

VirtualView Android实现详解(一)
source link: http://pingguohe.net/2017/12/27/deep-into-virtualview-android-1.html?amp%3Butm_medium=referral
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
苹果核 - VirtualView Android实现详解(一)—— 文件格式与模板编译
Dec 27, 2017 • Longerian
在之前的文章《猫客 Tangram 页面内组件的动态化方案》里介绍了 Tangram 页面的组件动态化方案,但是有很多细节没有展开讲,鉴于内容比较多,打算建一个系列,分多篇文章介绍。本文介绍编译 XML 模板的过程。
Android
Virtualview 方案:简单来讲,就是通过自定义 XML 模板搭建 UI 视图,并通过自研的渲染引擎渲染界面的一种方案,其中支持定义 Canvas 绘制的控件,因此成为 virtualview。 编译模板:将原始 XML 格式的模板序列化成一种二进制格式的过程。
为何选用二进制格式
通过 XML 编写的业务组件,如果直接加载解析,会有几个问题:一是原始文件相对较大,因为 XML 里会有冗余信息,如空格、换行、还有重复出现的字符串等,文件体积比较大;二是解析 XML 会有一定开销,相对于二进制数据直接解析,XML 解析会比较重,例如节点遍历、属性访问等都显得有些臃肿。通过提前将 XML 模板处理成二进制格式,可以将繁重的解析工作从客户端运行时中剥离出来,而通过将一些重复的资源做合并处理并建立索引,可以减少冗余信息,减少模板文件大小,通常情况下,处理成二进制格式的模板比原始模板可减少 50% - 60% 的大小。
二进制模板的格式
尽管之前的文章已经提过二进制模板文件的格式,不过这里还是要再次提及一下:
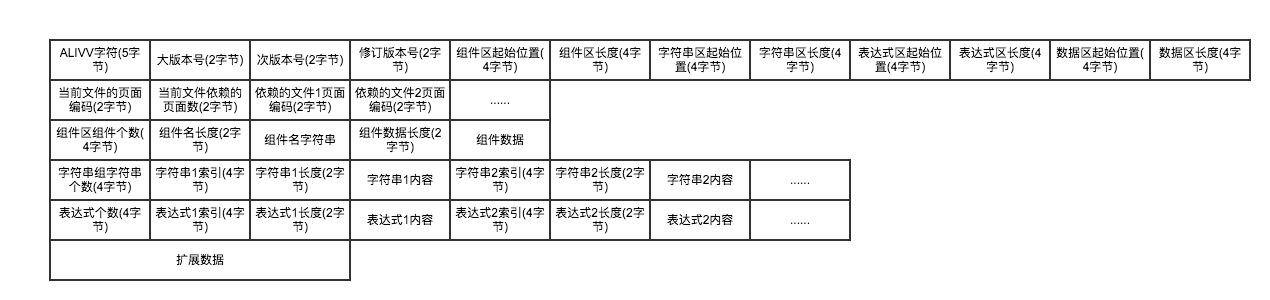
- 开始5个字节固定为 ALIVV;相当于我们的文件格式的一个标记。
- 版本号分三个,分别为主版本号,次版本号和修订版本号,均为 2 个字节;在无重大重构更新时,前两位一般不变,第三位用于组件的业务级别变更升级;
- 组件区的起始位置和长度,均为 4 个字节;表示这份文件里组件区数据从第几个字节开始,它总共有多少个字节,这样解析这份数据的时候能直接将文件指针定位到特定位置来读取数据。
- 字符串区的起始位置和长度,均为 4 个字节;表示这份文件里字符串数据从第几个字节开始,它总共有多少个字节。
- 表达式区的起始位置和长度,均为 4 个字节;表示这份文件里字符串数据从第几个字节开始,它总共有多少个字节。
- 数据区的起始位置和长度,均为 4 个字节;表示这份文件里附加数据从第几个字节开始,它总共有多少个字节。目前这一区块是作为一种保留区,实际还未使用到。
- 当前文件所属页编码,2 个字节,唯一标识一个页(保留使用)
- 当前文件依赖页的个数为 2 个字节,后面为依赖页的 Id,依赖页个数大于 0 表示该页用到了其他页的资源或者代码,在该页加载之前需要确保依赖页必须已经加载;(保留使用)
- 组件区开始,前 4 个字节表示文件里业务组件个数,目前一个 XML 模板编译成一个二进制文件,故其值固定为 1。每个业务组件前 2 个字节表示业务组件名称字符串的长度,后面为指定长度的字符串字节数据;紧接着是 2 个字节的编译后组件二进制流长度,后面为二进制代码;二进制代码的内容其实就是按照 XML 里定义的嵌套结构存储了一棵 UI 树,只不过节点开始、节点结束、每个节点tag名、属性、属性值等都被映射成一个整型索引;在解析的时候会通过索引值到对应的资源池里找到具体的资源;
- 字符串区开始,前4个字节表示字符串个数,在我们的框架里,会内置一些系统级别的字符串资源,这些字符串不用序列化到二进制文件里,而模板文件里出现的非系统字符串才会作为资源序列化到二进制文件。每个字符串资源前 4 个字节字符串索引 Id 即它的 hashCode,后面 2 个自己为字符串的长度,再后面为对应的字符串;
- 逻辑表达式代码表。前 4 个字节表示逻辑表达式资源个数,每个表达式资源前 4 个自己表示表达式的索引,它是表达式原始字符串的 hashCode,后面 2 个字节表示表达式的长度,后面为对应的表达式内容;
- 扩展数据段是保留为第三方扩展使用;(保留使用)
在一开始的时候,我们将所有模板文件编译到一个二进制文件里,类似于 Android 编译资源时做的处理,这样能更大程度地节省存储空间。但是考虑到后续要对模板进行动态下发,我们改成一个 XML 文件一份二进制文件的策略,这样当有个别模板更新的时候,只需要发布对应的模板,而不需要整体重新编译。尽管编译成一份文件也可以通过增量编译等方式来解决个别模板更新的问题,但是从管理、维护、使用等各方面考虑,还是一对一的策略更方便一些。
资源的映射处理,有以下逻辑:
- 颜色:转换成4字节整型颜色值,格式 AARRGGBB;
- 枚举:按照预定义的整数转换,比如 gravity 的类型,orientation 的类型;
- 字符串:以 hashCode 值作为它的序列化后整数,并在字符串资源区建立以 hashCode 为索引的列表,在解析的时候从中获取原始的字符串值;
- 逻辑表达式:与字符串的处理类似;
- 数字:直接转换成 4 字节的整型或者浮点型,并支持带单位的类型;
其中字符串等资源,采用了一个 hashCode 来作为索引值,主要是考虑当模板在线发布时,字符串有变动的情况下,能够不影响原来的字符串资源索引;否则如果按照带有顺序约定的协议来分配资源索引,很容易在模板变更的时候同一索引值在变更前后指向的资源内容是不一样的,这对稳定性和动态性会产生影响。
另外上面还提到保留使用的一些区段,这是前期设计时考虑加入的,虽然目前没有在用,可能将来会有使用的地方,比如页面编码可以用来归类模板的分组,页面依赖可以指定模板之间资源依赖的关系,可以用来做进一步的资源整合处理。又比如扩展数据区,可以用来存储额外的数据;
编译的具体流程

- 创建一个文件对象,编译工具开始编译模板的时候,先在创建一个输出文件的对象,指向特定路径,后续编译过程中的数据都写到这个文件里。
- 写入 ALIVV、版本号数据,按照文件格式,开头 5 字节固定未 ALIVV,可先写入,紧接着 6 个字节是 3 位版本号,主版本号固定为 1,次版本号固定未 0,修订版本号每次编译的时候开发人员通过参数传入,从 1 开始。
- 写入各区域的占位空间,根据文件格式,接下来 32 个字节分别为组件区、字符串区、表达式区、数据区的起始位置值和长度,所以先占位,初始化为 0。还有当前文件页面编码、以及它的依赖,这也是编译时用户传入,默认页面编码为 1,如果没有依赖的页面,这一部分不占空间。
- 读取一个原始模板文件,一个业务组件对应着一个模板,先读取一个原始模板数据。
- 创建 XML 解析器,因为原始模板是 XML 格式,使用XML解析器来解析其中的内容,XML 解析器会按照 XML 的格式获取到每个节点以及它的属性,所以接下来只要遍历这些节点和属性来序列化原始数据。
- 开始遍历,先获取一个节点名,先记录节点开始标记。
- 根据节点名字符串,先创建对应的基础组件编译器对象,在编译工具里,每一个基础组件都注册了对应的编译器类型。用户开发自定义基础组件,也要提供自定义编译器注册到编译工具里。基础组件和对应的编译器类通过组件类型关联起来。
- 获取该基础组件下所有属性,开始遍历属性并处理。
- 每获取到一个基础组件属性,就调用编译器处理属性,编译器知道每个属性应该如何处理,因为这是定义属性、开发编译器类的时候确定的,每一种属性都会被序列化成以下4种类型:int 整型、float 浮点型、string 字符串型、表达式类型,前两者直接作为序列化后的值写到返回结果里,后两者先通过 hashCode 为一个 4 字节索引作为序列化后的值写到返回结果里,真实的内容存储到临时列表里,后面会存储到单独的资源区。
- 遍历完当前节点所有属性。
- 按照整型、浮点型、字符串、表达式四种类别归类属性,按照 4 字节 key 索引、4 字节 value 索引存到内存里。
- 当前节点处理完毕,写入一节点结束标记。检查是否遍历晚所有节点,如果还有其他节点,回到第 6 步开始处理新的节点,如果没有,开始下一步准备写入文件
- 将第 11 步序列化后的组件数据写入到文件,将第 9 步里存储的字符串和表达式资源分别依次写入到文件。
- 这样组件区、字符串区、表达式区的起始位置都知道了,就可已更新第3步里预留的空白区域。
- 如果有扩展数据,可以在表达式区后面写入扩展数据,目前做保留。
- 全部写完之后所有数据输出到文件,文件后缀为
.out。
目前的局限性
在上述编译过程中,每个基础组件的编译都需要对应的编译模块器来执行二进制转换工作,也就是说每个类型的基础组件都有一个对应的编译器,这对于扩展新的自定义基础组件带来了一些不便,因为还要开发对应的编译器类,目前我们正在将它重构成基于属性的编译器模式,并通过配置文件的方式来解耦对自定义基础组件节点、自定义属性编译处理的逻辑,这样才能真正释放它的动态性,有助于提升开发效率与使用便捷度。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK