

【Agent组合技】最全解读MoE混合专家模型:揭秘关键技术与挑战
source link: https://www.woshipm.com/aigc/6043564.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
近期,法国AI公司Mistral-AI再次成为业界焦点,他们开源了一款专家模型。本文将从三个方面解读MoE混合专家模型,一起来看看吧。

最近,法国AI公司Mistral-AI再次成为业界焦点,他们又开源了一款专家模型——Mixtral 8x22B。这款模型能够以更低的成本生成更好的效果,能做到这一点的关键在于,模型采用的SMoE(稀疏混合专家模型)技术。
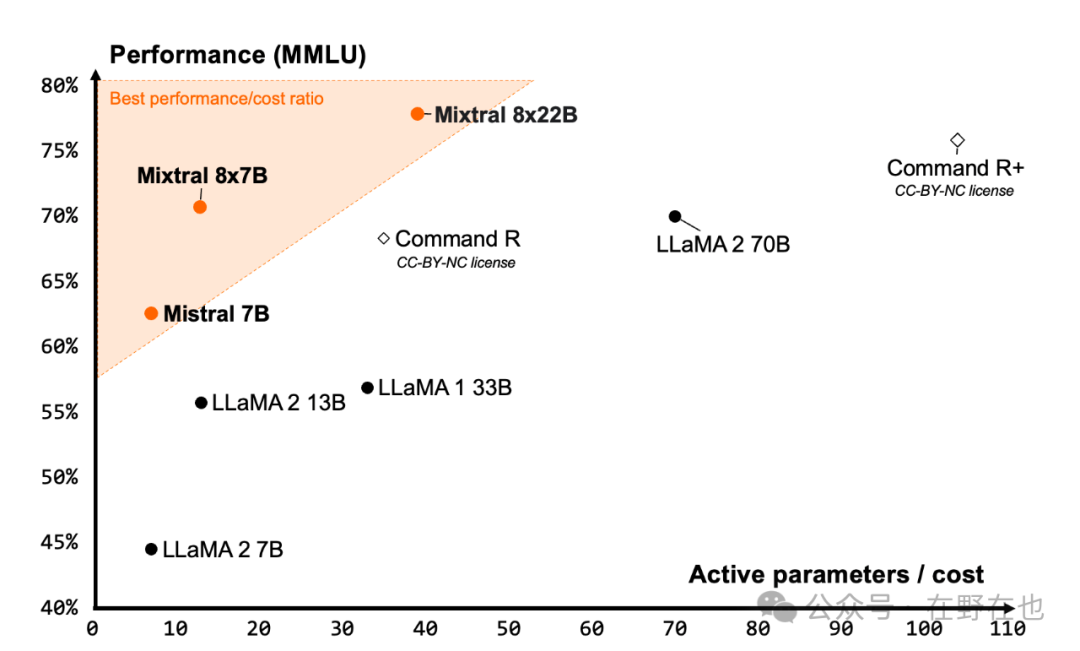
此外,去年年底,半导体分析SemiAnalysis发布了一篇GPT-4的技术报告,报告中特别提到OpenAI在GPT-4模型中集成了16个具有110亿个参数的混合专家模型,这进一步证明了MoE技术在当前AI领域的重要地位和应用前景。
本篇文章讲深入探讨:
- 什么是混合专家模型(Mixture of Experts,MoE)?
- 它的关键构成要素是什么?
- MoE技术的优势和面临的挑战有哪些?
一、什么是MoE?
1. 回顾大模型的演进历史
从处理单一文本数据的语言模型到现在能同时处理图像和音频数据的多模态大模型,我们可以把这个演变过程,想象成创业公司的发展过程。

2. 在公司初创时期,资源有限,团队成员往往要身兼数职
一个人可能同时负责产品设计、编程开发,甚至还要处理市场推广。
这种全能型的工作模式就像现在的大模型,什么都懂一点,但是往往很难在各领域都有最优的表现。
随着公司的发展和团队的扩充,引入了MoE(混合专家模型)这样的工作策略,即设立多个专业团队,每个团队都专注于自己的领域。
设计团队负责产品的外观和用户体验,开发团队专注于技术实现和功能开发,市场团队则专注于推广和销售。
此时,每当启动一个新项目时,产品经理会将项目拆分分为多个子任务,并将每个任务分配给最合适的专家团队处理。这种方式不仅加快了项目完成的速度,也显著提升了产品的质量。
MoE-混合专家模型 (Mixture of Experts),就像一个组织完善的公司,由产品经理把复杂的问题拆解为多个子问题,然后根据每个问题的特点,分配给最擅长处理这类问题的“专家团队”去解决。
二、MoE核心构成
MoE包含两个关键模块:路由器(Router)和 专家(Experts)。
1. 路由器(Router)
路由器(Router),它的作用是拆解需求和分配需求,对用户输入的内容进行需求拆解,再将拆解后的内容分配给合适的“专家”进行处理。
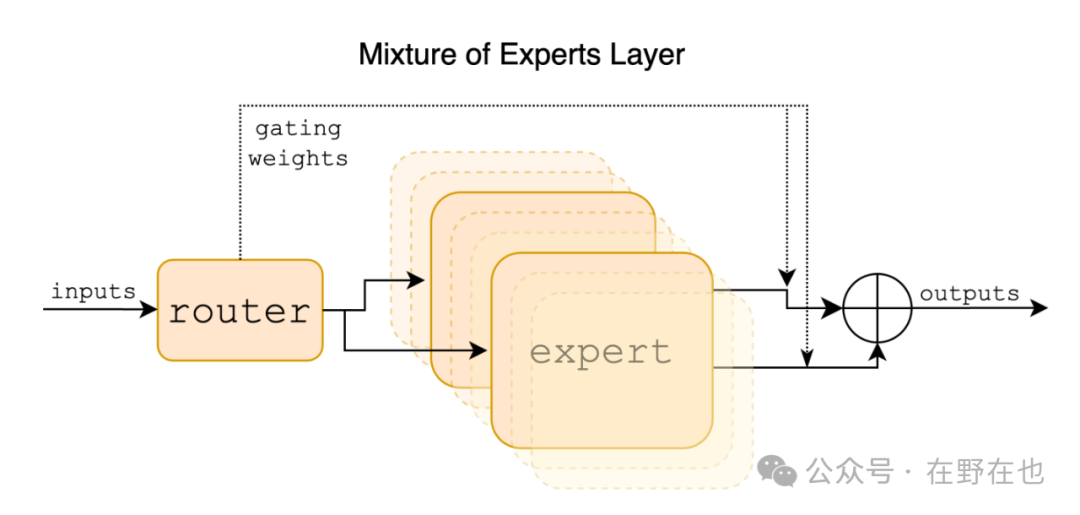
路由器(router)的处理逻辑包括以下四步
- 评估输入:路由器首先分析用户输入数据,识别主要特征,为后续的步骤奠定基础
- 专家评分:接下来,路由器利用一个预先训练好的门控网络(Gating Network)对每个专家进行评分,来预测每个专家处理特定任务的适应性
- 选择专家:根据上述评分,路由器会选择最适合解决当前数据的专家组合
- 分配任务:最后,路由器将具体的任务明确分配给选定的专家
2. 专家(Expert)
专家(experts),在混合专家模型(MoE)中,每个‘专家’可以被视为一个独立的小型神经网络,专门设计用来学习和处理特定类型的任务。

这些专家各具特色,具有不同的专业技能。
某些专家可能专门擅长图像识别,能够精准地处理视觉数据;而另一些专家更专注于语言处理,擅长解析和生成文本。
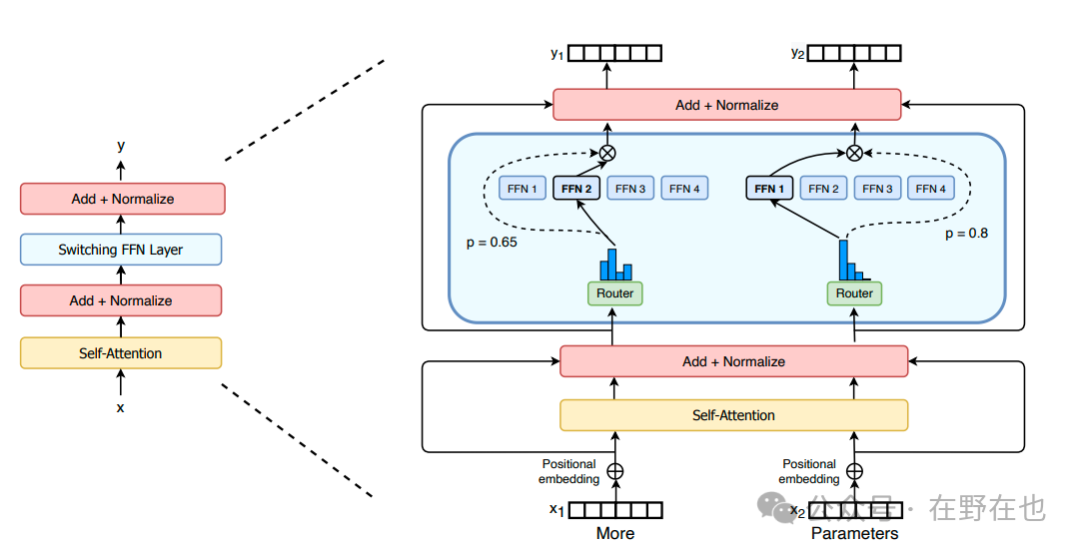
专家(expert)的处理逻辑包括以下四步:
- 接收数据:被启用的专家首先接收来自路由器的输入数据
- 数据处理:专家利用其训练的技能对接收到的数据进行分析和处理
- 输出结果:处理完成后,专家会输出对应的结果
- 整合输出:不同专家的输出结果将通过专门的网络层(例如使用加权平均的方法)进行数据整合,汇总成一个统一且准确的最终输出结果
三、MoE模型优势与挑战
1. MoE模型优势
灵活性与扩展性:根据具体的模型应用场景和需求,可以灵活增减专家的数量,使其成为一个有多个专家模型的智能团。
好比在Coze中配置一个工作流,我们可以配置不同能力的Agent进行协同工作。
如果你对Coze的工作流配置感兴趣,可以点击链接查看教程:https://www.bilibili.com/video/BV1kr42137bb/
《【AI提效,创意释放】使用Coze打造全能AI助理,免费使用GPT4、可集成多平台,全网最全的coze扣子使用教程|附加深度解析Agent技术原理与开源项目》
- 计算效率更高与推理成本更低:前文提到的Mixtral 8x22B,采用SMoE(稀疏混合专家模型)中的“稀疏”特性,正是体现在模型具备选择性分配任务的能力。这种设计允许模型仅利用一小部分的“专家”来处理特定的数据,从而提高计算效率,降低推理成本
- 专业化处理:在MoE模型中,每个专家都专注于自己擅长的领域,进行学习和持续优化。这一过程类似于高效的团队合作,其中每个成员都利用自己的专长为团队做出贡献,共同应对复杂的项目
2. MoE模型挑战
负载平衡:类似于一个班级中只有几个学生回答问题,而其他学生较少参与。在MoE模型中,如果某些“专家”频繁被选中,会导致训练不均
解决方案:为了解决这个问题,可以引入“辅助损失函数(auxiliary loss)”来鼓励均衡地选择每个专家,确保训练的公平性
内存问题:尽管MoE在推理阶段可以仅激活部分“专家”来减少减少推理的计算资源,但是在训练阶段,模型中所有“专家”参数都需要加载到内存中,对计算资源的要求更高
解决方案:可以实施专家并行策略,将专家层分布在多个计算设备上,以优化资源使用和降低单个设备的负载
MoE(混合专家模型)通过分解复杂问题并将其分配给特定的“专家模型”进行处理的策略,不仅显著提高了计算效率和模型的拓展性,也优化了资源利用率、降低了计算成本,在MoE中,每个“专家“或“智能代理(Agent)”都负责处理他们擅长的特定领域,展现出AI的分工合作和高度专业化的强大潜能。
节日快乐,下篇再见🎉
参考文献:
1、What is mixture of experts?
Link:https://www.ibm.com/topics/mixture-of-experts
2、Mixture of Experts Explained
Link:https://huggingface.co/blog/moe
3、Mixtral of Experts
Link:https://arxiv.org/pdf/2401.04088
作者:在野在也,公众号:在野在也
本文由 @在野在也 原创发布于人人都是产品经理。未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK