

【译文】在 TechEmpower Web 框架基准测试中,Rust 的速度为何如此之快?
source link: https://www.techug.com/post/how-can-rust-be-so-fast-in-the-techempower-web-framework-benchmarks/
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
【译文】在 TechEmpower Web 框架基准测试中,Rust 的速度为何如此之快?
当您查看 TechEmpower Web 框架基准测试时,很难不注意到 Rust 与其他语言相比有多快。
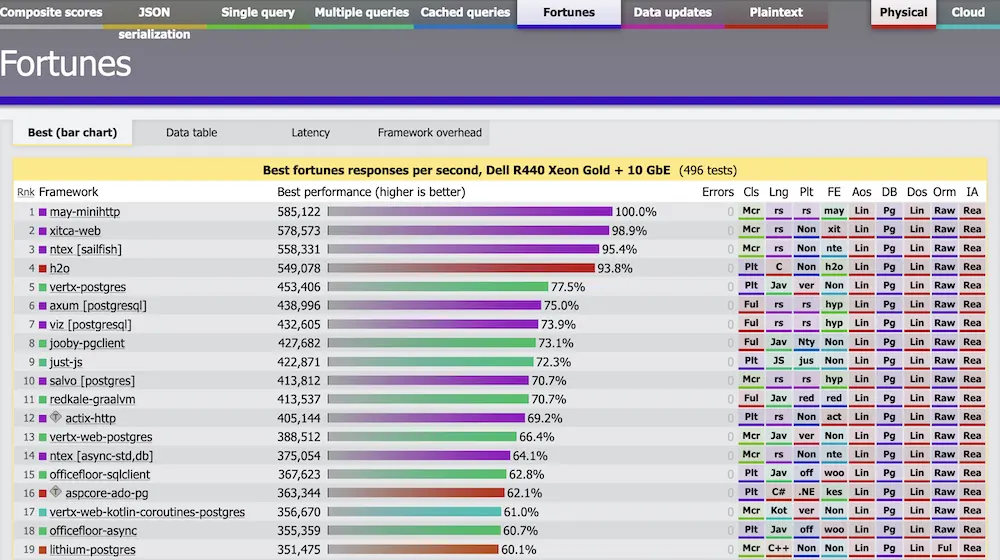
May-minihttp 的请求次数为 585 000 次/秒,axum [postgresql] 的请求次数为 400 000 次/秒!这很容易让人联想到 “ZOMGG!! Stop everything!! 我们需要用 Rust 重写 webApp!!”。
等一下,年轻的学徒,请永远记住有三种谎言:谎言、该死的谎言和基准测试。
当然,由于编译器速度非常慢,而且进行了大量优化,我们可以预期 Rust 的速度会很快,但它真的有那么快吗?让我们深入代码。
在这篇文章中,我们将介绍 Fortunes 基准测试,因为它最接近真实世界中网络应用程序的运行情况。基准代码从数据库中获取一些数据,执行一些操作,然后将数据呈现在模板中。
代码研究:提交 93b24acdfba67b7989909eb6313674c5288fd945
您可能注意到的第一件事是,axum [postgresql] 作为 hyper 的包装器,速度比 hyper 更快(439,000 次请求/秒对 322,000 次请求/秒)。这怎么可能呢?
虽然这两种实现的大部分代码相似,但它们使用了不同的模板库。
axum [postgresql] 使用的是 yarte crate。
<!DOCTYPE html><html><head><title>Fortunes</title></head><body><table><tr><th>id</th><th>message</th></tr>
{{~# each fortunes ~}}
<tr><td>{{id}}</td><td>{{message}}</td></tr>
{{~/each ~}}
</table></body></html>
markup::define! {
FortunesTemplate(fortunes: Vec<db::Fortune>) {
{markup::doctype()}
html {
head {
title { "Fortunes" }
}
body {
table {
tr { th { "id" } th { "message" } }
@for item in {fortunes} {
tr {
td { {item.id} }
td { {markup::raw(v_htmlescape::escape(&item.message))} }
}
}
}
}
}
}
}
Prepared statements
axum [postgresql] 在连接时使用了 prepared 语句。
let fortune = cl.prepare("SELECT * FROM fortune").await.unwrap();
// ...
let fut = self.client.query_raw::<_, _, &[i32; 0]>(&self.fortune, &[]);
hyper 实现也使用了prepared 语句。
let rows = self.client.query(&self.fortune, &[]).await?;
但是,axum [postgresql - deadpool] 不使用prepared 语句,而是为每个请求准备查询,这基本上会导致无用的数据库往返,这也是其性能不佳的部分原因。
let select = prepare_fetch_all_fortunes_statement(&client).await;
let mut fortunes = fetch_all_fortunes(client, &select)
.await
.expect("could not fetch fortunes");
无共享架构
xum [postgresql] 和 [hyper] 都使用了无共享架构:它们在每个线程中使用整个 tokio 运行时,而不是在线程(#[tokio::main])之间分配任务的传统抢工运行时架构。
for _ in 1..num_cpus::get() {
std::thread::spawn(move || {
let rt = tokio::runtime::Builder::new_current_thread()
.enable_all()
.build()
.unwrap();
rt.block_on(serve());
});
}
pub(crate) fn run<F>(per_connection: F)
where
F: Fn(TcpStream, &mut Http, Handle) + Clone + Send + 'static,
{
// Spawn a thread for each available core, minus one, since we'll
// reuse the main thread as a server thread as well.
for _ in 1..num_cpus::get() {
let per_connection = per_connection.clone();
thread::spawn(move || {
server_thread(per_connection);
});
}
server_thread(per_connection);
}
fn server_thread<F>(per_connection: F)
where
F: Fn(TcpStream, &mut Http, Handle) + Send + 'static,
{
let mut http = Http::new();
http.http1_only(true);
// Our event loop...
let core = RuntimeBuilder::new_current_thread()
.enable_all()
.build()
.expect("runtime");
let handle = core.handle();
当内核数量较多时,线程之间共享的可变数据(如原子计数器/互斥)会因 CPU 缓存失效而对性能产生巨大影响。
虽然这种优化大大提高了性能,但服务器应用程序通常需要在请求/任务之间共享一些状态。
数据库连接
axum [postgresql] 和 hyper 每个线程都使用一个数据库连接。
let pg_connection = PgConnection::connect(database_url).await;
let db_conn = db::connect(psql_addr, config, handle).await?;
从延迟数字和配置文件来看,数据库似乎与网络应用程序运行在同一台服务器上,这是每线程 1 个连接配置的理想情况,但如果数据库在另一台机器上,延迟超过 1 毫秒,性能就会非常差,就像在任何实际设置中一样。
此外,他们不使用 TLS 连接数据库,这也提高了性能,但在生产中绝对不能这样做。
let (cl, conn) = connect(&db_url, NoTls)
在现实世界中,您希望使用连接池来连接数据库,这可能会导致高并发时的竞争。
自定义分配器
may-minihttp 使用自定义 mimalloc 内存分配器,而不是默认的 glibc 分配器。
#[global_allocator] static GLOBAL: mimalloc::MiMalloc = mimalloc::MiMalloc;
建议所有生产型 Rust 服务器使用 jemalloc 等自定义分配器,因为默认的 libc 分配器在达到极限时会导致过多的内存碎片。
读完代码后,我的第一个想法是”真是一团糟!”
我本以为至少所有框架都使用相同的数据库,但事实并非如此。有些框架使用 MySQL,有些使用 PostgreSQL。有些框架的实现经过了超级优化,有些框架的实现则与普通网络应用程序无异。有些框架使用适当的模板库,有些则使用 Sprintf。
TechEmpower 基准实际上是一个苹果和一辆汽车之间的比较,所以请不要用它来作为选择技术的动机,否则以后会让你吃不了兜着走!
现在我们能说他们在作弊吗?
当然不是!但是,你绝对不能指望典型的 Rust WebApp 会有如此出色的表现。我想说的是,这只是一个不良激励机制的问题。他们被要求把图表做得更高,所以他们也就答应了。
事实上,当我们看看 axum [postgresql - sqlx](这是所有 Rust 实现中最成语化的代码)的表现时,它是最慢的框架之一,比大多数 Go、PHP、Java 甚至 JavaScript 实现都要慢。
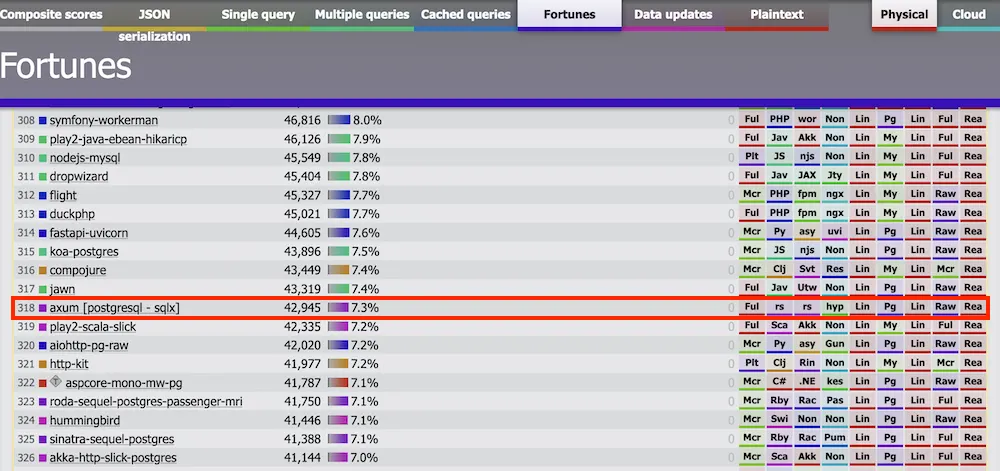
我不清楚原因,但我认为这与准备(prepared )语句和/或数据库连接池的管理方式有关。
最后,这次深入研究让我对 may 产生了好奇,它基本上为 Rust 提供了绿色线程(就像 Go 和它的 goroutines),因此我们不需要使用异步 Rust 来编写 I/O 繁重的程序,may 的运行时会为我们完成必要的工作。
我想更多地了解 may,并不是因为它在 TechEmpower 基准测试中表现出色,而是因为我非常不喜欢异步 Rust。
本文文字及图片出自 How can Rust be so fast in the TechEmpower Web Framework Benchmarks?
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK