

隐私保护,在法规以外更依赖技术
source link: https://zhuanlan.zhihu.com/p/124242485
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
隐私保护,在法规以外更依赖技术
前两天,Tectonix出了个视频,展示了春假期间迈阿密海滩的人群,几天内是如何散布到全美国的。如此大规模位置信息的追踪,可以说是疫情防控的定海神针。但是,相关隐私问题的来龙去脉和行业现状,也需要深入理解。
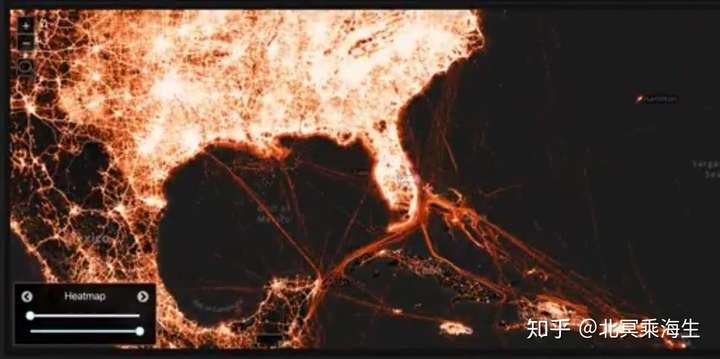
首先,我们要正视一个现实:今天的互联网服务,已经深深植根于用户数据,并且创造了巨大价值。如果一定要对用户数据使用层层设防,无异于在倡导大家不用电器一样荒唐。
为了严控隐私数据收集和使用,欧盟颁布了号称“史上最严格隐私保护”的GDPR标准。据估算,严格执行这个标准的话,实施成本可能就要上百万美金,小公司其实无法践行。用力这么猛,真的能解决问题么?
依我看,隐私问题如同大禹治水,宜疏不宜堵,主要靠技术而非法规解决。只有在中美这种互联网产业高度发达的市场,才能产生足以对抗隐私侵犯的技术。实际上,这方面的法规和技术能力,近两年都在逐渐清晰化。只是由于中国互联网早期的粗犷发展,大家出于惯性而疑虑重重。
当然,部分用户隐私问题,确实可以通过法规约束来解决或改善。
您肯定用过这种软件,像忠实粉丝一样,疯狂地要求授权,痴迷地收集着你的个人数据:办公软件要GPS,天气预报要摄像头,不论谁都要麦克风。这都是些什么操作?难道用软件还得面带微笑、文明表达,要不然就算不上优秀用户,需要定点清除么?显然,这些明显超出使用范围的过度授权,都是对用户隐私的侵犯。
对于提供综合性互联网服务的大平台而言,获得的数据自然更加多维,所生成的用户画像也更精准一些,不过在合规基础上的数据收集也只是为了让广告的投放更有价值,不必太过担心。但是,相比对平台可能存在的数据过度收集问题,我们更应该警惕的是大数据黑产。
卖数据,并不是给广告主几个兴趣标签这么简单。怕的是把地址和电话给无良商家,直接往你家里发货到付款的快递。你糊里糊涂收完了打开一看,原来就是块泡沫塑料!这可是真金白银的损失了。
这引出了隐私领域的一个重要概念:像地址、电话、邮箱这些能直接找到你的信息,泄露给陌生人风险很大。这些信息,叫做“个人可定位信息(Personal Identifiable Information,PII)”。
近年来法规趋严,从主观意图上看,PII数据的泄露风险已经很低了。毕竟,掌握大量PII信息的都是有一定规模的公司。而如今,卖五十条用户数据就要负刑事责任,为了这点小钱铤而走险的公司,恐怕早就倒闭了。
那么,这些信息是怎么流出来的呢?多数情况下,是因为内部人员的泄露。显然,这里有技术管理的问题。
研发人员因为统计和建模的需要,总要接触到用户数据,这就不可避免有泄漏的风险。上回,某公司的用户电话和地址泄露,不就是技术往外卖的么?
怎么办呢?可以建立这样的数据使用框架:产品技术人员只能访问一小部分采样用户数据,用以调试程序;而全量数据上的分析,则在与开发人员隔离的账号上提交执行。这样,就可以有效避免内部人员批量获得用户数据。
实际上,以欧盟的GDPR为代表的隐私保护法规,其主要内容除了在管理流程上做文章,对数据范围限定的部分主要聚焦在PII。
那么除了PII以外的数据,又能带来多大的隐私风险呢?其实,文章开始的例子已经给了我们答案:想想看,只要给出你的某个熟人几天的数据轨迹,即使像是一些日常人际交往、外出旅行等非敏感信息,以你对他的了解,是不是也很容易认出他是谁?
这也就意味着,仅靠管理权限和限定敏感数据的收集是不够的,我们还需要从技术手段进行有效的个人信息保护。
我们之所以能认识到这样的风险,是因为Netflix的推荐算法大赛。那次比赛的任务是:根据某用户对看过电影的评分,预测他对某一部新电影的评分。当然,在数据集里,用户的PII信息都是被抹去了的。
无巧不成书,有位参赛者在浏览数据时,无意中翻到一条记录。看此人的观影记录和评价,这不就是某某同事嘛!为什么这么肯定?因为他们俩经常交流电影,结合观影时间、片单和评价,正好能和这位某某同事一一呼应上。
于是,这位参赛者定睛又一看,同事的记录里还有些同性恋题材的片子,是从未提起过的。显然,这个数据集以始料未及的方式,泄露了他的隐私。该同事得知后怒不可遏,一纸诉状将Netflix告上了法庭。于是,推荐算法大赛只办了一届,就寿终正寝了·。
《纽约时报》在2010年3月16日的《How Privacy Vanishes Online》文章报道看来,即使不是位置信息,由于人的行为千差万别,一旦通过行为数据关联找到某个熟人,就可以发现他的更多秘密,这称为行为数据引起的去匿名化风险。
互联网上的个体行为数据,即使不是敏感的PII信息,在公开或交换时也要相当谨慎。
既然能通过行为数据去匿名化,那我们能不能空手套白狼呢?比如我们知道一个人的少量信息,然后像滚雪球一样,这边撸点儿,那边撸点儿,最后就能把这个用户查个底儿掉。
实际上这是可以实现的。具体怎么做呢?其实,玄机就在很多广告平台都提供的受众分析功能里。
比方说,我想知道某用户A的性别,可以先指定一个十人用户集,在平台拉出男性其占比是60%;然后,把A加入用户集,再查出男性占比是54.5%;两个比例做简单计算,是不是就可以知道A是女性了?
这叫差分隐私攻击,它是通过平台提供的聚合数据分析做差分运算,探知某个具体用户的信息。但兵来将挡水来土掩,大企业也有自己的防御方案,基本思想是在数据上加扰动,让差分攻击失效。
就我了解的案例,腾讯广告在提供受众分析时,就实现了对抗差分隐私攻击的方案:在给广告主提供的受众分析上,系统会加上一定的随机扰动,这样一来,简单直接的差分就无效了。
那我多拉几次数据取平均,不就可以去掉随机扰动了?没错。所以,系统还要让这个随机扰动,在一定时间内保持相对稳定。其中的技术细节很多,就不赘述了。
对于设备制造商来说,也可以在数据获取到云端时,实现差分隐私保护。这样一来,云端再有多么复杂的数据应用和交换,风险也都不大了。苹果手机从iOS10起,就引入了这样的方案。
总之,差分隐私问题要求我们,即使在提供人群上的聚合数据时,也需要精心设计算法,否则就如同裸奔。不过不用太担心,因为现在拥有大规模数据的平台,已经有了这方面的考虑和实践方案,否则不可能走得远。
有人说,只要有数据交换,我作为普通用户就还是不放心。那么,能不能根本不收集数据,又能完成系统必须的建模任务呢?这引出了一个有趣的新技术方向——联邦学习(Federated Learning)。
举个例子,输入法要根据用户的实际输入数据优化模型,如果不把数据收集到云端,能不能做呢?2017年,谷歌的研究员发表文章“Federated Learning :Challenges, Methods and Future Directions”,提出了这个研究方向。简单地理解概念,就是把模型下发到各个数据拥有方,它们分别更新以后,再到一个聚合方,同步成新的模型。整个流程如下图所示:
也就是说,不再需要从各个数据拥有方那里收集和交换数据,也可以完成建模的任务!当然,联邦学习具体的实现技术,以及适用于哪些场景,还是相当前沿的研究课题。如果想深入了解产业界这方面的问题和进展,建议大家参考微众银行的《联邦学习白皮书1.0》。
显然,利用联邦学习技术,可以在不将用户设备数据同步到云端的前提下,完成一些建模任务。比如,谷歌在输入法的“下一词预测”问题中,采用了此方案,并且取得了优于服务器端集中训练的性能。
联邦学习除了用于用户和平台之间的数据交换,还可以用于几家公司合作时,各自数据不便外流,又要完成联合建模的场景。最典型的例子,是相似人群拓展(Look-alike)问题:广告主甲有自己的种子用户,希望利用广告平台乙,拓展出相似人群,定向投放广告。
由于去匿名化风险,乙不会把用户数据交给甲;而甲考虑到信息安全或是法规限制(比如银行业),有时也不能把数据交给乙。显然,采用联邦学习的方法,也可以实现这一建模任务。
最近,微众银行与腾讯广告RTA有一个应用案例,里面就提到了联邦学习技术。我们有理由期待,这样既保护了各方数据安全,又可以基于用户数据进行建模的方案,会逐渐成为业界的显学,而用户的隐私保护问题,最终会被不断进击的技术所解决。
另外,蚂蚁金服也在致力解决数据孤岛的问题。在其《共享学习:蚂蚁金服数据孤岛解决方案》一文中,该项技术被称为共享机器学习(Shared Machine Learning)。近来,蚂蚁金服还在IEEE(电气和电子工程师协会)等标准化组织正式立项《共享学习系统技术框架及要求》,参与了国际标准的制定。
这么看来,隐私保护这张试卷,对欧盟的职业政客们而言,有点超纲了。因为这里除了加减法,还有微积分。如果对技术复杂性考虑不够,那就好比小学二年级毕业,就要强行给出全部标准答案。最终的唯一结果,是让互联网创业成本徒增。反而是中国互联网市场在用户和数据规模的基础上,更有可能发展出成熟的隐私保护技术,对这一点,我深信不疑。
我是@北冥乘海生,想吸收更多负能量,请大家关注我的公众号“计算广告”(Comp_Ad)和下面的知乎专栏:
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK