

联邦学习:联邦多视角学习在跨领域推荐中的应用 - orion-orion
source link: https://www.cnblogs.com/orion-orion/p/16584365.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

1.多视角推荐模型
推荐系统中常常面临冷启动和用户交互数据稀疏的问题。解决这个问题的一个手段就是对用户在多个领域(domain)的日志数据联合起来进行建模,这里的多个领域的数据可以指用户在诸如新闻App、音乐App、视频App等多个软件的日志数据(比如点击的浏览新闻标题和描述等)。这种联合建模基于一个假设:用户在不同领域也倾向于拥有相似的偏好,比如喜欢爱情电影的用户也很可能喜欢言情小说。
而多视角(multi view)推荐模型[1]就是一种常见的跨领域数据联合建模方式,它会将多个视角对应的特征映射到一个共享的隐空间(latent space)。
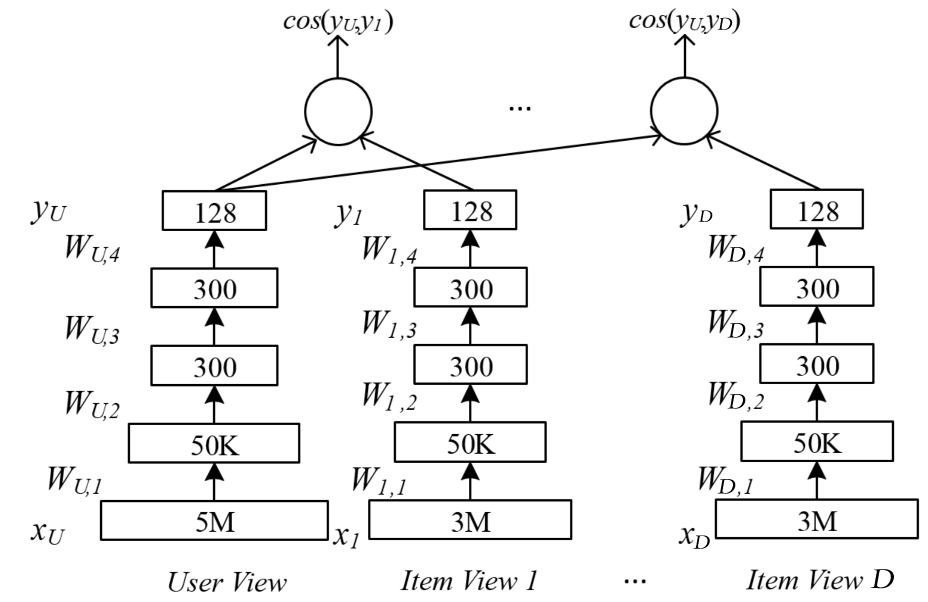
上图展示了对跨领域数据建模的多视角DNN,它基于深度结构化语义模型(Deep Structured Sematic Models, DSSM)的计算最大化用户视角和多个物品视角对应隐向量的相似度,并按照相似度排序来推荐物品。图中的User View对应的特征为用户使用搜索引擎的查询信息,而其他的Item View对应的特征为用户在其它App所点击过的物品特征数据。该模型假定所有领域都对应着共同的用户。它使用了DNN将多个视角对应的高维稀疏特征映射xU,x1,⋯,xD到共享隐空间中的低维稠密特征yU,y1,⋯,yD。
之后可以计算用户隐向量yU和物品隐向量yj(j=1,⋯,D)的语义相似度:
这里假设用户隐向量yU和物品隐向量yj(j=1,⋯,D)相关,然后接下来的目标就是为每个视角都找到一个非线性的映射,以使yU视角和其它物品视角y1,⋯,yD在隐空间的相似度之和最大化:
其中WU,W1,…WD为各个视角对应的权重参数,一共有个N用户-物品对样本和D个物品视角,其中每个物品视角xj都有其单独的输入特征维度dj。
第i个用户-物品对样本拥有一个用户视角的输入特征xi,u和其对应的物品视角特征xi,a,这里a是样本i对应物品视角的索引,样本i对应的其它物品视角的输入xi,j≠a则设为0向量。γ为温度系数。
如上文所述,跨领域推荐本质上是个迁移学习问题,它需要在多个领域异构数据的基础上通过某种“桥梁”(bridge)来提高一个或多个目标域的推荐效果。这里的“桥梁”指不同领域之间的关联项目,比如共同的用户,共同的物品,共同的特征等。上面的多视角DNN模型就假定所有领域都对应着共同的用户。
2. 联邦多视角推荐模型
跨领域推荐在实际应用中常常面临隐私性的挑战,其一是不同用户的数据难以合法地进行集中化收集;其二是其使用的迁移学习模型跨不同的域和数据集进行映射,这常常会关联到不同的组织机构,同样会面临隐私问题[2]。此时上面提到的需要将数据集中起来的多视角学习方法就不再行得通了,需要考虑在联邦场景下的多视角推荐模型。
而联邦场景下的多视角推荐模型根据其隐私保护的出发点不同,可大致分为以下三类:
-
保证用户(client)之间的数据数据不共享,但多视角的数据是打通的(横向)。
-
可以将用户的数据进行集中化收集,但多视角的数据不能共享(纵向)。
-
不仅保证client之间的数据不共享,且多视角的数据也是不能共享的(横向+纵向)。
我个人觉得在保证隐私的条件下进行多视角之间的信息共享(纵向/横向+纵向)是最有意思的,其核心是联邦迁移学习相关的理论:即在隐私保护的前提下,根据不同领域之间的关联来生成共享表示。根据我阅读过的大部分论文来看,如不同领域对应不同的组织机构,则它们的embeddings不能直接进行迁移,需要采取间接的迁移方法。这些方法具体来说就五花八门了,有用GAN来生成带差分隐私保护的共享embeddings的(参见我上一篇博客《联邦学习:联邦场景下的多源知识图谱嵌入》),有用另一个中间视角的数据来训练共享子模型的[4],有用VAE来生成一个独立于所有领域的共享embeddings的[5],有先对数据加以差分隐私保护再用自编码器生成共享embeddings的[6]。可以预见这在未来仍将是个热点。
以下我们分别看下这三类所对应的相关论文,了解一下该领域的大致情况。
3. 论文阅读
3.1 ECML-PKDD 2020《Federated multi-view matrix factorization for personalized recommendations》[3]
这篇论文提出了联邦多视角矩阵分解分解算法,因为其使用的多视角数据不涉及跨组织机构,故只需要保证用户数据不共享即可,属于前面所说的横向类型。具体而言,在传统的矩阵分解算法中,常常只考虑用户-物品矩阵,即所谓共现矩阵R,通过分解该矩阵得到用户的隐向量矩阵P和物品隐向量矩阵Q:
之后再基于用户矩阵P和物品矩阵Q得到用户u对物品i的预估评分:
其中pi是用户i在用户矩阵P中的对应行向量,qj是物品j在物品矩阵Q中的对应行向量。
而所谓多视角矩阵分解,即包括以下三个视角:用户-物品,用户-特征,物品-特征。这三个视角分别对应用户-物品矩阵R∈RNu×Nv,用户特征矩阵X∈RNu×Du,物品特征矩阵Y∈RNv×Dv。这里Nv为用户个数,Nv为物品个数,Du和Dv分别为用户和物品的特征维度。则多视角矩阵分解可表示为如下形式:
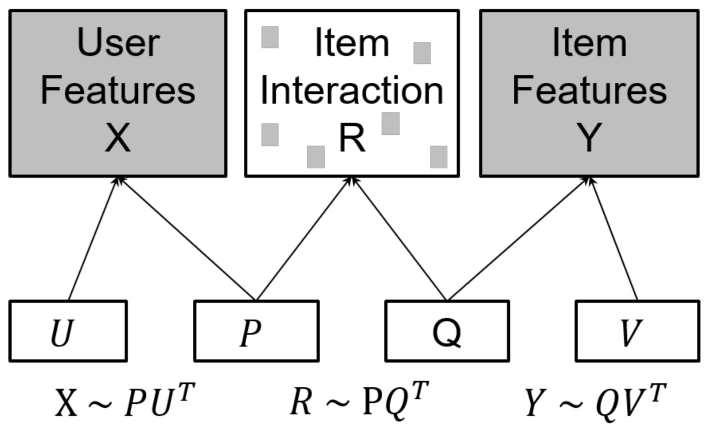
其中P∈RNu×K是用户隐向量矩阵,Q∈RNv×K是物品隐向量矩阵,U∈RDu×K是用户特征隐向量矩阵,V∈RDv×K是物品特征隐向量矩阵,这里K是隐向量维度。
此时所要优化的目标函数可以写为:
这里cij=1+αrij,α是一个表示隐式反馈不确定性的置信参数;λ2是L2正则项;λ1表示用户-物品视角与其它视角间的信息共享强度,若令λ1=0则表示用户-物品视角不与其它视角进行信息共享,0⩽λ1⩽1可以根据数据生成过程的先验知识选择,也可以通过超参数优化来决定。
模型参数P,Q,U,V可以通过交替最小二乘法(Alternating Least Square, ASL)来求解。
下图描述了在联邦场景下用交替最小二乘法求解该问题的算法。

如图所示,用户i和物品的交互信息r(i)(用户i在R中的对应行向量)及用户i的特征向量xi(用户i在X中的对应行向量)只能在client i本地使用。物品的特征矩阵Y存储在item server中。fl server会将Q,U分发给client(用户),并将Q发往item server。
在每个client i,用户的隐向量pi会在本地进行计算,其中会使用到该用户与物品的交互信息r(i)、该用户的特征向量xi与来自server的Q,U。新的用户隐向量p∗i计算公式如下:
之后,client i按照下式计算f(j,i)(用于之后在fl server计算∂J/∂qj以更新Q):
按照下式梯度f(i,du)(用于之后在fl server计算∂J/∂udu以更新U):
上述计算完毕后将f(j,i),f(i,du)发往fl server。
与此同时,在item server,物品特征隐向量矩阵V也会得到更新(其中会用到物品特征),新的物品隐向量v∗dy计算方式如下:
更新完成后,在此基础上计算f(j,dy)(用于之在fl server计算∂J/∂qj以更新Q):
之后再将f(j,dy)发给fl server。
而在fl server接收f(j,i),f(i,du),f(j,dy)后,按照下列两个式子计算梯度并更新Q和U:
然后又将Q和U发往各client,将Q发往item server,以此循环往复。
综上,该篇论文按照损失函数J对多视角数据矩阵R,X,Y共同进行矩阵分解,以学习隐向量矩阵P,Q,U和V,具体算法采用了联邦交替最小二乘法。可以注意到联邦场景下对参数矩阵Q和U进行的更新并不需要对用户数据进行聚合(虽然Q和U的更新依赖于用户数据)。
3.2 FTL-IJCAI21 《A federated multi-view deep learning framework for privacy-preserving recommendations》[4]
上面提到的是基于联邦矩阵分解的推荐模型,而下面要介绍的是联邦场景下基于内容的(content-based)推荐模型,它侧重将用户或者物品的特征信息作为输入特征来建模。具体的模型采用我们第1部分中所叙述的多视角DSSM模型。该模型同时满足了多个client数据的隐私性和单个client中多视角数据的隐私性,属于横向+纵向类型。
不过本文与原始多视角模型中共享用户视角的特征不同,本文共享的是物品视角的特征。设共有C个client,第c个client中的本地数据集表示为Dc={xI,x1,⋯xD}。这里x1,⋯xD(xj∈Rdj)为用户在D个不同App中记录的多视角特征数据,而物品视角数据集xI∈RdI从server下载,比如移动App的后端。DSSM模型将从各个App视角数据集xI,x1,⋯xD和物品数据集xI中分别提取隐向量。算法的目标是为每个视角学得一个非线性映射f(⋅)以使物品视角隐向量和多个用户视角隐向量相似度的和最大化。第c个client的目标定义如下:
这里Nc表示client c中用户-物品对的数量,第i个用户-物品对样本拥有一个物品视角的输入特征xi,I和其对应的用户视角特征xi,a,这里a是样本i对应用户视角的索引。y表示f(⋅)的映射结果,γ是温度参数。
联邦多视角DSSM模型(FL-MV-DSSM)求解算法的架构如下所示:
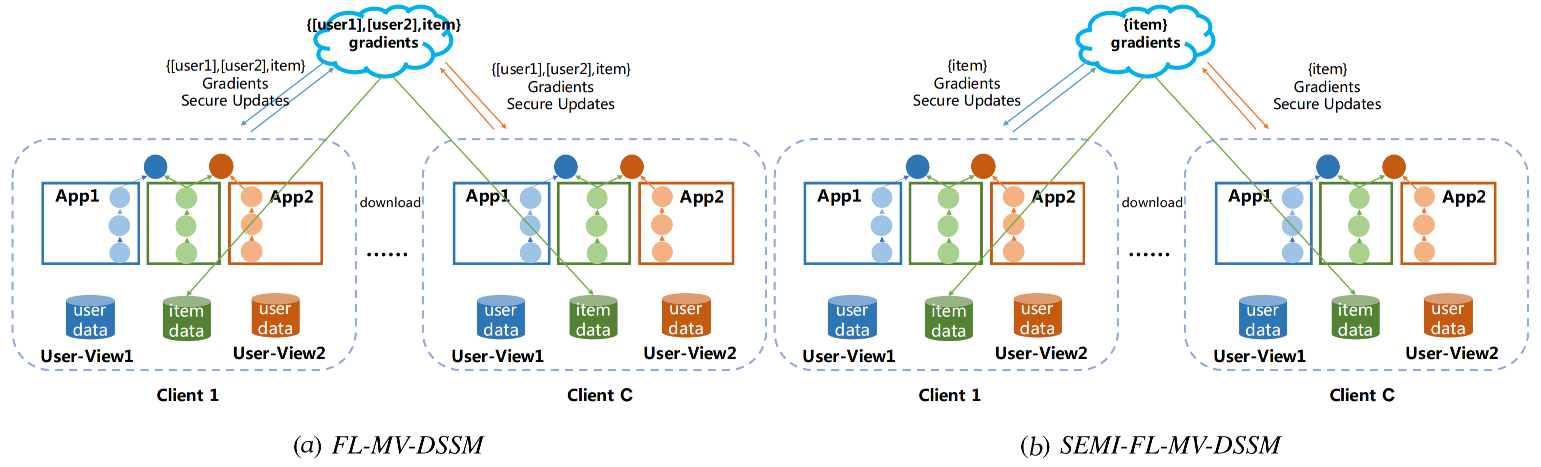
(a)FL-MV-DSSM和(b)SEMI-FL-MV-DSSM 都以传统的FedAvg算法为基础,且它们都需要server提供物品数据供所有client共享。不过在FL-MV-DSSM中每个client c中用户子模型和物品子模型的梯度会根据本地用户数据和本地物品数据进行计算,然后在server端对用户和物品子模型的梯度进行聚合;而SEMI-FL-MV-DSSM则只会聚合物品子模型的梯度,而不会聚合用户子模型的梯度。
注意,client在将梯度发往server前,会在本地先多个视角所算得的物品子模型梯度聚合(注意,D个用户视角共享同一个物品特征,会总共算得D个物品子模型的梯度);而为了保护各视角梯度中蕴含的敏感信息,FL-MV-DSSM使用差分隐私技术向各个视角所算得的物品子模型梯度中加入高斯噪声。在本地聚合完成后,client又会再将前述物品子模型梯度同D个用户子模型的梯度进行加密,然后发往server。
3.3 SIGIR21 《FedCT: Federated Collaborative Transfer for Recommendation》[5]
本论文提出的模型满足了多个client数据的隐私性和单个client中多视角数据的隐私性,也属于横向+纵向类型。不过与前文采用的方法不同,本文提出的DUE(Decentralized User Encoding)模型并没有利用一个中间视角的数据来训练共享子模型,而是采用变分自编码器(VAE)来生成一个单独的用户表示,该表示可以被所有视角共享。

上面的图 (a) 中展示的为领域-领域两两间的知识迁移,而 (b) 则为本文提出的DUE模型中所采用的基于中间表示的迁移方式。用户的表示Xu=[U(d1)u,…,U(dD)u]。事实上,(a) 中的这种方法直接迁移用户表示有违隐私性,而且当领域数量增长时计算量会很大。而 (b) 则更能保证隐私性,而且其计算代价也不会随领域数量快速增长。此外,(b) 这种方法可以随时加入和减少领域,更具灵活性。
设领域集合为D={d1,…,dD}。对每个领域d∈D,将起对应的物品集合表示为Id(大小为Nd)。设领域之间的物品无重叠,即满足∀d,d′∈D,d≠d′,Id∩Id′=0。设每个client对应一个用户,一共有C个用户。一个领域d可能只涉及到用户集合的子集U(d)⊆U,一个用户u∈U也可能只涉及到领域集合的子集D(u)⊆D。每个领域都有对应的共现矩阵Rd及其协同过滤模型fd,fd为一个给定用户-物品对(u,i)预测评分结果:ˆru,i,d=fd(U(d)u,i)的函数,这里U(d)u∈RLd表示用户u在领域d的表示,Ld为用户表示的维度。在本文的边缘跨领域推荐场景下,fd和U(d)根据特定领域的协同过滤目标函数LCFd进行预训练,并作为该领域对应的本地预训练模型使用。
加上server端,整体的联邦跨领域迁移架构如下图所示(图中仅仅展示了单个用户):

这里设Sd为server端的领域服务商存储空间(存有fd和Ud);Eu为用户在设备上所拥有的个人
存储空间(任何领域都能对其进行访问),用于存放共享表示zu;Ed,u为领域服务商在用户设备上的存储空间。它能够与Sd同步获取预训练模型并与用户的个人存储空间Eu通信。正如图中所示,对任意领域d和d′而言,本文在设定上禁止{Sd,Ed,u}和{Sd′,Ed′,u}的信息交互。不过,正如我们前面所说的,本文允许用户个人存储空间Eu和client端任意领域存储空间Ed,u的信息交换,这也就意味着用户个人存储空间充当了中间代理的作用,以协调间接性的知识迁移。
本文的最终目标是在为目标领域dt∈D的冷启动用户提供推荐(使用根据其它领域的用户表示做为辅助信息)。给定多个领域的用户表示做为训练数据,则问题就成为了学习对用户表示进行迁移的模型:g:RLd1+Ld2+⋯+LdD→RLdt,该模型将来自所有领域的用户信息映射到dt:
这里假定用户的表示Xu=[U(d1)u,…,U(dD)u]在优化和推断的过程中是固定的。若是在中心化环境下,所有领域协作训练一个共享的g是很容易的。但正如开头所说,直接迁移emebddings会带来隐私性的问题,而这就需要使用用户存储空间中的共享表示zu这一中介了。
具体地,本文为每个领域d都设置了一个VAE gd(包含编码器和解码器)。如下图所示,设zu∈RLc,则gd由一个编码器ENCd:RLd→RLc(参数为Φd,负责根据特定领域的用户表示U(d)生成zu)和一个解码器DECd:RLc→RLd(参数为Θd,负责根据zu生成ˆU(d))组成。这里DECd(⋅)生成的ˆU(d)u含有来自所有领域的丰富信息,将会被用于之后的推荐服务。另一方面,每个领域也会不断更新自己的编码器和解码器。

3.4 WWW22 《Differential Private Knowledge Transfer for Privacy-Preserving Cross-Domain Recommendation》[6]
本文不考虑用户间数据的隔离性,只考虑在两个相互隔离的领域间进行知识迁移,属于纵向类型。本文假定两个领域(源域和目标域)之间有着相同的用户,但是有着不同的用户-物品共现矩阵,目标在于在保证数据隐私的情况下,利用原域的数据以提高目标域的推荐表现。本文基于Johnson-Lindenstrauss变换(JLT)将共现矩阵加以差分隐保护,然后使用深度自编码器和深度学习网络来分别对源域和目标域中的共现矩阵进行建模,
本文采用的技术解决方案具体描述如下两个阶段:
在第一阶段,先基于JLT变换将共现矩阵由高维空间映射到低维空间空间,能够在够保护数据隐私(即无法辨识出某个用户的评分情况)的同时保持用户间的几何相似度(即相似评分的用户有相似品味)。此外本文还给出了考虑到稀疏情形的JLT(SJLT),能够进一步减少JLT的计算复杂度并解决源域的数据稀疏性问题,其中使用了sub-Gaussian随机矩阵和Hadamard变换。
在第二阶段,本文提出了一个异构的跨领域推荐模型(HeteroCDR),该模型使用深度自编码器和DNN来分别对差分隐私保护的源域共现矩阵和目标域共现矩阵进行建模。此外,论文对这两个网络学得的用户embeddings进行对齐,从而使知识能够进行迁移。
论文采用JLT随机变换以得到差分隐私保护的共现矩阵R′。JLT将一个来自Rd的向量变换到Rd′:ϕ:x→Mx。这里M∼N(0,Od′×d),Od′×d为所有元素为1的稠密矩阵。
而稀疏架构下的JLT和JLT的作用原理相似,也是定义一个从从高维到低维空间的映射,同时大概率保持变换后向量的l2范数不变。将稀疏向量从Rd转换到Rd′的SJLT定义为:ψ:x→Mx,这里M=PHD,P∈Rd′×d, H∈Rd×d,D∈Rd×d
hij=d−1/2(−1)(i−1,j−1)是标准化后的Hadamard矩阵(每个元素都是 +1或−1且每行互相正交),这里(i,j)=∑kikjk mod 2是一个按位运算并模2的内积,D是个随机对角矩阵并满足
整个隐私保护下的跨领域推荐架构如下:
Johnson-Lindenstrauss变换(JLT)

如图所示,将RA∈Rm×n1变换到R′∈Rm×n′1后,会通过自编码器来学习用户的embeddings(用于源域和目标域的知识迁移)。先通过编码器获取用户embeddings:uAi=ENC(r′A(i))∈Rh,这里h是用户embeddings的维度;然后解码器对共现矩阵进行重构:ˆr′A(i)=DEC(uAi)∈Rn′1。重构的loss为:
这里F为均方误差。
此外,论文对源域和目标域用户embeddings进行对齐以完成知识迁移。在对齐模型中,论文将用户embeddings的loss表示如下:
在目标域B方面,采用深度矩阵分解模型来拟合用户评分,其核心思想为最小化真实评分rBij和预测评分ˆrBij之间的交叉熵,这里预测评分由多层全连接网络输出。该网络会先计算计算用户和物品的隐向量uBi∈Rh和vBj∈Rh(h表示隐向量维度),然后计算用户和物品的隐向量的余弦相似度做为评分预测值,即ˆrBij=(uBi)TvBj。损失函数描述如下:
最终的完整损失函数为以上三个损失函数之和:
- [1] Elkahky A M, Song Y, He X. A multi-view deep learning approach for cross domain user modeling in recommendation systems[C]//Proceedings of the 24th international conference on world wide web. 2015: 278-288.
- [2] 杨强. 迁移学习[M]. 机械工业出版社, 2020.
- [3] Flanagan A, Oyomno W, Grigorievskiy A, et al. Federated multi-view matrix factorization for personalized recommendations[C]//Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, Cham, 2020: 324-347.
- [4] Hao Li, Mingkai Huang, Bing Bai, et al. A federated multi-view deep learning framework for privacy-preserving recommendations[C]//FTL-IJCAI. 2021.
- [5] Liu S, Xu S, Yu W, et al. FedCT: Federated collaborative transfer for recommendation[C]//Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 2021: 716-725.
- [6] Chen C, Wu H, Su J, et al. Differential Private Knowledge Transfer for Privacy-Preserving Cross-Domain Recommendation[C]//Proceedings of the ACM Web Conference 2022. 2022: 1455-1465.
__EOF__
Recommend
-
17
推荐系统应用广泛,已经渗透到人们生活各个方面,例如新闻推荐、视频推荐、商品推荐等。为了实现精准的推荐效果,推荐系统会收集海量用户和所推荐内容的数据,一般而言,收集的数据越多,对用户和推荐内容的了解就越全面和深入,推荐效果越...
-
5
Tuesday, 15 December 2020 09:58 Backdoored Orion binary still available on SolarWinds website Featured By Sam...
-
14
数据是人工智能时代的石油,但是由于监管法规和商业机密等因素限制,"数据孤岛"现象越来越明显。联邦学习(Federated Learning)是一种新的机器学习范式,它让多个参与者可以在不泄露明文数据的前提下,用多方的数据共同训练模型,实现数...
-
5
webpack 5引入联邦模式是为了更好的共享代码。 在此之前,我们共享代码一般用npm发包来解决。 npm发包需要经历构建,发布,引用三阶段,而联邦模块可以直接引用其他应用代码,实现热插拔效果。对比npm的方式更加简洁、快速、方便。 1、引入...
-
8
胡世杰:联邦学习如何颠覆传统AI应用和商业模式 - 精选 - 商界网 | 商界APP-专注于商人-企业以及商业思维胡世杰:联邦学习如何颠覆传统AI应用和商业模式 梁坤...
-
12
联邦学习:按混合分布划分Non-IID样本 我们在博文
-
10
再议 DDD 视角下的 EFCore 与 领域事件...
-
7
苹果公司请求联邦法院撤销Epic案的应用商店相关禁令 2022年07月16日12:29 财联社
-
4
联邦学习: 联邦场景下的时空数据挖掘 不论你望得多远,仍然有无限的空间在外边,不论你数多久,仍然有无限的时间数不清。——惠特曼...
-
8
当前位置:DaoCloud道客博客 > 新闻 > 联邦学习场景中 Piraeus 的应用
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK