
0

# yyds干货盘点 # 这个网络爬虫代码,拿到数据之后如何存到csv文件中去?
source link: https://blog.51cto.com/u_13389043/10514813
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
# yyds干货盘点 # 这个网络爬虫代码,拿到数据之后如何存到csv文件中去?
精选 原创大家好,我是皮皮。
还是昨天的那个网络爬虫问题,大佬们,帮忙看看这个网络爬虫代码怎么修改?那个粉丝说自己不熟悉pandas,用pandas做的爬虫,虽然简洁,但是自己不习惯,想要在他自己的代码基础上进行修改,获取数据的代码已经写好了,就差存储到csv中去了。
他的原始代码如下:
import requests
from lxml import etree
import csv
import time
import pandas as pd
def gdpData(page):
url = f'https://www.hongheiku.com/category/gdjsgdp/page/{page}'
headers ={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
resp = requests.get(url,headers = headers)
# print(resp.text)
data(resp.text)
file = open('data.csv',mode='a',encoding='utf-8',newline='')
csv_write=csv.DictWriter(file,fieldnames=['排名','地区','GDP','年份'])
csv_write.writeheader()
def data(text):
e = etree.HTML(text)
lst = e.xpath('//*[@id="tablepress-48"]/tbody/tr[@class="even"]')
for l in lst:
no = l.xpath('./td[1]/center/span/text()')
name = l.xpath('./td[2]/a/center/text()')
team = l.xpath('./td[3]/center/text()')
year = l.xpath('./td[4]/center/text()')
data_dict = {
'排名':no,
'地区':name,
'GDP':team,
'年份':year
}
print(f'排名:{no} 地区:{name} GDP:{team} 年份:{year} ')
csv_write.writerow(data_dict)
file.close()
url = 'https://www.hongheiku.com/category/gdjsgdp'
headers ={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
resp = requests.get(url,headers = headers)
# print(resp.text)
data(resp.text)
e = etree.HTML(resp.text)
#//*[@id="tablepress-48"]/tbody/tr[192]/td[3]/center
count = e.xpath('//div[@class="pagination pagination-multi"][last()]/ul/li[last()]/span/text()')[0].split(' ')[1]
for index in range(int(count) - 1):
gdpData(index + 2)二、实现过程
这里粉丝给了一瓶冰红茶的费用,一个热心市民给了一份代码,在他的代码基础上进行修改的,代码如下:
import requests
from lxml import etree
import csv
import time
import pandas as pd
def gdpData(page):
url = f'https://www.hongheiku.com/category/gdjsgdp/page/{page}'
headers ={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
resp = requests.get(url,headers = headers)
# print(resp.text)
data(resp.text)
def data(text):
file = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_write = csv.DictWriter(file, fieldnames=['排名', '地区', 'GDP', '年份'])
csv_write.writeheader()
e = etree.HTML(text)
lst = e.xpath('//*[@id="tablepress-48"]/tbody/tr[@class="even"]')
for l in lst:
no = ''.join(l.xpath('./td[1]/center/span/text()'))
name = ''.join(l.xpath('./td[2]/a/center/text()')[0])
team = ''.join(l.xpath('./td[3]/center/text()'))
year = ''.join(l.xpath('./td[4]/center/text()'))
data_dict = {
'排名':no,
'地区':name,
'GDP':team,
'年份':year
}
print(f'排名:{no} 地区:{name} GDP:{team} 年份:{year} ')
csv_write.writerow(data_dict)
file.close()
url = 'https://www.hongheiku.com/category/gdjsgdp'
headers ={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
resp = requests.get(url,headers = headers)
# print(resp.text)
data(resp.text)
e = etree.HTML(resp.text)
#//*[@id="tablepress-48"]/tbody/tr[192]/td[3]/center
count = e.xpath('//div[@class="pagination pagination-multi"][last()]/ul/li[last()]/span/text()')[0].split(' ')[1]
for index in range(int(count) - 1):
gdpData(index + 2)代码运行之后,数据就存储到csv中去了。
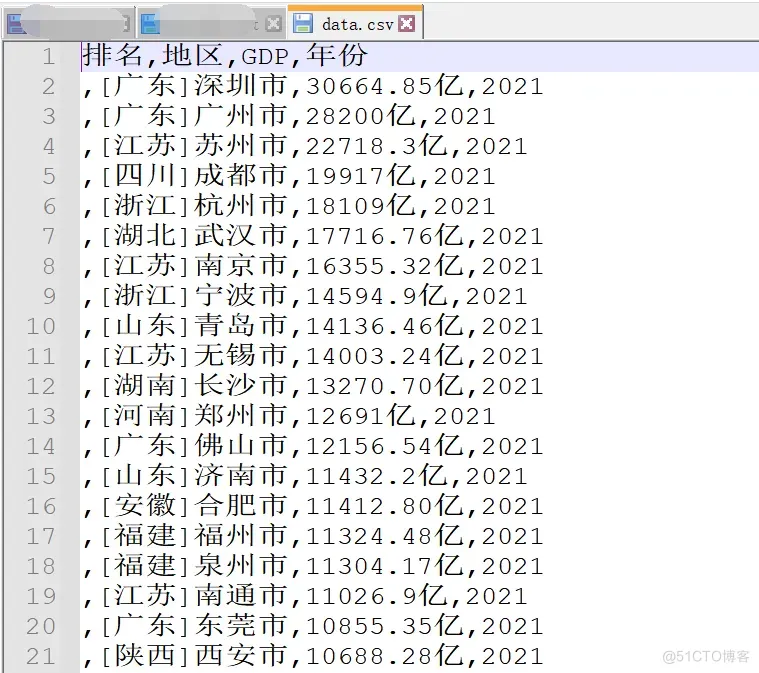
顺利地解决了粉丝的问题!
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫后数据存储的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【蓝桉】提问,感谢【热心市民】给出的思路和代码解析,感谢【eric】等人参与学习交流。
- 赞
- 收藏
- 评论
- 分享
- 举报
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK