

分析型数据库DuckDB基准测试
source link: https://www.51cto.com/article/768991.html
Go to the source link to view the article. You can view the picture content, updated content and better typesetting reading experience. If the link is broken, please click the button below to view the snapshot at that time.
分析型数据库DuckDB基准测试
我们都知道Polars很快,但是最近DuckDB以其独特的数据库特性让我们对他有了更多的关注,本文将对二者进行基准测试,评估它们的速度、效率和用户友好性。
我们都知道Polars很快,但是最近DuckDB以其独特的数据库特性让我们对他有了更多的关注,本文将对二者进行基准测试,评估它们的速度、效率和用户友好性。

在评测之前我们先看看这两个框架
- DuckDB(0.9.0):一个用c++编写的内存分析数据库。
- Polars(0.19.6):一个用Rust实现的超快的DataFrame库
除此以外还有Pandas、Dask、Spark和Vaex本文主要关注DuckDB和Polars的基准测试,因为它们特别强调在某些环境下的速度性能。之所以对这两个框架进行对比是因为 Polars是我目前测试后得到最快的库,而DuckDB它可以更好的支持SQL,这对于我来说是非常好的特这个,因为我更习惯使用SQL来进行查询。
我使用了官方的polar基准测试存储库进行此评估。基准测试由tpc标准化查询组成。这些是专门用来评估实际的、真实的工作流的性能的。在Polars官方网站上,提供了8个此类查询的详细结果。这个基准包含22个唯一的查询(q1、q2等)。这些范围从多表连接到聚合排序,所有这些都是大家认可的经过特殊构建的查询。
测试在一台配备16核AMD vCPU和32GB RAM的机器上进行。所有代码都使用Python 3.10执行。
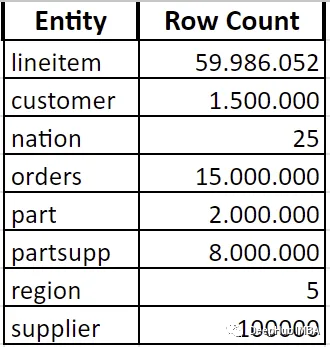
数据是由使用scale10的存储库代码生成的,下面是每个实体的大小
数据转换与查询
我们文件读取到内存中,然后进行查询。
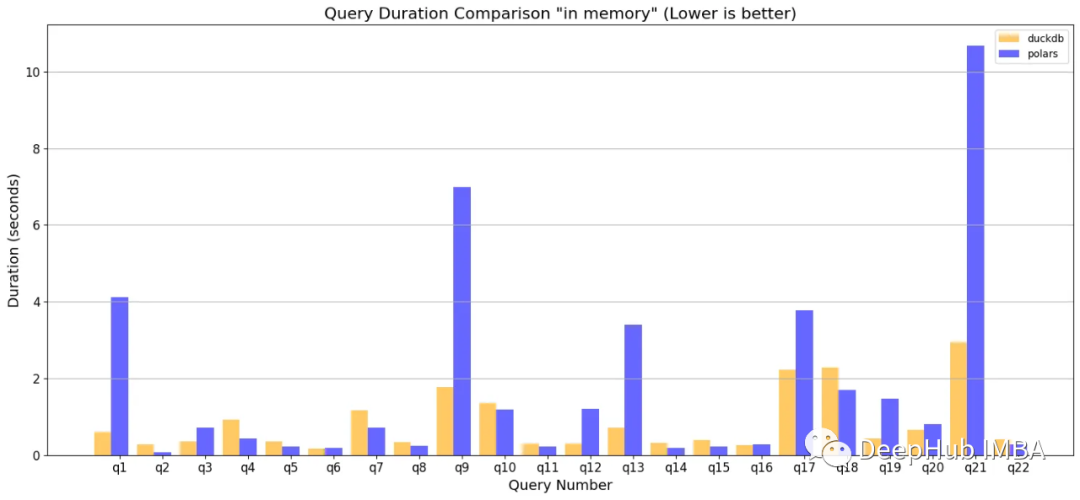
在q1、q9、q13和q17中,多连接、基于字符串的过滤和复杂聚合的组合对于polars 来说很难像duckdb那样有效地进行优化。Q21是对惟一值的计数、基于这些计数进行过滤以及随后的一系列连接的操作。
总的来说DuckDB在这两种情况下看起来更快,但这并不是全部。
因为将数据加载到内存中的过程会产生时间和内存开销。我们通过Makefile准确地度量这些成本。
/usr/bin/time -v make run_duckdb
/usr/bin/time -v make run_polars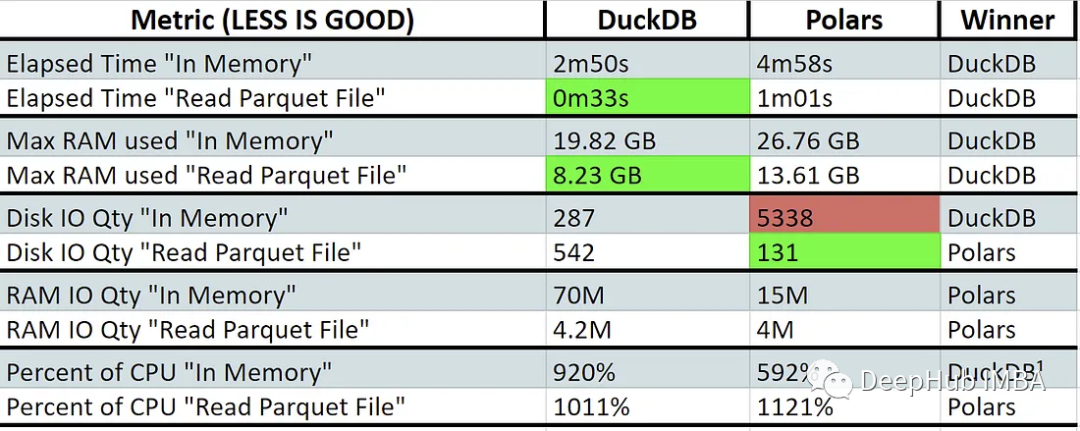
与polar相比,DuckDB在直接读取文件时表现出更快的性能和更低的内存使用。这表明polars 可能使用了交换内存(红色)。这些库不是为跨多台机器扩展而设计的,所以它们都进行了高效CPU核心利用率的设计。
Polars在某些特定领域表现出具有竞争力甚至更好的性能,例如直接读取文件时的磁盘IO和内存操作时的RAM IO。在磁盘IOPS较低的系统中,polar可以表现得更好。
另外:上图中的CPU百分比越高越好。值大于100%表示正在使用多核处理。
下面是我们测试的代码:
DuckDB读取Parquet直接查询
import duckdb
conn = duckdb.connect(database=':memory:')
df_count = conn.sql("""
SELECT
count(*) as count_order
FROM
'lineitem.parquet'
"""
).fetchdf()
print(df_count)DuckDB内存查询
import duckdb
conn = duckdb.connect(database=':memory:')
conn.sql("""
CREATE TEMP TABLE IF NOT EXISTS lineitem AS
SELECT *
FROM read_parquet('lineitem.parquet');
"""
)
df_count = conn.sql("""
SELECT
count(*) as count_order
FROM
lineitem
"""
).fetchdf()
print(df_count)Polars 读取Parquet直接查询
import polars as pl
df = pl.scan_parquet('lineitem.parquet')
df_count = df.select(
pl.count().alias("count_order"),
).collect()
print(df_count)Polars 内存查询
import polars as pl
df = pl.scan_parquet('lineitem.parquet')
df = df.collect().rechunk().lazy()
df_count = df.select(
pl.count().alias("count_order"),
).collect()
print(df_count)可以看到在Python处理引擎领域,DuckDB是一个很有前途的竞争者。他在涉及连接和复杂聚合的任务中表现非常亮眼。另外它的简单并且更干净、而且还支持SQL语句直接查询。
但是DuckDB仍处于初级阶段。可能偶尔会遇到bug或缺少功能的问题,如果你有兴趣,可以在你的研究项目中使用DuckDB替代Polars或者Pandas。
本文的测试脚本:
https://github.com/pola-rs/tpch#polars-tpch
Recommend
About Joyk
Aggregate valuable and interesting links.
Joyk means Joy of geeK