

[Reading] Focal Loss for Dense Object Detection
source link: https://blog.nex3z.com/2021/04/09/reading-focal-loss-for-dense-object-detection/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
[Reading] Focal Loss for Dense Object Detection
Author: nex3z 2021-04-09
Focal Loss for Dense Object Detection (2017/8)
Contents [show]
文章的主要贡献有:
- 提出了 focal loss 损失函数,通过降低容易分类的样本的权重,应对目标检测任务中正负样本数量不平衡的问题。
- 设计了 RetinaNet 目标检测网络来验证 focal loss 的效果,使用 focal loss 训练时,RetinaNet 以单阶段检测器的速度,超过了两阶段检测器的准确度。
在目标检测任务中,单阶段检测器通常速度很快,但准确率不如两阶段的检测器。文章发现单阶段检测器准确率较低的原因在于,训练时前景和背景类别极度不平衡。如 R-CNN 之类的两阶段检测器在生成候选区域的时候,会不断地降低候选区域的数量(1~2k),过滤掉大部分背景样本;在分类阶段,也会使用启发式采样,如限制前景和背景样本的比例(如 1:3),或者使用在线难例挖掘(Online Hard Example Mining,OHEM),维持前景和背景的平衡。而单阶段检测器需要处理大量不同位置、尺寸和长宽比例的候选框(~100k),即便使用类似的启发式采样,训练仍会被容易分类的背景类所主导。
类别不平衡是目标检测中的经典问题。一方面大量简单的负例不提供有用的学习信号,会导致训练变得低效;另一方面训练被简单的负例主导,导致模型劣化。这类问题一般通过自举(bootstrapping)和难例挖掘来处理。
针对类别不平衡的问题,文章提出的 focal loss 损失函数通过缩放因子 (1–pt)γ,动态地对交叉熵损失进行缩放,如 Figure 1 所示。随着对样本预测信心的增加,样本的缩放因子逐渐降低到 0,由此可以自动地降低容易样本的权重,让模型专注于难例。文章同时发现,focal loss 的具体形式并不重要,还有一些其他的形式可以达到类似的效果。
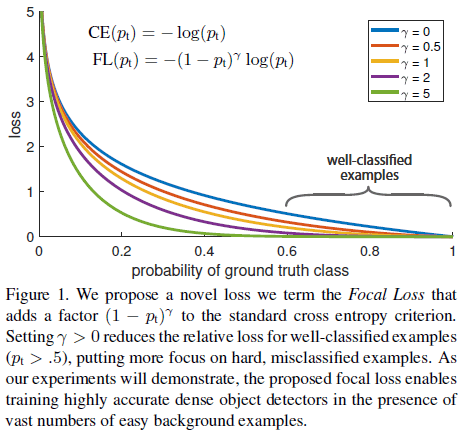 Figure 1
Figure 1为了验证 focal loss 的效果,文章设计了一个简单的单阶段目标检测器,称为 RetinaNet,retina 指网络会对目标区域进行密集采样。RetinaNet 结合了 RPN 中的锚点框,以及 SSD 和 FPN 中的特征金字塔。以 ResNet-101-FPN 作为主干的 RetinaNet 使用 focal loss 训练后,在 COCO 上的性能超过了之前最好的单阶段和两阶段检测器,如 Figure 2 所示。
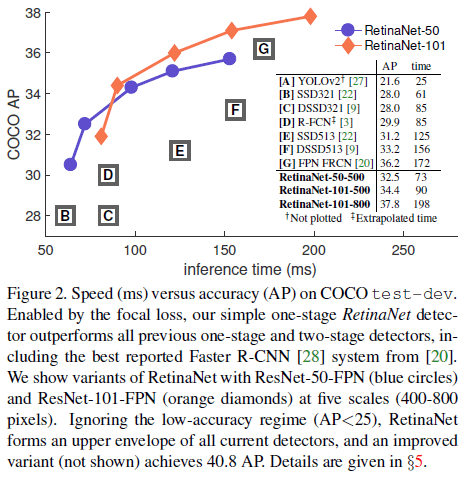 Figure 2
Figure 2值得注意的是,设计损失函数的一个方向是设计具有鲁棒性的损失函数,如 Huber loss 对具有较大误差的离群点进行降权。而 focal loss 与之相反,对群内的简单样本进行降权,使得训练专注于稀疏的难例。
2. Focal Loss
二分类的交叉熵(Cross Entropy,CE)损失定义为
CE(p,y)={−log(p)if y=1−log(1–p)otherwise
其中 y∈{±1} 为真实类别,p∈[0,1] 为模型估计 y=1 的概率。定义
pt={pif y=11–potherwise
则有 CE(p,y)=CE(pt)=−log(pt)。交叉熵损失如 Figure 1 中的蓝线所示,可见对于非常简单的样本(pt≫0.5),仍会引入相当程度的损失。大量简单样本的损失加起来,就会盖过稀少类别的损失。
2.1. 平衡的交叉熵
处理类别不平衡的一个常见方法是在交叉熵中引入一个权重因子 α∈[0,1],正例的权重为 α,负例的权重为 1–α,即
CE(pt)=−αtlog(pt)
αt={αif y=11–αotherwise
α 通常设置为逆类别频率(inverse class frequency),或者作为超参数通过交叉验证得到。
2.2. Focal Loss 定义
文章指出,虽然式 (3) 中的 α 可以对正例和负例进行平衡,但它并不能区分难例。文章提出的 focal loss 则通过降低容易样本的权重来突出难例,其形式为
FL(pt)=–(1–pt)γlog(pt)
上式在交叉熵的基础上添加了 (1–pt)γ 作为调整因子(modulating factor),γ≥0 是一个可调整的注意力参数,γ∈[0,5] 的图像如 Figure 1 所示。
式 (4) 也可以写成
FL(p)={−(1–p)γlog(p)if y=1−pγlog(1–p)otherwise
可见当 y=1 时:
- 如果 p 很小,则调整因子 (1–p)γ 接近 1,损失几乎不受影响;
- 如果 p→1,则调整因子 (1–p)γ→0,进行了降权。
通过 γ 可以调整对简单样本进行降权的速度,当 γ=0 时,FL 等同于 CE;随着 γ 的增加,调整效果越来越明显。文章发现当 γ=2 时可以获得最佳效果。
实践中,文章发现带 α 平衡的 focal loss
FL(pt)=–αt(1–pt)γlog(pt)
效果略优于式 (4) 的版本。文章同时指出,focal loss 的具体形式并不重要,还有一些其他的形式可以达到类似的效果。
2.3. 类别不平衡和模型初始化
对于二分类模型,默认会将模型初始化为等概率地输出 y=−1 或 1。但在类别不平衡的场景下,占比较多的类别会主导损失,并导致训练早期的不稳定。为此文章在初始化时引入先验知识,使得模型在初始阶段对稀少类别(前景)输出的较低的概率,见下文 3.2.3。
2.4. 类别不平衡和两阶段检测器
两阶段的检测器在训练时通常使用交叉熵,没有使用 α 进行平衡,而是通过两阶段的级联和有偏的小批量采样,来应对类别不均衡的问题。检测的第一阶段在生成候选区域时,会将可能有位置的区域数量缩减至一两千,而且这些区域不是随机生成的,而是可能存在物体的区域,由此就移除了大部分简单的负例。在第二阶段的训练中,会控制正例和负例的比例(如 1:3),相当于通过采样隐式地使用了 α 进行平衡。相比之下,本文通过 focal loss 从代价函数的角度在单阶段系统中解决类别不平衡的问题。
3. RetinaNet 检测器
RetinaNet 包含一个用于计算卷积特征的主干网络,以及两个分别用于分类和边界框回归的子网络,如 Figure 3 所示。
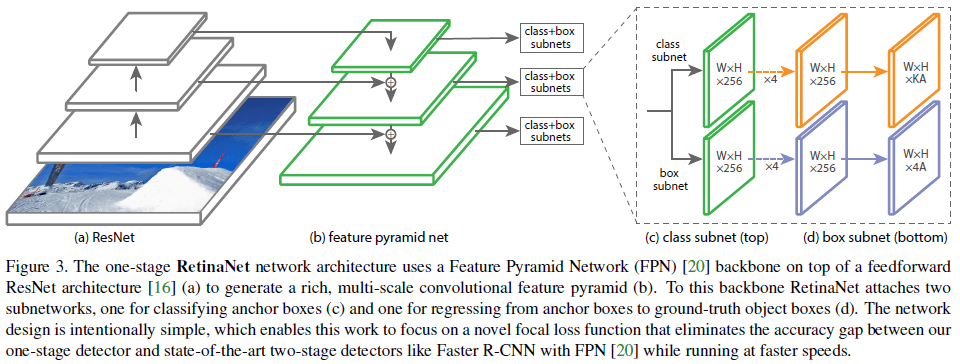 Figure 3
Figure 33.1. 网络结构
3.1.1. 特征金字塔
文章使用 FPN(Feature Pyramid Network)作为主干网络,FPN 通过在标准的卷积网路中加入一条自顶向下的路径和横向连接(lateral connection),有效地从单分辨率的输入图像中构造了丰富的、所尺度的特征金字塔,如 Figure 3 (a)、(b) 所示。金字塔的每一层都可以用来进行目标检测,提高 FCN(fully convolutional networks)对多尺度目标的检测能力。
文章在 ResNet 的基础上构造 FPN,使用 P3 到 P7 来构造特征金字塔,每层都有 256 个通道。
3.1.2. 锚点
对 P3 到 P7 的金字塔层,分别使用面积为 322 到 5122 的锚点框。在金字塔的每一层使用 {1:2,1:1,2:1} 三种长宽比。为了让锚点框覆盖得更加密集,对每种长宽比的基础锚点框,还会进行 {20,21/3,22/3} 三种倍数的缩放,这样每一层共计使用 9 种锚点框。
每一个锚点框对应一个长度为 K 的独热向量作为分类目标,和一个长度为 4 的向量作为边界框回归目标。如果锚点框与标注框的 IOU 高于 0.5,则将标注框分配给锚点框;如果 IOU 在 [0,0.4) 之间,则认为是背景;忽略 IOU 在 [0.4,0.5) 的锚点框。每个锚点框最多分配一个对象,因此分类目标是一个独热向量。边界框回归的目标是锚点框相对于所分配标注框的偏移。
3.1.3. 分类子网络
在每个 FPN 层之后,使用一个小的 FCN 子网络对目标进行分类,这个分类子网络的参数在所有金字塔层级共享。分类子网络的结构很简单,先是 4 个 3×3 卷积层,每层有 C 个过滤器,使用 ReLU 激活函数;对于 K 个类别和 A 个锚点框,使用一个有 KA 个 3×3 过滤器的卷积层,在每个空间位置上预测 KA 个值,如 Figure 3(c) 所示。文章使用 C=256 和 A=9。
3.1.4. 边框回归子网络
边框回归子网络与分类子网络平行,用于将锚点框回归到对应的物体上,网络结构也与分类子网络平行类似,只是在最后一层在每个位置上给出 4A 个线性输出,如 Figure 3(d) 所示。
3.2. 推理和训练
3.2.1. 推理
推理时,一张图像经过网络的一次前向传播,即可得到检测结果。为了提高速度,可以按 0.05 的置信度过滤后,只解码每层分数排名前 1000 的检测框,然后将所有结果汇总起来,按 0.5 的 IOU 门限进行 NMS,得到最终的检测结果。
3.2.2. Focal Loss
在训练时使用了式 (5) 所示的 focal loss,文章发现 γ∈[0.5,5] 时网络都很稳定,使用 γ=2 时效果很好。不同于 RPN 的启发式采样和 SSD 的难例挖掘,对每张图像,focal loss 会使用全部的约 100k 个锚点框,将所有的损失加起来,作为图像的总 focal loss,然后在使用被分配了标注框的锚点框数量进行归一化。注意这里没有使用全部锚点框的数量进行归一化,因为大部分锚点框都是简单的负例,由 focal loss 产生的损失很小。
对于式 (5) 中稀有类别的权重 α,虽然在一个范围内也能发挥稳定的效果,但应与 γ 联合调整,如 Table 1a、1b 所示。当 γ 增加时,应降低 α。文章使用 γ=2,α=0.25。
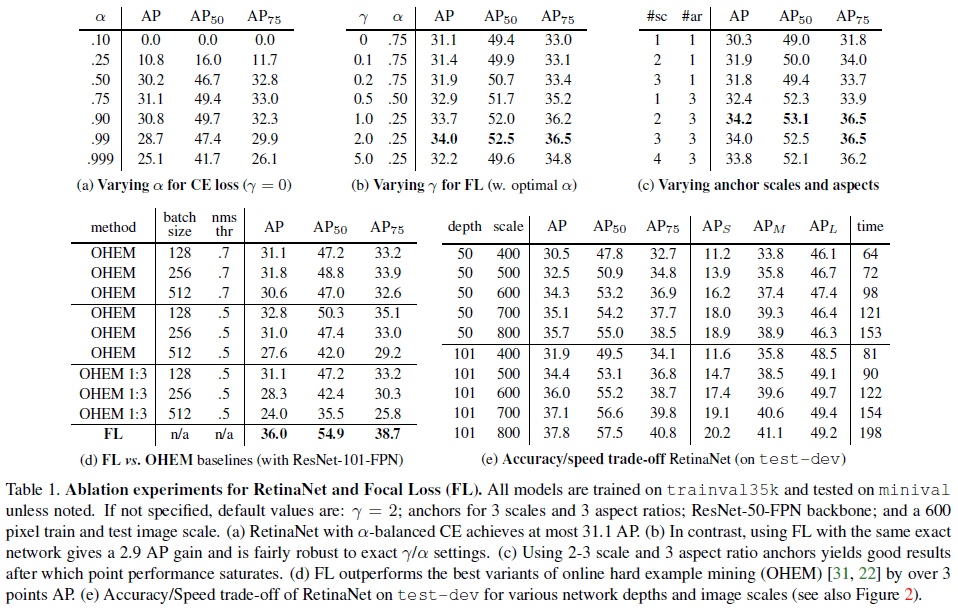 Table 1
Table 13.2.3. 初始化
文章分别尝试了 ResNet-50-FPN 和 ResNet-101-FPN 作为主干网络,二者都在 ImageNet1k 上进行预训练。FPN 新加的层中,除了最后一层外的卷积层都初始化偏置 b=0 ,使用 σ=0.01 的高斯分布初始化权重。分类子网络的最后一个卷积层初始化 b=−log((1–π)/π),其中 π 为训练开始时将每个锚点框预测为前景的置信度,文章使用 π=0.01。这样的初始化可以避免大量的背景锚点框在训练初期产生过大的、不稳定的损失。
3.2.4. 优化
文章使用 SGD 训练 RetinaNet,只使用了随机的水平翻转作为数据增强,训练损失为分类的 focal loss 和边界框回归的 smoothL1 loss 之和。
4. 实验结果
4.1. 训练密集检测
4.1.1. 网络初始化
文章尝试了只使用标准的交叉熵和初始化方法,网络在训练时发散了。仅通过使用 3.2.3. 的初始化方法,网络就可以获得有效的学习,训练得到的 RetinaNet(ResNet-50)在 COCO 上获得 30.2 的 AP。同时文章发现实验结果对 π 的取值不敏感,选择使用 π=0.01。
4.1.2. 平衡的交叉熵
使用如式 (3) 的平衡交叉熵的结果如 Table 1a,当取 α=0.75 时获得最高的 31.1 AP。
4.1.3. Focal Loss
使用 focal loss 时,引入了额外的超参数 γ,随着 γ 的增大,简单的样本会获得更小的权重。不同 γ 的效果如 Table 1b,可见 γ=2 时可以获得最佳的 34.0 AP,比使用平衡交叉熵的最佳 AP 高 2.9。
文章还尝试了为各种 γ 寻找合适的 α,在测试了 α∈[0.01,0.999] 后,发现最佳的 α 位于 [0.25,0.75],但调整 γ 的效果要远大于调整 α。文章最终选择了 γ=2.0 和 α=0.25。
4.1.4. 分析 Focal Loss
文章使用训练好的 RetinaNet 对一系列随机图像进行检测,分别计算正负例窗口的 focal loss 损失,归一化后计算累积分布函数(CDF)如 Figure 4 所示。可见对于正例,使用不同 γ 得到的 CDF 都很相似,约 20% 的难例贡献了大约一半的正例损失。对于负例,当 γ=0 时得到与正例相似的 CDF,随着 γ 的增加,难例的权重越来越大,当 γ=2 时,绝大部分的损失都来自于很小一部分的样本。可见 focal loss 可以降低容易的负例的权重,从而将注意力集中在困难的负例上。
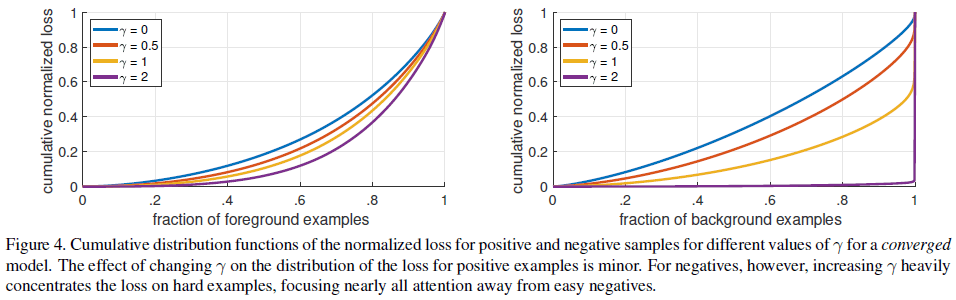 Figure 4
Figure 44.1.5. 在线难例挖掘(Online Hard Example Mining,OHEM)
OHEM 使用损失对样本进行打分,经过 NMS 后,使用具有最高损失的样本构造小批量。与 focal loss 相比,OHEM 同样会给错误分类的样本更高的权重,但二者的不同之处在于 OHEM 会完全丢弃容易的样本。SSD 中使用了 OHEM 的一种变体,即在 NMS 后构造小批量时,保证正例和负例的比例为 1:3,使得小批量中包含足够的的正例。文章测试了这两种形式的 OHEM,结果如 Table 1d 所示,可见 focal loss 比 OHEM 更有效。
4.1.4. Hinge Loss
文章还尝试了在 pt 上使用 hinge loss,即对大于特定值的 pt 设置损失为 0。这样会导致不稳定,无法得到有意义的结果。
4.2. 模型设计
4.2.1. 锚点密度
单阶段的检测器在固定的采样网格的各个位置上使用多个锚点框进行检测,以检测不同尺度和长宽比的对象。文章尝试了 4 种不同的尺度(2k/3,for k≤3)和 3 中不同的长宽比([0.5,1,2]),结果如 Table 1c 所示,表头的 sc 表示 scale,ar 表示 aspect ratio。可见只使用 1 个正方形锚点框就可以得到相当好的效果,文章选择使用 3 种尺度和 3 种长宽比。
4.2.2. 速度和准确率
使用更大的主干网络可以获得更高的准确率,但也会降低检测速度,如 Table 1e 所示。Figure 2 绘制了速度和准确率的取舍情况。通过使用更大的分辨率,RetinaNet 具有超过两阶段检测器的准确率和速度。
4.3. 性能比较
RetinaNet 和其他网络的比较如 Table 2 所示。可见使用 ResNet-101-FPN 的 RetinaNet 达到了 39.1 mAP,超过了两阶段的 Faster R-CNN。使用 ResNeXt-101-FPN 主干网络后,RetinaNet 进一步获得了 40.8 的 mAP。
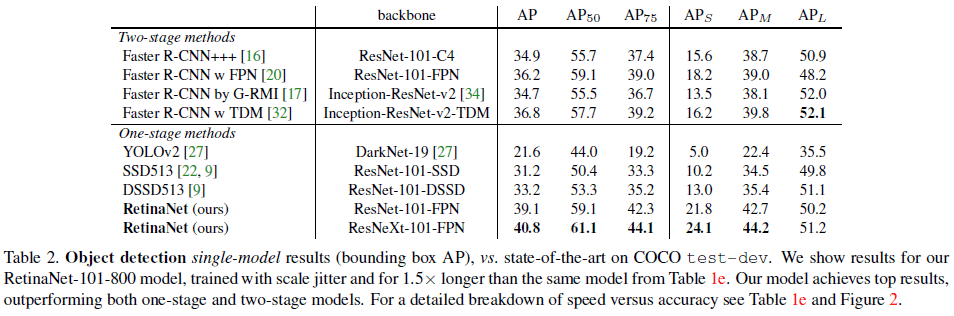 Table 2
Table 2Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK