

Copying data from S3 to EBS 30x faster using Golang.
source link: https://medium.com/@venks.sa/copying-data-from-s3-to-ebs-30x-faster-using-go-e2cdb1093284
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

Copying data from S3 to EBS 30x faster using Golang.
We had a very simple problem,
Copy a large number of small images (a few KBs) from S3 to EBS
We have a legacy service that processed images in an EBS volume. These images were also backed up in S3. In case of a disaster we needed a way to quickly restore from the backup. We also needed to restore the images from S3 into an isolated environment to help with the debugging. We hoped solve both problems with the same tool.
In our journey to find a solution for this problem we
- Used the AWS CLI, only to find it was very slow.
- Implemented a naive solution in Go, which crashed spectacularly.
- Understood a bit more about Go’s scheduler, and under what conditions the runtime spawns new OS threads.
- Tweaked the design to end up with a tool that was reliable and almost 30x faster than the AWS CLI.
Naive solution
The first approach we tried was the recommended way to copy objects from S3. Install the AWS CLI and do a
aws s3 cp --recursive s3://<the-bucket> /data/<the-bucket>
This took 22 minutes to copy an S3 bucket with 250,000 small images. The transfer speeds reported by the CLI was just 4.1MiB/sec. The slow transfer time was not acceptable, especially when we had developers waiting for a debugging environment to launch.
A quick online search told us we can set the max_concurrent_requests and max_queue_size to a higher value in the config to speed up the process. We updated the config to set max_concurrent_requests at 1000 and max_queue_size at 3000.
aws configure set default.s3.max_concurrent_requests 1000
aws configure set default.s3.max_queue_size 3000cat ~/.aws/config
[default]
s3 =
max_queue_size = 3000
max_concurrent_requests = 1000
Rerunning the copy did not reduce the time. We still ended up taking around 22 minutes. Most of the stackoverflow and other posts we found talked about uploading from EBS to S3. The few posts we found focused on copying large objects.
AWS CLI S3 Configuration does not document options that would be relevant to our specific use-case. (If we missed an option please let us know.)
What can we do next?
The main observation with the AWS CLI was that it does not concurrently copying objects from S3. So we planned to use GNU Parallel + aws s3 cp. Having exhausted the day, we decided to stop here and continue the next morning.
But on the train ride home, I continued to think about a possible solution. Go’s amazing support for concurrency made it a promising choice for writing a small tool to solve this specific problem. The tool was never intended to be used as a final solution. The only purpose of the prototype was to gain some experience with Go and the Go’s AWS SDK.
The first stop was the Go AWS S3 SDK api documentation. In it there were 2 API that could be used.
- s3.ListObjectsV2Pages to get the list of keys in the bucket
- s3.GetObject retrieve the object for the specific key
Next, we need a way to create directories for a given key. For this we write a DirectoryCreator that is be responsible for creating directories that have not been created before. (If the directory already exists the os.MkdirAll will not recreate it.)
DirectoryCreator creates new directories that are not present.
Next, we write a Copier that is responsible for copying and saving the object for a given key in the specified directory.
Copier copies objects from S3 and persists them on a EBS volume.
At last, we are left with designing the core. This is where we would list all the keys in the bucket and copy the object for corresponding key.
Out of the different patterns that could be used to design the core we chose 2 possible candidates.
- Server pattern
- Worker (Fan-out) pattern
You can learn more about different concurrency patters in from the following articles
The “Server pattern” based solution
In the server pattern a goroutine is spawned for the short period of time, just to accomplish some task.
This means that we should call the s3.ListObjectsV2Pages API to return a list of keys, and for each key we spawn a new goroutine to do the copying.
It worked well for bucket with a small number of images. But crashed when trying to copy the test bucket with 250,000 images. The following error was seen:
runtime: program exceeds 10000-thread limit
fatal error: thread exhaustion Followed by a huge runtime stack dump
Searching the thread limit error brought up a Google group post by Brad Fitzpatrick that had pointers to find out the root cause.
One of the reply had a grep command to show the number of goroutines that were running a system call. In our case we had 9180 goroutines that were running a system call at the time of the panic.
$ grep -C 1 '\[runnable\]' time.txt | egrep -v '^(--|goroutine |$)' | sed 's/(.*//' | sort | uniq -c 1 github.com/aws/aws-sdk-go/private/protocol/...
1 internal/poll.convertErr
69 internal/poll.runtime_pollWait
71 net/http.
1 net/textproto.canonicalMIMEHeaderKey
1 strings.ToLower
6056 syscall.Syscall
3124 syscall.Syscall6
Reading a bit more showed that when goroutines block on a system call; the runtime may create threads to schedule goroutines that are runnable. In our case, we were creating an unbounded number of goroutines where each one does a file create, write and close system calls. This ends up causing the runtime to spawn a large number of threads.
When the number of threads spawns reaches 10,000 the runtime panics and crashes the program. We can call debug.SetMaxThreads to increase the thread limit, but this just masks the underlying problem. A different solution is needed.
The key takeaways from the “server pattern” is that
- Spawning an unbounded number of goroutines is a bad idea
- A goroutine blocking on a system call can cause the runtime to spawn a new thread.
The better “Worker pattern” based solution
In the worker pattern multiple goroutines can read from a single channel, distributing an amount of work between them.
This means we would be calling the s3Client.ListObjectsV2Pages and then sending the keys to a buffered channel. Then a pool of worker goroutines would read from the buffered channel and copy the object corresponding to the received key.
We limit the number of goroutines spawned using the concurrency parameter and we limit the number of keys buffered by the channel using the queueSize parameter.
Results
We used the 250,000 small images S3 bucket as the source in the following benchmarks.
On a c5.large instance the Go “worker based” CLI took around 4mins to complete the copy; whereas the AWS CLI took ~22mins. The number of concurrent requests was set to 2000 and the queue size was set to 4000. This was promising to see a 5x reduction in the time taken.
Running the benchmark on c5.4xlarge instance saw a further drop to about 50secs using the Go CLI; whereas the AWS CLI still took ~21mins. The concurrent requests and the queue size remained at 2000 and 4000 respectively.
The results of repeating the benchmark on different instance sizes are shown below.
Table comparing the performance of AWS CLI vs Go CLI on different EC2 instance sizes.
We can see that the Go CLI gets faster as the size of the instance gets bigger. The bigger the instances the higher the dedicated EBS bandwidth. But the additional bandwidth and cores were not being used by the AWS CLI.
The Go CLI is able to make better use of the higher dedicated EBS bandwidth and higher cores count available in larger EC2 instances. This is shown by the CPU Utilization graph and the Network Input graph.
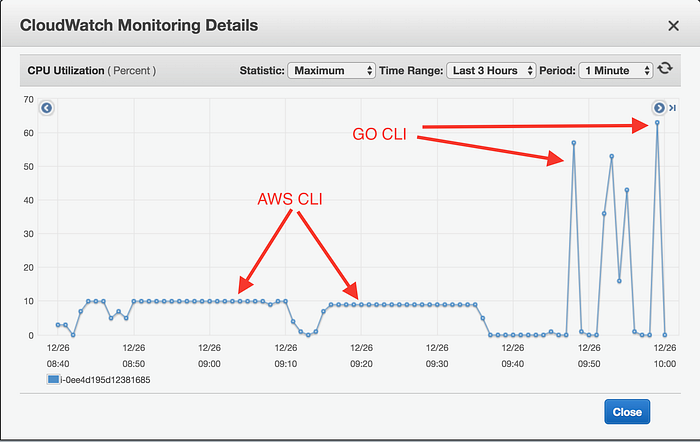
CPU utilization on c5.4xlarge instance
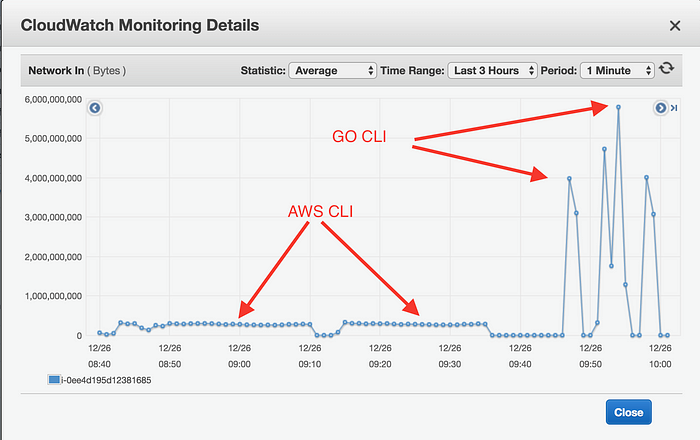
Network In on a c5.4xlarge
Though we see that the Go CLI becomes faster on bigger instances we saw that only 12 of the 16 cores being used. Running on a 8 cores instance saw all the cores being utilized. Though it would be interesting to find out why this is, we stopped here as the speedup achieved was sufficient. We could look into this issue another day.
There was no good reason for why we chose 2000 as the max concurrent requests for the benchmark. In order to determine a good value to use, we reran the benchmark on a c5.4xlarge instance with a variety of concurrency and queue size values. The best result was when the max concurrency set to 500 and queue size set to 3000.
Benchmark with various Concurrency and Queue Size settings against a S3 bucket with 250,000 images.
The best part with the worker based solution was that we never saw the 10,000 thread limit runtime error.
Conclusion
We started with a very simple problem of moving large number of very small images from a S3 bucket to an EBS volume. The AWS CLI though very versatile proved insufficient for us. We chose to write a simple Go CLI to see if we could do better.
We were able to do a lot better, we reduced the time taken for our benchmark from ~22mins using the AWS CLI to ~38secs. All of this was achieved in just 130 lines of Go code. This showcases how easy it is to write a highly concurrent solution in Go.
https://github.com/venkssa/s3copier has the full copier code along with a stats tracker that logs the progress made by the CLI.
Further Reading
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK