

Matching external companies to LinkedIn’s Economic Graph at scale
source link: https://engineering.linkedin.com/blog/2022/matching-external-companies-to-linkedin-s-economic-graph-at-scal
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Co-authors: Remi Mir, Tianhao Lu, Xiaoqiang Luo, Yunpeng Xu
Introduction
LinkedIn’s Economic Graph is rich with nodes representing different entities, one type of which is organizations. Each organization has an ID and a Company Page on LinkedIn.com. There are multiple business benefits associated with being able to map external organizational records to such LinkedIn pages. For example, say you want to reach out to LinkedIn members who are employees or followers of Microsoft. You can find the organization page on LinkedIn, perhaps with attributes like the name “Microsoft” and website “microsoft.com.” There may even be other attributes, like location, industry, and phone number, that allow you to search with more confidence. Now, what if there are thousands, or even millions, of records with such attributes that we want to find a match for?
This is where Organization Entity Resolution (OER) comes in. It consumes client requests that contain structured organizational attributes, like the ones mentioned in our example. For a given request, OER generates and ranks candidate organization pages using a mixture of machine learning techniques and heuristics that capture business logic. The highest ranked candidate is the one that the model has the most confidence will be a match for the request.
OER is available both offline via Spark and online via a Rest.li service. Offline access means the resolutions are not immediately available, as the volume expected for that setting is typically much larger than what is sent online, for which resolutions are available almost immediately.
Different lines of business at LinkedIn leverage OER to unlock rich insights from organization data and drive economic opportunities for members. Use cases include, but are not limited to:
Account-based advertisement targeting for LinkedIn Marketing Solutions (LMS)
Customer relationship management (CRM) account synchronization for Sales Navigator for LinkedIn Sales Solutions (LSS)
Comma-separated values (CSV) import for LinkedIn Sales Insights (LSI) for LinkedIn Sales Solutions (LSS)
We’ll describe the impact of OER on these use cases, as well as future plans, in this blog post.
Technical approach
Overall pipeline
The task of entity resolution consists of: 1) request handling, 2) candidate retrieval, 3) feature computation, and 4) candidate ranking.
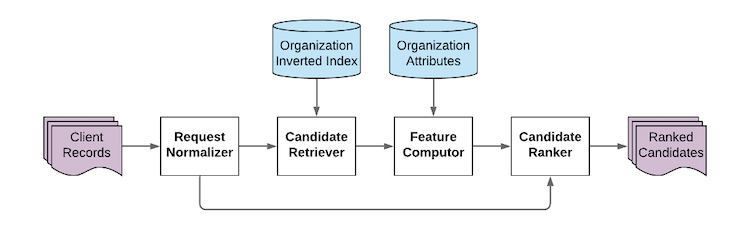
Figure 1. The pipeline for Organization Entity Resolution.
For OER specifically, two data stores (the inverted index and organization attributes) help with candidate retrieval and feature computation steps (Figure 1). To illustrate these concepts, we use a record with the name "Bank of Remi" and website "https://www.bankofremi.com" as an example request sent to the service. In general, each request may have various attributes that can be used by the system:
Request handling
We clean requests, which can be noisy. For example, a request name is stripped of certain punctuation and stop words that can confuse efforts to match the organization. Consider multiple candidates whose names contain a stop word like “Limited.” Stop words do not provide value in identifying the best match and, if considered during the creation of the inverted index, can result in false positives for a request that also contains the stop word in its name. We exclude stop words when building the index and retrieving candidates, as described in more detail in the following section. Stop word removal is also helpful for the purpose of efficiency.
Candidate retrieval
Candidate retrieval is based on keys derived from the organization name and website. For fast lookup, we maintain an inverted index: a store of mappings from keys to organization IDs. This precludes having to compare requests against every organization on LinkedIn.
For the organization name, we use word n-grams as keys in the inverted index. Request normalization, particularly stop word removal, helps reduce the number of keys that are put in the index. For the website, the key is typically the domain (Figure 2). However, we also account for “aggregator” URLs, such as “linkedin.com,” which multiple organizations might use. Consider the example of “https://www.linkedin.com/company/linkedin.” It would require its own entry in the index and is not used for creating the values for the key “linkedin.com.” That’s why the inverted index also contains website keys that go beyond mere domains like “linkedin.com.”
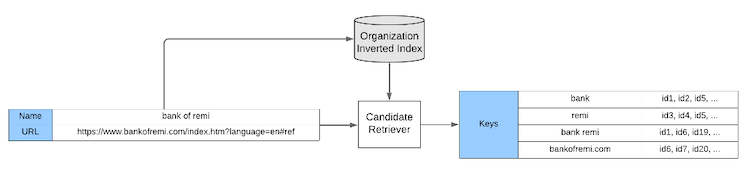
Figure 2. Example of keys produced for a request name and website at retrieval time. Simplified for illustrative purposes.
Each key is mapped to a set of organization IDs. Considering all sources (name and website), there may be hundreds, or even thousands, of candidates for a given request. When taking service latency constraints into consideration for the online setting, our tests determined that it is better to only choose a subset of those candidates based on a few signals, and then pass those to a separate ranker that is designed to take even more signals into consideration.
Because candidates are considered at two “levels,” we call Level 1 (L1) ranking the phase where we select a subset of candidates. At this level, to rank name-based candidates, we use a model that consumes features for string similarity between the request name and the candidate name. For website-based candidates, we simply use a string similarity metric between the request website and the candidate website.
After retrieving the L1 candidates, we remove duplicates, choose the top 10, and pass them to the Level 2 (L2) ranker.
Feature computation and candidate ranking
The organization attributes store maps LinkedIn organization IDs to the attributes of the corresponding organization. For each ID, there are associated names, websites, addresses, industries, page metadata (whether the page has a description, logo, administrator, etc.), and other attributes (Figure 3).
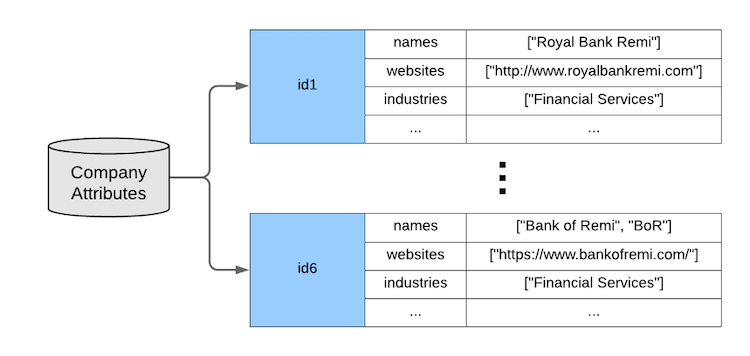
Figure 3. Attributes for organizations. Simplified for illustrative purposes.
For each candidate provided by the L1 ranker in the Candidate Retrieval step, we gather organization attributes from the store. For each request-candidate pair, we use the attributes to calculate multiple features, including name similarity, domain/URL match, industry match, and geographic match. If the candidate has page quality signals, such as a description, logo, or verified page administrator, these signals are used to boost the scores of the candidate. The features are passed to the L2 model, which generates a final score for how likely the candidate is to be a match for the request. The top scoring candidate is consumed by different use cases.
Training and evaluation
Training data comes from LinkedIn CRM and external data vendors. Most ground truth labels are based on manual overrides, which are the result of users changing or assigning organization IDs to CRM accounts. However, some labels are provided by crowdsourced annotation tasks. In other words, CRM users and annotators determine the most appropriate organization page for the given records. For training, the OER system requires positive and negative candidates. Given request names and websites, we generate candidates using the inverted index. Any candidates that match the ground truth labels are marked as positive examples, while the rest are negative examples.
With ~1M examples, we train wide-n-deep and wide-only models (Figure 4). Each has its own advantages for different use cases. Wide-only models are much smaller and contribute less to service latency. Wide-n-deep models are better able to capture semantic similarities of variable-length text attributes, like “industry,” via embeddings. This is helpful in cases where the correct candidate has an industry that may not exactly match the one given in the query (“Banking Services” vs. “Financial Services”).
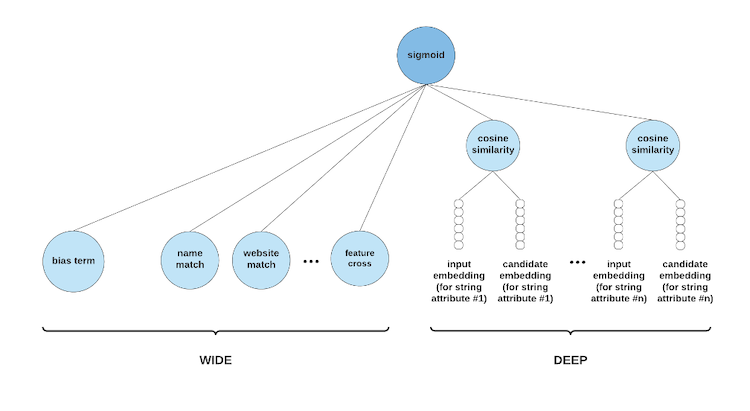
Figure 4. Wide-n-deep architecture for OER. Wide-only models are a subset of the architecture, containing binary match features, string similarity features, and feature crosses (features produced by multiplying different features together). The deep component trains embeddings for request and candidate string attributes like industry.
After training a new model, we can compute scores for candidates. These scores are turned into a ranking by sorting the scores of candidates per request. We compute precision, recall, match rate (the percent of requests that received any matches), and AUC on records that were specifically approved for evaluation purposes. If it demonstrates stable or improved performance, we deploy the model for use in production.
Service reliability
While ML models are a critical component of OER, they are far from being the only part, as illustrated in Overall Pipeline (Figure 1). To monitor the stability of the service overall, we built a data pipeline that generates tracking events for OER service requests (Figure 5).
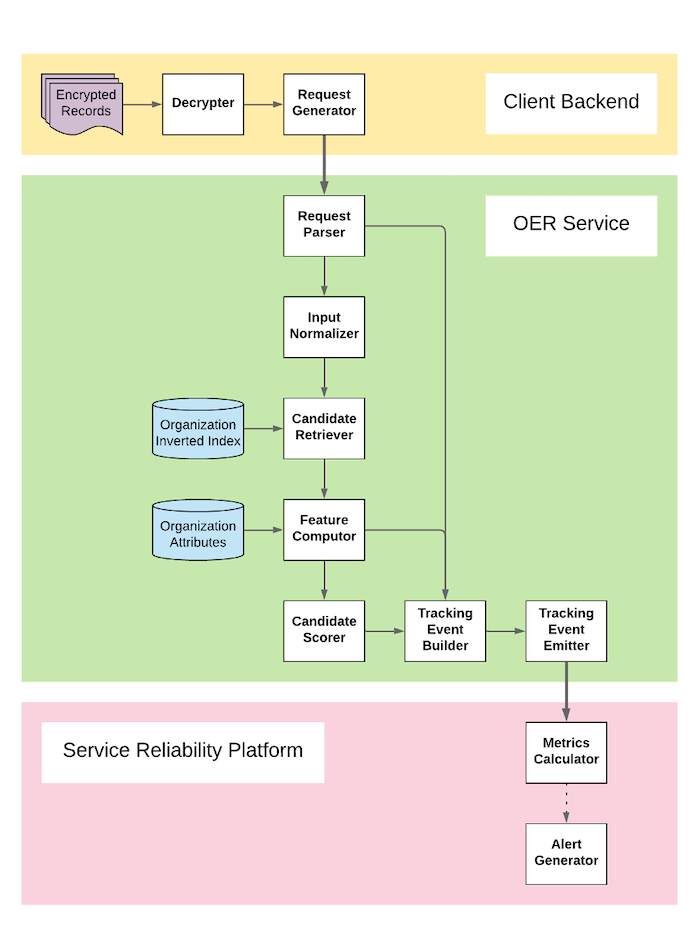
Figure 5. Data pipeline that generates tracking events for OER service requests.
In compliance with data privacy regulations, unless permission is explicitly granted for a use case, the tracking events do not contain the raw data provided in the requests. Each tracking event, however, contains information like the presence of different attributes in the request, computed features, the list of ranked candidates, and model metadata, such as the version used at the time of resolution. Raw data is not recoverable from computed features.
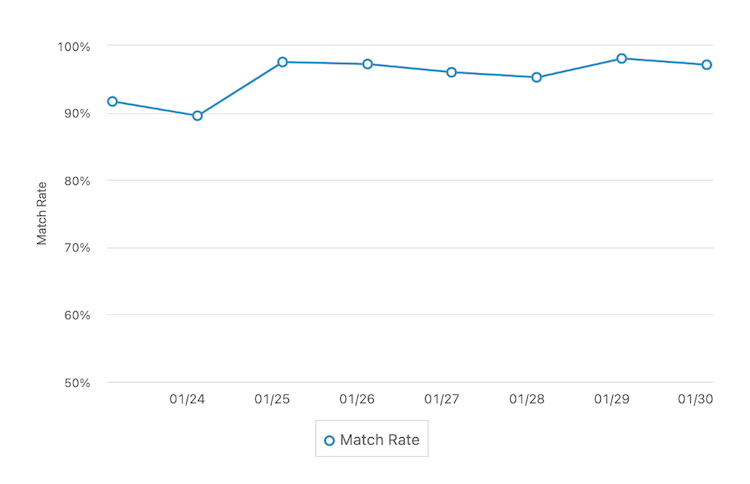
Figure 6. Match rate of the OER service over a week.
Because most traffic lacks ground truth labels, we use tracking events to calculate match rate as one measure of service reliability. On a dashboard, we visualize match rate (Figure 6), as well as score distributions and the breakdown of requests by attribute.
The second measure of service reliability is real-time metrics for large-scale regression tests. If precision or match rate falls past a certain threshold, an alert is triggered. This is critical for identifying potential production issues so that we can investigate and quickly restore the service to a healthy state.
Another aspect of service reliability is stability of the underlying data. Because organization data on LinkedIn is constantly evolving, the inverted index and organization attribute stores are refreshed daily. Using Data Sentinel, we run validations on aspects like data volume and the presence of expected data versions. If any validation fails, it signals that there may be missing or partial data, which would adversely affect system performance. If all validations pass, the new data is published for use by the offline and online services.
Business impact
LSS
CRM Sync
CRM data is critical to Sales Navigator customers in terms of tracking all account and contact interaction history, deal statuses, and business performance. LinkedIn has a feature to allow users to sync their CRM accounts from external tools, like Salesforce and Dynamics 365, to LinkedIn organization pages. This unlocks the opportunity for customers to best explore relevant organization data.
At synchronization time, CRM records are sent to the online OER service, whose top ranked output is displayed to Sales Navigator users. Given that OER systems are not perfect and that there may be delays in record ingestion, users have the option to manually override system results. These overrides can be used to measure model quality: the fewer overrides, the better. Overrides can also augment the training dataset after being fully anonymized, in compliance with data privacy regulations.
LSI CSV import
On LSI, customers can upload CSVs with account (“organization”) names, among other attributes (Figure 7).
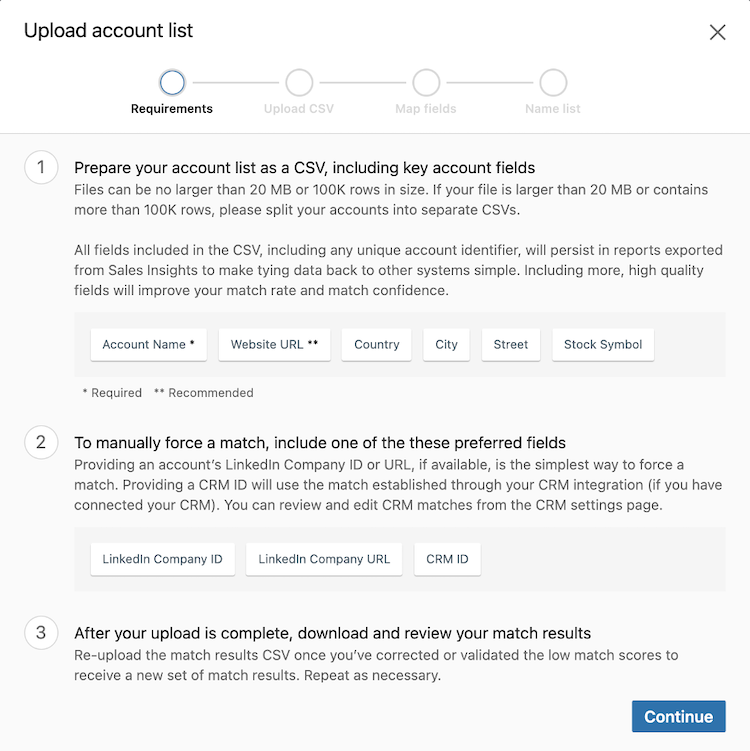
Figure 7. UI for LSI CSV import, a use case of OER.
LSI calls OER to generate matches that can enrich existing client databases and maximize the value that clients derive from LinkedIn data (more on LSI here).
LMS ads targeting
Customers of the LMS platform can upload large lists of target companies. Offline OER powers matching for this Ads Targeting use case. Advertisers can create custom campaign strategies that target LinkedIn members who follow or work at the resolved companies and can further narrow down their audiences based on attributes like industry and location.
Next steps
In this post, we reviewed LinkedIn’s technical approach to OER, as well as its applications in several LinkedIn products.
In the future, we aim to invest more into learning from user feedback data. These signals are useful to collect for training purposes, but require special attention to data privacy regulations, as the data is often encrypted. In addition to reliably de-noising and using such data under encryption settings, we aim to extend our work to more languages for better internationalization.
Acknowledgements
We’d like to thank Tao Xiong for his contributions to OER, Abby Fortin, Kayla Guglielmo, Rupesh Gupta, Dan Melamed, Hannah Sills, and Katherine Vaiente for providing insightful feedback on this post, and our partner teams for using and supporting OER to provide more value to LinkedIn customers.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK