

Open3D-ML快速教程【点云分析】
source link: http://blog.hubwiz.com/2021/06/29/open3d-ml/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
Open3D-ML快速教程【点云分析】
发表于 2021-06-29
| 分类于 BIM
Open3D-ML 是 3D 机器学习任务 Open3D 的扩展。它建立在 Open3D 核心库之上,并使用机器学习工具扩展 3D 数据处理。Open3D-ML侧重于语义点云细分等应用,并提供可应用于常见任务的预培训模型以及用于训练 的管道。

Open3D-ML 与TensorFlow和PyTorch合作,轻松集成到现有项目中,还提供独立于 ML 框架(如数据可视化) 的一般功能。
Open3D-ML 集成在Python版本的Open3D v0.11 中。要使用所有的机器学习功能,你需要安装 PyTorch 或 TensorFlow。Open3D v0.11 与以下版本兼容
- PyTorch 1.6
- TensorFlow 2.3
- CUDA 10.1 (可选)
如果你需要使用不同的版本,我们建议从源码构建 Open3D。
我们提供预制的 pip 包,用于Ubuntu 18.04+ 的 Open3D-ML+,可以使用如下命令安装:
$ pip install open3d
可以使用如下命令测试安装:
# with PyTorch
$ python -c "import open3d.ml.torch as ml3d"
# or with TensorFlow
$ python -c "import open3d.ml.tf as ml3d"
2、读取数据集
dataset命名空间包含了用于阅读常见数据集的类。在这里,我们阅读语义KITTI数据集并将其可视化。
import open3d.ml.torch as ml3d # or open3d.ml.tf as ml3d
# construct a dataset by specifying dataset_path
dataset = ml3d.datasets.SemanticKITTI(dataset_path='/path/to/SemanticKITTI/')
# get the 'all' split that combines training, validation and test set
all_split = dataset.get_split('all')
# print the attributes of the first datum
print(all_split.get_attr(0))
# print the shape of the first point cloud
print(all_split.get_data(0)['point'].shape)
# show the first 100 frames using the visualizer
vis = ml3d.vis.Visualizer()
vis.visualize_dataset(dataset, 'all', indices=range(100))
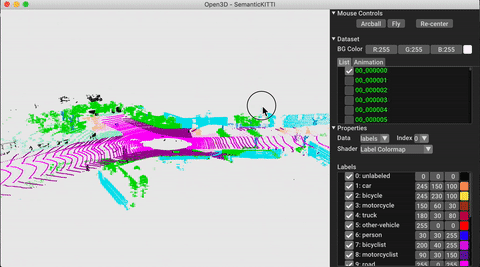
3、运行预先训练的模型
在上一个示例的基础上,我们可以使用预先训练的语义分割模型对管道进行即时处理, 并在数据集的点云上运行。请参阅model zoo 获得预训练模型的权重。
model = ml3d.models.RandLANet()
pipeline = ml3d.pipelines.SemanticSegmentation(model=model, dataset=dataset, device="gpu")
# load the parameters.
pipeline.load_ckpt(ckpt_path='randlanet_semantickitti_202009090354utc.pth', is_train=False)
data = test_split.get_data(0)
# run inference on a single example.
# returns dict with 'predict_labels' and 'predict_scores'.
result = pipeline.run_inference(data)
# evaluate performance on the test set; this will write logs to './logs'.
pipeline.run_test()
4、训练模型
与推理类似,管道为在数据集上训练模型提供了接口。
# use a cache for storing the results of the preprocessing (default path is './logs/cache')
dataset = ml3d.datasets.SemanticKITTI(dataset_path='/path/to/SemanticKITTI/', use_cache=True)
# create the model with random initialization.
model = RandLANet()
pipeline = SemanticSegmentation(model=model, dataset=dataset, max_epoch=100)
# prints training progress in the console.
pipeline.run_train()
有关更多示例,请参阅examples 和scripts目录。
5、使用预定义的脚本
scripts/semseg.py为在 数据集中培训和评估模型提供了一个容易的接口。它减少了定义特定模型和 传递精确配置的麻烦。
python scripts/semseg.py {tf/torch} -c <path-to-config> --<extra args>
请注意,extra args的优先级高于配置文件中的相同参数。因此,在启动脚本时,你可以通过命令行 而不是在配置文件中更改参数。
# Launch training for RandLANet on SemanticKITTI with torch.
python scripts/semseg.py torch -c ml3d/configs/randlanet_semantickitti.yml --dataset.dataset_path <path-to-dataset> --dataset.use_cache True
# Launch testing for KPConv on Toronto3D with tensorflow.
python scripts/semseg.py tf -c ml3d/configs/kpconv_toronto3d.yml --dataset.dataset_path <path-to-dataset> --model.ckpt_path <path-to-checkpoint>
要获得进一步的帮助,请运行python scripts/semseg.py --help
6、存储库结构
Open3D-ML 的核心部分位于ml3d子目录中,该子目录集成到ml命名空间。除了核心部分外,exsamples和 scripts目录中还提供支持脚本,以便设置训练管道或在数据集商运行网络。
├─ docs # Markdown and rst files for documentation
├─ examples # Place for example scripts and notebooks
├─ ml3d # Package root dir that is integrated in open3d
├─ configs # Model configuration files
├─ datasets # Generic dataset code; will be integratede as open3d.ml.{tf,torch}.datasets
├─ utils # Framework independent utilities; available as open3d.ml.{tf,torch}.utils
├─ vis # ML specific visualization functions
├─ tf # Directory for TensorFlow specific code. same structure as ml3d/torch.
│ # This will be available as open3d.ml.tf
├─ torch # Directory for PyTorch specific code; available as open3d.ml.torch
├─ dataloaders # Framework specific dataset code, e.g. wrappers that can make use of the
│ # generic dataset code.
├─ models # Code for models
├─ modules # Smaller modules, e.g., metrics and losses
├─ pipelines # Pipelines for tasks like semantic segmentation
├─ scripts # Demo scripts for training and dataset download scripts
7、语义分割任务
对于语义分割的任务,我们使用所有类的平均交叉合并 (mIoU) 来衡量不同方法的性能。该表显示了 用于分割任务的可用模型和数据集以及相应的得分。每个分数都链接到相应的权重文件。
|Model / Dataset |SemanticKITTI |Toronto 3D |S3DIS| |—-|—|—|—| |RandLA-Net (tf) |53.7| 69.0| 67.0| |RandLA-Net (torch)| 52.8 |71.2| 67.0| |KPConv (tf) |58.7| 65.6| 65.0| |KPConv (torch)| 58.0| 65.6| 60.0|
8、Model Zoo
有关所有全重文件的完整列表,请参阅model_weights.txt 和 MD5 检查文件model_weights.md5。
9、预置数据集
以下是我们提供Reader的数据集列表:
- SemanticKITTI (project page)
- Toronto 3D (github)
- Semantic 3D (project-page)
- S3DIS (project-page)
- Paris-Lille 3D (project-page)
要下载这些数据集,请访问对应网页并查看scripts/download_datasets 中的脚本。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK