

联邦学习:按混合分布划分Non-IID样本 - orion-orion
source link: https://www.cnblogs.com/orion-orion/p/15991423.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

联邦学习:按混合分布划分Non-IID样本
我们在博文《联邦学习:按病态独立同分布划分Non-IID样本》中学习了联邦学习开山论文[1]中按照病态独立同分布(Pathological Non-IID)划分样本。 在上一篇博文《联邦学习:按Dirichlet分布划分Non-IID样本》中我们也已经提到了按照Dirichlet分布划分联邦学习Non-IID数据集的一种算法。下面让我们来看按Dirichlet分布划分数据集的另外一种变种,即按混合分布划分Non-IID样本,该方法为论文[2]中首次提出。
该论文提出了一个重要的假设,那就是虽然联邦学习每个client的数据是Non-IID,但我们假设它们都来自一个混合分布(混合成分个数为超参数可调):
形象化的展示图片如下:

有了这个假设,那我们相当于假定了每个client数据间的一种相似性,这种相似性类似于从Non-IID中找出潜藏的IID成分。
接下来我们来看这个划分算法的函数如何设计。除了常规Dirichlet划分算法所要求的n_clients、n_classes、αα等, 它还有一个专门的n_clusters参数,表示混合成分个数。我们来看函数原型:
def split_dataset_by_labels(dataset, n_classes, n_clients, n_clusters, alpha, frac, seed=1234):
我们解释一下函数的参数,这里dataset是torch.utils.Dataset类型的数据集,n_classes表示数据集里样本分类数,n_clusters是簇的个数(后面会解释其含义,如果设置为-1,则就默认n_clusters=n_classes,相当于每个client各为一个簇,即放弃了混合分布假设),alpha 用于控制clients之间的数据diversity(多样性),frac是使用数据集的比例(默认是1,即使用全部数据),seed是传入的随机数种子。该函数返回一个由n_client个client所需的样本索引组成的列表组成的列表client_idcs。
接下来我们看这个函数的内容。这个函数的内容可以概括为:先将所有类别分组为n_clusters个簇;再对每个簇c,将样本划分给不同的clients(每个client的样本数量按照dirichlet分布来确定)。
首先,我们判断n_clusters的数量,如果为-1,则默认每一个cluster对应一个数据class:
if n_clusters == -1:
n_clusters = n_classes
然后将打乱后的标签集合{0,1,...,n_classes−1}{0,1,...,n_classes−1}分为n_clusters个独立同分布的簇。
all_labels = list(range(n_classes))
np.random.shuffle(all_labels)
def iid_divide(l, g):
"""
将列表`l`分为`g`个独立同分布的group(其实就是直接划分)
每个group都有 `int(len(l)/g)` 或者 `int(len(l)/g)+1` 个元素
返回由不同的groups组成的列表
"""
num_elems = len(l)
group_size = int(len(l) / g)
num_big_groups = num_elems - g * group_size
num_small_groups = g - num_big_groups
glist = []
for i in range(num_small_groups):
glist.append(l[group_size * i: group_size * (i + 1)])
bi = group_size * num_small_groups
group_size += 1
for i in range(num_big_groups):
glist.append(l[bi + group_size * i:bi + group_size * (i + 1)])
return glist
clusters_labels = iid_divide(all_labels, n_clusters)
然后再建立根据上面划分为簇的标签(clusters_labels)建立key为label, value为簇id(group_idx)的字典,
label2cluster = dict() # maps label to its cluster
for group_idx, labels in enumerate(clusters_labels):
for label in labels:
label2cluster[label] = group_idx
接着获取数据集的索引
data_idcs = list(range(len(dataset)))
之后,我们
# 记录每个cluster大小的向量
clusters_sizes = np.zeros(n_clusters, dtype=int)
# 存储每个cluster对应的数据索引
clusters = {k: [] for k in range(n_clusters)}
for idx in data_idcs:
_, label = dataset[idx]
# 由样本数据的label先找到其cluster的id
group_id = label2cluster[label]
# 再将对应cluster的大小+1
clusters_sizes[group_id] += 1
# 将样本索引加入其cluster对应的列表中
clusters[group_id].append(idx)
# 将每个cluster对应的样本索引列表打乱
for _, cluster in clusters.items():
rng.shuffle(cluster)
接着,我们按照Dirichlet分布设置每一个cluster的样本个数。
# 记录来自每个cluster的client的样本数量
clients_counts = np.zeros((n_clusters, n_clients), dtype=np.int64)
# 遍历每一个cluster
for cluster_id in range(n_clusters):
# 对每个cluster中的每个client赋予一个满足dirichlet分布的权重
weights = np.random.dirichlet(alpha=alpha * np.ones(n_clients))
# np.random.multinomial 表示投掷骰子clusters_sizes[cluster_id]次,落在各client上的权重依次是weights
# 该函数返回落在各client上各多少次,也就对应着各client应该分得的样本数
clients_counts[cluster_id] = np.random.multinomial(clusters_sizes[cluster_id], weights)
# 对每一个cluster上的每一个client的计数次数进行前缀(累加)求和,
# 相当于最终返回的是每一个cluster中按照client进行划分的样本分界点下标
clients_counts = np.cumsum(clients_counts, axis=1)
然后,我们根据每一个cluster中的每一个client分得的样本情况(我们已经得到了每一个cluster中按照client进行划分的样本分界点下标),合并归纳得到每一个client中分得的样本情况。
def split_list_by_idcs(l, idcs):
"""
将列表`l` 划分为长度为 `len(idcs)` 的子列表
第`i`个子列表从下标 `idcs[i]` 到下标`idcs[i+1]`
(从下标0到下标`idcs[0]`的子列表另算)
返回一个由多个子列表组成的列表
"""
res = []
current_index = 0
for index in idcs:
res.append(l[current_index: index])
current_index = index
return res
clients_idcs = [[] for _ in range(n_clients)]
for cluster_id in range(n_clusters):
# cluster_split为一个cluster中按照client划分好的样本
cluster_split = split_list_by_idcs(clusters[cluster_id], clients_counts[cluster_id])
# 将每一个client的样本累加上去
for client_id, idcs in enumerate(cluster_split):
clients_idcs[client_id] += idcs
最后,我们返回每个client对应的样本索引:
return clients_idcs
接下来我们在EMNIST数据集上调用该函数进行测试,并进行可视化呈现。我们设client数量N=10N=10,Dirichlet概率分布的参数向量αα满足αi=0.4, i=1,2,...Nαi=0.4,i=1,2,...N, 混合成分个数为3:
import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
if __name__ == "__main__":
N_CLIENTS = 10
DIRICHLET_ALPHA = 1
N_COMPONENTS = 3
train_data = datasets.EMNIST(root=".", split="byclass", download=True, train=True)
test_data = datasets.EMNIST(root=".", split="byclass", download=True, train=False)
n_channels = 1
input_sz, num_cls = train_data.data[0].shape[0], len(train_data.classes)
train_labels = np.array(train_data.targets)
# 注意每个client不同label的样本数量不同,以此做到Non-IID划分
client_idcs = split_dataset_by_labels(train_data, num_cls, N_CLIENTS, N_COMPONENTS, DIRICHLET_ALPHA)
# 展示不同client的不同label的数据分布
plt.figure(figsize=(20,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=True,
bins=np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), train_data.classes)
plt.legend()
plt.show()
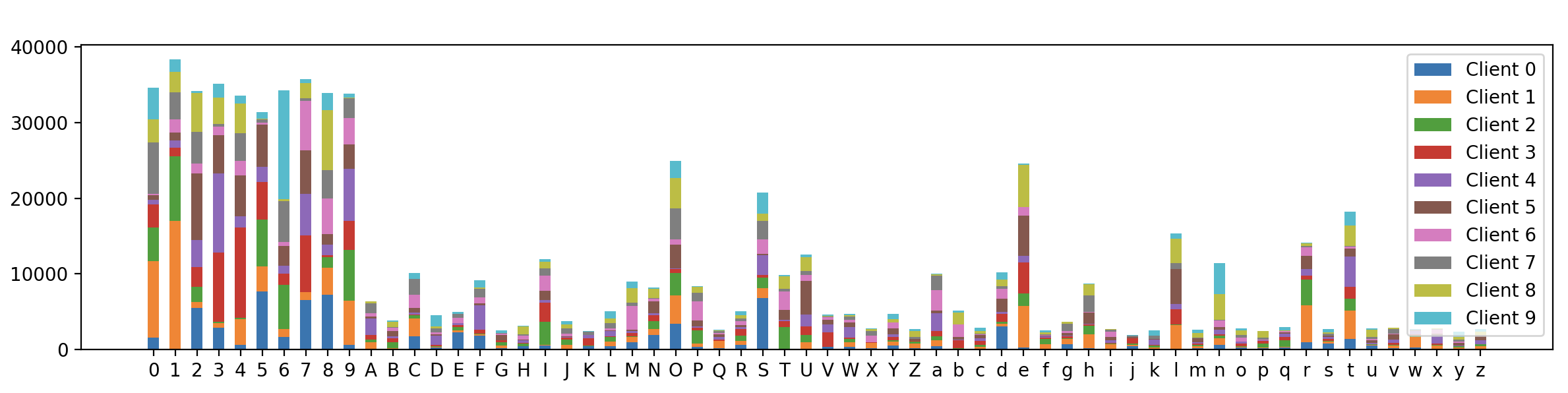
最终的可视化结果如下:

可以看到,62个类别标签在不同client上的分布虽然不同,但相对下面的完全基于Dirichlet的样本划分算法,每个client之间的数据分布显得更加相似,这证明我们的混合分布样本划分算法是有效的。
-
[1] McMahan B, Moore E, Ramage D, et al. Communication-efficient learning of deep networks from decentralized data[C]//Artificial intelligence and statistics. PMLR, 2017: 1273-1282.
-
[2] Marfoq O, Neglia G, Bellet A, et al. Federated multi-task learning under a mixture of distributions[J]. Advances in Neural Information Processing Systems, 2021, 34.
Recommend
-
100
-
59
雷锋网 (公众号:雷锋网) AI 科技评论按: 通常而言,深度学习是典型的数据驱动型技术,面对数据有限的情况,传统的深度学习技术的性能往往不尽如人意。在本届 ICLR 上,许多研究者们利用元学习、迁移学习等...
-
61
本文选择深度学习细分种类下的少样本学习(Few-Sh...
-
11
编者按: 值分布强化学习 ( Distributional Reinforcement Learning )
-
4
看到一篇文章中提到“最近几年国内的初级Android程序员已经很多了,但是中高级的Android技术人才仍然稀缺“,这的确不假,从我在百度所进行的一些面试来看,找一个适合的高级Android工程师的确不容易,一般需要进行大量的面试才能挑选出一个比较满意的。为什么中...
-
4
联邦学习: 联邦场景下的时空数据挖掘 不论你望得多远,仍然有无限的空间在外边,不论你数多久,仍然有无限的时间数不清。——惠特曼...
-
4
1.多视角推荐模型 推荐系统中常常面临冷启动和用户交互数据稀疏的问题。解决这个问题的一个手段就是对用户在多个领域(domain)的日志数据联合起来进行建模,这里的多个领域的数据可以指用户在诸如新闻App、音乐App、视频App等多个软件的日志...
-
7
一. 概率分布概述
-
6
我们在博客《联邦学习:联邦场景下的多源知识图谱嵌入》中介绍了联邦场景下的知识图谱嵌入,现在让我们回顾一下其中关于数据部分的细节。在联邦场景下,C
-
7
使用高斯混合模型拆分多模态分布 作者:Adrian Evensen 2023-09-29 22:31:25 本文介绍如何使用高斯混合模型将一维多模态分布拆分为多个分布。 本文介绍如何使用高斯混合模型将一维多模态分布拆分为多个...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK