

[Reading] EfficientDet: Scalable and Efficient Object Detection
source link: https://blog.nex3z.com/2021/04/09/reading-efficientdet-scalable-and-efficient-object-detection/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
[Reading] EfficientDet: Scalable and Efficient Object Detection
Author: nex3z 2021-04-09
EfficientDet: Scalable and Efficient Object Detection (2019/11)
Contents [show]
文章的主要贡献有:
- 提出了一种加权双向特征金字塔(weighted Bi-directional Feature Pyramid Network,BiFPN),可以简单快速地进行多尺度特征的融合。
- 提出了一种组合缩放方法,可以对主干网络、特征网络、边界框/分类预测网络进行均匀的分辨率、深度、宽度缩放。
- 基于以上优化,提出了 EfficientDet 系列目标检测器,其中 EfficientDet-D7 在 COCO 上获得最高的 55.1 AP,比之前的检测器小 4x-9x,计算量少 13-42x。
文章对目标检测任务的神经网络架构进行了系统化的研究,提出了一系列手段来提高效率。
目标检测性能的提高往往伴随着网络的增大,过大的网络难以在计算和容量受限的场景中部署。单阶段和无锚点的检测器具有较高的效率,但通常会牺牲准确度,同时之前的研究大多只关注特定的某个或某些资源要求,而现实中的应用,从移动设备到数据中心,通常会有不同的资源限制。文章通过对检测器架构设计时的各种设计选择进行系统化的研究,尝试构造一个可缩放的检测架构,在一个很宽的资源约束内(如 3B 到 300B FLOPS),同时获得高准确率和高效率。
基于单阶段检测器,文章研究了主干网络、特征融合、分类/边界框预测网络的各种设计选择,发现了两点挑战。
首先是高效的多尺度特征融合。之前使用 FPN 进行多尺度特征融合时,通常只是无差别地将特征相加。但多尺度的特征来自不同的分辨率,对融合后特征的贡献也是不同的。文章提出的 BiFPN 为不同的输入特征引入可学习的权重,来学习不同特征的重要性。
然后是模型缩放。之前对网络的缩放通常是通过使用不同的主干网络和输入图像分辨率进行的,文章发现对特征网络和分类/边界框预测网络进行缩放也十分重要。受 EfficientNet 启发,文章提出了一种组合缩放(compound scaling)方式,同时对主干网络、特征网络、分类/边界框预测网络的分辨率、深度、宽度进行缩放。
同时文章发现使用 EfficientNet 作为主干网络可以获得更高的效率,通过结合 EfficientNet、BiFPN 和组合缩放,文章提出了名为 EfficientDet 的系列目标检测器,在使用更少参数和 FLOPs 就可以获得更高的准确率,如 Figure 1、Figure 4 所示。
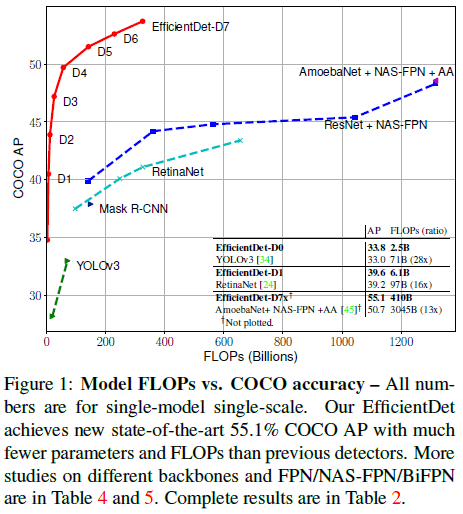 Figure 1
Figure 12. BiFPN
2.1. 问题
多尺度特征融合是为了聚合不同分辨率的特征。给定一系列多尺度特征 →Pin=(Pinl1,Pinl2,…),其中 Pinli 表示第 li 层的特征,我们的目标是找到一种高效的变换 f 来对不同的特征进行聚合,得到新的特征 →Pout=f(→Pin)。
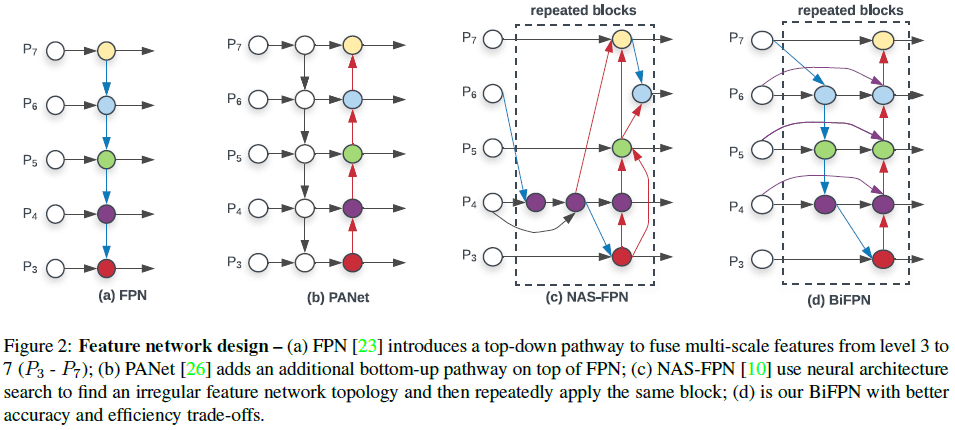 Figure 2
Figure 2Figure 2(a) 展示了传统的由上到下的 FPN,使用第 3 到 7 层的特征 →Pin=(Pin3,…,Pin7),Pini 特征的分辨率为输入图像的 1/2i。传统的 FPN 由上到下地对多尺度特征进行聚合,即
Pout7=Conv(Pin7)Pout6=Conv(Pin6+Resize(Pout7))…Pout3=Conv(Pin3+Resize(Pout4))
其中 Resize 通常是通过上采样或下采样来匹配分辨率。
2.2 跨尺度连接
在前述由上到下的 FPN 中,信息是单向流动的。PANet 加入了一个从下到上的聚合网络,如 Figure 2(b) 所示。NAS-FPN 通过神经架构搜索来寻找更好的跨尺度特征网络拓扑,使用大量的计算找到了一个难以解释和修改的不规则网络,如 Figure 2(c) 所示。通过研究这三种网络的性能(Table 5),文章发现使用 PANet 可以获得更高的准确率,但也需要更多的参数和计算。为此文章进行了一系列优化,包括
- 移除只有一条输入边的节点,因为这些节点没有特征融合,作用不大;
- 在同级的输入和输出节点间加入一条额外的边,以此在不引入额外消耗的条件下融合更多特征;
- 将双向的路径看成是一个特征网络层,将同样的结构重复多次,获取更高级的特征融合。
最终得到的 BiFPN 结构如 Figure 2(d) 所示。
2.3. 加权特征融合
融合不同尺寸的特征时,常见的方法式先将它们调整到相同尺寸,再进行相加,无差别地对待所有特征。文章发现不同分辨率的输入特征对输出有不同的贡献,因此为每一个输入添加了一个额外的权重,让网络学习每个输入特征的重要性。文章给出了三种不同的加权融合方法:
- 无边界融合:O=∑iwi⋅Ii,其中 wi 是一个可学习的权重,可以是标量(对每个特征加权)、向量(对每个通道加权)或多维张量(对每个像素加权)。由于权重是无界的,存在导致训练不稳定的风险,因此文章通过对权重进行归一化来限制权重的范围。
- 基于 softmax 的融合:O=∑iewi∑jewi⋅I,通过 softmax 对权重进行归一化。但文章发现 softmax 在 GPU 上计算较慢,为了降低延迟,文章提出了一种快速的融合方法。
- 快速归一化融合:O=∑iwiϵ+∑jwj⋅I,这里的 wi 会先通过 ReLU 来保证 wi≥0,ϵ=0.0001 用于避免数值不稳定。归一化后的权重取值在 0 和 1 之间,没有使用 softmax 因此效率更高。实验发现快速归一化和 softmax 的准确率非常接近,但前者在 GPU 上的速度要比后者快 30%。
最终得到的 BiFPN 整合了双向跨尺度连接和快速归一化融合,如 Figure 2(d) 所示。以第 6 层为例,有
Ptd6=Conv(w1⋅Pin6+w2⋅Resize(Pin7)w1+w2+ϵ)Pout6=Conv(w1′⋅Pin6+w2′⋅Ptd6+w3′⋅Resize(Pout5)w1′+w2′+w3′+ϵ)
其中 Ptd6 为第 6 层从上到下路径上的中间特征。其他特征都通过类似地方式构造得到。
4. EfficientDet
4.1. EfficientDet 架构
文章基于 BiFPN 设计了名为 EfficientDet 的检测模型,如 Figure 3 所示。网络使用 EfficientNet 作为主干网络,使用 BiFPN 作为特征网络,使用主干网络中第 3 到 7 层的特征 {P3,P4,P5,P6,P7},重复使用双向特征融合(BiFPN Layer),最后将融合的特征送往分类网络和边界框预测网络。分类和边界框预测网络的权重在所有层级的特征上共享。
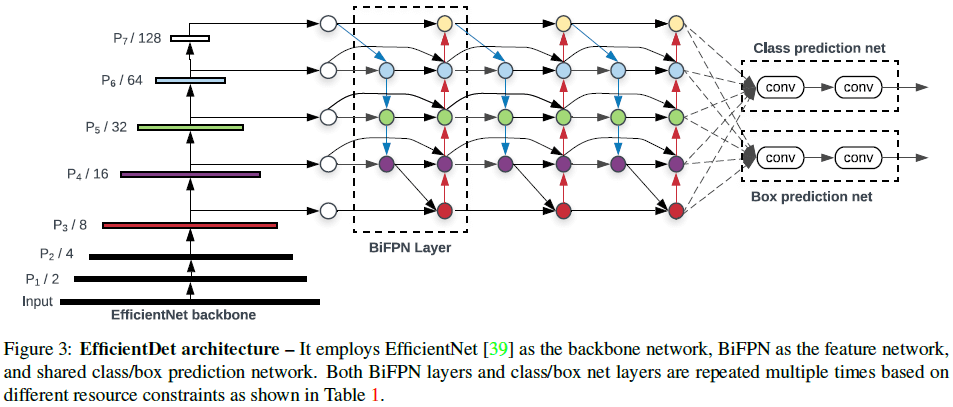 Figure 3
Figure 34.2. 组合缩放
文章希望给出一组能满足不同计算约束的模型,这里的主要挑战是如何对基线的 EfficientDet 进行缩放。之前对网络进行放大的方法通常是使用更大的主干网络、使用更高的输入分辨率、使用更多的 FPN 层,这些方法只关注于一个或有限的几个维度。
参考 EfficientNet 中的组合缩放方法,文章提出了一种用于目标检测的组合缩放方法,通过缩放系数 ϕ 来同时对主干网络、BiFPN、分类/边界框预测网络和输入分辨率进行缩放。由于目标检测任务中可供缩放的维度很多,在所有维度上进行网格搜索的代价太大,文章采用了一种启发式的搜索方式。
4.2.1. 主干网络
对于主干网络,文章采用了和 EfficientNet-B0 到 B6 相同的宽度和深度缩放,由此也可以复用 EfficientNet 的 ImageNet 预训练模型。
4.2.2. BiFPN 网络
文章线性地增加 BiFPN 的深度 Dbifpn(层数),因为深度通常是一个小整数。参考 EfficientNet,指数地增加 BiFPN 的宽度 Wbifpn(通道数),通过对 {1.2,1.25,1.3,1.35,1.4,1.45} 这一系列值进行网格搜索,找到了最佳的 BiFPN 宽度缩放系数为 1.35。由此得到对 BiFPN 宽度和深度的缩放方法为
Wbifpn=64⋅(1.35ϕ),Dbifpn=3+ϕ
4.2.3. 边界框/类别预测网络
对边界框/类别预测网络,其宽度与 BiFPN 相同(Wpred=Wbifpn),但深度通过下式线性增加:
Dbox=Dclass=3+⌊ϕ/3⌋
4.2.4. 输入图像分辨率
BiFPN 使用了第 3 到 7 层的特征,Pini 特征的分辨率为输入图像的 1/2i,因此输入分辨率必须能被 27=128 整除,于是使用下式线性地增加分辨率:
Rinput=512+ϕ∗128
通过在式 (1)、(2)、(3) 中使用不同的 ϕ,得到从 EfficientDet-D0(ϕ=0)到 EfficientDet-D7(ϕ=7),如 Table 1 所示。Table 1 中的 D7x 使用与 D7 相同的分辨率,但是用了更大的主干网络,以及一个额外的特征层(从 P3 到 P8)。
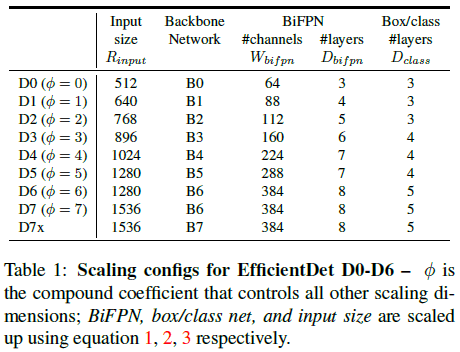 Table 1
Table 15. 实验结果
5.1. 目标检测
文章测试了 EfficientDet 在 COCO 2017 检测数据集上的性能,网络使用了 SiLU(Swish-1)激活函数和 focal loss,并使用了水平翻转和缩放扰动进行数据增强,测试结果如 Table 2 所示。可见 EfficientDet 具有最高的效率,比其他检测器小 4x – 9x,FLOPs 少 13x – 42x,广泛覆盖了各种准确率和资源限制。其中 EfficientDet-D0 准确率与 YOLOv3 类似,但 FLOPs 少 28x;EfficientDet-D7x 取得了最高的 55.1 AP,超过之前最佳性能模型的同时具有更少的 FLOPs。
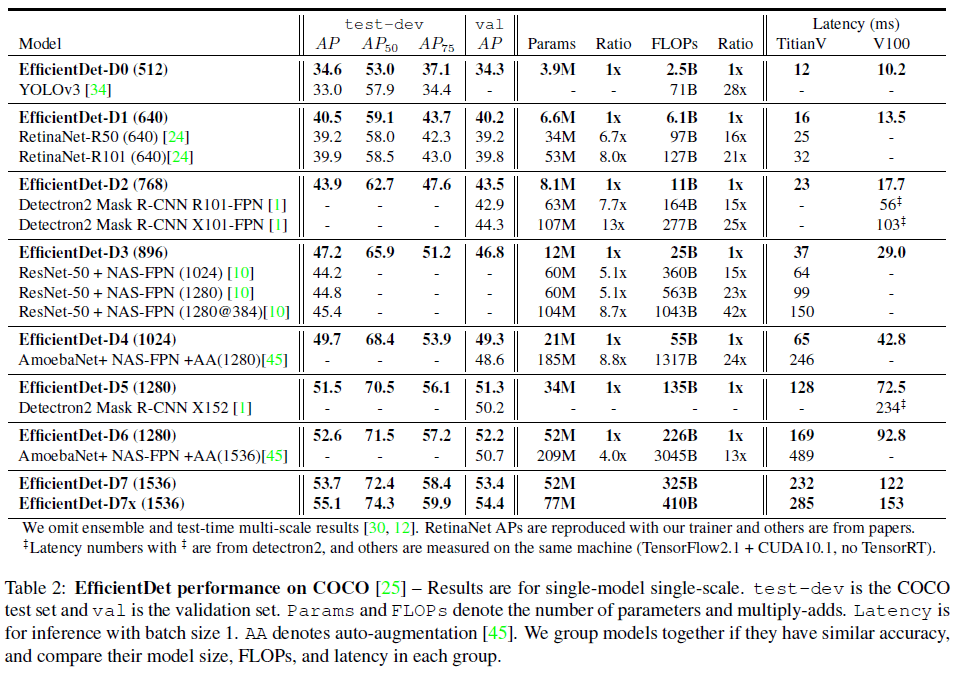 Table 2
Table 2各模型在模型尺寸、GPU/CPU 延迟上的比较如 Figure 4 所示。可见 EfficientDet 最多可以让模型尺寸减少 8.7x,并降低 4.1x 的 GPU 延迟和 10.8x 的 CPU 延迟,表明 EfficientDet 在真实硬件上也足够高效。
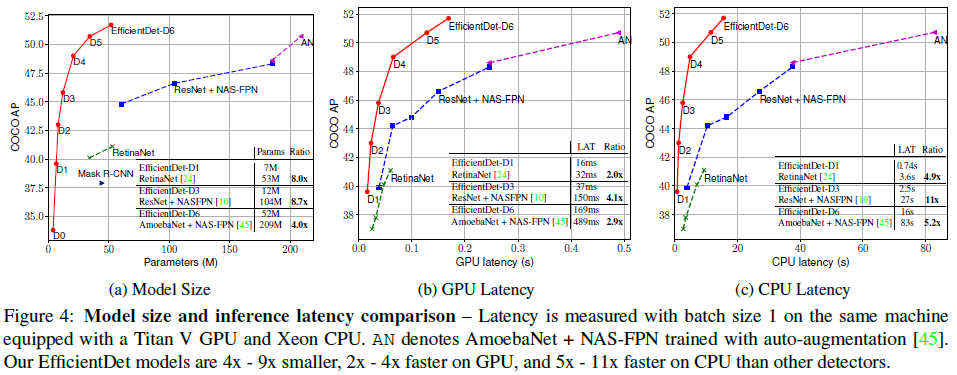 Figure 4
Figure 45.2. 语义分割
虽然 EfficientDet 主要是针对目标检测任务设计的,文章也测试了它在语义分割任务上的性能,如 Table 3 所示。可见 EfficientDet 使用更少的 FLOPs 获得了超过了 DeepLabV3+ 的性能。
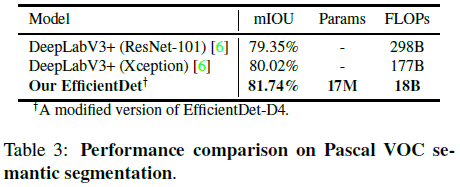 Table 3 /figcaption>
Table 3 /figcaption>6. 消融研究
6.1. 分离主干和 BiFPN
文章尝试了主干网络和 BiFPN 的不同组合,来了解二者对准确率和效率的贡献,如 Table 4 所示。可见在同使用 FPN 时,使用 EfficientNet-B3 主干的 AP 要高于 ResNet50,同时前者的参数量和 FLOPs 都更少。在同使用 EfficientNet-B3 作为主干时,BiFPN 的 AP 要高于 FPN,同时前者的参数量和 FLOPs 也都更少。可见 EfficientNet 主干和 BiFPN 对准确率和效率的提升都很重要。
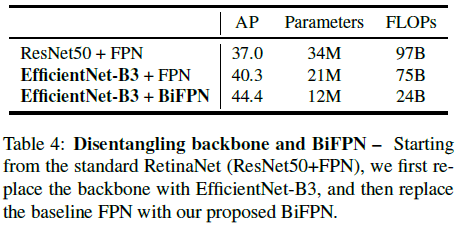 Table4
Table46.2. BiFPN 跨尺度连接
文章比较了使用 Figure 2 中不同跨尺度连接的性能,如 Table 5 所示。可见 Repeated top-down FPN 只有单向的信息流动,AP 最低;BiFPN 的效果与 FPN+PANet 接近,但具有更少的参数量和 FLOPs。
 Table 5
Table 56.3. Softmax 和快速归一化融合
文章比较了 2.3. 中 softmax 和快速归一化融合的性能如 Table 6 所示,可见二者的 AP 接近,但快速归一化融合的速度要快得多。
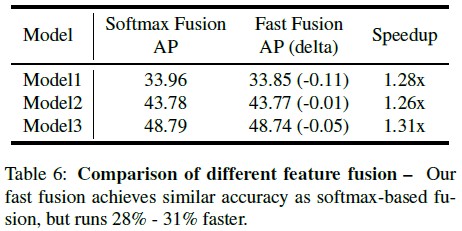 Table 6
Table 6文章从 BiFPN 层中随机选择了 3 个特征融合节点,绘制了它们在训练过程中的权重如 Figure 5 所示,可见二者具有类似的学习行为。
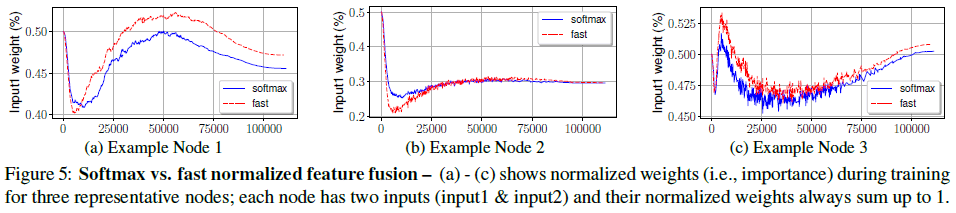 Figure 5
Figure 56.4. 组合缩放
Figure 6 比较了在同一个基线网络上使用各种缩放方法的效果,可见在相同 FLOPs 上,使用组合缩放的网络能够获得更高的 AP。
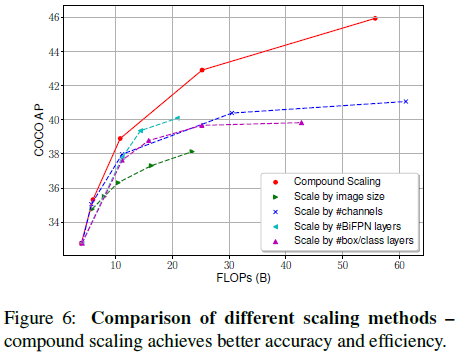 Figure 6
Figure 6Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK