

详解 C++ 实现 K-means 算法
source link: https://www.51cto.com/article/786530.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
详解 C++ 实现 K-means 算法
K-means算法是一种非常经典的聚类算法,其主要目的是将数据点划分为K个集群,以使得每个数据点与其所属集群的中心点(质心)的平方距离之和最小。这种算法在数据挖掘、图像处理、模式识别等领域有着广泛的应用。
一、K-means算法概述

K-means算法是一种非常经典的聚类算法,其主要目的是将数据点划分为K个集群,以使得每个数据点与其所属集群的中心点(质心)的平方距离之和最小。这种算法在数据挖掘、图像处理、模式识别等领域有着广泛的应用。
二、K-means算法的基本原理
K-means算法的基本原理相对简单直观。算法接受两个输入参数:一是数据集,二是用户指定的集群数量K。算法的输出是K个集群,每个集群都有其中心点以及属于该集群的数据点。
K-means算法的执行过程如下:
- 初始化:随机选择K个点作为初始集群中心(质心)。
- 分配数据点到最近的集群:对于数据集中的每个点,计算其与各个质心的距离,并将其分配到距离最近的质心所对应的集群中。
- 重新计算质心:对于每个集群,计算其内所有数据点的平均值,并将该平均值设为新的质心。
- 迭代优化:重复步骤2和3,直到满足某个终止条件(如质心的变化小于某个阈值,或者达到最大迭代次数)。
图解说明:
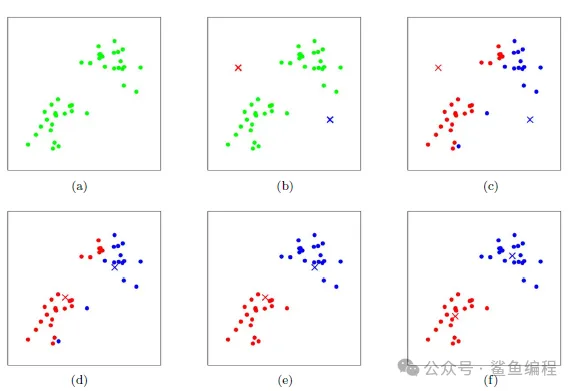
图a表示初始的数据集,在图b中随机找到两个类别质心,接着执行上述的步骤二,得到图c的两个集群,但此时明显不符合我们的要求,因此需要进行步骤三,得到新的类别质心(图d),重复的进行多次迭代(如图e和f),直到达到不错的结果。
三、K-means算法的数学表达
K-means 算法是一种迭代求解的聚类分析算法,其目标是将 个观测值划分为 ()个聚类,以使得每个观测值属于离它最近的均值(聚类中心或聚类质心)对应的聚类,以作为聚类的标准。
1.数据表示

2.聚类中心

3.目标函数

4.迭代更新

5.算法终止条件
迭代进行分配步骤和更新步骤,直到聚类中心不再发生显著变化,或者达到预设的最大迭代次数。
四、K-means算法的C++实现
首先是头文件:
#include <iostream>
#include <vector>
#include <cmath>
#include <limits>
#include <algorithm>第一步: 数据结构定义
我们定义了一个Point结构体来表示二维空间中的点。
struct Point {
double x, y;
Point(double x = 0, double y = 0) : x(x), y(y) {}
};这个结构体很简单,只有两个成员变量x和y,分别表示点在二维空间中的横坐标和纵坐标。还有一个构造函数,用于创建点对象时初始化坐标。
第二步: 辅助函数
距离计算函数
double distance(const Point& a, const Point& b) {
return std::hypot(a.x - b.x, a.y - b.y);
}这个函数计算两个点之间的距离,使用了<cmath>库中的std::hypot函数,它接受两个参数(横坐标和纵坐标的差值),并返回这两点之间的欧几里得距离。
质心计算函数
Point centroid(const std::vector<Point>& cluster) {
double sum_x = 0, sum_y = 0;
for (const auto& point : cluster) {
sum_x += point.x;
sum_y += point.y;
}
return Point(sum_x / cluster.size(), sum_y / cluster.size());
}这个函数计算一个点集的质心。质心是所有点的坐标平均值。函数遍历点集,累加所有点的x坐标和y坐标,然后分别除以点的数量,得到质心的坐标。
第三步: K-means算法主体
K-means算法的主体部分可以进一步拆分为几个小的步骤:初始化、分配点、重新计算质心和检查收敛性。
在K-means算法中,我们需要首先选择K个初始质心。在这个简单的实现中,我们随机选择数据集中的K个点作为初始质心。
std::vector<Point> centroids(k);
for (int i = 0; i < k; ++i) {
centroids[i] = data[rand() % data.size()];
}对于数据集中的每个点,我们需要找到最近的质心,并将其分配给该质心对应的集群。
std::vector<std::vector<Point>> clusters(k);
for (const auto& point : data) {
double min_distance = std::numeric_limits<double>::max();
int cluster_index = 0;
for (int i = 0; i < k; ++i) {
double dist = distance(point, centroids[i]);
if (dist < min_distance) {
min_distance = dist;
cluster_index = i;
}
}
clusters[cluster_index].push_back(point);
}重新计算质心
分配完点后,我们需要重新计算每个集群的质心。
std::vector<Point> new_centroids(k);
for (int i = 0; i < k; ++i) {
new_centroids[i] = centroid(clusters[i]);
}检查收敛性
如果新旧质心之间的变化很小(在一个很小的阈值以内),则算法收敛,可以停止迭代。
bool converged = true;
for (int i = 0; i < k; ++i) {
if (distance(centroids[i], new_centroids[i]) > 1e-6) {
converged = false;
break;
}
}如果算法未收敛,则更新质心并继续迭代。
第四步: 主函数和数据准备
在主函数中,我们准备了一个简单的数据集(整体代码见最后),并设置了K值和最大迭代次数。然后调用kmeans函数进行聚类。
这就是K-means算法的一个基本实现。在实际应用中,可能还需要考虑更多的优化和异常情况处理,比如处理空集群、改进初始质心的选择方法、添加对异常值的鲁棒性等。
结果输出:
Cluster 1 centroid: (3.5, 3.9)
(1, 0.6) (8, 5) (1, 4) (4, 6)
Cluster 2 centroid: (5.41667, 9.06667)
(2, 10) (2.5, 8.4) (5, 8) (8, 8) (9, 11) (6, 9)五、K-means算法的优缺点
- 算法简单直观,易于理解和实现。
- 对于大数据集,K-means算法是相对高效的,因为它的复杂度是线性的,即O(n)。
- 当集群之间的区别明显且数据分布紧凑时,K-means算法表现良好。
- 需要预先指定集群数量K,这在实际应用中可能是一个挑战。
- 对初始质心的选择敏感,不同的初始质心可能导致完全不同的结果。
- 只能发现球形的集群,对于非球形或复杂形状的集群效果不佳。
- 对噪声和异常值敏感,因为它们会影响质心的计算。
六、源代码如下
#include <iostream>
#include <vector>
#include <cmath>
#include <limits>
#include <algorithm>
struct Point {
double x, y;
Point(double x = 0, double y = 0) : x(x), y(y) {}
};
double distance(const Point& a, const Point& b) {
return std::hypot(a.x - b.x, a.y - b.y);
}
Point centroid(const std::vector<Point>& cluster) {
double sum_x = 0, sum_y = 0;
for (const auto& point : cluster) {
sum_x += point.x;
sum_y += point.y;
}
return Point(sum_x / cluster.size(), sum_y / cluster.size());
}
void kmeans(std::vector<Point>& data, int k, int max_iterations) {
std::vector<Point> centroids(k);
std::vector<std::vector<Point>> clusters(k);
// 随机化第一个质点
for (int i = 0; i < k; ++i) {
centroids[i] = data[rand() % data.size()];
}
for (int iter = 0; iter < max_iterations; ++iter) {
for (const auto& point : data) {
double min_distance = std::numeric_limits<double>::max();
int cluster_index = 0;
for (int i = 0; i < k; ++i) {
double dist = distance(point, centroids[i]);
if (dist < min_distance) {
min_distance = dist;
cluster_index = i;
}
}
clusters[cluster_index].push_back(point);
}
// 清除前一个的质点
for (auto& cluster : clusters) {
cluster.clear();
}
// 重新计算质点
for (int i = 0; i < data.size(); ++i) {
int cluster_index = 0;
double min_distance = std::numeric_limits<double>::max();
for (int j = 0; j < k; ++j) {
double dist = distance(data[i], centroids[j]);
if (dist < min_distance) {
min_distance = dist;
cluster_index = j;
}
}
clusters[cluster_index].push_back(data[i]);
}
std::vector<Point> new_centroids(k);
for (int i = 0; i < k; ++i) {
new_centroids[i] = centroid(clusters[i]);
}
bool converged = true;
for (int i = 0; i < k; ++i) {
if (distance(centroids[i], new_centroids[i]) > 1e-6) {
converged = false;
break;
}
}
if (converged) {
break;
}
centroids = new_centroids;
}
// 输出结果
for (int i = 0; i < k; ++i) {
std::cout << "Cluster " << i + 1 << " centroid: (" << centroids[i].x << ", " << centroids[i].y << ")" << std::endl;
for (const auto& point : clusters[i]) {
std::cout << "(" << point.x << ", " << point.y << ") ";
}
std::cout << std::endl;
}
}
int main() {
srand(time(nullptr)); // 随机数种子,可以使用随机数生成数据集
std::vector<Point> data = {
// 数据集
{2.0, 10.0}, {2.5, 8.4}, {5.0, 8.0}, {8.0, 8.0}, {1.0, 0.6},
{9.0, 11.0}, {8.0, 5.0}, {1.0, 4.0}, {4.0, 6.0}, {6.0, 9.0}
};
int k = 2; // 集群数量
int max_iterations = 5; // 迭代次数
kmeans(data, k, max_iterations);
return 0;
}Recommend
-
135
专栏 | 从架构到算法,详解美团外卖订单分配内部机制 美团点评技术团队...
-
84
前言总括: 本文详细讲述了RSA算法详解,包括内部使用数学原理以及产生的过程。 原文博客地址:RSA算法详解 知乎专栏&&简书专题:前端进击者(知乎)&&前端进击者(简书) 博主博客地址:Damonare的个人博客 相濡以沫。到底需...
-
59
高精度加、减、乘、除算法实现详解
-
5
K-Means是一个超级简单的聚类方法,说他简单,主要原因是使用它时只需设置一个K值(设置需要将数据聚成几类)。但问题是,有时候我们拿到的数据根本不知道要分为几类,对于二维的数据,我们还能通过...
-
6
KMP算法的实现 要求解KMP算法,首先要得到next数组,也有的地方叫prefix数组。先用手算的方法求得。 假设模式串为abacab; 第一步列出模式串的所有前缀(包括自身): (1)a (2)ab (3)aba
-
4
本文章将从数学及代码角度阐述K-Means聚类方法的原理及应用。 聚类分析允许我们找到相似样本或者feature的组,这些对象之间的相关性更强。 常见的用途有包括按照不同的基因表达情况对样本进行分组,或者根据不同样本的分类对基因进行分组等。 本文将会介...
-
1
聚类算法是无监督学习最常见的一种,K-Means 算法是一种聚类算法。 假设给定数据:x(1),x(2),⋯,x(m),x(i)∈Rnx(1),x(2),⋯,x(m),x(i)∈Rn,注意数据是没有标签的。 K-Means 算法的一般流程 选择初始的 K 个聚类中心 μ1,μ2,…,μk∈Rnμ1,μ...
-
0
机器学习(十)——K-Means算法 2016-09-05 贝叶斯统计和规则化ML(续) 因为预测样本集和训练样本集的分布是独立的,因此上式又可写为:...
-
3
聚类是一种非监督式的机器学习方法。对于监督式的分类问题,其 learning dataset 中的每一个样本点都有对应的标签,其目标为学习一个模型使得其对未知数据的预测表现最好。而对于非监督式的聚类问题,其数据集中并没有提供标签,而且它不像分类问题那样有明显的 训练...
-
2
Fuzzy C-Means简介 模糊控制是自动化控制领域的一项经典方法。其原理则是模糊数学、模糊逻辑。1965,L. A. Zadeh发表模糊集合“Fuzzy Sets”的论文, 首次引入隶属度函数的概念,打破了经典数学“非0即 1”的局限性,用[0,1]之间的实数来描述中间状态。
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK