

Downloading geo files from Census FTP using python
source link: https://andrewpwheeler.com/2022/02/28/downloading-geo-files-from-census-ftp-using-python/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Downloading geo files from Census FTP using python
I was working with some health data that only has MSA identifiers the other day. Not many people seem to know about the US Census’s FTP data site. Over the years they have had various terrible GUI’s to download data, but I almost always just go to the FTP site directly.
For geo data, check out https://www2.census.gov/geo/tiger/TIGER2019/ for example. Python for pandas/geopandas also has the nicety that you can point to a url (even a url of a zip file), and load in the data in memory. So to get the MSA areas was very simple:
# Example download MSA
import geopandas as gpd
from matplotlib import pyplot as plt
url_msa = r'https://www2.census.gov/geo/tiger/TIGER2019/CBSA/tl_2019_us_cbsa.zip'
msa = gpd.read_file(url_msa)
msa.plot()
plt.show()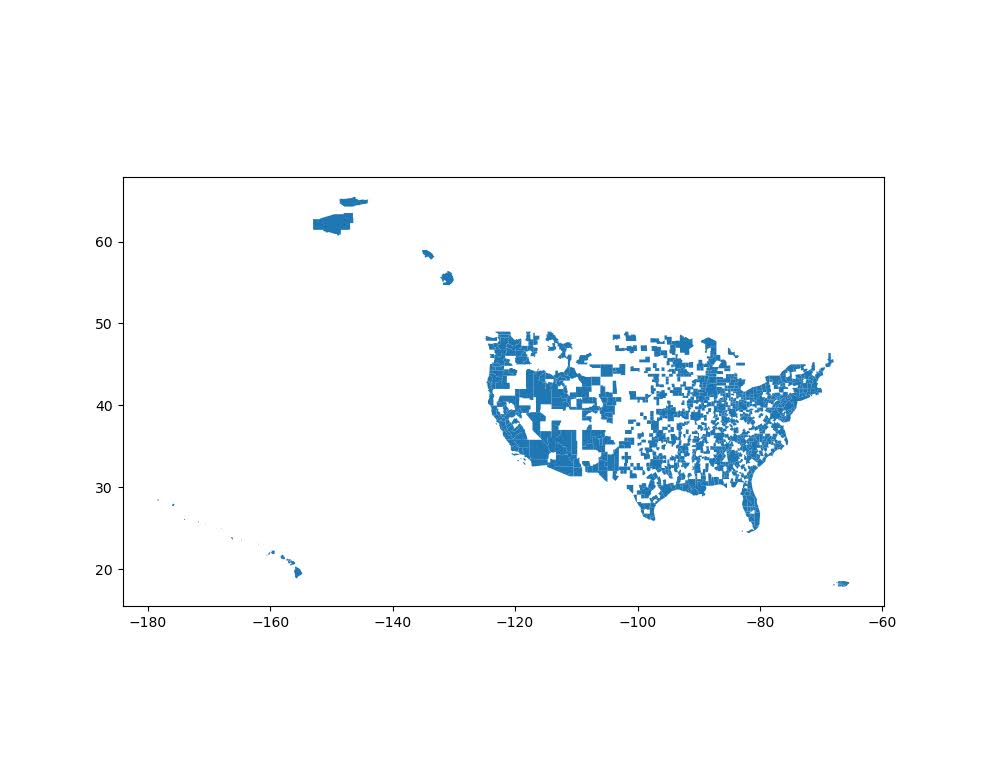
Sometimes the census has files spread across multiple states. So here is an example of doing some simple scraping to get all of the census tracts in the US. You can combine the geopandas dataframes the same as pandas dataframes using pd.concat:
# Example scraping all of the zip urls on a page
from bs4 import BeautifulSoup
import pandas as pd
import re
import requests
def get_zip(url):
front_page = requests.get(url,verify=False)
soup = BeautifulSoup(front_page.content,'html.parser')
zf = soup.find_all("a",href=re.compile(r"zip"))
# Maybe should use href
zl = [os.path.join(url,i['href']) for i in zf]
return zl
base_url = r'https://www2.census.gov/geo/tiger/TIGER2019/TRACT/'
res = get_zip(base_url)
geo_tract = []
for surl in res:
geo_tract.append(gpd.read_file(surl))
geo_full = pd.concat(geo_tract)
# See State FIPS codes
# https://www.nrcs.usda.gov/wps/portal/nrcs/detail/?cid=nrcs143_013696
geo_full[geo_full['STATEFP'] == '01'].plot()
plt.show()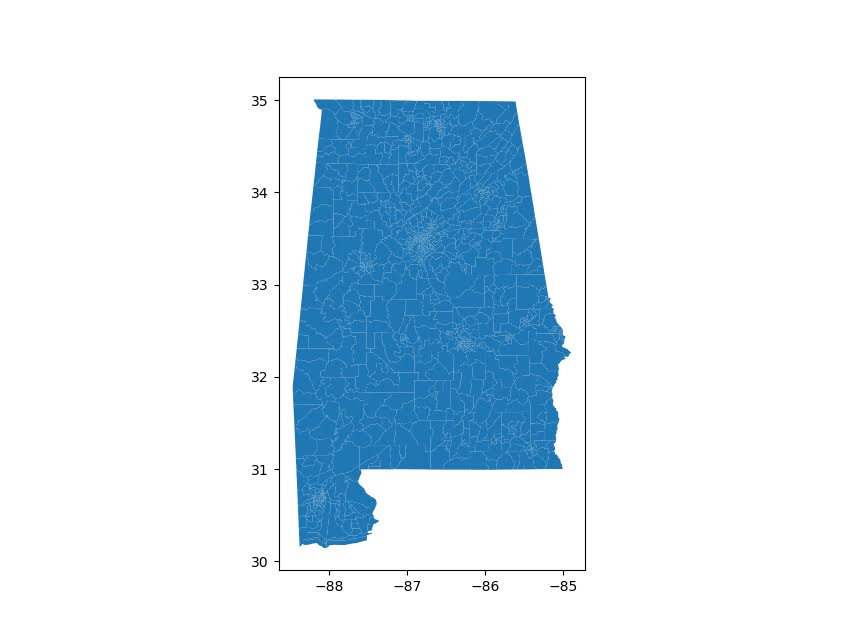
Unfortunately for the census data tables, such as https://www2.census.gov/programs-surveys/acs/summary_file/2019/data/5_year_seq_by_state/Alabama/Tracts_Block_Groups_Only/, those zip files contain two files (an estimate file and a margin of error file), so you cannot just do pd.read_csv(url) for those tables. But for the shapefile zip files this appears to work just fine and dandy.
I am currently working on a project at work (but Gainwell has given me the thumbs up to open source it) to build tables to create the CDC’s Social Vulnerability Index, which I can build for multiple geographies in combo with the census data. So hopefully in the next few weeks will be able to share that work.
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK