

鹿晗和关晓彤如何联手搞垮新浪微博服务器?
source link: http://server.51cto.com/sOS-553620.htm
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

鹿晗和关晓彤如何联手搞垮新浪微博服务器?-51CTO.COM
不知不觉,美好的十一假期已经结束了。在假期的最后一天,大约有四千万人同时失恋,我们迎来了 2017 年度最大甜蜜暴击!
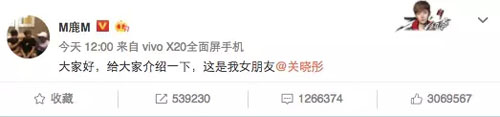
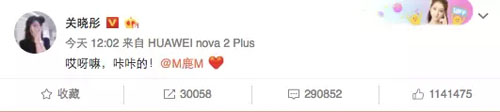
鹿晗在新浪微博高调宣布了自己的新恋情,并大方的@了女朋友关晓彤。消息一出,微博立马就炸了。
短短几个小时之后,该条微博被转发 736137 次、评论 1913926 次、点赞 4179888 次,短时间内转发评论点赞分分钟冲上百万,疯狂上涨的数字搞垮了新浪微博的服务器……


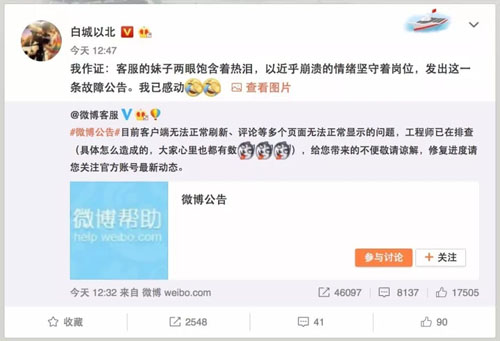
终于,新浪工程师担心的事情还是出现了:北京时间 10 月 8 日午间 12 时 32 分,新浪微博官方客服账号发布公告称,目前客户端无法正常刷新、评论等多个页面无法正常显示的问题,工程师已在排查。
对于造成这一问题的具体原因,新浪微博在公告中称“大家心里也都有数”。
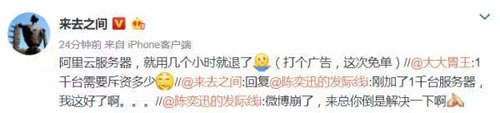
最后还是老板弄来了一千台服务器才搞定...
然而整个事件当中,除了无数粉碎的少女心,最无辜躺枪还如此敬业的小哥哥,非这位微博搜索工程师丁振凯莫属啦,结婚当日,遇鹿晗公布恋情,不得不从酒席上离开处理微博异常后继续婚礼,心疼小哥哥三秒钟......
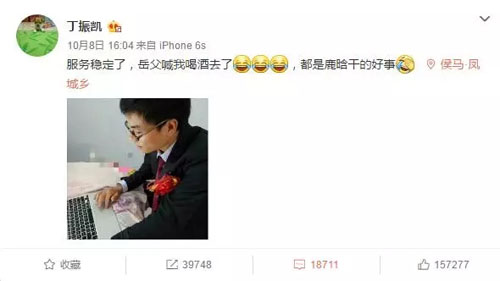
那一刻,被迫加班的程序员内心是这样的:

连今天的淘宝程序猿都是失恋了:

微博工程师眼中的「鹿晗」:

好的,言归正传,新浪服务器到底是怎么垮的?
新浪服务器是怎么垮的?
知友:苏莉安(200+ 赞,程序员话题优秀回答者)
我觉得不像数据库挂了,微博这种级别的架构根本不是简单的分布式 server+DB 就能抗住的,别说鹿晗关晓彤搞个大新闻,就算平时运营的压力也扛不住。
刚才王高飞说加一千台服务器暂时顶住了,数据库是不可能临时这么弹性伸缩的,能伸缩的无非就是 HTTP Server、各中间层服务、缓存或消息队列。
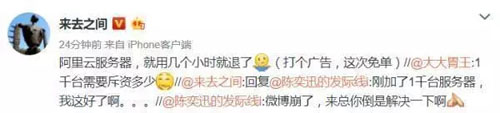
大概是微博自动扩容的算法没写好,或者没敢全交给算法来做。比如你发现流量升高了,自动下单加几十台服务器能接受,突然加一千台要是程序出 Bug 的话微博得白支出多少钱啊……多半是这个量级的扩容需要运维手工来确认。
而且是在长假最后一天的中午爆发的,不是访问高峰期,服务器也准备不足。明星公布恋情这件事又没法预警,谁知道他们啥时候心血来潮忽然介绍女朋友啊……
知友(400+ 赞)
根据目前已有的信息猜测是数据库被压垮了,先发猜想,稍后写个程序分析当时的点赞评论转发数据验证猜想。微博这样的网站,如果被大流量压垮,不太可能是非必需字段没有容错。
之前经历过几次热门事件,我相信在爆发热点新闻的时候,微博会暂时牺牲一点数据准确性来保证关键服务可用,也就是说,光读请求很难压垮微博。
根据事故时的微博点赞数、转发数、评论数、评论的回复数、评论的点赞数、转发的评论转发点赞数等的量,微博极可能是由于事发当时需要写入数据库的请求太多(写行为峰值可能达到了几十万甚至更高),以及大部分写都会落到同一条微博上,而且某些写操作还需要触发相应的其他写行为(回复评论需要通知评论者、点赞需要进关注者 feed 等),数据库压力过大扛不过来,最终跪了一会儿。
其实如果缓存做好,这时候还是可以满足核心数据读请求的(当然微博缓存做的并不好,我微博个人页数据错误很久了反馈也没用)。
如果数据库压力过大时,对部分写请求异步化,或者考虑暂时抛弃部分请求换取稳定性,当然这样也各有利弊,不一定是好的。
可以抓取当时鹿晗发的微博的所有评论转发回复点赞的时间,看下故障前几秒成功的写行为究竟有多少。
不负责任的未经验证的猜测(画图水平有限,省略了部分过程,但是从上下两个过度的箭头数,大致表达了很多请求是读且未压到数据库,将就看吧:
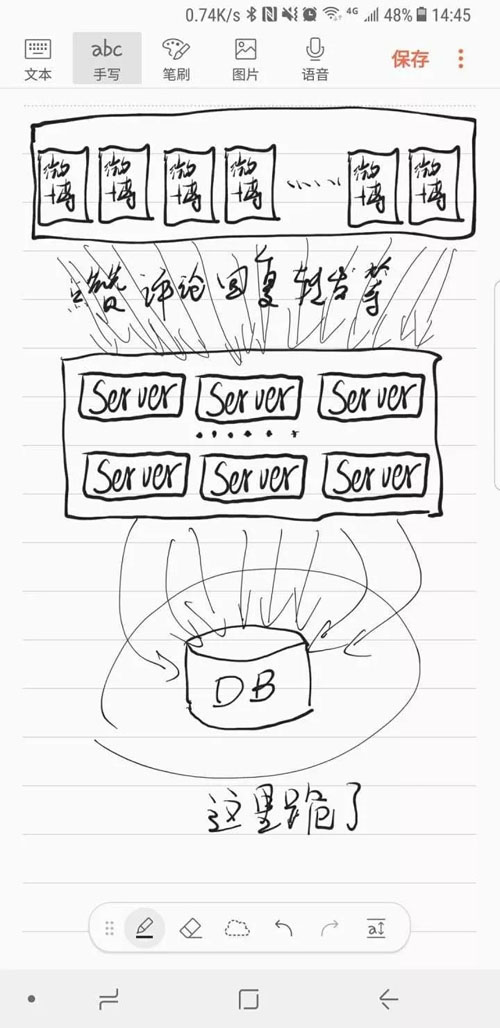
知友:佚名(150+ 赞)
让我放两张来自微博后台数据的图片:
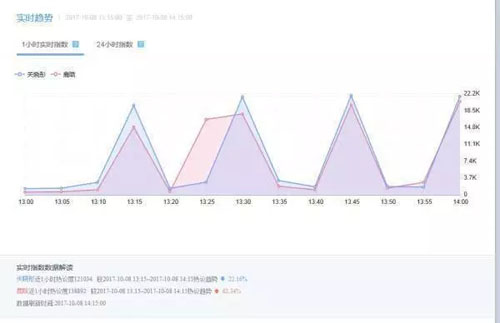
这样看可能不是很直观?
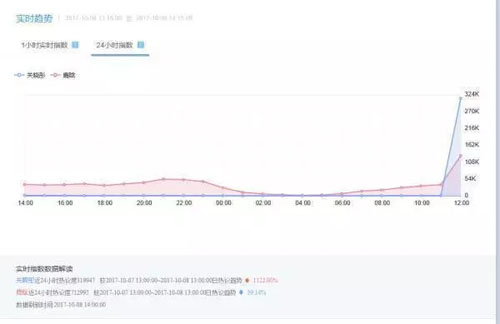
没有对比就没有伤害啊!关晓彤热议趋势硬生生涨了 1122.9%,社会社会!

如何快速提高系统性能?
回顾一下,究竟是多大的流量使得曾豪言“微博服务器稳定,能同时应付三对劈腿的”壮志秒破功,具体数据如下图所示:

按照微博明星势力榜各个榜单计分方式:满分 100 分,由阅读数、互动数、社会影响力、爱慕值四项组成,所占比例分别为30%、30%、20%、20%。
由上可以看出,鹿晗所发微博的每一项都达到了峰值,那么在如此高流量的情况之下,作为开发者是否有好的方法来快速提高系统性能呢?就鹿晗宣布恋情导致微博宕机事件浅谈大型网站高可用性架构。
作为一名程序员,我更感兴趣的是微博如何应对瞬时涌来的高并发大流量。从很久很久以前文章马伊琍的 “周一见”,到后来 “出轨队”、“吸毒队” 的争相夺分,再到前段时间的郭敬明事件、薛之谦事件,再到今天的鹿晗宣布恋情......
微博看似每次都在挂,一直都没有进步,大家每次遇到热点事件刷不出内容的时候都会吐槽微博的应用平台很辣鸡。但是呢,微博的后台系统肯定一直在重构升级优化,我觉得能够做到今天这种水平已经很不错了。
01从用户的角度(主要是我的角度 hhhhh)来看
遇到热点事件的时候微博大概率在短时间内(大约 10~15)可能会完全刷不出内容,过了一段时间之后(大约半小时)进行间隔刷新(间隔 10 秒左右),有可能某些时候会看到 5xx 的 error,5 开头的 http 状态码代表服务器或者是网关存在问题。
比如说服务器拒绝连接、网关超时或者是应用代码存在 Bug 等都会导致 5xx 的错误。在热点事件发生 1 小时内,系统应该可以恢复正常的服务。
02从网站开发、运维人员的角度来看
运维:卧槽?怎么访问流量这么高?是出啥 Bug 了吗?卧槽!不会是又有人出轨吸毒了吧?emmmm.... 我的国庆假期可还没结束啊!
运维:兄弟们,快醒醒!快加机器啊!系统要崩了!
开发:别催!再催自杀!
leader:测试在扩容之后赶紧拉出来测测!
测试:人在家中躺,锅从天上来!
上面都是我乱说的!

为什么我觉得微博在高并发大流量访问方面的表现已经很不错了呢?举个例子吧:淘宝每年在双 11 购物节的时候也要应对高并发的场景,但是这是可以提前做很多准备的。
比如说提前购买带宽资源、增加服务器资源、进行完备的异地容灾等等,很多都是可预测的。而微博呢?热点事件随时都可能发生,所以这对于微博的运维工程师来说是很大的考验。
当然,现在的运维平台也是非常的智能了,可以对各项指标进行实时监控,一有异常,马上进行短信或者邮件报警,之后就是各个岗位的工程师人肉上场调配各类资源了。
那微博在平时为什么不增加一些服务器资源呢?服务器资源、网络带宽资源等既重要,又昂贵。
由于并不是每时每刻都必须应对高并发的场景,因此如果说在平时增加了冗余的服务器资源导致大量机器空载,也是一种很大的浪费。我们在考虑提供可用服务的同时,也必须考虑一下成本。下面我就针对高可用性架构中经常会提到的几个点来讲讲。
大型网站高可用架构
不管是对于小型网站还是大型网站来说,分层都是必须的:粗粒度的分层一般为应用层、业务层和数据层。横向分层之后,可能还会根据模块的不同对每一层进行纵向的分割。
拿微博举例,我觉得它的评论模块和点赞模块应该是解耦的。越是复杂的系统,横向和纵向的分层分割粒度就会越细。很多时候你用起来以为它就是一个系统,其实后面可能是由几百上千个独立部署的系统对外提供服务。
集群
集群在大型网站架构中是一个非常非常重要的概念。由于服务器(不管是应用服务器还是数据服务器)容易发生单点问题,一旦一台服务器挂了,就必须进行失效转移。
应用服务器集群
一般来说,应用服务器必须是无状态的。什么叫无状态服务器呢?在介绍它之前,我们先来说一下状态服务器:状态服务器一般会保存请求相关的信息,每个请求会默认地使用以前的请求信息。
这样就很容易导致会话粘滞问题:如果一台状态服务器宕机了,那么它保存的请求信息 (例如 session) 就丢失了,可能会导致不可预知的问题。
那么相对的,无状态服务器就不保存请求信息,它处理的客户信息必须由请求自己携带,或者是从其他服务器集群获取。
因此无状态服务器相对于状态服务器来说更加地健壮,就算是重启服务器甚至是服务器宕机都不会丢失状态。由此引申出来的另一个优点就是方便扩容:只要在增加的服务器上部署相同的应用并做好反向代理就能对外提供正常的服务。
Session 管理
既然应用服务器是无状态的,那么用户的登录信息 (session) 如何管理呢?比较常见的有下面四种方式:
- session 复制
- 源地址 hash(session 绑定)
- 用 cookie 记录 session
- session 服务器
但是由于前三种都有很大的局限性,这里只聊聊基于集群的 session 服务器管理方式。
我们在这里是将服务器的状态进行分离:分为无状态的应用服务器和有状态的 session 服务器。
当然,这里说的 session 服务器肯定说的是 session 服务器集群。我们可以借助分布式缓存或者是关系型数据库来存储 session。
对于微博来说,这里肯定得用分布式缓存了:因为用关系型数据库的话,数据库连接资源容易成为瓶颈,并且 I/O 操作也很耗时间。
比较常见的 K-V 内存数据库有 Redis。我觉得微博内容中的赞数、用户的关注数和粉丝数用 Redis 来存应该算是比较合适的。
负载均衡
既然提到了集群,肯定得说说负载均衡。但是感觉负载均衡应该可以归类到可伸缩性里面去,所以这里就不详细讲啦,就简单说说有哪些常见的负载均衡的方式以及负载均衡算法。
负载均衡方式:
- HTTP 重定向负载均衡。
- DNS 域名解析负载均衡。
- 反向代理负载均衡。
- IP 负载均衡。
- 数据链路层负载均衡。
负载均衡算法:
- 源地址哈希。
- 加权轮询。
- 加权随机。
- 最小连接数。
插播点别的
突然想到一个比较有意思的东西:在微博的架构中,应该采用的是异步拉模型而不是同步推模型。
什么意思呢?我们举个例子:鹿晗的粉丝有 3000 多万,关晓彤的粉丝有 1000 多万。假如他俩发了条微博的同时需要往这 4000 万粉丝的内容列表中 (假设这里用的是关系型数据库) 推送过去,这就是简化的同步推模型。
那这样有什么缺点呢?首先,这样会消耗大量的数据库连接资源,更重要的是这样不太符合软件设计规范:因为对于两人的粉丝来说,分别由有 3000 多万和 1000 多万的数据是冗余的。
假如说陈赫、邓超在第一时间对他俩的微博进行了点赞,此时瓶颈就来了:刚才往数据库里插入 4000 多万感觉还可以接受,但是现在四人的粉丝数加起来好几亿了,同时往数据库插这么多数据是不是感觉不太合适?
没关系,我们现在换一种内容推送方式:我们现在不用同步推了,而是用异步拉。我们每次在手机上刷微博的时候,如果想要看到更新的内容是不是都要下拉刷新获取?没错这就是异步拉。
异步拉有什么好处呢?很明显的一个好处就是可以将热点数据进行集中管理,并且不用进行大量的数据插入冗余操作。另外对系统资源的消耗也较少。
那么微博内容从哪里拉呢?主流的解决方案是把热点内容放到缓存中,每次都去查缓存,这样可以减少 I/O 操作并且避免发生因资源枯竭造成的超时问题。
其实高可用性架构还包括服务升级、服务降级、数据备份、失效转移等等。关于网站高可用、高性能、高拓展方面感觉还有很多很多东西来写。但是有些知识没有一定的实践经验呢,又不能很好的掌握。更多深度技术内容可见:新浪微博如何应对极端峰值下的弹性扩容挑战?

Recommend
-
162
-
201
鹿晗关晓彤公开恋情 最大赢家竟然是它? 2017年10月08日 15:45:06...
-
139
https://juejin.im/entry/59da1381f265da0655057284# 此页面未在微博完成域名备案,可能存在内容风险。 如要继续访问,请注意你的隐私及财产安全。
-
133
鹿晗和关晓彤干崩了微博,围观不再改变中国,只是改变了微博-36氪鹿晗和关晓彤干崩了微博,围观不再改变中国,只是改变了微博刺猬公社·2017-1...
-
194
不少媒体人和程序员的8天长假提前提前半天被终结,只因昨天中午鹿晗和关晓彤在微博上公布恋情。两人的恋情公布之后,由于瞬间流量过大,新浪微博的服务器不堪重负,不少地区都出现了无法访问的情况。随后,微博CEO@来去之间表示,紧急租用增加了1000台服务器来应对...
-
137
十一长假行将结束之时,一波狗粮意外:90后小鲜肉鹿晗、长腿学霸女神关晓彤在微博上公开了恋情,甜蜜秀恩爱,甚至一度让微博崩溃。首先是鹿晗发微博称:“大家好,给大家介绍一下,这是我女朋友@关晓彤。”关晓彤马上回复:“哎呀嘛,咔咔的!@M鹿M。”并附上爱心图标...
-
137
我用Python爬了鹿晗、关晓彤微博的热门评论,并进行了情感分析-51CTO.COM 我用Python爬了鹿晗、关晓彤微博的热门评论,并进行了情感分析 作者:大吉大利小米酱 2017-10-10 15:42:56 相...
-
168
用python对鹿晗、关晓彤微博进行情感分析前言:本文主要涉及知识点包括新浪微博爬虫、python对数据库的简单读写、简单的列表数据去重、简单的自然语言处理(snowNLP模块、机器学习)。适合有一定编程基础,并对python有所了解的盆友阅读...
-
27
故事 事故是这样的 新开发的jar包部署在老服务器上,版本是Red Hat Enterprise Linux AS release 4 (Nahant Update 5),提示需要高版本jdk,高版本jdk提示glibc版本太低得升级,是的,就像套娃。 使用编译...
-
43
升级glibc后系统无法进入怎么办
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK