div.myclass 之类的操作。同样,style 属性匹配内联 CSS 样式
当骨架包含 parseDOM 注解时,你可以使用 DOMParser.fromSchema 为其创建DOMParser 对象。这是由编辑器完成的,用于创建默认剪贴板解析器,但你也可以覆写它
文档还带有内置的 JSON 序列化格式。你可以在文档上调用 toJSON 以获取可以安全地传递给 JSON.stringify 的对象,并且骨架对象具有将此表示形式解析回文档的 nodeFromJSON 方法
扩展一个骨架 Extending a schema
传递给 Schema 构造函数的 nodes 和 marks 选项采用了 OrderedMap 对象以及纯 JavaScript 对象。骨架的 spec.nodes 和 spec.marks 属性始终是一组 OrderedMap,可以用作其它骨架的基础
此类映射支持许多方法以方便地创建更新版本。例如,你可以调用 schema.markSpec.remove(“blockquote”) 来派生一组没有 blockquote 节点的节点,然后可以将其作为新骨架的节点字段传入
schema-list 模块导出一个便捷方法,将这些模块导出的节点添加到节点集中
文档转换 Document transformations
转换是 ProseMirror 工作方式的核心。它们构成了事务的基础,转换使得历史追踪和协作编辑成为可能
为什么 Why?
为什么我们不能直接改变文档?或者至少创建一个新版本的文档,然后将其放入编辑器中?
有几个原因。一个是代码清晰度。不可变数据结构确实使得代码更简单。但是,转换系统的主要工作是留下更新的痕迹,以值的形式表示旧版本的文档到新版本所采取的各个步骤
撤消历史记录可以保存这些步骤并反转应用它们以便及时返回(ProseMirror 实现选择性撤消,这比仅回滚到先前状态更复杂)
协作编辑系统将这些步骤发送给其他编辑器,并在必要时重新排序,以便每个人最终都使用相同的文档
更一般地说,编辑器插件能够检查每个更改并对其进行响应是非常有用的,为了保持其自身状态与编辑器的其余状态保持一致
步骤 Steps
对文档的更新会分解为步骤(step)来描述一次更新。通常不需要你直接使用这些,但了解它们的工作方式很有用
例如使用 ReplaceStep 来替换一份文档,或者使用 AddMarkStep 来给指定的范围(Range)添加标记
可以将步骤应用于文档来成新文档
console.log(myDoc.toString()) // → p("hello")
// A step that deletes the content between positions 3 and 5
let step = new ReplaceStep(3, 5, Slice.empty)
let result = step.apply(myDoc)
console.log(result.doc.toString()) // → p("heo")
应用一个步骤是一件相对奇怪的过程 — 它没有做任何巧妙的事情,比如插入节点以保留骨架的约束,或者转换切片以使其适应约束。这意味着应用步骤可能会失败,例如,如果你尝试仅删除节点的打开标记,这会使标记失衡,这对你来说是毫无意义的。这就是为什么 apply 返回一个 result 对象的原因,result 对象包含一个新文档或者一个错误消息
你通常会使用工具函数来生成步骤,这样就不必担心细节
转换 Transforms
一个编辑动作可以产生一个或多个步骤(step)。处理一系列步骤最方便的方法是创建一个 Transform 对象(或者,如果你正在使用整个编辑器状态,则可以使用 Transaction,它是 Transform 的子类)
let tr = new Transform(myDoc)
tr.delete(5, 7) // Delete between position 5 and 7
tr.split(5) // Split the parent node at position 5
console.log(tr.doc.toString()) // The modified document
console.log(tr.steps.length) // → 2
大多数转换方法都返回转换本身,方便链式调用 tr.delete(5,7).split(5)
会有很多关于转换的方法可以使用,删除、替换、添加、删除标记,以及维护树型结构的方法如 分割、合并、包裹等
映射 Mapping
当你对文档进行更改时,指向该文档的指针可能会变成无效或并不是你想要的样子了。例如,如果插入一个字符,那么该字符后面的所有位置都会指向一个旧位置之前的标记。同样,如果删除文档中的所有内容,则指向该内容的所有位置现在都会失效
我们经常需要保留文档更改的位置,例如选区边界。为了解决这个问题,步骤可以为你提供一个字典映射,可以在应用该步骤之前和之后进行转换并且应用应该步骤
let step = new ReplaceStep(4, 6, Slice.empty) // Delete 4-5
let map = step.getMap()
console.log(map.map(8)) // → 6
console.log(map.map(2)) // → 2 (nothing changes before the change)
转换对象会自动对其中的步骤(step)累加一系列的字典,使用一种叫做 映射 的抽象,它收集了一系列的步骤字典来帮助你一次性映射它们
let tr = new Transaction(myDoc)
tr.split(10) // split a node, +2 tokens at 10
tr.delete(2, 5) // -3 tokens at 2
console.log(tr.mapping.map(15)) // → 14
console.log(tr.mapping.map(6)) // → 3
console.log(tr.mapping.map(10)) // → 9
在某些情况下,并不是完全清楚应该将给定位置映射到什么位置。考虑上面示例的最后一行代码。位置 10 恰好指向我们分割节点的地方,插入两个标识。它应该被映射到插入内容后面还是前面?例子中明显是映射到插入内容后面
但是有时候你需要一些其它的行为,这是为什么 map 方法有第二个参数 bias 的原因,你可以设置成 -1 当内容被插入到前面时保持你的位置
console.log(tr.mapping.map(10, -1)) // → 7
Rebasing
当使用步骤和位置映射时,比如实现一个变更追踪的功能,或者给协作编辑符加一些功能,你可能就会遇到使用 rebase 步骤的场景
…(本小节译者并没有完全理解,暂不翻译,有兴趣可以参考原文)
编辑器状态 The editor state
编辑的状态由什么构成?当然,你有自己的文档。还有当前的选区。例如当你需要禁用或启用一个标记但还没在该标记上输入内容时,需要有一种方法来存储当前标记集已更改的情况
一个 ProseMirror 的状态由三个主要的组件构成:doc, selection 和 storedMarks
import {schema} from "prosemirror-schema-basic"
import {EditorState} from "prosemirror-state"
let state = EditorState.create({schema})
console.log(state.doc.toString()) // An empty paragraph
console.log(state.selection.from) // 1, the start of the paragraph
但是插件可能也有存储状态的需求 — 例如,撤消历史记录必须保留其变更记录。这就是为什么所有激活的插件也被存放在状态中的原因,并且这些插件可以用于存储自身状态的槽(slots)
选区 Selection
ProseMirror 支持几种选区类型(并允许三方代码定义新的选区类型)。选区就是 Selection 类的一个实例。就像文档和其它状态相关的值一样,它们是不可变的 — 想改变选区,就得创建一个新的选区对象让新的状态关联它
选区至少包含一个开始(.from)和一个结束(.to)做为当前文档的位置指针。许多选区还区分选区的 anchor(不可移动的)和 head(可移动的),因此这两个属性在每个选区对象上都存在
最常见的选区类型是文本选区(text selection),它用于常规的光标(当 anchor 和 head 一样时)或者选择的文本。文本选区两端必须是内联位置,比如 指向内联内容的节点
核心库同样也支持节点选区(node selections),当一个文档节点被选择,你就能得到它,比如,当你按下 ctrl 或者 cmd 键的同时再用鼠标点击一个节点。这样就会产生一个节点开始到结束的选区
事务 Transactions
在正常的编辑过程中,新状态将从它们之前的状态派生而来。但是某些情况例外,例如 你想要创建一个全新的状态来初化化一个新文档
通过将一个事务应用于现有状态,来生成新状然后进行状态更新。从概念上讲,它们只发生一次:给定旧状态和事务,为状态中的每个组件计算一个新值,并将它们放在一个新的状态值中
let tr = state.tr
console.log(tr.doc.content.size) // 25
tr.insertText("hello") // Replaces selection with 'hello'
let newState = state.apply(tr)
console.log(tr.doc.content.size) // 30
Transaction 是 Transform 的子类,它继承了构建一个文档的方法,即 应用步骤到初始文档中。另外一点,事务会追踪选区和其它状态相关的组件,它提供了一些和选区相关的便捷方法,例如 replaceSelection
创建事务的最简单方法是使用编辑器状态对象上的 tr getter。这将基于当前状态创建一个空事务,然后你可以向其添加步骤和其他更新
默认情况下,旧选区通过每个步骤映射以生成新选区,但可以使用 setSelection 显式设置新选区
let tr = state.tr
console.log(tr.selection.from) // → 10
tr.delete(6, 8)
console.log(tr.selection.from) // → 8 (moved back)
tr.setSelection(TextSelection.create(tr.doc, 3))
console.log(tr.selection.from) // → 3
同样地,在文档或选区更改后会自动清除激活的标记集,并可使用 setStoredMarks 或 ensureMarks 方法设置
最后,scrollIntoView 方法可用于确保在下次绘制状态时,选区内容将滚动到视图中。大多情况下都需要执行此操作
与 Transform 方法一样,许多 Transaction 方法都会返回事务本身,以方便链式调用
插件 Plugins
当创建一个新状态时,你可以指定一个插件数组挂载到上面。这些插件将被应用在这个新状态以及它的派生状态上,这会影响到事务的应用以及基于这个状态的编辑器行为
插件是 Plugin 类的实例,可以用来实现很多功能,最简单的一个例子就是给编辑器视图添加一些属性,例如 处理某些事件。复杂一点的就如添加一个新的状态到编辑器并基于事务更新它
创建一个插件,你可以传入一个对象来指定它的行为:
let myPlugin = new Plugin({
props: {
handleKeyDown(view, event) {
console.log("A key was pressed!")
return false // We did not handle this
}
}
})
let state = EditorState.create({schema, plugins: [myPlugin]})
当一个插件需要他自己的状态槽时,可以定义一个 state 属性:
let transactionCounter = new Plugin({
state: {
init() { return 0 },
apply(tr, value) { return value + 1 }
}
})
function getTransactionCount(state) {
return transactionCounter.getState(state)
}
示例中的插件定义了一个非常简单的状态,它只计算已经应用于某个状态的事务数。辅助函数使用插件的 getState 方法,该方法可用于从编辑器的状态对象中(插件作用域外)获取插件状态
因为编辑器状态是持久化(不可变)的对象,并且插件状态是该对象的一部分,所以插件状态值必须是不可变的。即需要更改,他们的 apply 方法必须返回一个新值,而不是更改旧值,并且其他代码是不可以更改它们的
可对于插件而言向事务添加一些额外信息是非常有用的。例如,撤销历史记录在执行实际撤消时会标记生成的事务,以便在插件可以识别到,而不仅仅是生成一个新事务,将它们添加到撤消堆栈,我们需要单独处理它,从撤消(undo)堆栈中删除顶部项,然后同时将此事务添加到重做(redo)堆栈
为此,事务允许附加元数据(metadata)。我们可以更新我们的事务计数器插件,过滤那些被标记过的事务,如下所示:
let transactionCounter = new Plugin({
state: {
init() { return 0 },
apply(tr, value) {
if (tr.getMeta(transactionCounter)) return value
else return value + 1
}
}
})
function markAsUncounted(tr) {
tr.setMeta(transactionCounter, true)
}
metadata 的属性键可以是字符串,但是要避免命名冲突,建议使用插件对象。有一些属性名库中已经定义过了,比如:addToHistory 可以设置成 false 表示事务不可以被撤消,当处理一个粘贴动作时,编辑器将在事务上设置 paste 属性为 true
视图组件 The view component
ProseMirror 编辑器视图是一个 UI 组件,它向用户显示编辑器状态,并允许它们进
核心视图组件使用的 编辑操作 的定义相当狭义 — 它用来直接处理与编辑器界面的交互,比如 输入、点击、复制、粘贴、拖拽,除此之外就没了。这表示核心视图组件并不支持一些高级一点的功能,像 菜单、快捷键绑定 等。想实现这类功能必须使用插件
可编辑的 DOM Editable DOM
浏览器允许我们指定 DOM 的某些部分是可编辑的,这具有允许我们可以在上面聚焦或者创建选区,并且可以输入内容。视图创建其文档的 DOM 展示(默认情况下使用模式的 toDOM 方法),并使其可编辑。当聚焦到可编辑的元素时,ProseMirror 确保 DOM 选区对应于编辑器状态中的选区
它还会注册很多我DOM在事件处理程序,并将事件转换为适当的事务。例如,粘贴时,粘贴的内容将被解析为 ProseMirror 文档切片,然后插入到文档中
很多事件也会按原生方式触发,然后才会由 ProseMirror 的数据模型重新解释。浏览器很擅长处理光标和选区等问题(当需要两向操作时则变得困难无比),所以大多数与光标相关的键和鼠标操作都由浏览器处理,之后 ProseMirror 会检查当前 DOM 选区对应着什么样的文本选区类型。如果该选区与当前选区不同,则通过调度一次事务来更新选区
甚至像输入这种动作通常都留给浏览器处理,因为干扰它往往会破坏诸如 拼写检查,某些手机上单词自动首字母大写,以及其它一些设配原生的功能。当浏览器更新 DOM 时,编辑器会注意到,并重新解析文档的更改的部分,并将差异转换为一次事务
数据流 Data flow
编辑器视图展示给定的编辑器状态,当发生某些事件时,它会创建一个事务并广播它。然后,这个事务通常用于创建新状态,该状态调用它的 updateState 方法将状态返回给视图
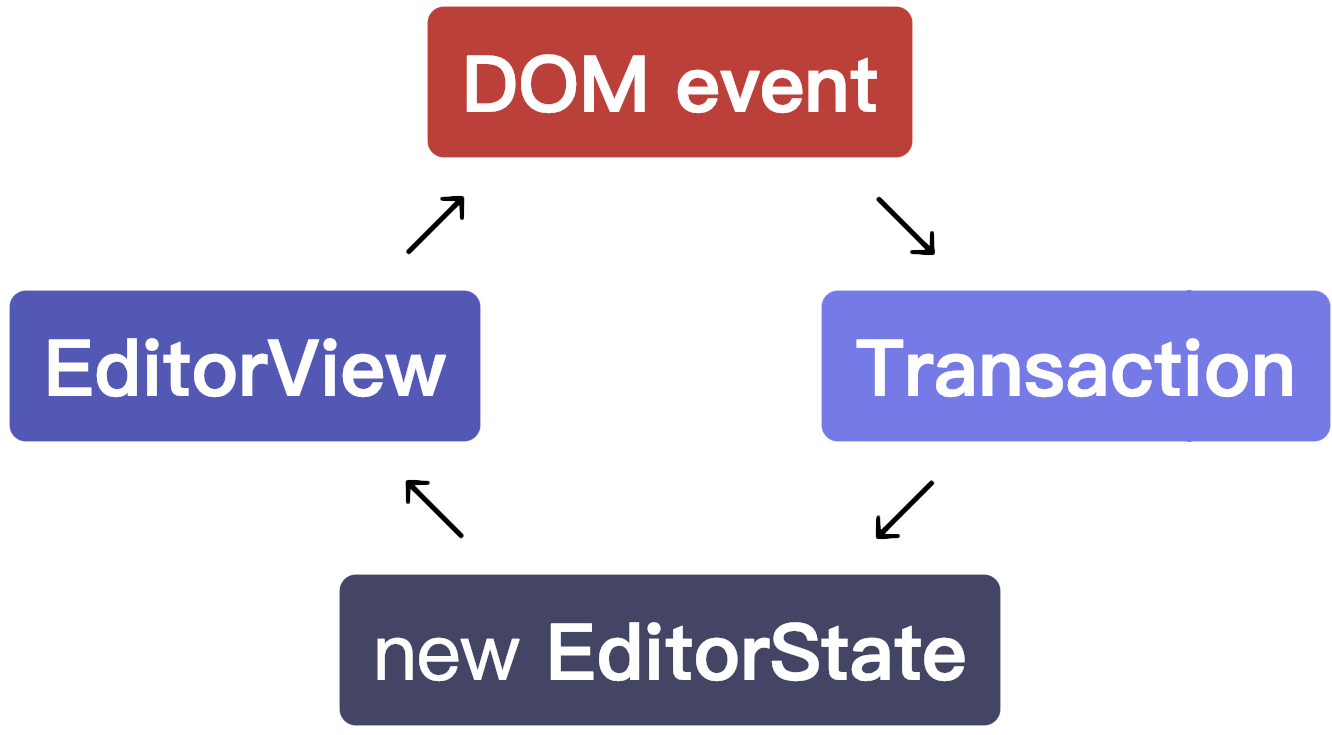
这样就创建了一个简单的循环数据流,在 JavaScript 的世界,通常会立即处理事件处理器(可以理解成命令式的触发事件后直接操作 DOM),后者往往会创建更复杂的数据流网络(数据流可能是双向的,不容易理解与维护)
由于事务是通过 dispatchTransaction 属性来调度的,所以拦载事务是可以的做到的,为了将这个循环数据流连接到一个更大的周期 — 如果你的整个应用程序使用这样的数据流模型,就像类似 Redux 的体系结构一样,你可以使 ProseMirror 的事务与主动作调度(main action-dispatching)周期集成起来,将 ProseMirror 的状态保留在你应用程序的 store 中
// The app's state
let appState = {
editor: EditorState.create({schema}),
score: 0
}
let view = new EditorView(document.body, {
state: appState.editor,
dispatchTransaction(transaction) {
update({type: "EDITOR_TRANSACTION", transaction})
}
})
// A crude app state update function, which takes an update object,
// updates the `appState`, and then refreshes the UI.
function update(event) {
if (event.type == "EDITOR_TRANSACTION")
appState.editor = appState.editor.apply(event.transaction)
else if (event.type == "SCORE_POINT")
appState.score++
draw()
}
// An even cruder drawing function
function draw() {
document.querySelector("#score").textContent = appState.score
view.updateState(appState.editor)
}
高效更新 Efficient updating
一种简单的实现 updateState 的方法是在每次调用文档时重绘文档。但对于大型文档而言,这会变得很慢
由于在更新期间,视图可以访问到旧文档和新文档,可以用它们来做对比,单独保留没发生变化的节点对应的 DOM 部分。 ProseMirror 就是这么做的,这将使得常规的更新动作只需要做很少的工作
在某些情况下,例如 通过浏览器的编辑操作添加到 DOM 的更新文本。确保DOM 和状态一致,根本不需要任何 DOM 更改(当以一个事务被取消,修改时,视图将撤消 DOM 更改以确保 DOM 和状态保持同步)
类似地,DOM 选区仅在实际与状态中的选区不同步时才会更新,这是为了避免破坏浏览器在选区中的各种「隐藏 hidden」状态(例如,当你使用向下或向上箭头空过短行时,你的水平位置会回到你进入下一条长行的位置)
属性 Props
大体上讲 Props 很有用,这是从 React 学过来的。属性就像是 UI 组件中的参数。理想情况下,组件的属性完全定义其行为
let view = new EditorView({
state: myState,
editable() { return false }, // Enables read-only behavior
handleDoubleClick() { console.log("Double click!") }
})
因此,当前的状态就是一个属性。即使一段代码控制了组件并更新某属性,它也不是真正意义上的状态,因为组件 自己 并没有改变它们,updateState 方法也只是更新状态中某个属性的一种简写
插件可以声明除了 state 和 dispatchTransaction 以外的任意属性,它们可以直接传给视图
function maxSizePlugin(max) {
return new Plugin({
props: {
editable(state) { return state.doc.content.size < max }
}
})
}
当一个给定的属性被多次声明时,它的处理方式取决于属性类型。直接传入的的属性优先,然后每个插件按顺序执行。对于一些属性而言,比如 domParser,只会使用第一次声明的值。如果是事件处理函数,可以返回一个布尔值来告诉底层事件系统是否要执行自己的逻辑(比如 事件处理函数反回 false,这表示底层事件上绑定的相同事件处理函数将不会被处理),有的属性,像 attributes 则会做合并然后使用
装饰器 Decorations
装饰使你可以控制视图绘制文档的方式。它们是通过从 装饰器 属性返回值创建的,有三种类型
- 节点装饰器 Node decorations - 将样式或其他 DOM 属性添加到单个节点的 DOM 展示中
- 挂件装饰器 Widget decorations - 在指定位置插入一个 DOM 节点,该节点不是实际文档的一部分
- 内联装饰器 Inline decorations - 添加样式或属性,就像节点装饰器一样,但是会添加到给定范围内的所有内联节点
为了能够有效地绘制和比较装饰器,它们需要作为装饰数组提供(这是一种模仿实际文档的树形数据结构)。你可以使用静态 create 方法创建,提供文档和装饰对象数组
let purplePlugin = new Plugin({
props: {
decorations(state) {
return DecorationSet.create(state.doc, [
Decoration.inline(0, state.doc.content.size, {style: "color: purple"})
])
}
}
})
如果你有很多装饰器,那么每次重新绘制时都要重新创建这些装置成本会很高。这种情况下,维护装饰器的推荐方法是将数组放在插件的状态中,通过更改将其映射到之前的状态,并且只在需要时进行更改
let specklePlugin = new Plugin({
state: {
init(_, {doc}) {
let speckles = []
for (let pos = 1; pos < doc.content.size; pos += 4)
speckles.push(Decoration.inline(pos - 1, pos, {style: "background: yellow"}))
return DecorationSet.create(doc, speckles)
},
apply(tr, set) { return set.map(tr.mapping, tr.doc) }
},
props: {
decorations(state) { return specklePlugin.getState(state) }
}
})
上面的插件将其状态初始化为装饰器数组,该装饰器数组将会执行每 4 个位置添加黄色背景。这个例子可能并不是非常有用,但有点类似于突出显示搜索匹配或注释区域的场景
当事务应用于状态时,插件状态的 apply 方法将装饰器数组向前映射,使装饰器保持原位并「适应」新文档形状。通过利用装饰器数组的树形结构使得映射方法(典型的局部变化)变得高效 - 树形结构中只有变化的部分才会被处理或者重建
在插件的实际使用过程中,apply 方法也可以根据你基于新事件添加或删除装饰的位置而定,或者是通过检测事务中的更新,或基于特定的附加到事务的插件元数据
最后,装饰属性只是返回插件状态,这就导致装饰器会展示在视图中
节点视图 Node views
还有一种方法可以影响编辑器视图绘制文档的方式。节点视图可以为文档中的各个节点定义一种微型的 UI 组件。它们允许你展示 DOM,定义更新方式,并编写自定义代码以及响应事件
let view = new EditorView({
state,
nodeViews: {
image(node) { return new ImageView(node) }
}
})
class ImageView {
constructor(node) {
// The editor will use this as the node's DOM representation
this.dom = document.createElement("img")
this.dom.src = node.attrs.src
this.dom.addEventListener("click", e => {
console.log("You clicked me!")
e.preventDefault()
})
}
stopEvent() { return true }
}
上面的示例为图片节点定义了视图对象,为图像创建了自定义的 DOM 节点,添加了事件处理程序,并使用 stopEvent 方法声明 ProseMirror 应忽略来自该DOM 节点的事件
通常你可能会有与节点交互以影响文档中的实际节点的需求。但是要创建更改节点的事务,首先需要知道该节点的位置。为此,节点视图将传递一个 getter 函数,该函数可用于查询文档中当前节点的位置。让我们修改示例,实现单击节点查询你输入图像的 alt 文本:
let view = new EditorView({
state,
nodeViews: {
image(node, view, getPos) { return new ImageView(node, view, getPos) }
}
})
class ImageView {
constructor(node, view, getPos) {
this.dom = document.createElement("img")
this.dom.src = node.attrs.src
this.dom.alt = node.attrs.alt
this.dom.addEventListener("click", e => {
e.preventDefault()
let alt = prompt("New alt text:", "")
if (alt) view.dispatch(view.state.tr.setNodeMarkup(getPos(), null, {
src: node.attrs.src,
alt
}))
})
}
stopEvent() { return true }
}
setNodeMarkup 是一个方法,可用于更改给定位置的节点的类型或属性集。在示例中,我们使用 getPos 查找图像的当前位置,并使用新的 alt 文本为其提供新的属性对象
节点更新后,默认行为是保持节点外部 DOM 结构不变,并将其子项与新的子元素集进行比较,根据需要更新或替换它们。节点视图可以使用自定义行为覆盖它,这允许我们执行类似于根据内容更改段落类(css class)属性的操作
let view = new EditorView({
state,
nodeViews: {
paragraph(node) { return new ParagraphView(node) }
}
})
class ParagraphView {
constructor(node) {
this.dom = this.contentDOM = document.createElement("p")
if (node.content.size == 0) this.dom.classList.add("empty")
}
update(node) {
if (node.type.name != "paragraph") return false
if (node.content.size > 0) this.dom.classList.remove("empty")
else this.dom.classList.add("empty")
return true
}
}
图片标签不会有子内容,所以在我们之前的例子里,我们并不需要关心它是如何渲染的,但是段落有子内容。Node view 支持两种处理内容的方式:要么你让 ProseMirror 库来管理它,要么完全由你自己来管理。如果你提供一个 contentDOM 属性,ProseMirror 将把节点渲染到这里并处理内容更新。如果你不提供这个属性,内容对于编辑器将变成一个黑盒,内容如何展示如何交互都将取决于你
在这种情况下,我们希望段落内容的行为类似于常规可编辑文本,因此contentDOM 属性被定义为与 dom 属性相同,因为内容需要直接渲染到外部节点中
魔术发生在 update 方法中。首先,该方法负责决定是否可以更新节点视图以显示新节点。此新节点可能是编辑器更新算法尝试绘制的任何内容,因此你必须验证此节点有对应的节点视图来处理它
示例中的 update 方法首先检查新节点是否为段落,如果不是,就退出。然后它确保 empty 类存在或不存在,具体取决于新节点的内容,返回true,则表示更新成功(此时节点的内容将被更新)
命令 Commands
在 ProseMirror 的术语中,命令是实现编辑操作的功能,用户可以通过按某些组合键或与菜单交互来执行命令
出于实际原因考虑,命令的接口稍微有点复杂。一个接收 state 和 dispatch 参数的函数,该函数返回一个布尔值。下面是一个非常简单的例子:
function deleteSelection(state, dispatch) {
if (state.selection.empty) return false
dispatch(state.tr.deleteSelection())
return true
}
当一个命令非正常执行时应该返回 false,表示什么都不会发生。相反如果返正常执行,则应该调度一个事务并且返回 true。确实是这样的,当一个命令被绑定到一个健位并执行时,keymap 插件中对应于这个健位的事件将会被阻止
为了能够查询一个命令对于一个状态下是否具有可执行性(可执行但又不通过执行来验证),dispatch 参数是可选的 — 当命令被调用并且没传入 dispatch 参数时,如果命令具有可执行性,那就应该什么也不做并返回 true
function deleteSelection(state, dispatch) {
if (state.selection.empty) return false
if (dispatch) dispatch(state.tr.deleteSelection())
return true
}
为了能够知道一个选区否可以被删除,你可以调用 deleteSelection(view.state, null),然而如果你想真正执行这个命令就应该这样调 deleteSelection(view.state, view.dispatch)。菜单栏就是用这个来决定菜单按钮的可用性的
这种行式下,命令并不需要访问实际的编辑器视图 — 大多数命令都不需要,这样的话命令就可以在设置中应用和测试而不必关心视图是否可用。但是有的命令则偏偏需要与 DOM 交互 — 可能需要查询指定的位置是否在文本块儿后面,或者打开一个相对于视图定位的对话框。为了解决这种需求,命令还提供了第三个(整个编辑器视图)参数
function blinkView(_state, dispatch, view) {
if (dispatch) {
view.dom.style.background = "yellow"
setTimeout(() => view.dom.style.background = "", 1000)
}
return true
}
上面的例子可能并不是合适,因为命令并没有调度一次事务 — 调用他们可能会产生副作用,所以 *通常* 需要调度一次事务,但是也可能不需要,比如弹出一个层(因为这个层不在编辑器视图里面,并不属于编辑器的状态,所以调度事务就显得多余了)
prosemirror-commands 模块提供了很多编辑器命令,从简单如 deleteSelection 命令到复杂如 joinBackward 命令,后者实现了块级节点的拼合,当你在文本块开始的地方触发 backspace 键的时候就会发生。它也会附加一些基本的快捷键绑定
chainCommands 函数可以合并一系列的命令并执行直到某个命令返回 true
举个例子,基础的快捷键绑定模块中,backspace 会被绑定到一个命令链上:1. deleteSelection 当选区不为空时删除选区;2. joinBackward 当光标在文本块开始的地方时;3. selectNodeBackward 选择选区前的节点,以防骨架中不允许有常规的拼合操作。当这些都不适用时,允许浏览器运行自己的 backspace 行为,这对于清除文本块内容是合理的
命令模块还导出许多命令构造器,例如 toggleMark,它采用标记类型和可选的一组属性,并返回一个命令函数,用于切换当前选区上的标记
其他一些模块也会导出命令函数 — 例如,从 history 模块中 undo 和 redo。要自定义编辑器,或允许用户与自定义文档节点进行交互,你可能还需要编写自定义命令
协作编辑 Collaborative editing
实时协作编辑允许多人同时编辑同一文档。它们所做的更改会立即应用到本地文档,然后发送给对等(pears)方,这些对等方会自动合并这些更改(无需手动解决冲突),以便编辑动作可以不间断地进行,文档也会不断地被合并
这一节将介绍如何给 ProseMirror 嫁接上协作编辑的功能
算法 Algorithm
ProseMirror 的协作编辑使用了一种中央集权式的系统,它会决定哪个变更会被应用。如果两个编辑器同时发生变更,他们两都将带着自己的变更进入系统,系统会接受其中之一,并且广播到其它编辑器中,另外一方的变更将不会被应用,当这个编辑器接收到新的变更时,它将被基于其它编辑器之上执行本地变更的 rebase 操作,然后再次提交更新
权鉴 The Authority
集权式的系统的角色其实是相对简单的,它只须做到以下几点…
- 跟踪当前文档的版本
- 接受编辑器的变更,当变更被应用时,添加到变更列表中
- 当给定一个版本时,提供一种编辑器接受变更的方法
让我们实现一个简单的集权式的系统,它在与编辑器相同的 JavaScript 环境中运行
class Authority {
constructor(doc) {
this.doc = doc
this.steps = []
this.stepClientIDs = []
this.onNewSteps = []
}
receiveSteps(version, steps, clientID) {
if (version != this.steps.length) return
// Apply and accumulate new steps
steps.forEach(step => {
this.doc = step.apply(this.doc).doc
this.steps.push(step)
this.stepClientIDs.push(clientID)
})
// Signal listeners
this.onNewSteps.forEach(function(f) { f() })
}
stepsSince(version) {
return {
steps: this.steps.slice(version),
clientIDs: this.stepClientIDs.slice(version)
}
}
}
当编辑器试着提交他们的变更到系统时,可以调用 receiveSteps 方法,传递他们接收到的最新版本号,同时携带着新的变更及他们自己的 client ID(用来识别变更来自哪里)
当这步骤被接收,客户端就会知道被接收了。因为系统会通知他们新的可用步骤,然后发送给他们自己的步骤。真正的实现中,做为优化项,你也可以调用 receiveSteps 返回一个状态码,然后立即确认发送的步骤,但是这里用到的东西必须要在不可靠的网络环境下保证同步
这种权限的实现保持了一系列不断增长的步骤,其长度表示当前版本
协作模块 The collab Module
collab 模块导出一个 collab 函数,该函数返回一个插件,负责跟踪本地变更,接收远程变更,并对于何时必须将某些内容发送到中央机构做出指示
import {EditorState} from "prosemirror-state"
import {EditorView} from "prosemirror-view"
import {schema} from "prosemirror-schema-basic"
import collab from "prosemirror-collab"
function collabEditor(authority, place) {
let view = new EditorView(place, {
state: EditorState.create({schema, plugins: [collab.collab()]}),
dispatchTransaction(transaction) {
let newState = view.state.apply(transaction)
view.updateState(newState)
let sendable = collab.sendableSteps(newState)
if (sendable)
authority.receiveSteps(sendable.version, sendable.steps,
sendable.clientID)
}
})
authority.onNewSteps.push(function() {
let newData = authority.stepsSince(collab.getVersion(view.state))
view.dispatch(
collab.receiveTransaction(view.state, newData.steps, newData.clientIDs))
})
return view
}
collabEditor 函数创建一个加载了collab 插件的编辑器视图。每当状态更新时,它都会检查是否有任何内容要发送给系统。如果有,就发送
它还注册了一个当新的步骤可用时系统应该调用的函数,并创建一个事务来更新我们的本地编辑器反映这些步骤的状态
当一组步骤被系统拒绝时,它们将一直保持未确认状态,这个时间段应该会比较短,持续到我们从系统收到新的步骤之后。接着,因为 onNewSteps 回调调用 dispatch,dispatch 再调用我们的 dispatchTransaction 函数,代码才会将尝试再次提交其更改
这基本上就是的所有协作模块的功能了。当然,对于异步数据通道(例如上面的演示代码中的长轮询或 Web套接字),你需要更复杂的通信和同步代码,而且你也可能需要集权系统在某些情况下开始抛出步骤,而不至于内存被消耗完。但是这个小例子大概也描述清楚了实现过程
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK