
1

Kafka Consumer 消费消息和 Rebalance 机制
source link: https://www.51cto.com/article/784133.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Kafka Consumer
Kafka 有消费组的概念,每个消费者只能消费所分配到的分区的消息,每一个分区只能被一个消费组中的一个消费者所消费,所以同一个消费组中消费者的数量如果超过了分区的数量,将会出现有些消费者分配不到消费的分区。消费组与消费者关系如下图所示:
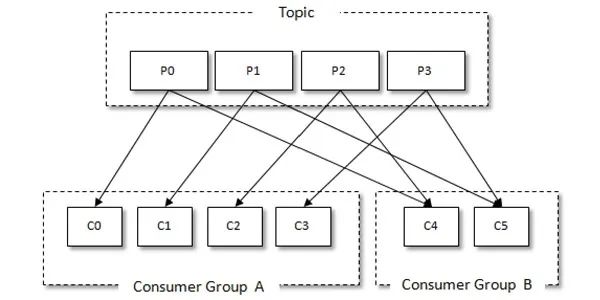
consumer group
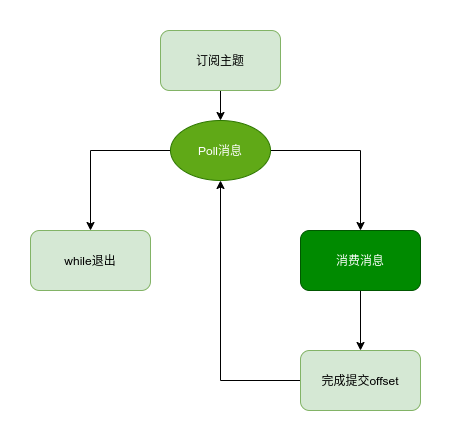
Kafka Consumer Client 消费消息通常包含以下步骤:
- 配置客户端,创建消费者
- 拉去消息并消费
- 提交消费位移
- 关闭消费者实例
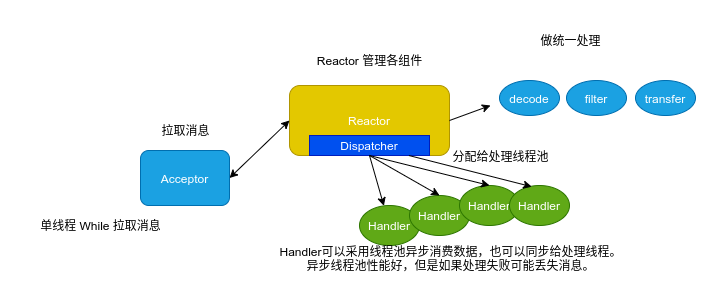
因为 Kafka 的 Consumer 客户端是线程不安全的,为了保证线程安全,并提升消费性能,可以在 Consumer 端采用类似 Reactor 的线程模型来消费数据。
Kafka consumer 参数
- bootstrap.servers:连接 broker 地址,host:port 格式。
- group.id:消费者隶属的消费组。
- key.deserializer:与生产者的key.serializer对应,key 的反序列化方式。
- value.deserializer:与生产者的value.serializer对应,value 的反序列化方式。
- session.timeout.ms:coordinator 检测失败的时间。默认 10s 该参数是 Consumer Group 主动检测 (组内成员 comsummer) 崩溃的时间间隔,类似于心跳过期时间。
- auto.offset.reset:该属性指定了消费者在读取一个没有偏移量后者偏移量无效(消费者长时间失效当前的偏移量已经过时并且被删除了)的分区的情况下,应该作何处理,默认值是 latest,也就是从最新记录读取数据(消费者启动之后生成的记录),另一个值是 earliest,意思是在偏移量无效的情况下,消费者从起始位置开始读取数据。
- enable.auto.commit:否自动提交位移,如果为false,则需要在程序中手动提交位移。对于精确到一次的语义,最好手动提交位移
- fetch.max.bytes:单次拉取数据的最大字节数量
- max.poll.records:单次 poll 调用返回的最大消息数,如果处理逻辑很轻量,可以适当提高该值。但是max.poll.records条数据需要在在 session.timeout.ms 这个时间内处理完 。默认值为 500
- request.timeout.ms:一次请求响应的最长等待时间。如果在超时时间内未得到响应,kafka 要么重发这条消息,要么超过重试次数的情况下直接置为失败。
Kafka Rebalance
rebalance 本质上是一种协议,规定了一个 consumer group 下的所有 consumer 如何达成一致来分配订阅 topic 的每个分区。比如某个 group 下有 20 个 consumer,它订阅了一个具有 100 个分区的 topic。正常情况下,Kafka 平均会为每个 consumer 分配 5 个分区。这个分配的过程就叫 rebalance。
什么时候 rebalance?
这也是经常被提及的一个问题。rebalance 的触发条件有三种:
- 组成员发生变更(新 consumer 加入组、已有 consumer 主动离开组或已有 consumer 崩溃了——这两者的区别后面会谈到)
- 订阅主题数发生变更
- 订阅主题的分区数发生变更
如何进行组内分区分配?
Kafka 默认提供了两种分配策略:Range 和 Round-Robin。当然 Kafka 采用了可插拔式的分配策略,你可以创建自己的分配器以实现不同的分配策略。
kafka 高频面试题
- Kafka 有哪些命令行工具?你用过哪些?/bin目录,管理 kafka 集群、管理 topic、生产和消费 kafka。
- Kafka Producer 的执行过程?拦截器,序列化器,分区器和累加器。
- Kafka Producer 有哪些常见配置?broker 配置,ack 配置,网络和发送参数,压缩参数,ack 参数。
- 如何让 Kafka 的消息有序?Kafka 在 Topic 级别本身是无序的,只有 partition 上才有序,所以为了保证处理顺序,可以自定义分区器,将需顺序处理的数据发送到同一个 partition。
- Producer 如何保证数据发送不丢失?ack 机制,重试机制。
- 如何提升 Producer 的性能?批量,异步,压缩。
- 如果同一 group 下 consumer 的数量大于 part 的数量,kafka 如何处理?多余的 Part 将处于无用状态,不消费数据。
- Kafka Consumer 是否是线程安全的?不安全,单线程消费,多线程处理。
- 讲一下你使用 Kafka Consumer 消费消息时的线程模型,为何如此设计?拉取和处理分离。
- Kafka Consumer 的常见配置?broker, 网络和拉取参数,心跳参数。
- Consumer 什么时候会被踢出集群?奔溃,网络异常,处理时间过长提交位移超时。
- 当有 Consumer 加入或退出时,Kafka 会作何反应?进行 Rebalance。
- 什么是 Rebalance,何时会发生 Rebalance?topic 变化,consumer 变化。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK