

学习大纲:两周搭建Demo理解机器学习
source link: http://www.woshipm.com/pmd/889024.html?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.

很多互联网PM都想转型到人工智能产品经理,作者也一样,还是零编程基础、零算法基础、零AI实战经验。渴望对神经网络和机器学习理解得多一点,就亲自验证了一条有效的极简路径:40-50小时,学会搭建几种简单的神经网络。理解原理的同时,还能增强信心和兴趣。
对互联网PM来说,做Demo就是本能。虽然AIPM岗的职责不涉及代码操作,但目前还没有专用的Demo工具。所以用Python实操理解ML,是个踏实高效的切入口。这套极简路径,总共有三步:浅学Python–>入门Tensorflow–>入门Keras。
浅学Python【20小时】
配置环境:如果不想安装虚拟机,没Mac电脑,推荐Windows环境下用Python_3.5.4 + PyCharm_2017 编辑器。
学习节奏:选用莫烦或小甲鱼的免费视频(约7小时),学到函数就停下,按心情决定是否把函数全学完。下载一款APP:Python利器,有空就瞅几眼。再抽空看看与机器学习相关的文章,找找感觉。
牢记初心:目的是理解ML,用Python操作Tensorflow、Keras构建神经网络。所以暂时不学爬虫、游戏等。多敲代码,不苛求闭眼睛敲出30行以上,熟悉语法就OK。
入门Tensorflow【25小时-重点】
2.1 配置环境:用pip安装Tensorflow1.4_cpu版,和numpy、matplotlib、sklearn等类库,白天安装pip下载快。
2.2 学习节奏:选用莫烦的Tensorflow入门免费教程,视频共5个小时。跟着老师敲代码,怕忘的地方用#标注,遇到不懂就上网查或问朋友。
2.3 时间分配:主要时间用来理解ANN的结构,还有调试BUG。Pycharm可以智能提示语法BUG,困扰初学者的往往是逻辑BUG,比如哪个参数传错了。这种情况查一下原版教学代码,用文件对比工具找到原因,就可以解决问题。
2.4 执行标准:理解Tensorflow的框架结构和操作思路,能读懂每行代码,顺利运行就OK。
第2个小时:能拟合出一条线性函数曲线
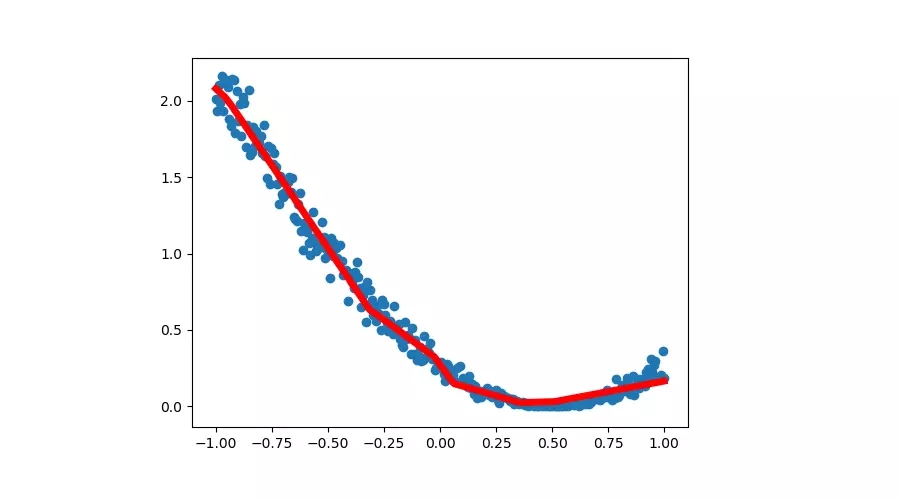
第3个小时:可以创建传说中的神经网络
第5个小时:可视化损失函数和神经网络
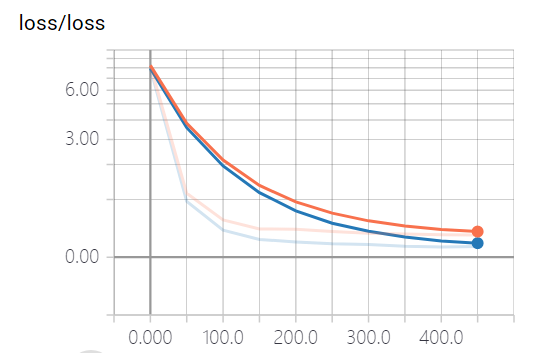
当我们输出了Graph时,一切都变得直观了。就这样一步步实现Tensorboard、过拟合、CNN、RNN、无监督等案例,整个人会越来越有信心。
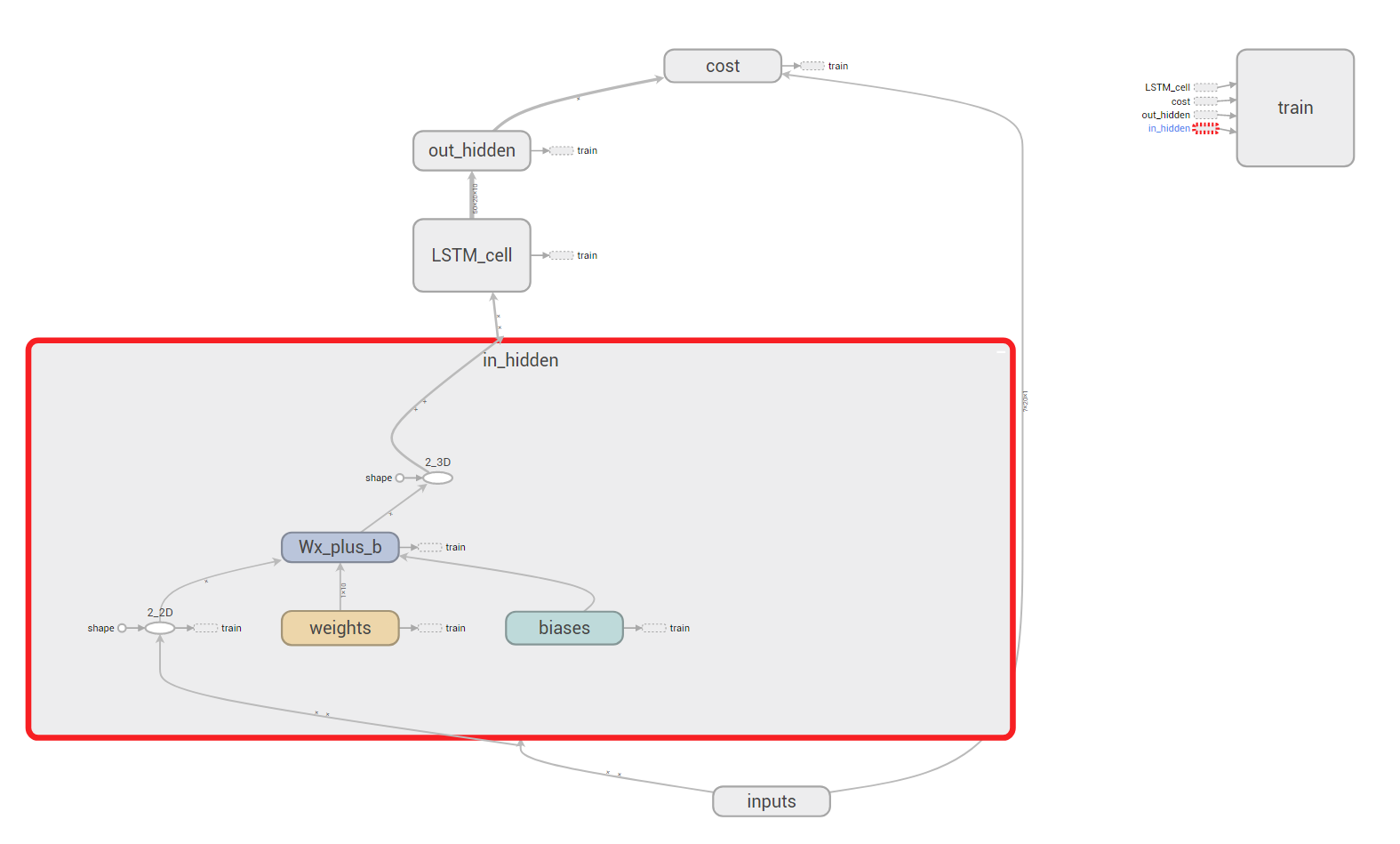
20-30小时:我们能实现上图的LSTM。
可以一边操作,一边想象过程:比如点击上图中第一个隐藏层in_hidden,展开后能清晰地看到神经元和流动的张量。输入信号的shape先从3维转到2维,优化器参与梯度优化,shape从2维升到3维,最终将输出信号给到LSTM。
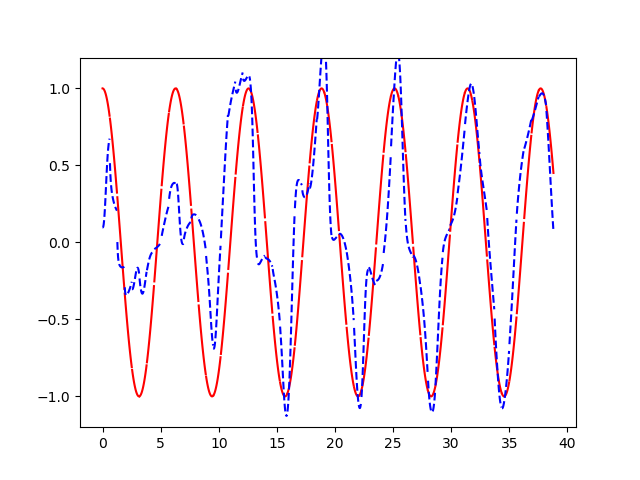
LSTM中每个cell选择性接收前一个cell的记忆和输入信号,再选择性输出给下个cell。循环往复类似的过程,模型就拥有了长久记忆能力。通过下面的结果图,可以直观地看到蓝线始终在学习红线的轨迹。经过不断的循环,蓝线最终拟合到接近红线的程度。
浅学Keras【5小时】
依然用莫烦的视频教程,比较简单就不细说了。可能有人觉得学习50小时依然很长,都够玩120盘王者荣耀了。也可以跨过Tensorflow直接上Keras,大约30小时内出模型。这里作者还是推荐学习Tensorflow,有助于更深入理解细节。
以上就是入门神经网络Demo的三步走。如果你与我一样是工作兼学习,只要每天投入4小时,坚持2-3周,就可以有这5项收获:
- 理解概念:张量、激励函数、优化器、损失函数、梯度下降、反向传播、学习率、批标准化等。
- 理解模型:CNN–>卷积、池化、全连接;RNN–>分类、回归、LSTM;非监督学习–>聚类、降维。
- 了解工程:采集标注、设计模型、构建模型、训练模型、测试调优等流程,有助于跟工程师更好地交流配合。
- 抽象能力:构建神经网络会思考数据的特征、模型的结构,不知不觉间就经历了抽象特征–>可视化的全过程。
- 类机器思维:本文的写作思路,就模仿了机器学习过程。以理解原理(result)为导向,从学习资源(data)中提取特征,对信息做过滤、降维处理。然后通过实践(training)优化认知(optimizer),再将个人推测(prediction)与真相对比印证(loss)。自从接触了AI,类机器学习的思维模式就开始赋能我生活、工作的场景。它帮助我不断进化,越来越高效。
关于学习,我最在乎的就是速度,唯快不破!现实中每条赛道终点幸存者寥寥无几,参赛者都在拼命减少犯错的可能性。全民拼命的背景下,谁犯错少谁就胜出。
AI的范畴比较大,我转型的策略是先模拟项目、模拟Demo,“一石多鸟”的学习方式,保持较广的视野。而不是一头扎进某个深坑,管中窥豹,很久都爬不上船。
不管AI的泡沫何时被戳破,我们上船的速度都非常重要。速度决定我们未来能喝到啤酒,还是随泡沫一起被吹散。我觉得要转型AIPM的、零AI基础的朋友们,可以先切入几个相对容易获取的能力维度:
- 产业、场景分析能力
- 大数据、知识图谱能力
- 理解机器学习、神经网络原理
- 理解NLP、CV、推荐系统等技术
- 理解常用算法
这也是为什么我复盘3周的学习后,先输出一篇场景分析,再输出本篇Demo。
这条路径受到前辈们的启发,很幸运地借鉴了@李杰克的经验,少走很多弯路。欢迎朋友们提问和建议,转型路上,让我们一起加油吧!
作者:于长弘,公众号:AI小宇宙(ID:AI_endless)
本文由 @于长弘 原创发布于人人都是产品经理。未经许可,禁止转载
题图来自 Unsplash ,基于 CC0 协议
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK