

使用零一万物 200K 模型和 Dify 快速搭建模型应用
source link: https://soulteary.com/2024/03/13/use-yi-34b-chat-200k-model-and-dify-to-quickly-build-model-application.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
使用零一万物 200K 模型和 Dify 快速搭建模型应用
本篇文章,我们聊聊如何使用 LLM IDE (Dify) 快速搭建一个模型应用,以及使用超长上下文的 200K 模型,完成懒人式的电子书翻译。
最近在 GitHub 上看到了前 HuggingFace 员工,前 transformers 核心贡献者之一的 Stas Bekman 以开源的方式写了一本机器学习的书,基于之前训练 BLOOM 176B 和 IDEFICS 80B 的经验,相对详细的聊了训练大语言模型和多模态模型。
这本书的干货还是蛮多的,我个人认为或许能够对和我一样的模型爱好者有帮助,所以我动了翻译它,分享给同好的心思。
翻译完毕的内容,开源在了 soulteary/ml-engineering,欢迎一键三连,同样欢迎一起协作,让内容更精致,提升大家的阅读体验。
作为一个懒人,自然是选择目前最高效的方案来整啦。我主要借助了两个外部工具来做这个事情:
第一个,是前两周申请到的零一万物的模型(yi-34b-chat-200k),能够将作者每一章的全文都扔到模型里,而不用切分章节或做一些递归式的章节摘要等麻烦事。
第二个,是开源生态做的非常好的 LLM 应用开发平台(LLM IDE),Dify。使用它可以快速把 Prompt 调试好,然后启动一个能够按照预期调用接口,拿到数据的应用。
前者的 API 申请,需要去官方社区填写申请表,后者是完全开源的工具,可以从 GitHub langgenius/dify 获取应用代码和快速启动配置。
另外,我特别建议你准备一杯饮料或者一本书,在模型开始翻译内容后,我们可以喝着饮料看看书,放松放松。
准备工作:获取要翻译的电子书
获取电子书比较简单,我们只需要使用 git 下载它就行,为了方便修改文件,我对原始仓库进行了 fork:
git clone https://github.com/soulteary/ml-engineering.git
包含电子书“源码”的内容下载完毕,我们先放在一边,稍后使用。
准备工作:启动 Dify IDE
我们有两种方案使用 Dify,可以选择使用 Dify 的 Cloud 在线版本,也可以本地使用 Docker 快速地搭建应用。
前者没什么好聊的,使用 GitHub 或者 Google 账号授权登录,默认“入门套餐”免费送 10 个应用的额度。后者的话,我们需要下载程序:
# git clone https://github.com/langgenius/dify.git
Cloning into 'dify'...
remote: Enumerating objects: 44636, done.
remote: Counting objects: 100% (7874/7874), done.
remote: Compressing objects: 100% (1528/1528), done.
remote: Total 44636 (delta 6730), reused 7116 (delta 6326), pack-reused 36762
Receiving objects: 100% (44636/44636), 24.19 MiB | 10.31 MiB/s, done.
Resolving deltas: 100% (31710/31710), done.
然后,使用 docker 启动应用:
cd dify/docker
docker compose up -d
默认的配置中包含了下面几种应用服务:
dify,应用的前后端服务。postgres作为数据库使用。redis作为缓存服务使用。weaviate作为向量数据库使用。nginx作为应用网关使用,默认端口是 80,我们可以根据自己的需求修改调整。
应用启动完毕,设置完默认的管理员邮箱和密码,我们就能够看到 Dify 的 Dashboard 啦。

准备工作:配置零一万物模型
当在社区里申请了零一万物的模型 API 后,邮箱中会 “New” 出一份包含 “API Key” 和对应使用文档的邮件。
点击 Dify 控制台右上角的个人头像,在下拉菜单中选择“设置”,能够看到 Dify 支持的模型列表。
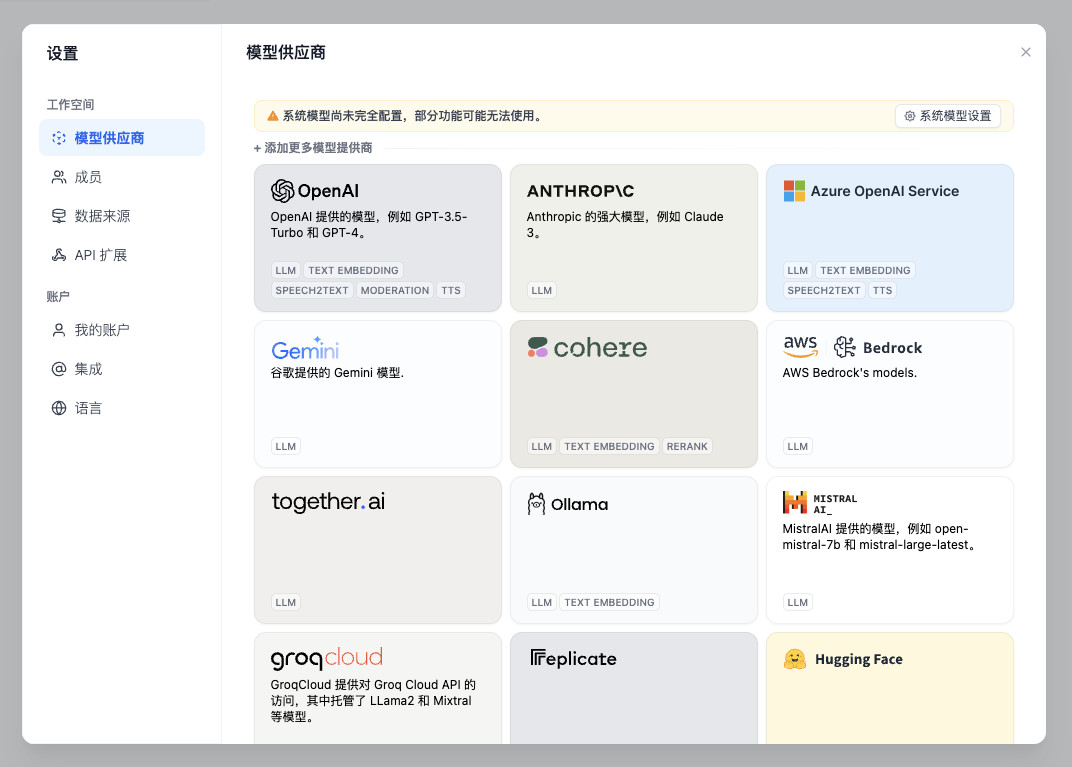
然后在打开的“模型供应商”窗口中往下滑到底。直到看到 “OpenAI 兼容 API” 的项目,点击它,选择添加一个模型后端服务。

然后,使用邮件和模型文档中的内容完成模型的配置即可。
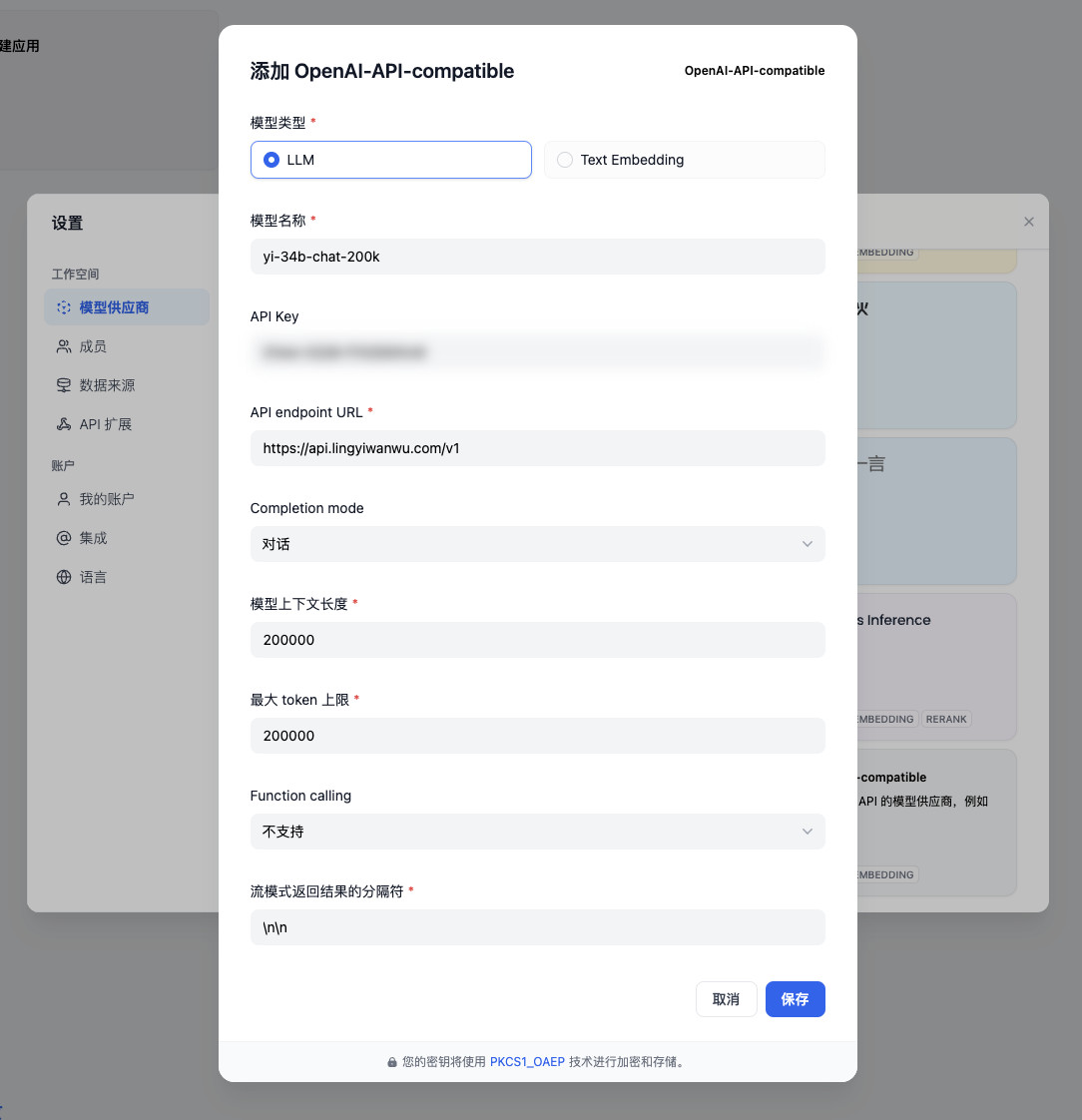
点击确认,界面右上角会提醒我们配置完毕,界面中也会出现 yi-34b-chat-200k 的可用模型提示。
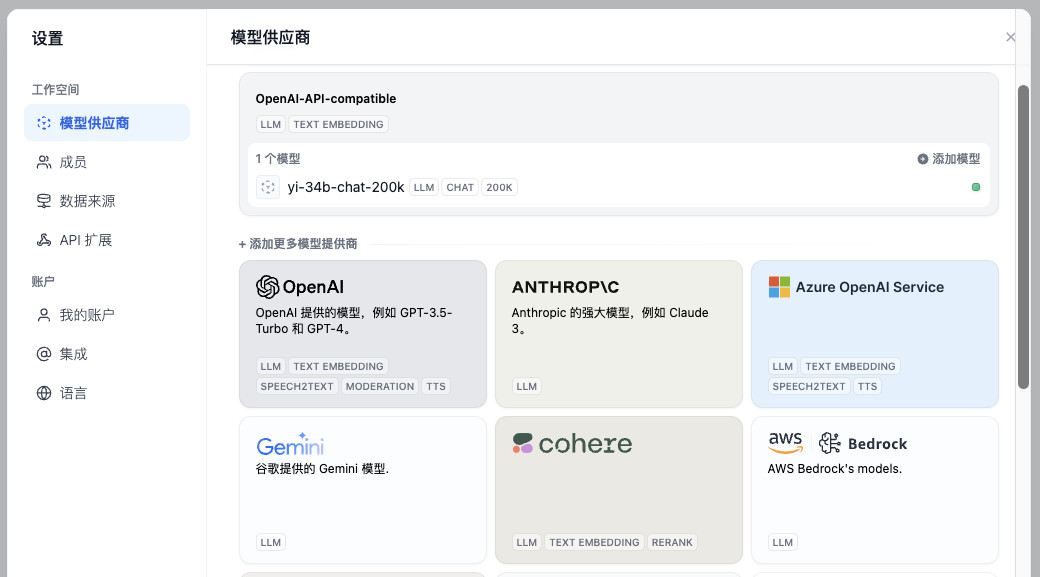
准备工作都结束后,我们就可以来配置模型应用,以及使用 AI 写一些程序,进行电子书的翻译啦。
配置模型翻译应用
回到 Dify 的 Dashboard,选择创建应用。
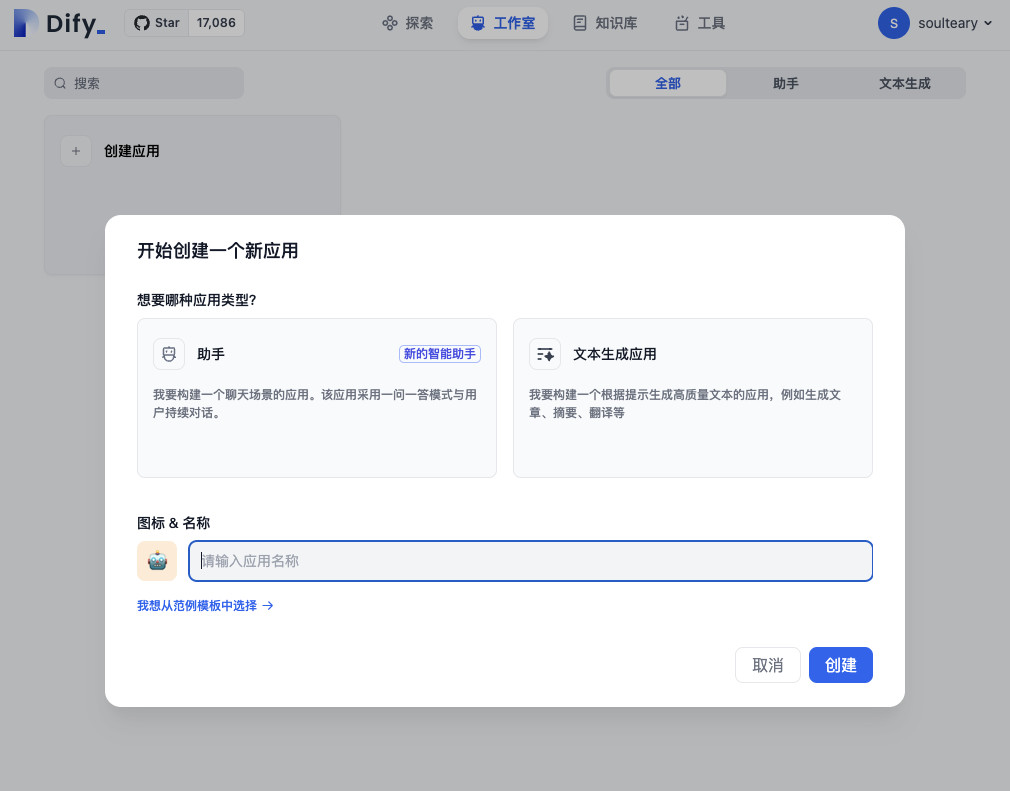
然后,给应用起一个合适的名字(主要方便我们自己区分多个应用)。
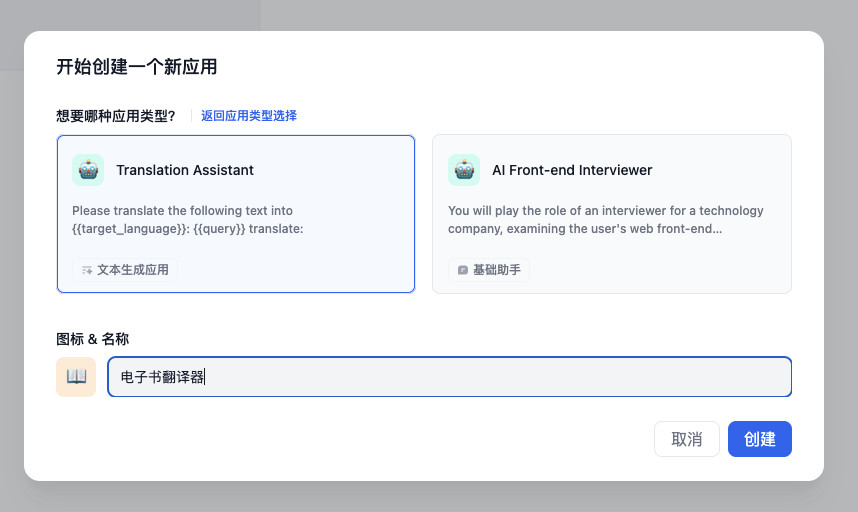
应用创建完毕后,会弹出模型超参数设置的窗口,我们适当调整下上下文长度即可。(目前 200K 模型调用时,我们需要稍微减少一些 Token,避免请求参数中各种字符加上去,超出接口限制)
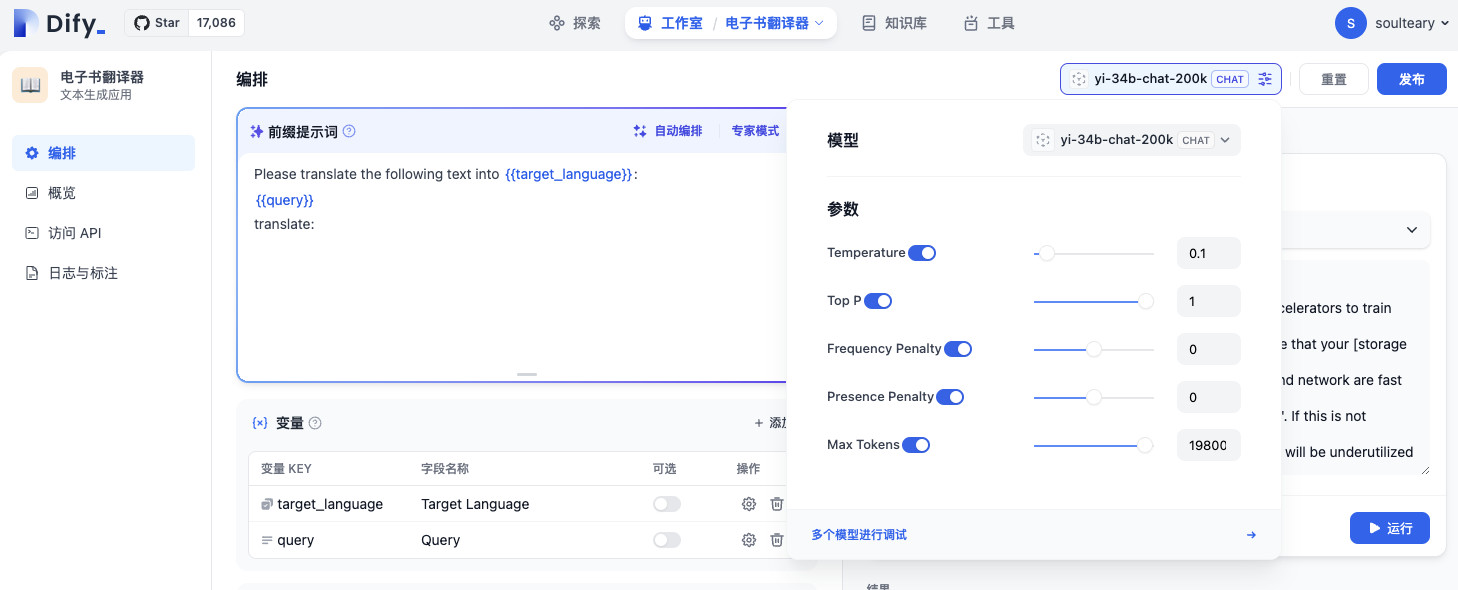
设置完毕,我们将要翻译的长文内容随便找一篇扔到输入框中进行测试即可。相比较手动拼接字符串,调整 Prompt,使用 Dify 这类 LLM IDE 效率上还是提升蛮多的。
点击运行按钮,在下面的结果区域就能够看到模型在迅速地吐结果啦。
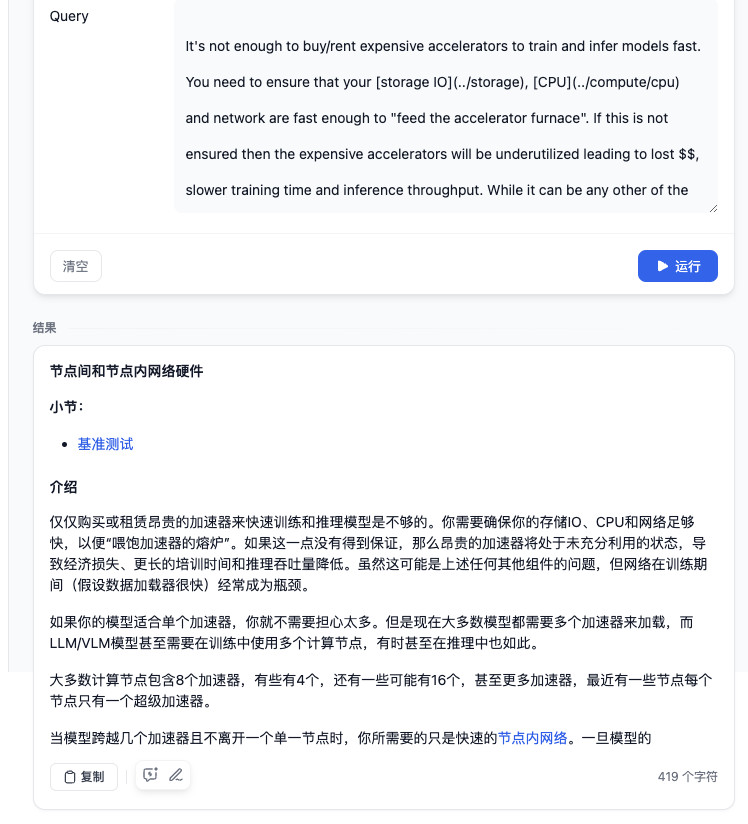
再次回到 Dashboard,左侧的侧边栏就会出现我们刚刚配置的“电子书翻译器”,点击应用名称,我们就能够看到一个简易的模型应用页面啦。我们只需要在左侧选择要翻译到的目标语言,以及输入我们要翻译的内容,点击i运行,就能够得到模型的输出结果了。
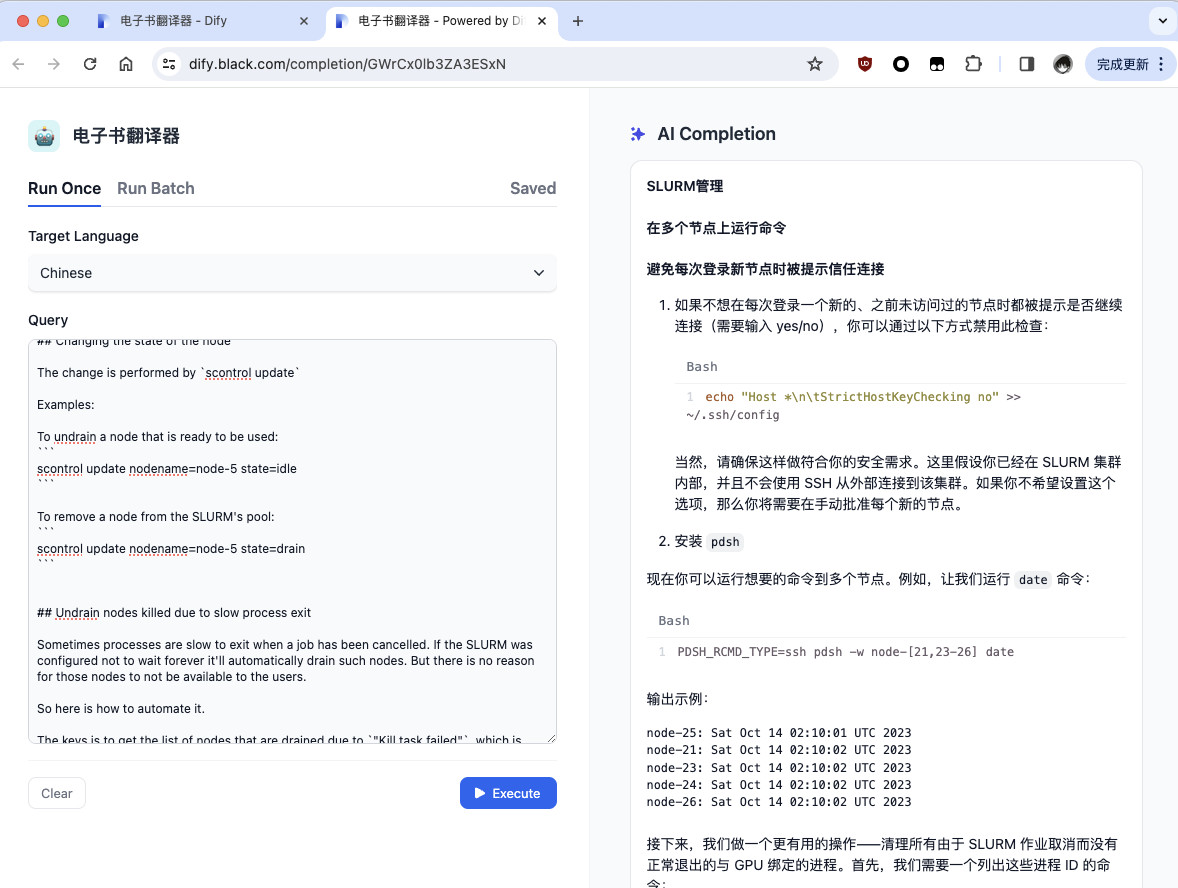
当然,Dify 也支持批量翻译。
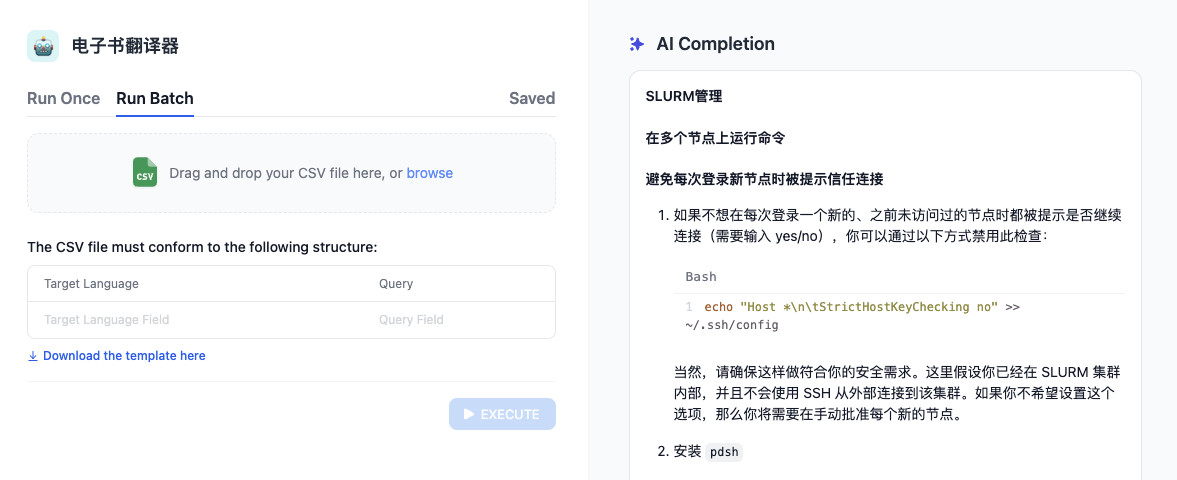
当然,如果文章只是聊如何使用 Dify 折腾一个界面,那么这篇文章也太水了,毕竟这样不能自动化。让我们继续折腾吧。
编写基于模型后端的自动化翻译程序
让我们继续发挥懒人精神,借助 AI 模型,来编写一个能够批量、自动翻译内容的工具吧。
虽然在上文中,我们能够看到模型具备翻译能力,通过不断地“复制粘贴”内容到上面在 Dify 配置好的模型应用也能搞定翻译。
但是,通常情况下,我们想翻译的这类电子书往往会有许多文件需要被处理。以及后续往往不确定哪一个文件又会被作者更新,维护成本还是蛮高的。
所以,如果我们编写一个简单的程序,能够借助模型能力,始终对项目进行完整翻译,或许这个事情就会变的很简单:
- 程序能够读取目录中的每一个需要翻译的文件
- 将文件内容传递给模型程序获取翻译结果
- 然后将翻译好的内容更新到原始文件中
如果后续原作者有其他的更新,我们也只需要按需执行一遍上面的程序,就能够获得最新的资料的翻译内容啦。
编译模型 API 调用程序
让我们先来编写最重要的模型翻译程序,让程序能够调用上面我们配置好的应用,来进行翻译工作。
因为 dify 目前 Golang SDK 存在一些问题,不能直接使用,所以我们先曲线救国,借助 AI 来封装一个简单的调用工具。
打开上面的模型应用界面,在浏览器页面邮件打开“开发者工具”,然后随便输入一些内容,点击运行按钮,让模型进行翻译。此时我们能够在“开发者工具”的“网络”选项卡中捕获到模型的程序请求。选中请求,在请求上右键选择“复制”,将请求以 curl 的方式保存。
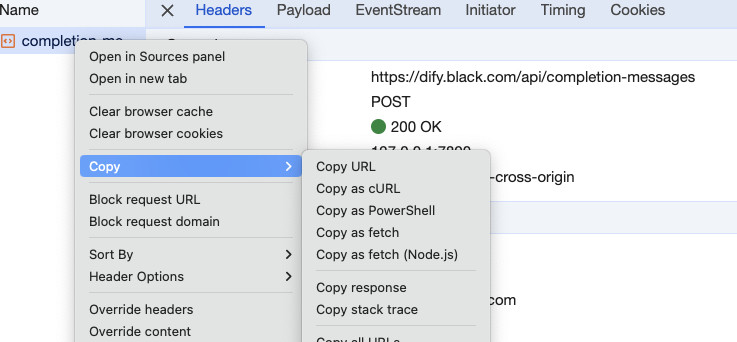
接着,在已经对接好模型的 Chat 工具里,将上面复制保存下来的请求粘贴进去,并在最开头写“一句要求”:
将下面的 curl 请求改写为 golang 程序:
'''bash
curl 'https://dify.black.com/api/completion-messages' \
-H 'authority: dify.black.com' \
-H 'accept: */*' \
-H 'accept-language: zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7' \
...
--data-raw '{"inputs":{"target_language":"Chinese","query":"hello world"},"response_mode":"streaming"}'
'''
稍等片刻,模型就会帮助我们写好类似下面的一段程序:
package main
import (
"fmt"
"io"
"log"
"net/http"
"strings"
)
func main() {
client := &http.Client{}
var data = strings.NewReader(`{"inputs":{"target_language":"Chinese","query":"hello world"},"response_mode":"streaming"}`)
req, err := http.NewRequest("POST", "https://dify.black.com/api/completion-messages", data)
if err != nil {
log.Fatal(err)
}
req.Header.Set("authority", "dify.black.com")
req.Header.Set("accept", "*/*")
req.Header.Set("accept-language", "zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7")
req.Header.Set("authorization", "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJiZTAxZmU0OC05OTRjLTQ3MGItODgxMS0zNTNhNjlhY2ZhZDciLCJzdWIiOiJXZWIgQVBJIFBhc3Nwb3J0IiwiYXBwX2lkIjoiYmUwMWZlNDgtOTk0Yy00NzBiLTg4MTEtMzUzYTY5YWNmYWQ3IiwiYXBwX2NvZGUiOiJHV3JDeDBsYjNaQTNFU3hOIiwiZW5kX3VzZXJfaWQiOiI0ZGM4MmFmOC02OTY3LTRkYzctYTFkMS00YmU5MGUzNGY5N2EifQ.jVewI-mI-p-vybJ66yep1-sPYbVUuSHUPSboOSDRxbE")
req.Header.Set("cache-control", "no-cache")
req.Header.Set("content-type", "application/json")
req.Header.Set("dnt", "1")
req.Header.Set("origin", "https://dify.black.com")
req.Header.Set("pragma", "no-cache")
req.Header.Set("referer", "https://dify.black.com/completion/GWrCx0lb3ZA3ESxN")
req.Header.Set("sec-ch-ua", `"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"`)
req.Header.Set("sec-ch-ua-mobile", "?0")
req.Header.Set("sec-ch-ua-platform", `"macOS"`)
req.Header.Set("sec-fetch-dest", "empty")
req.Header.Set("sec-fetch-mode", "cors")
req.Header.Set("sec-fetch-site", "same-origin")
req.Header.Set("user-agent", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", bodyText)
}
根据小学二年级学会的编程技巧,我们将上面的程序做一些简化,去掉可加可不加的内容,让程序先看起来比较干净:
package main
import (
"fmt"
"io"
"log"
"net/http"
"strings"
)
func main() {
client := &http.Client{}
var data = strings.NewReader(`{"inputs":{"target_language":"Chinese","query":"hello world"},"response_mode":"streaming"}`)
req, err := http.NewRequest("POST", "https://dify.black.com/api/completion-messages", data)
if err != nil {
log.Fatal(err)
}
req.Header.Set("authority", "dify.black.com")
req.Header.Set("accept", "*/*")
req.Header.Set("accept-language", "zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7")
req.Header.Set("authorization", "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJiZTAxZmU0OC05OTRjLTQ3MGItODgxMS0zNTNhNjlhY2ZhZDciLCJzdWIiOiJXZWIgQVBJIFBhc3Nwb3J0IiwiYXBwX2lkIjoiYmUwMWZlNDgtOTk0Yy00NzBiLTg4MTEtMzUzYTY5YWNmYWQ3IiwiYXBwX2NvZGUiOiJHV3JDeDBsYjNaQTNFU3hOIiwiZW5kX3VzZXJfaWQiOiI0ZGM4MmFmOC02OTY3LTRkYzctYTFkMS00YmU5MGUzNGY5N2EifQ.jVewI-mI-p-vybJ66yep1-sPYbVUuSHUPSboOSDRxbE")
req.Header.Set("content-type", "application/json")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
fmt.Printf("%s\n", bodyText)
}
将上面的内容保存为 main.go,然后执行 go run main.go,因为上面程序的请求中包含了 "response_mode":"streaming",所以我们将得到类似下面的流式输出的结果:
# go run main.go
data: {"event": "message", "id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "task_id": "28591fdc-9ec2-4f12-b931-86e2dba66d25", "message_id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "answer": "\u4f60\u597d", "created_at": 1710262616}
data: {"event": "message", "id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "task_id": "28591fdc-9ec2-4f12-b931-86e2dba66d25", "message_id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "answer": "\uff0c", "created_at": 1710262616}
data: {"event": "message", "id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "task_id": "28591fdc-9ec2-4f12-b931-86e2dba66d25", "message_id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "answer": "\u4e16\u754c", "created_at": 1710262616}
data: {"event": "message", "id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "task_id": "28591fdc-9ec2-4f12-b931-86e2dba66d25", "message_id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "answer": "\uff01", "created_at": 1710262616}
data: {"event": "message", "id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "task_id": "28591fdc-9ec2-4f12-b931-86e2dba66d25", "message_id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "answer": "", "created_at": 1710262616}
data: {"event": "message_end", "task_id": "28591fdc-9ec2-4f12-b931-86e2dba66d25", "id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "message_id": "72e9eda4-d251-4506-9f50-06cad6db55fa", "metadata": {}}
在我们的场景中,处理多帧的流式输出比较麻烦(浪费代码行数),所以我们可以将流式输出参数去掉。我们再次执行程序,就能够得到传统的输出结果啦,这样更方便处理。
# go run main.go
{"event": "message", "task_id": "c2355980-9685-450d-ad62-b4b95c50b6c4", "id": "b56c5ff7-c7c6-476e-a28c-5d57cc91ce2d", "message_id": "b56c5ff7-c7c6-476e-a28c-5d57cc91ce2d", "mode": "completion", "answer": "\u4f60\u597d\uff0c\u4e16\u754c\uff01", "metadata": {}, "created_at": 1710262788}
我们将上面的输出结果贴到模型对话窗口中,然后继续向模型提问,比如问模型“如何序列化上面的 JSON 内容,获得 answer 字段中的内容”,简单组合代码,可以得到类似下面的程序:
package main
import (
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"strings"
)
type Response struct {
Answer string `json:"answer"`
}
func main() {
client := &http.Client{}
var data = strings.NewReader(`{"inputs":{"target_language":"Chinese","query":"hello world"}}`)
req, err := http.NewRequest("POST", "https://dify.black.com/api/completion-messages", data)
if err != nil {
log.Fatal(err)
}
req.Header.Set("authority", "dify.black.com")
req.Header.Set("accept", "*/*")
req.Header.Set("accept-language", "zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7")
req.Header.Set("authorization", "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJiZTAxZmU0OC05OTRjLTQ3MGItODgxMS0zNTNhNjlhY2ZhZDciLCJzdWIiOiJXZWIgQVBJIFBhc3Nwb3J0IiwiYXBwX2lkIjoiYmUwMWZlNDgtOTk0Yy00NzBiLTg4MTEtMzUzYTY5YWNmYWQ3IiwiYXBwX2NvZGUiOiJHV3JDeDBsYjNaQTNFU3hOIiwiZW5kX3VzZXJfaWQiOiI0ZGM4MmFmOC02OTY3LTRkYzctYTFkMS00YmU5MGUzNGY5N2EifQ.jVewI-mI-p-vybJ66yep1-sPYbVUuSHUPSboOSDRxbE")
req.Header.Set("content-type", "application/json")
req.Header.Set("origin", "https://dify.black.com")
req.Header.Set("content-type", "application/json")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
log.Fatal(err)
}
var response Response
json.Unmarshal(bodyText, &response)
fmt.Println(response.Answer)
}
再次执行程序,我们将得到符合我们预期的结果,只包含模型处理结果的内容:
# go run main.go
你好,世界!
到这里为止,我们就完成了核心的基于模型的翻译程序。
为了方便后续的调用,我们可以再稍微调整下代码结构,以及完善函数传递参数的方式:
func query(input string) (result string, err error) {
client := &http.Client{}
type Request struct {
Inputs struct {
TargetLanguage string `json:"target_language"`
Query string `json:"query"`
} `json:"inputs"`
ResponseMode string `json:"response_mode,omitempty"`
}
type Response struct {
Answer string `json:"answer"`
}
var payload Request
payload.Inputs.TargetLanguage = "Chinese"
payload.Inputs.Query = input
payloadBuf, err := json.Marshal(payload)
if err != nil {
return result, err
}
var data = strings.NewReader(string(payloadBuf))
req, err := http.NewRequest("POST", "https://dify.black.com/api/completion-messages", data)
if err != nil {
return result, err
}
req.Header.Set("authority", "dify.black.com")
req.Header.Set("accept", "*/*")
req.Header.Set("accept-language", "zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7")
req.Header.Set("authorization", "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJiZTAxZmU0OC05OTRjLTQ3MGItODgxMS0zNTNhNjlhY2ZhZDciLCJzdWIiOiJXZWIgQVBJIFBhc3Nwb3J0IiwiYXBwX2lkIjoiYmUwMWZlNDgtOTk0Yy00NzBiLTg4MTEtMzUzYTY5YWNmYWQ3IiwiYXBwX2NvZGUiOiJHV3JDeDBsYjNaQTNFU3hOIiwiZW5kX3VzZXJfaWQiOiI0ZGM4MmFmOC02OTY3LTRkYzctYTFkMS00YmU5MGUzNGY5N2EifQ.jVewI-mI-p-vybJ66yep1-sPYbVUuSHUPSboOSDRxbE")
req.Header.Set("content-type", "application/json")
req.Header.Set("origin", "https://dify.black.com")
req.Header.Set("content-type", "application/json")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
return result, err
}
var response Response
json.Unmarshal(bodyText, &response)
return response.Answer, nil
}
编写需要翻译的文本程序
接下来,我们来(让模型)编写文件更新相关的程序。还是和模型聊聊天,询问模型如何 “使用 golang 获取目录中所有的 .md 文件路径”,模型告诉我们这样就行:
package main
import (
"fmt"
"os"
"path/filepath"
)
func visit(paths *[]string) filepath.WalkFunc {
return func(path string, info os.FileInfo, err error) error {
if err != nil {
fmt.Printf("Error accessing path %q: %v\n", path, err)
return err
}
if !info.IsDir() && filepath.Ext(path) == ".md" {
*paths = append(*paths, path)
}
return nil
}
}
func main() {
var mdFiles []string
root := "./" // 确定你想要开始搜索的目录路径
err := filepath.Walk(root, visit(&mdFiles))
if err != nil {
panic(err)
}
for _, file := range mdFiles {
fmt.Println(file)
}
}
将上面的内容保存为 main.go,然后调整下要搜索的目录路径,执行 go run main.go 后,我们可以得到所有需要翻译的电子书文件路径:
# go run main.go
../ml-engineering/README.md
../ml-engineering/build/README.md
../ml-engineering/compute/README.md
../ml-engineering/compute/accelerator/README.md
../ml-engineering/compute/accelerator/nvidia/debug.md
../ml-engineering/compute/cpu/README.md
../ml-engineering/compute/cpu-memory/README.md
../ml-engineering/debug/README.md
../ml-engineering/debug/make-tiny-models-tokenizers-datasets.md
../ml-engineering/debug/nccl-performance-debug.md
../ml-engineering/debug/pytorch.md
../ml-engineering/debug/tiny-scripts/README.md
...
接下来,我们再问问模型如何 “使用 golang 读取文件,在原始内容后添加新内容,写回文件”,很容易得到类似下面的程序代码:
package main
import (
"fmt"
"os"
)
func main() {
// 设置文件名
filename := "example.txt"
// 读取文件内容
data, err := os.ReadFile(filename)
if err != nil {
fmt.Println("Error reading file:", err)
return
}
// 需要添加的新内容
newContent := "\nThis is the new content to append."
// 将新内容追加到原始内容后
data = append(data, newContent...)
// 写回文件
err = os.WriteFile(filename, data, 0644) // 0644 是文件权限 (通常意味着所有者可读写,组和其他用户只读)
if err != nil {
fmt.Println("Error writing to file:", err)
return
}
fmt.Println("Content appended successfully")
}
到目前为止,我们所有需要的程序就都齐啦。
编写最终的翻译程序
我们将上面的两段程序代码,以及上文中我们封装好的模型翻译程序代码合并起来:
package main
import (
"encoding/json"
"fmt"
"io"
"log"
"net/http"
"os"
"path/filepath"
"strings"
)
func query(input string) (result string, err error) {
client := &http.Client{}
type Request struct {
Inputs struct {
TargetLanguage string `json:"target_language"`
Query string `json:"query"`
} `json:"inputs"`
ResponseMode string `json:"response_mode,omitempty"`
}
type Response struct {
Answer string `json:"answer"`
}
var payload Request
payload.Inputs.TargetLanguage = "Chinese"
payload.Inputs.Query = input
payloadBuf, err := json.Marshal(payload)
if err != nil {
return result, err
}
var data = strings.NewReader(string(payloadBuf))
req, err := http.NewRequest("POST", "https://dify.black.com/api/completion-messages", data)
if err != nil {
return result, err
}
req.Header.Set("authority", "dify.black.com")
req.Header.Set("accept", "*/*")
req.Header.Set("accept-language", "zh-CN,zh;q=0.9,en;q=0.8,ja;q=0.7")
req.Header.Set("authorization", "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJiZTAxZmU0OC05OTRjLTQ3MGItODgxMS0zNTNhNjlhY2ZhZDciLCJzdWIiOiJXZWIgQVBJIFBhc3Nwb3J0IiwiYXBwX2lkIjoiYmUwMWZlNDgtOTk0Yy00NzBiLTg4MTEtMzUzYTY5YWNmYWQ3IiwiYXBwX2NvZGUiOiJHV3JDeDBsYjNaQTNFU3hOIiwiZW5kX3VzZXJfaWQiOiI0ZGM4MmFmOC02OTY3LTRkYzctYTFkMS00YmU5MGUzNGY5N2EifQ.jVewI-mI-p-vybJ66yep1-sPYbVUuSHUPSboOSDRxbE")
req.Header.Set("content-type", "application/json")
req.Header.Set("origin", "https://dify.black.com")
req.Header.Set("content-type", "application/json")
resp, err := client.Do(req)
if err != nil {
log.Fatal(err)
}
defer resp.Body.Close()
bodyText, err := io.ReadAll(resp.Body)
if err != nil {
return result, err
}
var response Response
json.Unmarshal(bodyText, &response)
return response.Answer, nil
}
func visit(paths *[]string) filepath.WalkFunc {
return func(path string, info os.FileInfo, err error) error {
if err != nil {
fmt.Printf("Error accessing path %q: %v\n", path, err)
return err
}
if !info.IsDir() && filepath.Ext(path) == ".md" {
*paths = append(*paths, path)
}
return nil
}
}
func main() {
var mdFiles []string
root := "../ml-engineering"
err := filepath.Walk(root, visit(&mdFiles))
if err != nil {
panic(err)
}
for _, filePath := range mdFiles {
fmt.Println("开始处理文件", filePath)
buf, err := os.ReadFile(filePath)
if err != nil {
fmt.Printf("读取文件出错: %s\n", err)
return
}
translated, err := query(string(buf))
if err != nil {
fmt.Printf("调用模型翻译出错: %s\n", err)
return
}
err = os.WriteFile(filePath, []byte(translated), 0644)
if err != nil {
fmt.Printf("保存文件出错: %s\n", err)
return
}
fmt.Println("搞定!")
}
}
将上面的代码保存为 main.go,然后再次执行 go run main.go,我们将得到类似下面的结果:
# go run main.go
开始处理文件 ../ml-engineering/README.md
搞定!
开始处理文件 ../ml-engineering/build/README.md
搞定!
开始处理文件 ../ml-engineering/compute/README.md
搞定!
开始处理文件 ../ml-engineering/compute/accelerator/README.md
搞定!
开始处理文件 ../ml-engineering/compute/accelerator/nvidia/debug.md
...
耐心等待程序请求结束,每一篇内容大概需要花费十几秒左右的时间,来等待模型处理。如果你在看本篇文章的时候已经准备好了饮料和书,那么现在就是一边喝饮料,一边看书的时刻啦。
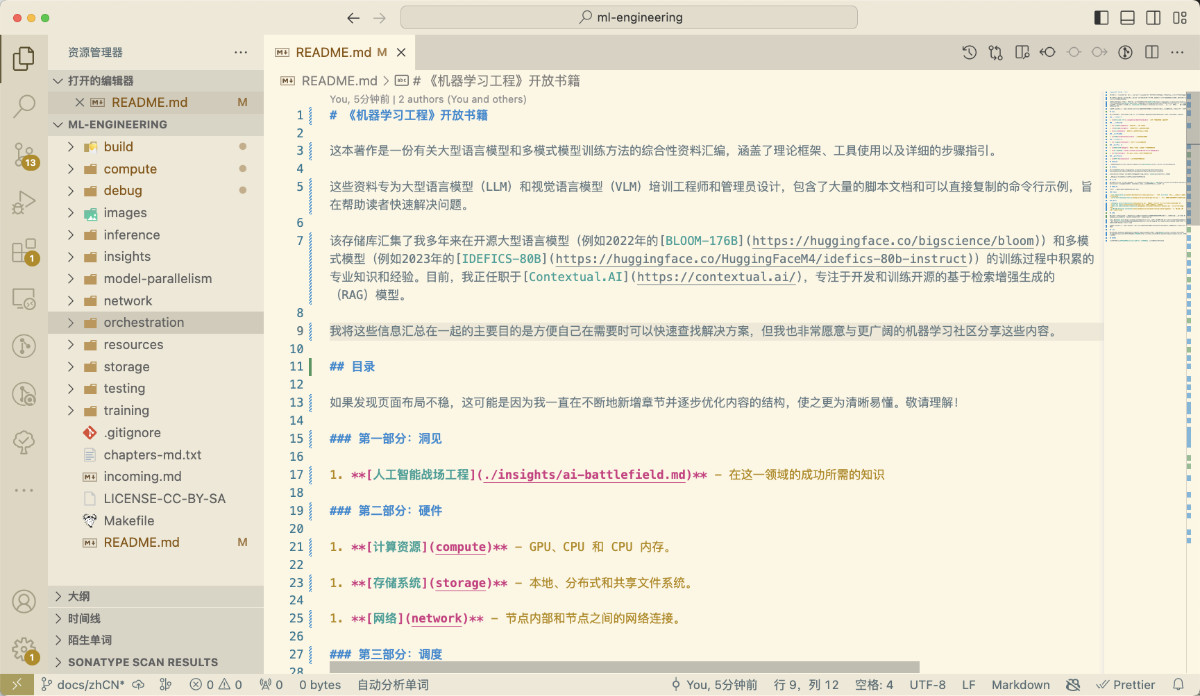
稍等片刻,当模型处理完所有文件后,我们就能够得到模型翻译电子书的第一版中文内容啦。
当然,这里只是翻译的第一步,类似训练模型分为不同的阶段,这个阶段,我们使用模型和一杯饮料,就可以快速的完成整本书的低成本的快速翻译。

至于精细化翻译,以及名词一致性调整,额外的内容的总结和摘要,或者风格化口语翻译,我们后面慢慢来。
本篇文章,我们就先聊到这里,下一篇相关的文章里,我们来聊聊更精细的翻译细节处理,以及模型应用的复杂流水线的编排。
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK