

线上问题跟进总结 · TesterHome
source link: https://testerhome.com/topics/11385?
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
前言
很多时候我们能把大部分的 bug 或一些部署等问题在业务上线之前就解决了,但由于某些因素,线上问题还是时而出现,影响业务生产甚至是公司效益,避免线上问题的发生以及线上问题及时处理是测试人员的一项重要职责,如何快速地处理,最大限度地降低影响范围,也就是传说中的“救火体系”,团队内部也进行了分享讨论,那今天就来聊一下这个“救火体系”的一些方案和策略
跟进前提
进行一切线上问题跟进的活动是基于测试人员本身对业务系统的熟悉程度,业务系统,也就是指业务和系统,除了业务之外,需要测试人员对业务所在的整体系统架构具备一定的熟悉程度,这里从上到下分应用层,软件层,系统层来分析
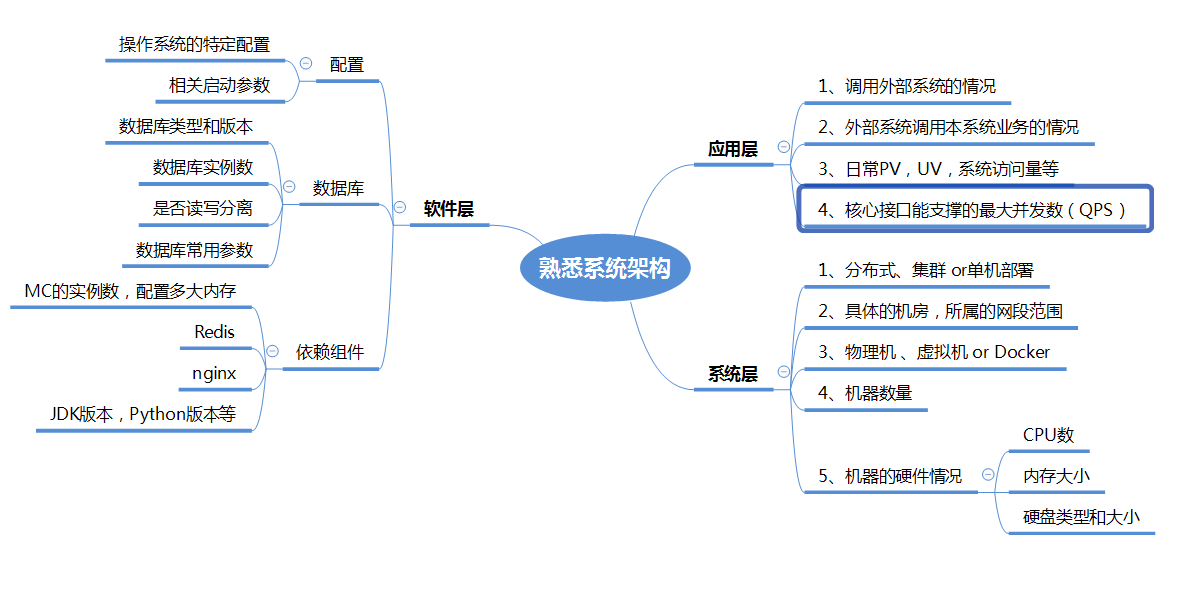
1、应用层
在应用层方面一般要关注的就是我们能直接接触到的,一般要了解自己所负责的业务系统所处整体业务系统的什么位置,除了业务系统内部之外,外部系统对自身业务系统的调用,以及业务系统对外部系统的调用也是需要了解的
同时需要清楚最基本的关键要素:量,也就是平时业务系统的访问量,如日访问量等,而且对核心接口或核心功能的最大并发量要比较熟悉,以应对突如其来的大流量以及一些网络攻击等问题
2、软件层
这里的软件层一般涉及到的是数据、配置以及相关组件,数据一般指的数据库,了解数据库的部署情况有利于在数据读写等问题上的定位,同时对于基础组件,比如 nginx,涉及到负载均衡,跨域访问等一些业务配置,同时对于缓存的合理使用情况分析了解有利于定位在持久化以及数据库使用情况的问题分析,还有相关的像 JDK 版本,JVM 的启动参数等等
3、系统层
系统层更多的和硬件相关,比如业务系统的部署方式,单机,分布式,具体机房及网段,部署的机器是物理机还是 docker 等,同时对于机器的硬件,像内存大小,CPU 数量大小,磁盘类型大小也是要了解清楚
要做好线上问题跟进,就得对自己所负责的业务系统了如指掌,只有知己知彼,才能百战百胜
跟进策略
对于跟进问题的策略,大概可以分四个环节,分布是影响范围评估,快速恢复,定位方法以及问题复盘,下面具体来说一下这 4 个环节

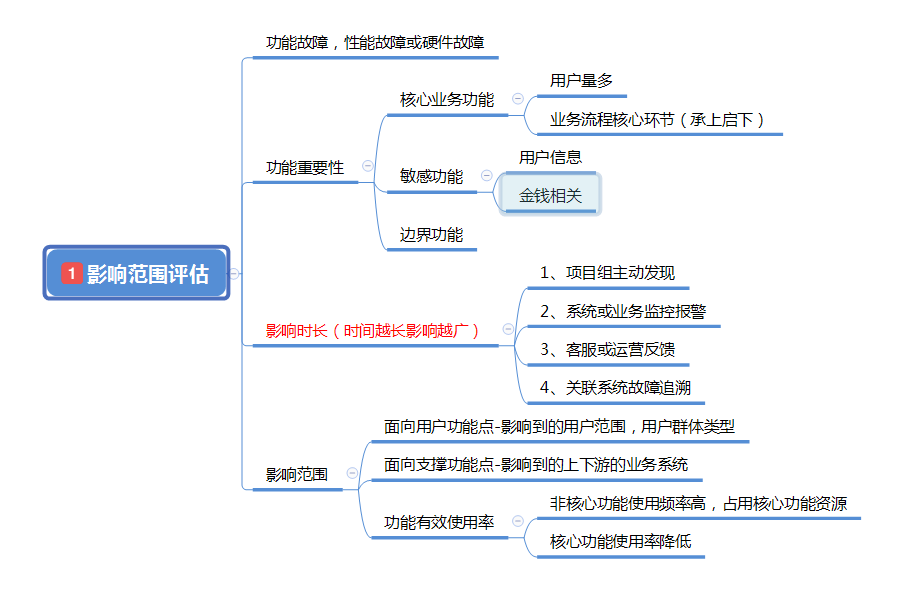
影响范围评估一般作为跟进问题的首要步骤,一般情况下根据评估的结果来设计策略和救火方案
首先要清楚发生的问题或故障属于哪种类型,是功能,性能还是硬件上的,比如突然的大流量大并发由于资源不够导致一堆的 pending,又如内存等突然坏了导致资源效率低下等
对应功能上的故障,可以梳理出功能的重要性或优先级,对应核心功能的故障,就必须短时间内能制定出救火策略来降低影响范围,同时必须保证敏感功能敏感信息的安全稳定
判断影响范围,对症下药。一般如果是面向用户的功能,尽可能地避免问题功能和用户接触,如果是作为上下游的功能可以尽快通知对应业务方做好规避并采取措施
同时对于评估还是制定救火策略,都必须要迅速,因为影响范围和程度会随着时间不断扩大,所以就得建立起良好的告警反馈体系,通过线上监控,客服反馈等措施实时了解问题情况,可以有效降低因为时长带来的影响
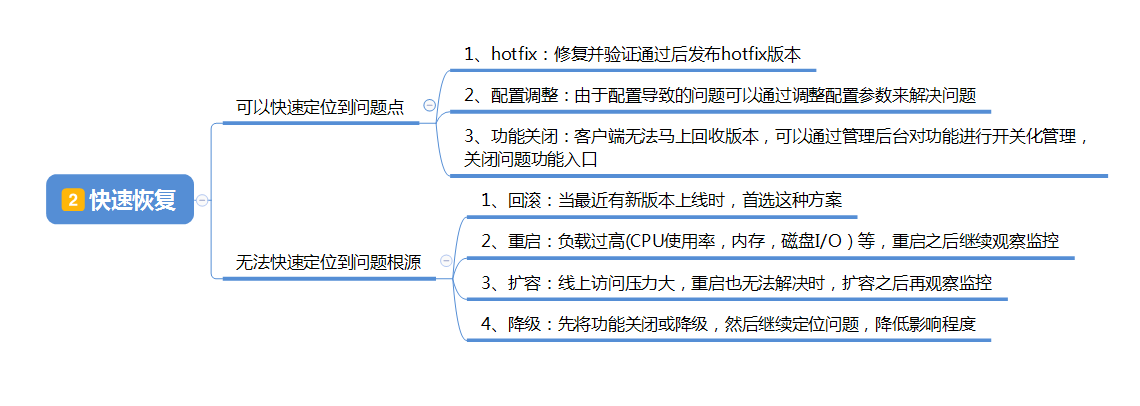
在评估完影响范围之后就得快速响应并恢复系统,一般分为可快点定位问题以及无法快速定位问题两种情况
能快速定位问题的,因为业务功能导致的问题,一般都会采取 hotfix 的方式,但对于像客户端尤其是 app 这种无法马上回收或者是发布版本的,可以通过后台配功能配置的方式将功能降级或关闭,除此之外有部分问题可以通过配置调整参数来规避的,也可以采取这方式将线上问题的影响范围减小
当不能快速地定位问题时,这时候就要当机立断,跟进线上问题的首要原则还是先将问题影响范围降到最低
可以通过回滚版本的方式来规避问题, 这也是最有效且首选的方式,回滚版本可以切断问题发生的导火线,同时最原先稳定的业务最有保证的策略
当然像由于负载过高导致的问题,不是说回滚版本就能处理的,这时候一般就是采用重启大法策略,重启之后继续观察资源的想像,一般都是因为新版本的一些问题导致资源死锁之类的,所以必要时回滚版本也会和重启大法一起使用
如果是硬件方面的问题,一般扩容就能解决的,就采取扩容的方法,加硬盘,加内存,先把资源加上去,之后再考虑优化性能的方案
对于有进行功能配置的,还是可以先将功能关闭和降级,之后在测试环境继续定位和解决在发布就好
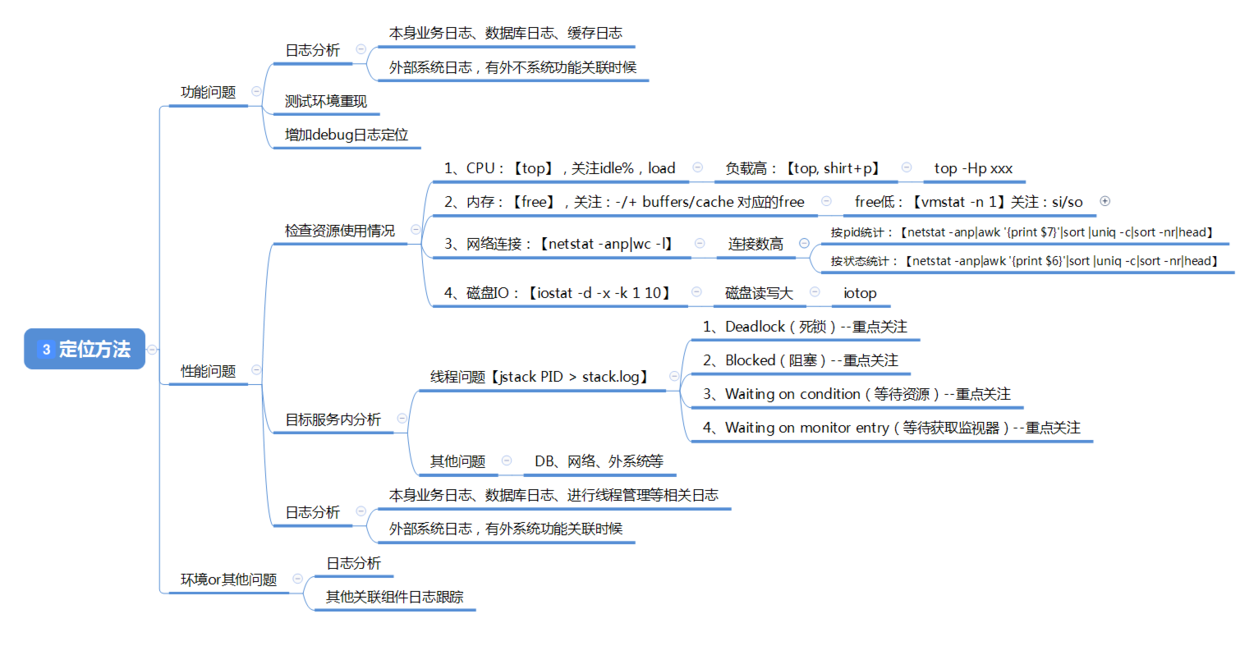
在处理问题线上的问题,降低影响范围之后,接着要做的就是定位线上问题的原因,在不管是功能问题,性能问题,还是环境问题等,日志是作为定位问题重要载体,所以一般都会要求业务的日志要精,错误要告警到位,但也不能什么都写进日志,只有精准的业务日志,才会给业务系统的稳定运行提供有效的依据,通过排查日志的信息定位问题的原因也是最有效的手段
功能上的问题都可以在测试环境重现,尽可能的模拟线上的情况,包括数据和配置,这样重现问题的概率会提高而容易定位
资源性能上的问题可以通过监控告警的日志,以及一些常规的命令来获取信息对症下药
定位到问题之后迅速制定修复和上线方案,保证业务系统在稳定的情况下继续上线运行

执行完上面的过程之后,我们还需要做的就是总结,也就是问题复盘,大家都不想问题再次发生,以及相关同类问题的出现,所以通过复盘的手段总结经验,可以提升大家规避问题的能力以及应对线上问题的能力
所以我们可以对问题的原因进行分析,是人为导致的还是系统 bug,是遗漏 bug 还是新引入的 bug,以及是否由于外部系统的数据流或者是组件等不兼容的问题导致
处理问题的流程是否合理,有些时候明明要回滚版本的就没做,有些时候不必须回滚的就回滚了,这样要考虑成本的大小和方案的合理性,毕竟有些时候版本很急,回滚的话相当于延期,对于业务来说这不是很好的结果
如何避免类似问题的发生也是问题复盘的核心环节,我们要去了解监控是否完善到位,是否由于监控告警不及时,信息不完善影响了整体救火的进度,同时在系统架构上是否可以进行性能相关优化,建立起对系统的保护措施,如过载保护,服务降级,数据解耦等
问题的复盘对于团队救火能力的提升是最有效果的,同时建立起相关文档,加强团队对业务以及系统的了解程度
总结
上述的一些方法或策略可能更多地是偏后端服务,但对于客户端的产品也是一样的方法,就拿 iOS 应用举例,除了业务之外,也得了解 iOS 操作系统的一些版本特征是否会导致应用出问题等,还是反复提起一句:知己知彼百战百胜
线上问题跟进是测试工程师的一项重要的职责,也是测试工程师的一门重要的能力,除了发现在研发测试阶段的问题,我们还需要去解决线上的问题,为业务系统保驾护航,对于测试工程师来说责无旁贷,在提升自己代码能力,测试工具使用能力,写用例能力的同时,也要提升自己应对问题处理的能力,丰满自己在各个质量保证环节的能力,这样才能成为一名优秀的测试工程师
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK