

Kafka消费者消息拉取机制
source link: https://www.tony-bro.com/posts/260393677/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Kafka消费者消息拉取机制
工作中有对Kafka重度使用的项目,其实很早就想写这一篇,但是当时也看到过一些类似的文章以及有一些其他的分享内容,所以一直拖到现在。对Kafka的使用聚焦在消费端,所以详细聊一下Kafka consumer消费过程中是如何拉取数据的。
本篇讨论的版本为Java客户端v2.8。
Poll方法
Kafka在消息消费上的实现是poll模型,消费者需要主动向broker拉取数据,Kafka consumer需要不停的调用KafkaConsumer#poll(java.time.Duration)方法。Kafka作为一个成熟复杂的消息系统,为了平衡完备的功能和易用的客户端,因而将consumer设计为这种单线程持续调用poll方法的形式(但是Kafka并没有限制获取数据后要如何消费,可以参考KafkaConsumer这个类上长长的javadoc描述的最后一部分),poll方法内部做了很多额外的工作,最大程度减少了客户端使用的复杂度。那么如果抛开其他有的没的,是不是poll方法内部就是简单地发送请求给broker然后等待获取响应的消息数据最后返回给调用方呢?在没有深入了解之前,很容易产生这样的想法,这也是这个方法给人最直观的感受,但是事实并非如此。
但是无论如何数据都是从poll方法调用后返回的,除了拉取数据之外的其他内容同样不可忽视,只不过不是本篇所述的重点,所以就以一张图和原代码展示一下poll方法的基本调用过程。
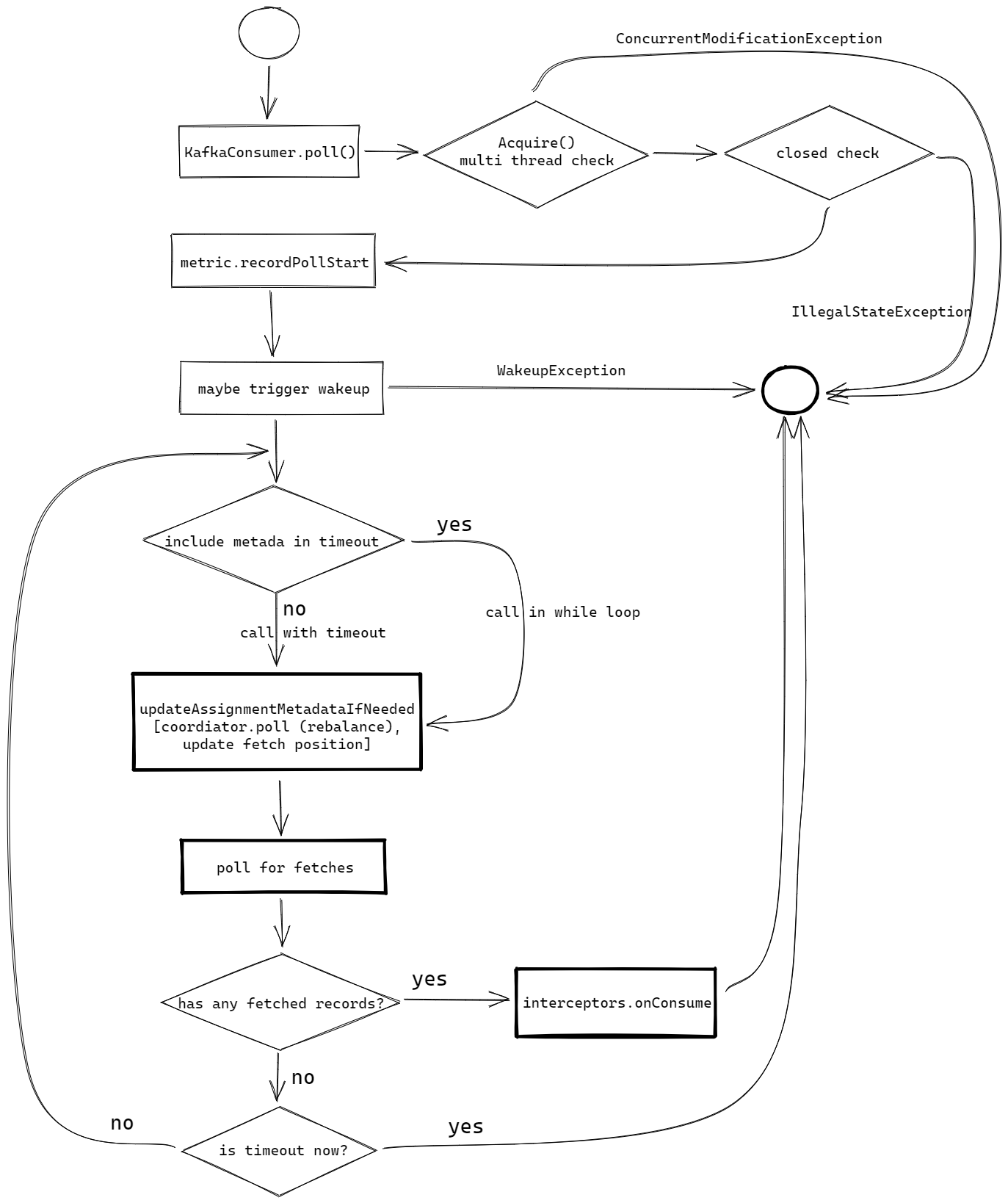
@Override
public ConsumerRecords<K, V> poll(final Duration timeout) {
return poll(time.timer(timeout), true);
}
/**
* @throws KafkaException if the rebalance callback throws exception
*/
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) {
// 1. 多线程检查(CAS变量)、关闭检查
acquireAndEnsureOpen();
try {
// 监控打点
this.kafkaConsumerMetrics.recordPollStart(timer.currentTimeMs());
// 订阅检查
if (this.subscriptions.hasNoSubscriptionOrUserAssignment()) {
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
}
do {
client.maybeTriggerWakeup();
// 2. 元数据更新(包括rebalacne和拉取数据位置更新等)
if (includeMetadataInTimeout) {
// try to update assignment metadata BUT do not need to block on the timer for join group
updateAssignmentMetadataIfNeeded(timer, false);
} else {
while (!updateAssignmentMetadataIfNeeded(time.timer(Long.MAX_VALUE), true)) {
log.warn("Still waiting for metadata");
}
}
// 3. 数据拉取(本篇重点)
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollForFetches(timer);
if (!records.isEmpty()) {
// 如果取到了数据,为了提高效率尝试发送下一轮fetch请求
// before returning the fetched records, we can send off the next round of fetches
// and avoid block waiting for their responses to enable pipelining while the user
// is handling the fetched records.
//
// NOTE: since the consumed position has already been updated, we must not allow
// wakeups or any other errors to be triggered prior to returning the fetched records.
if (fetcher.sendFetches() > 0 || client.hasPendingRequests()) {
client.transmitSends();
}
// 4. 拦截器处理、返回
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (timer.notExpired());
// 4. 返回空数据
return ConsumerRecords.empty();
} finally {
// 5. 释放CAS变量,监控打点
release();
this.kafkaConsumerMetrics.recordPollEnd(timer.currentTimeMs());
}
}
Fetcher
poll方法的最外层其实写的非常紧凑清晰,数据的拉取相关操作都在它的pollForFetches方法中。这个方法的代码抛开进一步的封装调用也很简短,把英文注释翻译了直接贴出来:
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollForFetches(Timer timer) {
// 计算剩余超时时间
long pollTimeout = coordinator == null ? timer.remainingMs() :
Math.min(coordinator.timeToNextPoll(timer.currentTimeMs()), timer.remainingMs());
// 1. 如果已经存在可用数据,直接返回
// 即从响应缓冲区中解析数据
final Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty()) {
return records;
}
// 2. 发送任何能够发送的fetch请求(如果fetch请求已经在等待发送则不会进行重复发送)
// 查看注释和内部代码,这句注释的详细意思是对于每个broker节点不会同时发送多个请求
fetcher.sendFetches();
// We do not want to be stuck blocking in poll if we are missing some positions
// since the offset lookup may be backing off after a failure
// NOTE: the use of cachedSubscriptionHashAllFetchPositions means we MUST call
// updateAssignmentMetadataIfNeeded before this method.
if (!cachedSubscriptionHashAllFetchPositions && pollTimeout > retryBackoffMs) {
pollTimeout = retryBackoffMs;
}
log.trace("Polling for fetches with timeout {}", pollTimeout);
// 3. 条件阻塞消费线程,等待fetch请求响应
Timer pollTimer = time.timer(pollTimeout);
client.poll(pollTimer, () -> {
// 由于fetch请求可能由后台线程执行完毕,我们需要这个poll(network poll)条件
// 来保证不会阻塞多余的时间
return !fetcher.hasAvailableFetches();
});
timer.update(pollTimer.currentTimeMs());
// 4. 再次尝试从响应缓冲区中解析已经拉取到的消息
return fetcher.fetchedRecords();
}
整个消息拉取过程简述如下:
- 调用 fetcher.fetchRecords()
- 判断调用是否有数据返回,如果有数据直接返回数据
- 如果没有数据,调用 fetcher.sendFetches()
- 调用networkClient.poll,调用返回条件为收到fetch请求响应数据或者等待超时
- 再次调用 fetcher.fetchRecords()
可以看到消息拉取的处理都是由org.apache.kafka.clients.consumer.internals.Fetcher这个类对象来处理,并且核心方法只有两个:fetchRecords 和 sendFetches,这两个方法代码看起来会多一些,但是同样很清晰,所以还是直接贴出来跟这源码走一遍。
sendFetches
// 接收缓冲区是一个并发链表
private final ConcurrentLinkedQueue<CompletedFetch> completedFetches;
/**
* 为所有已经分配了分片且没有在途请求或等待数据的节点发送fetch请求
* @return 发送的fetch请求数量
*/
public synchronized int sendFetches() {
// 监控打点相关数据更新
// Update metrics in case there was an assignment change
sensors.maybeUpdateAssignment(subscriptions);
// 1. 根据分片订阅情况为每个需要拉取数据的broker节点生成相关信息
// 这个方法值得仔细看看
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
final Node fetchTarget = entry.getKey();
final FetchSessionHandler.FetchRequestData data = entry.getValue();
// 2. 在循环中使用builder模式构造fetch请求对象,这里包含了大量相关配置参数
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes)
.metadata(data.metadata())
.toForget(data.toForget())
.rackId(clientRackId);
log.debug("Sending {} {} to broker {}", isolationLevel, data, fetchTarget);
// 3. 发送请求,注意kafka客户端使用的是异步IO,这里只是把请求加入发送队列,不会阻塞
RequestFuture<ClientResponse> future = client.send(fetchTarget, request);
// 每个节点不会同时发送多个请求,为了达到这个目的,会把已经发送数据的节点id加入到set中
// 收到节点响应后会从set中移除相应的id,见下面addListener部分
// 注意响应处理有使用synchronized修饰
// We add the node to the set of nodes with pending fetch requests before adding the
// listener because the future may have been fulfilled on another thread (e.g. during a
// disconnection being handled by the heartbeat thread) which will mean the listener
// will be invoked synchronously.
this.nodesWithPendingFetchRequests.add(entry.getKey().id());
// kafka的网络IO都是这种自己实现的异步callback形式,包装的很漂亮
future.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) {
synchronized (Fetcher.this) {
try {
@SuppressWarnings("unchecked")
FetchResponse<Records> response = (FetchResponse<Records>) resp.responseBody();
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.",
fetchTarget.id());
return;
}
if (!handler.handleResponse(response)) {
return;
}
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
for (Map.Entry<TopicPartition, FetchResponse.PartitionData<Records>> entry : response.responseData().entrySet()) {
TopicPartition partition = entry.getKey();
FetchRequest.PartitionData requestData = data.sessionPartitions().get(partition);
if (requestData == null) {
String message;
if (data.metadata().isFull()) {
message = MessageFormatter.arrayFormat(
"Response for missing full request partition: partition={}; metadata={}",
new Object[]{partition, data.metadata()}).getMessage();
} else {
message = MessageFormatter.arrayFormat(
"Response for missing session request partition: partition={}; metadata={}; toSend={}; toForget={}",
new Object[]{partition, data.metadata(), data.toSend(), data.toForget()}).getMessage();
}
// Received fetch response for missing session partition
throw new IllegalStateException(message);
} else {
long fetchOffset = requestData.fetchOffset;
FetchResponse.PartitionData<Records> partitionData = entry.getValue();
log.debug("Fetch {} at offset {} for partition {} returned fetch data {}",
isolationLevel, fetchOffset, partition, partitionData);
Iterator<? extends RecordBatch> batches = partitionData.records().batches().iterator();
short responseVersion = resp.requestHeader().apiVersion();
// 4. 成功收到响应,把响应数据放到接收缓存completedFetches中
completedFetches.add(new CompletedFetch(partition, partitionData,
metricAggregator, batches, fetchOffset, responseVersion));
}
}
// fetch请求响应延迟监控打点
sensors.fetchLatency.record(resp.requestLatencyMs());
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
@Override
public void onFailure(RuntimeException e) {
synchronized (Fetcher.this) {
try {
FetchSessionHandler handler = sessionHandler(fetchTarget.id());
if (handler != null) {
handler.handleError(e);
}
} finally {
nodesWithPendingFetchRequests.remove(fetchTarget.id());
}
}
}
});
}
return fetchRequestMap.size();
}
总的来说这个方法就是在做发送请求的工作,根据订阅的分片信息,给所有相关的broker发送fetch请求。
fetchRecords
// 当前正在解析的数据作为一个类成员
private CompletedFetch nextInLineFetch = null;
/**
* 返回拉取的数据,清空记录缓存,更新消费位置
*
* NOTE: 返回空记录保证消费位置不会更新
*
* @return 每个分片对应拉取的数据
* @throws OffsetOutOfRangeException If there is OffsetOutOfRange error in fetchResponse and
* the defaultResetPolicy is NONE
* @throws TopicAuthorizationException If there is TopicAuthorization error in fetchResponse.
*/
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
Queue<CompletedFetch> pausedCompletedFetches = new ArrayDeque<>();
// 限定返回的最大记录数,即经典配置项 max.poll.records 所定
int recordsRemaining = maxPollRecords;
try {
// 循环从接收缓冲区获取数据
while (recordsRemaining > 0) {
if (nextInLineFetch == null || nextInLineFetch.isConsumed) {
CompletedFetch records = completedFetches.peek();
if (records == null) break;
if (records.notInitialized()) {
try {
// 处理返回信息,更新HW、副本偏好信息、错误处理等
nextInLineFetch = initializeCompletedFetch(records);
} catch (Exception e) {
// Remove a completedFetch upon a parse with exception if (1) it contains no records, and
// (2) there are no fetched records with actual content preceding this exception.
// The first condition ensures that the completedFetches is not stuck with the same completedFetch
// in cases such as the TopicAuthorizationException, and the second condition ensures that no
// potential data loss due to an exception in a following record.
FetchResponse.PartitionData<Records> partition = records.partitionData;
if (fetched.isEmpty() && (partition.records() == null || partition.records().sizeInBytes() == 0)) {
completedFetches.poll();
}
throw e;
}
} else {
nextInLineFetch = records;
}
completedFetches.poll();
} else if (subscriptions.isPaused(nextInLineFetch.partition)) {
// when the partition is paused we add the records back to the completedFetches queue instead of draining
// them so that they can be returned on a subsequent poll if the partition is resumed at that time
log.debug("Skipping fetching records for assigned partition {} because it is paused", nextInLineFetch.partition);
pausedCompletedFetches.add(nextInLineFetch);
nextInLineFetch = null;
} else {
// 解析数据的核心方法,返回的响应可能包含多条信息,允许只返回其中的若干条
// 执行数据解码,以及相关的监控打点,有时间可以细看
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineFetch, recordsRemaining);
// 响应结果(map)处理
if (!records.isEmpty()) {
TopicPartition partition = nextInLineFetch.partition;
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
} else {
// this case shouldn't usually happen because we only send one fetch at a time per partition,
// but it might conceivably happen in some rare cases (such as partition leader changes).
// we have to copy to a new list because the old one may be immutable
// 看注释是为了兼容不可变的list,所以每次都新建list重新put到结果map中
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
newRecords.addAll(currentRecords);
newRecords.addAll(records);
fetched.put(partition, newRecords);
}
// 更新剩余记录数
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
} finally {
// add any polled completed fetches for paused partitions back to the completed fetches queue to be
// re-evaluated in the next poll
completedFetches.addAll(pausedCompletedFetches);
}
return fetched;
}
可以看到该方法主要是从响应缓冲区中取出数据,进行解析、相关数据处理,返回解析好的ConsumerRecord。
线程模型概述
看下来这个线程模型核心逻辑并不复杂。如果只论请求响应,可以描述为根据订阅情况给各个broker并发发送请求,异步接收请求(底层使用NIO)将收到的数据写入响应缓冲区链表,注意对于每个broker不会同时发起多个请求。从整个调用过程来看:消费的时候首先查看缓冲区(线程安全的链表)中是否还有未消费的数据,如果有则直接解码处理后返回(同时异步发起下一轮请求),如果没有则根据订阅情况针对所有相关broker节点并发做异步请求,异步响应结果都会存入缓冲区;消费线程会等待直到缓冲区有任何可用的数据或者超时;循环解析缓冲链表中的数据,返回不超过配置数量(max.poll.records)的消息。
相关参数和数据
绝大部分相关参数都可以在fetch请求构建时看到(观察 FetchRequest.Builder),加上poll方法的一个经典配置项,涉及的相关参数主要有如下:
- fetch.min.bytes:在响应fetch请求时服务器应返回的最小数据量。如果没有足够的数据可用,请求将等待累积相应数据量后再作响应。默认设置为1字节意味着只要有一个字节的数据可用,或者请求等待超时,fetch请求就会得到响应。将其设置为大于1的值将导致服务器等待累计更大的数据量,这样可以稍微提高服务器的吞吐量,但也会增加一些延迟。
- fetch.max.bytes:服务器响应fetch请求时应返回的最大数据量。数据记录由使用者分批获取,如果第一个非空分区中的第一个记录集合大于其值,则仍将返回记录集合,以确保使用者能够正常执行下去。因此,这不是一个绝对的最大值。broker接受的最大记录集合大小通过 message.max.bytes (broker config) 或 max.message.bytes (topic config)定义。请注意,使用者会并行执行多个读取操作。
- fetch.max.wait.ms:如果没有足够的数据立即满足 fetch.min.bytes 提供的要求,服务器在响应fetch请求之前将阻塞的最大时间。
- max.partition.fetch.bytes:服务器返回的每个分区的最大数据量。记录由使用者分批获取。如果提取的第一个非空分区中的第一个记录批处理大于此限制,则仍将返回该批处理,以确保使用者能够正常执行下去。
- max.poll.records:单次调用 poll() 返回的最大记录数。
在本人的实际的项目应用中,总消费量最高可以达到十万每秒的级别,在这种消费速度下如果不做任何人工配置全部采用默认值,每次fetch请求基本上还是只会返回1条消息记录,此时单机fetch请求的QPS可以达到4,5k。在消费速度和生产速度匹配的情况下Kafka的消费延迟(从生产方发送到消费方收到这个数据)能够维持在一个比较低的水平(几十毫秒以内),这也可以反映出Kafka的吞吐量确实相当不错,上限很高(处理日志的集群会达到更高的数量级),同时延迟也能够在这个量级下得到保证。此外,如果想要降低CPU、提升吞吐量、能够接受一定的延迟提升,Kafka也提供了上述相关配置进行更改,满足不同情况下的使用需求。
Recommend
-
37
我们继续对消息消费流程的源码进行解析。 本文主要针对push模式下的消息拉取流程进行解析。我们重点分析集群消费模式,对于广播模式其实很好理解,每个消费者都需要拉取主题下面的所有消费队列的消息。 在集群消费模式下,同一个消费者组内包含了...
-
9
在《RocketMQ源码分析之RebalanceService》中回答了消费者在第一次启动后是如何来获取消息这个问题,那么在构建PullRequest(消息拉取任务)后,消费者与broker之间是如何交互来完成消息拉取任务?本篇文章就来分析消息拉取流程。...
-
8
SpringBoot使用Testcontainers+Avro消息测试Kafka消费者您有一个 Spring Boot 微服务来管理用户数据。该微服务侦听来自 Kafka 的传入事件(例如用户创建、更新或删除),将它们转换为您自己的业务对象,将它们写入 PostgreSQL 数据库并通过 REST 接口将它们提供...
-
5
Kafka -- 元数据的拉取时机发布于 17 分钟前生产者发消息给Kafka,是需要知道Kafka的ip、端口等节点信息,这些节点信息是元数据的一部分,属于元数据Metadata的Clus...
-
8
上一节我们分析了Producer的核心组件,我们得到了一张关键的组件图。你还记得么?
-
9
消息队列之kafka 消费者的Offset管理 发表于 2021-01-21 ...
-
4
kafka生产者消息分区机制 发表于 2019-10-09 更新于 2019-10-19 分类于 kafka Valine:
-
14
Kafka生产者消息发送机制写了消费者,那再写下生产者吧,兴许应该再写写网络模型和Broker端的内容,免得偏科,毕竟也吃过亏。虽然仍是聚焦于一点,但是生产者的内容也不少,与分析消费者如何拉取数据那篇一样,着重描述一下如何发送数据,...
-
6
【RocketMQ】消息的拉取 RocketMQ消息的消费以组为单位...
-
5
Kafka ConsumerKafka 有消费组的概念,每个消费者只能消费所分配到的分区的消息,每一个分区只能被...
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK